追加训练预训练处理器
使用账单解析器,您可以追加训练预训练处理器以提高准确率。您从一个预制模型开始,然后使用您的数据训练模型,并添加自定义字段。账单格式多种多样,使用您的数据追加训练通用账单解析器可以针对特定格式提高其准确率,并让解析器能够提取预训练模型不支持的字段。Google 提供了示例数据,但您也可以按照相同的步骤来使用自己的数据。
如需在 Google Cloud 控制台中直接遵循有关此任务的分步指导,请点击操作演示:
准备工作
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Document AI, Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. 在 Google Cloud 控制台导航菜单中,依次选择 Document AI 和处理器库。
在处理器库中,
搜索 账单解析器,然后选择创建。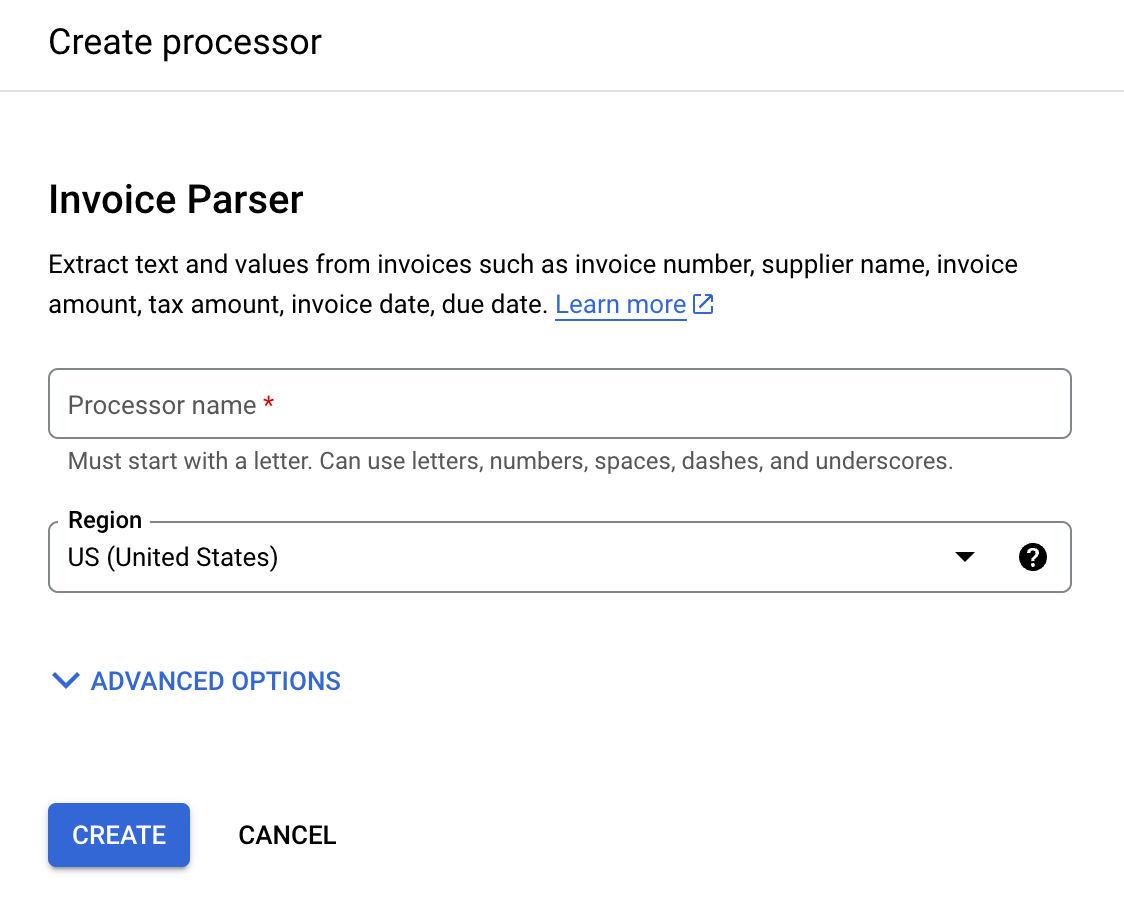
输入处理器名称,例如
invoice-parser-for-uptraining。选择离您最近的区域。
选择创建。系统随即会显示处理器详情标签页。
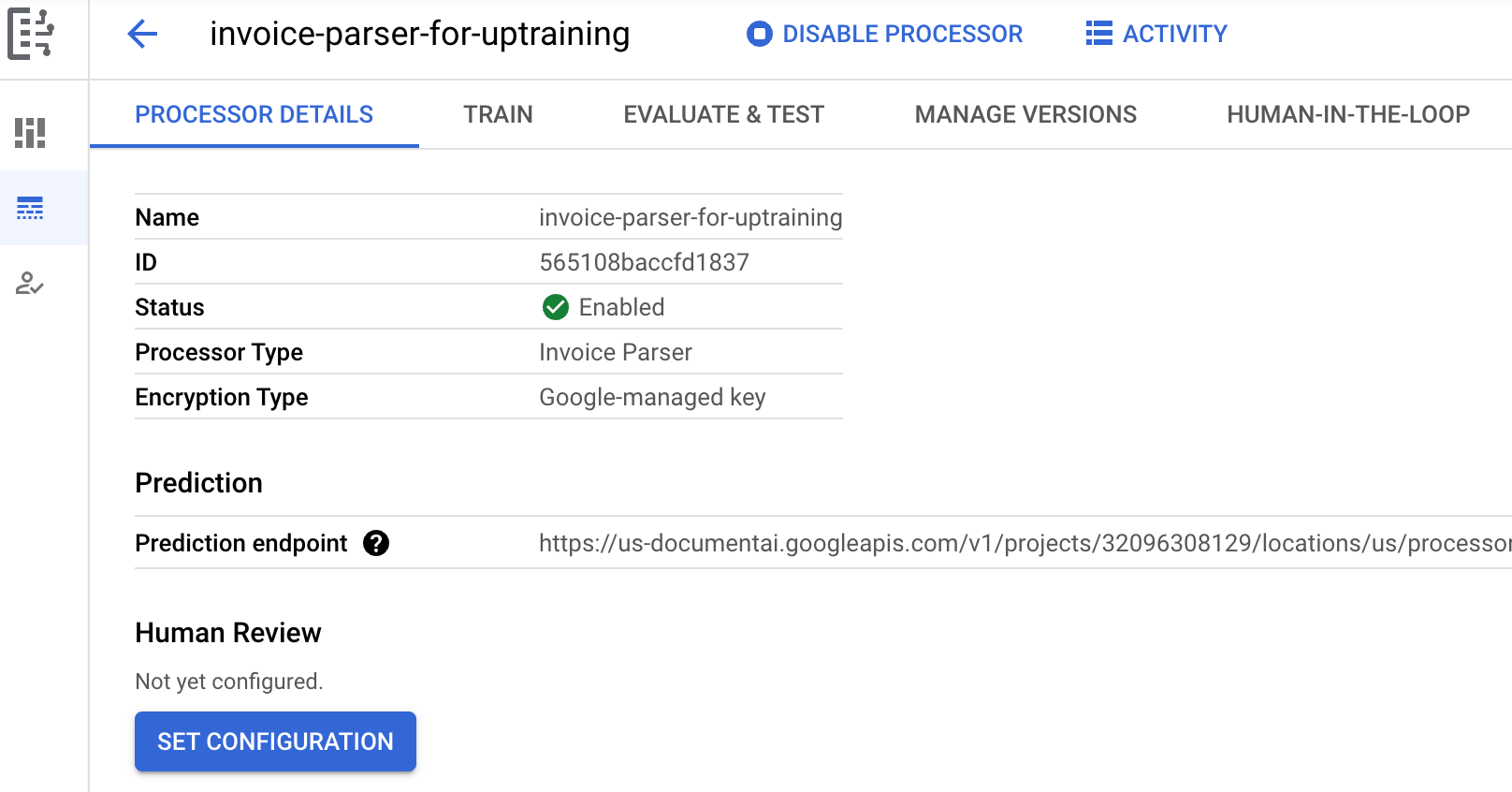
转到处理器的
训练 标签页。选择
设置数据集位置 。系统会提示您选择或创建一个空的 Cloud Storage 存储桶或文件夹。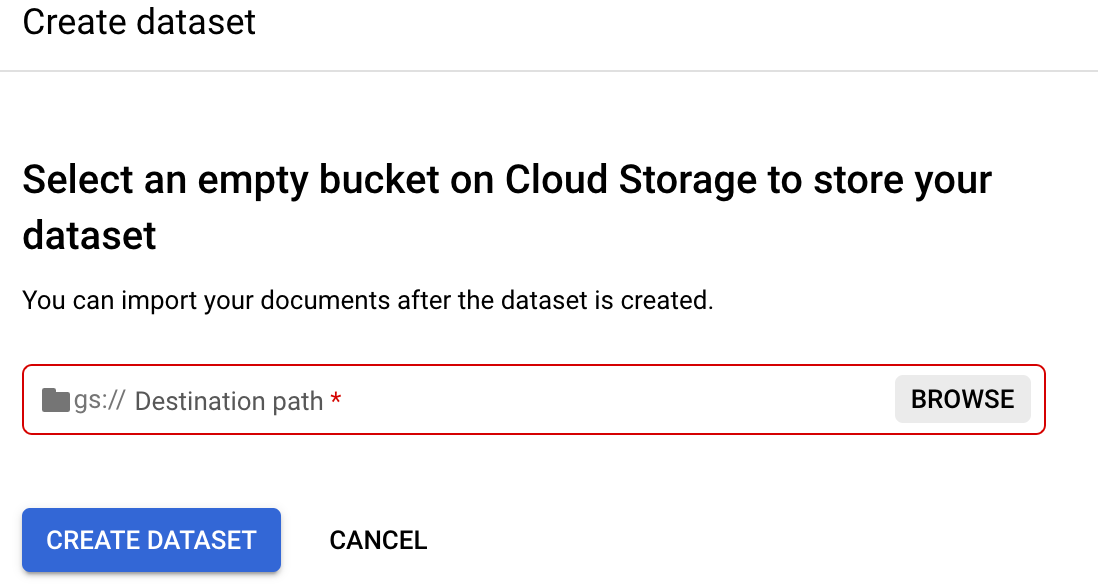
选择
浏览 以打开选择文件夹。选择
创建新存储桶 ,然后按照提示创建新的存储桶。如需详细了解如何创建 Cloud Storage 存储桶,请参阅 Cloud Storage 存储桶。注意:存储桶是顶级存储实体,您可以在其中嵌套文件夹。如果愿意,您也可以在某个现有存储桶中创建一个空文件夹并选择该文件夹,而不是创建一个存储桶并选择该存储桶。请参阅模拟文件夹。
创建存储桶后,系统会显示该存储桶的选择文件夹页面。
在存储桶的选择文件夹页面上,选择对话框底部的
选择 。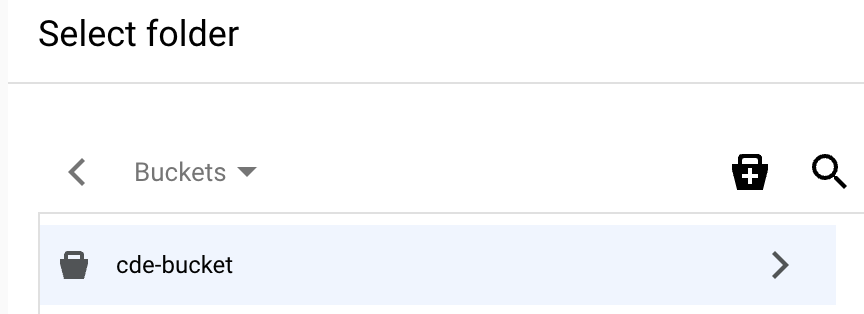
确保目标路径中填充了您选择的存储桶的名称。选择
创建数据集 。数据集最多可能需要几分钟时间才能创建完毕。
直接进入上训练阶段:跳至导入预先标记的数据。 您可以使用工具手动为字段添加标签,并将文档添加到训练数据中,而不是导入示例文档。
手动为文档添加标签并将其添加到训练集:在继续进行增量训练之前,请继续导入用于手动添加标签的示例文档,并完成其中的说明。
在训练标签页上,选择
导入文档 。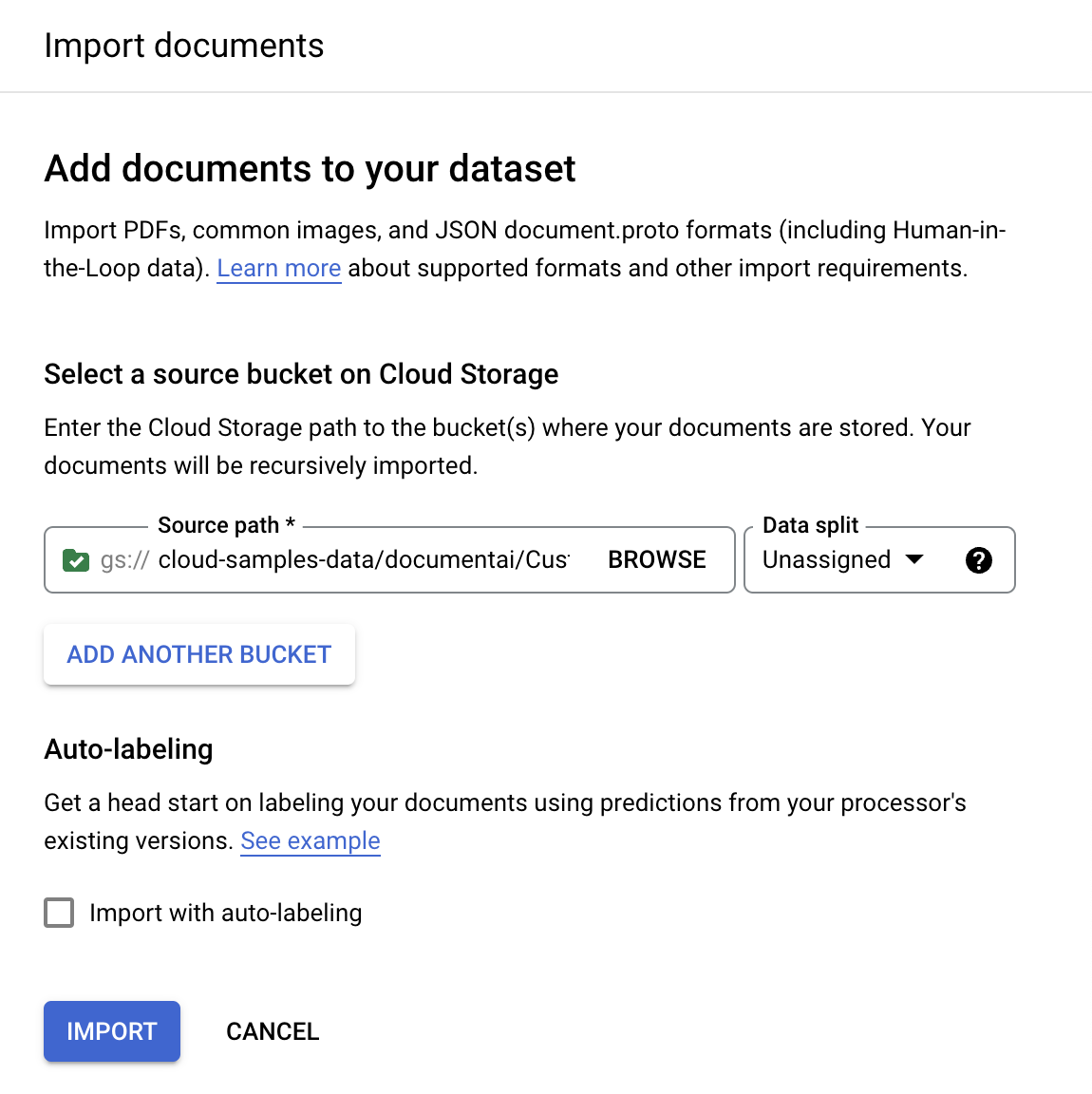
在此示例中,请在
来源路径 中输入此存储桶名称。这可直接链接到一个文档。cloud-samples-data/documentai/codelabs/uptraining/pdfs对于数据拆分,选择未分配。此文件夹中的文档既未分配给测试集,也未分配给训练集。请不要勾选使用自动添加标签功能导入。
选择导入。 Document AI 将存储桶中的文档读入数据集。它不会修改导入存储桶,也不会在导入完成后从存储桶读取数据。
在训练标签页上,选择左下角的
修改架构 。系统随即会打开管理标签页面。如需停用未使用的标签,请勾选未添加到以下列表中的字段对应的
复选框 ,然后选择停用。以下字段应保持启用状态:invoice_date line_item amount description receiver_address receiver_name supplier_address supplier_name total_amount注意:标签是无法删除的。不过,您可以停用不想使用的任何标签。
标签设置完成后,选择
保存 。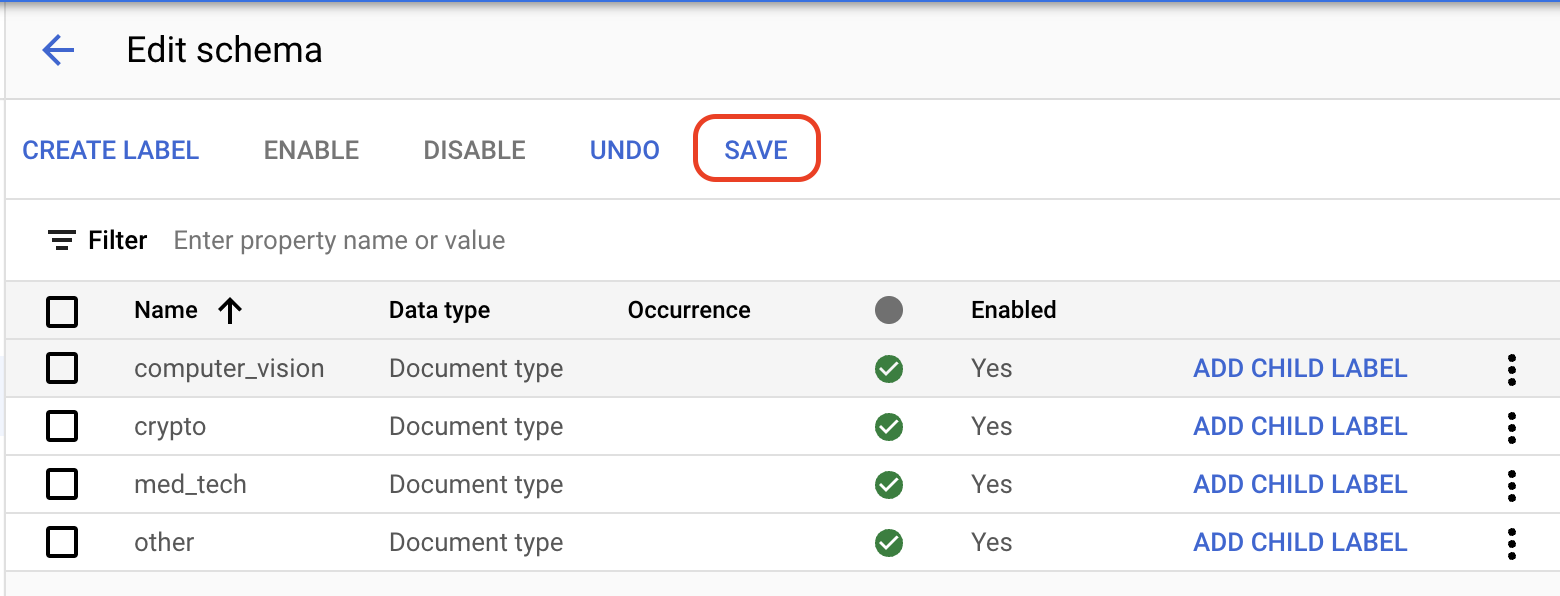
选择
返回箭头 以返回训练页面。返回训练标签页,然后选择
一个文档 以打开标签管理控制台。接下来,从左侧面板中,从与要添加注解的值对应的架构标签中进行选择,并应用该标签。
默认情况下使用
边界框 工具,或使用选择文字 工具设置多行值,以选择内容并应用标签。例如,在此账单中,文本“McWilliam Piping International Piping Company”应分配有
supplier_name标签。您可以使用文本过滤条件来搜索标签名称。注意:选择文本工具并不适用于所有文本值,因此请使用边界框(如果适用)。您还可以使用边界框工具来选择非文本字段,例如复选框。
查看检测到的文本值,以确保其反映文档中正确的文本。
选择与标签对应的文字时,请确保仅添加相关文本。例如,对于
invoice_id标签,请勿添加通常位于数值前面的字符(例如#)。请勿包含$等货币符号。- 确保您为实体的所有实例添加注解。例如,
supplier_name或invoice_id可能会在文档中多次出现,并且应为每个实例添加注解。
- 确保您为实体的所有实例添加注解。例如,
对每个要添加标签的字段重复执行上述步骤。
完成为文档添加注解后,选择
标记为已加标签 。在训练标签页上,左侧面板会显示已标记 1 个文档。
在训练标签页上,选中
全选 复选框。从
分配给集合 列表中,选择训练。选择
导入文档 。在
来源路径 中输入以下路径。此存储桶包含文档 JSON 格式的预先添加标签的文档。cloud-samples-data/documentai/Custom/Invoices/JSON在数据拆分列表中,选择自动拆分。这会自动拆分文档,使其数据在训练集中占 80%,在测试集中占 20%。请不要勾选使用自动添加标签功能导入。
选择导入。 导入过程可能需要几分钟时间。随后,在训练标签页中找到文档。
在训练页面上,
导入文档 。复制并粘贴下面的 Cloud Storage 路径。该目录包含 5 个没有加标签的账单 PDF 文件。在数据拆分下拉列表中,选择训练。
cloud-samples-data/documentai/Custom/Invoices/PDF_Unlabeled在自动加标签部分,选中
使用自动添加标签功能导入 复选框。选择现有处理器版本,以便为文档添加标签。
- 例如:
pretrained-invoice-v1.3-2022-07-15
- 例如:
选择导入,然后等待文档导入。您可以离开此页面,稍后再返回来查看。
- 完成后,文档会显示在训练页面的已自动加标签部分中。
您不能使用自动加标签的文档进行训练或测试,除非将其标记为已加标签。找到
已自动加标签 部分以查看自动加标签的文档。选择第一个文档以进入标签控制台。
请验证该标签,确保其正确无误。如果不正确,请进行调整。
完成后,选择
标记为已加标签 。为每个自动加标签的文档重复标签验证,然后返回训练页面以使用数据进行训练。
选择
追加训练新版本 。在
版本名称 字段中,输入此处理器版本的名称,例如invoice-uptrain-1。(可选)选择查看标签统计信息,找到文档标签的相关信息。这有助于确定覆盖率。选择关闭即可返回训练设置。
选择
开始训练 ,您可以在右侧面板上查看训练状态。数据集管理页面随即会打开。您可以在右侧查看训练状态。训练可能需要几个小时,具体取决于数据集的大小。您可以离开此页面,稍后再返回来查看。
训练完成后,转到
管理版本 标签页。您可以查看刚刚训练的版本的详细信息。选择要部署的版本右侧的
三个垂直点 ,然后选择部署版本。从弹出式窗口中选择
部署 。部署需要几分钟才能完成。
部署完成后,转到
评估和测试 标签页。在此页面上,您可以查看完整文档以及各个标签的各项评估指标,包括 F1 得分、精确率和召回率。如需详细了解评估及统计信息,请参阅评估处理器。
下载之前训练或测试中未涉及的文档,以便使用它来评估处理器版本。如果您使用自己的数据,则可以使用为此目的预留的文档集。
选择
上传测试文档 ,然后选择您刚刚下载的文档。系统会打开账单解析器分析页面。屏幕输出会展示文档的分类效果。
您也可以针对其他测试集或处理器版本重新运行评估。
在 Google Cloud 控制台导航菜单中,依次选择 Document AI 和我的处理器。
选择要删除的处理器所在行中的
更多操作 。选择删除处理器,输入处理器名称,然后再次选择删除进行确认。
创建处理器
为数据集创建 Cloud Storage 存储桶
如需训练新处理器,您必须创建一个包含训练和测试数据的数据集,以帮助处理器识别您要提取的实体。
此数据集需要新的 Cloud Storage 存储桶。请不要使用与存储文档的存储桶相同的存储桶。
导入示例文档以手动添加标签
接下来,将示例账单 PDF 文件导入数据集。您要为本文档中的字段添加标签,以协助后续的追加训练流程。
在本指南中,为您提供了代表性文件作为示例文档。
导入文档时,可以选择性地在导入后将文档分配给训练或测试集,或者等待稍后再分配这些文档。
如果要删除已导入的一个或多个文档,请在训练标签页上选择这些文档,然后选择删除。
如需详细了解如何准备要导入的数据,请参阅数据准备指南。
定义处理器架构
您的数据集可能不包含账单解析器支持的所有标签。
如果是这样,则在开始进行追加训练之前,您必须标记未用作 Inactive 的标签。在开始进行追加训练之前,您还可以添加一个或多个自定义标签。
为文档加标签
选择文档中的特定文本并为其添加标签的过程也称为“加注释”。
以下示例展示了完整标签集及其相应文本。
| 标签名称 | 文本 |
|---|---|
supplier_name |
McWilliam Piping International Piping Company |
supplier_address |
14368 Pipeline Ave Chino, CA 91710 |
invoice_id |
10001 |
due_date |
2020-01-02 |
line_item/description |
转向节耦合器 |
line_item/quantity |
9 |
line_item/unit_price |
74.43 |
line_item/amount |
669.87 |
line_item/description |
PVC 管(12 英寸) |
line_item/quantity |
7 |
line_item/unit_price |
15.90 |
line_item/amount |
111.30 |
line_item/description |
铜管 |
line_item/quantity |
7 |
line_item/unit_price |
91.20 |
line_item/amount |
638.40 |
net_amount |
1,419.57 |
total_tax_amount |
113.57 |
total_amount |
1,533.14 |
currency |
$ |
将已添加注解的文档分配给训练集
现在,您已为此示例文档添加了标签,接下来可以将其分配给训练集。
在左侧面板中,您可以看到系统已将 1 个文档分配给训练集。
将预先加标签的数据导入训练集和测试集
Document AI 追加训练要求训练集和测试集中至少有 10 个文档,并且每个集中的每个标签有 10 个实例。
为了获得最佳性能,我们建议您在每个数据集中至少有 50 个文档,每个标签至少有 50 个实例。通常,训练数据越多,准确性就越高。
在本指南中,我们已为您提供了预先加标签的数据。 但如果您处理的是自己的项目,则必须确定如何为您的数据添加标签。请参阅标签选项。
可选:为新导入的文档自动添加标签
在为已部署现有处理器版本的处理器导入未加标签的文档时,您可以使用自动加标签功能来节省加标签的时间。
训练处理器
现在,您已导入训练和测试数据,接下来就可以训练处理器了。由于训练过程可能需要几个小时,因此在开始训练之前,请确保您已使用适当的数据和标签设置处理器。
部署处理器版本
评估和测试处理器
使用处理器
您已成功创建并追加训练了账单解析器处理器。
您可以像管理任何其他处理器版本一样管理自定义训练的处理器版本,例如在某个处理器已弃用时迁移到较新的处理器。如需了解详情,请参阅管理处理器版本。
您可以向自定义处理器发送处理请求,并且响应的处理方式可以与其他实体提取处理器相同。
清理
为避免因本页中使用的资源导致您的 Google Cloud 账号产生费用,请按照以下步骤操作。
为避免产生不必要的 Google Cloud 费用,请使用 Google Cloud console删除您不需要的处理器和项目。
如果您为了解 Document AI 创建了一个新项目,但现在不再需要该项目,[请删除项目][delete-project]。
如果您使用的是现有 Google Cloud 项目,请删除您创建的资源,以避免您的账号产生费用: