必须使用加标签的文档数据集才能训练、追加训练或评估处理器版本。
本页面介绍了如何将处理器架构中的标签应用于数据集中导入的文档。
本页面假定您已创建支持训练、追加训练或评估的处理器。如果您的处理器受支持,您现在会在 Google Cloud 控制台中看到训练标签页。此外,还假设您已创建数据集、导入文档并定义处理器架构。
用于生成式 AI 提取的名称字段
字段的命名方式会影响使用生成式 AI 提取字段的准确性。我们建议在命名字段时遵循以下最佳实践:
使用与文档中描述字段时所用的语言相同的语言来命名字段:例如,如果文档中有一个字段描述为
Employer Address,则将该字段命名为employer_address。请勿使用emplr_addr等缩写。目前不支持在字段名称中使用空格:请使用
_而不是空格。例如:First Name将命名为first_name。迭代名称以提高准确性:Document AI 存在一项限制,即不允许更改字段名称。如需测试不同的名称,请使用重命名实体名称工具,将数据集中的旧实体名称更新为新名称,导入数据集,在处理器中启用新实体,然后停用或删除现有字段。
零样本学习和少样本学习
搭载 Gemini 的模型具有零样本学习和少样本学习能力,只需少量甚至无需训练数据即可创建高性能模型。
零样本学习是一种机器学习示例,其中预训练模型无需任何上游训练,即可在测试期间学习识别和分类之前未遇到过的类别和实体。
少样本学习是指模型仅需少量训练示例即可学习识别和分类新类别和实体。它利用从大型、标记完善的数据集中获得的预训练模型知识来提高少样本任务的性能。
当训练数据集整洁且经过仔细标记时,少样本学习会更加有效。通常,这意味着至少需要 10 个测试示例和 10 个训练示例供模型学习。
标签选项
以下是用于标记文档的选项:
人工:在 Google Cloud 控制台中手动为文档添加标签
自动加标签:使用现有处理器版本生成标签
导入预先添加标签的文档:如果您已有添加标签的文档,可节省时间
在 Google Cloud 控制台中手动添加标签
在训练标签页中,选择一个文档以打开标签工具。
在标签工具左侧的架构标签列表中,选择“添加”符号以选择边界框工具,从而突出显示文档中的实体并将其分配给标签。
在以下屏幕截图中,文档中的 EMPL_SSN EMPLR_ID_NUMBER、EMPLR_NAME_ADDRESS、FEDERAL_INCOME_TAX_WH、SS_TAX_WH、SS_WAGES 和 WAGES_TIPS_OTHER_COMP 字段已被分配标签。
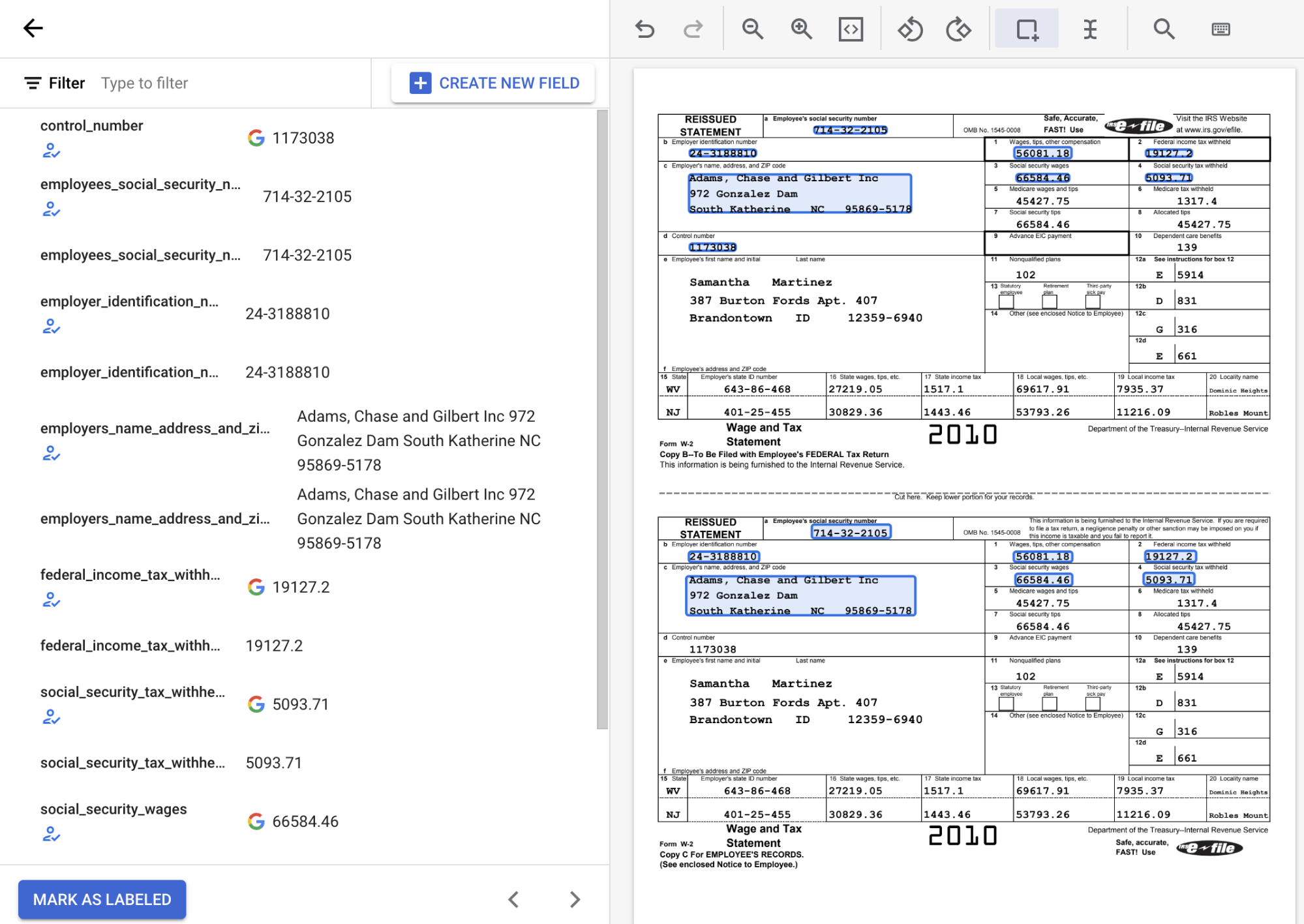
使用边界框工具选择复选框实体时,请仅选择复选框本身,而不要选择任何关联的文本。确保左侧显示的复选框实体处于选中或未选中状态,与文档中的状态一致。

为父实体-子实体对添加标签时,请勿为父实体添加标签。父实体只是子实体的容器。仅标记子实体。 父实体会自动更新。
为子实体添加标签时,请先为第一个子实体添加标签,然后将相关子实体与该行关联。当您首次为这类实体添加标签时,会在第二个子实体中注意到这一点。例如,对于发票,如果您标记说明,它看起来就像任何其他实体一样。不过,如果您接下来标记数量,系统会提示您选择父级。
针对每个订单项重复此步骤,为每个新订单项选择新父实体。
系统支持最多嵌套三层的表格的父子实体。 基础模型支持三个层级的字段(祖父级、父级、子级),因此子实体可以有一个层级的子级。如需详细了解嵌套,请参阅三级嵌套。
速查表
在为表格添加标签时,一遍又一遍地为每一行添加标签可能会很麻烦。有一个非常方便的工具可以复制行实体结构。 请注意,此功能仅适用于水平对齐的行。
- 首先,像往常一样为第一行添加标签。
然后,将指针悬停在表示相应行的父实体上。选择添加更多行。该行将成为用于创建更多行的模板。
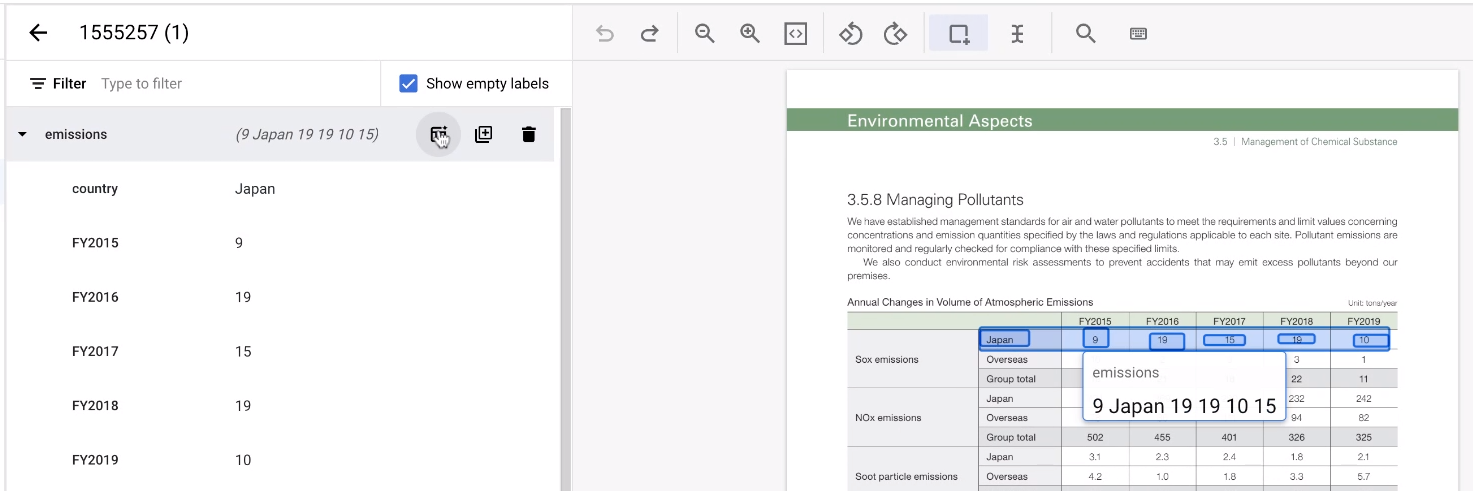
选择表格的其余区域。
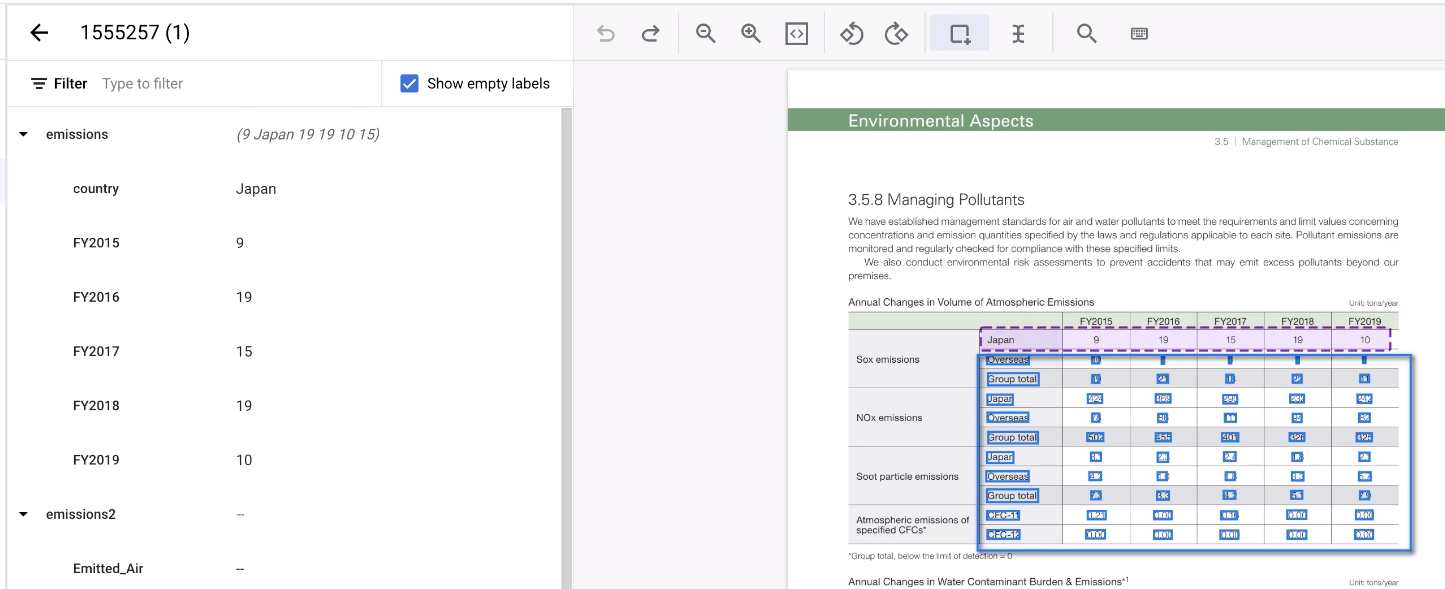
该工具会猜测注释,而且通常能猜对。对于无法处理的任何表格,请手动添加注释。
在控制台中使用键盘快捷键
如需查看可用的键盘快捷键,请选择标记控制台右上角的 菜单。系统会显示键盘快捷键列表,如下表所示。
| 操作 | 快捷键 |
|---|---|
| 放大 | Alt + =(在 macOS 上为 Option + =) |
| 缩小 | Alt + -(在 macOS 上为 Option + -) |
| 缩放至合适大小 | Alt + 0(在 macOS 上为 Option + 0) |
| 滚动即可缩放 | Alt + 滚动(在 macOS 上为 Option + 滚动) |
| 平移 | 滚动 |
| 已撤消的平移 | Shift + 滚动 |
| 拖动进行平移 | 空格键 + 鼠标拖动 |
| 撤消 | Ctrl + Z(在 macOS 上是 Control + Z) |
| 重做 | Ctrl + Shift + Z(在 macOS 上为 Control + Shift + Z) |
自动添加标签
如果您有处理器的现有版本,则可以用它来开始添加标签。
您可以在导入期间启动自动添加标签功能。所有文档都使用指定的处理器版本进行注释。
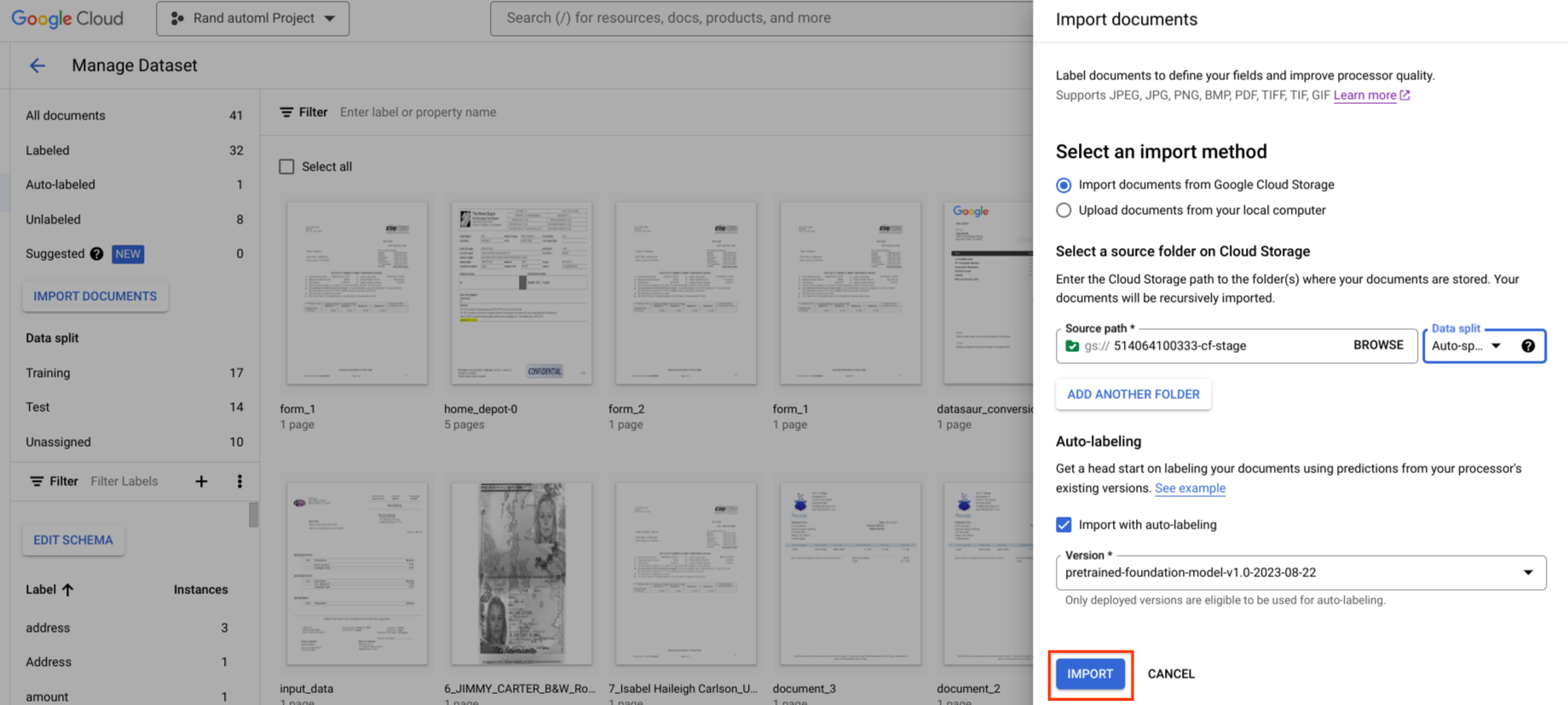
对于未加标签或自动加标签类别中的文档,可以在导入后启动自动加标签功能。所有选定文档均使用指定的处理器版本进行注释。
您不能使用自动加标签的文档进行训练或增量训练,也不能在测试集中使用这些文档,除非将其标记为已加标签。手动检查并更正自动添加的标签注释,然后选择标记为已添加标签以保存更正。然后,您可以根据需要分配文档。
导入预先添加标签的文档
您可以导入 JSON Document 文件。如果文档中的 entity 与处理器架构中的标签匹配,则导入器会将 entity 转换为标签实例。您可以通过多种方式获取 JSON 文档文件:
为文档添加标签的最佳实践
需要一致的标签才能训练出高质量的处理器。我们建议您:
创建标注说明:您的说明应包含常见情形和特殊情形的示例。一些提示:
- 说明应注释哪些字段,以及如何确保标签的一致性。例如,在标记“金额”时,指定是否应标记币种符号。如果标签不一致,处理器质量就会降低。
- 为实体的所有出现情况添加标签,即使标签类型为
REQUIRED_ONCE或OPTIONAL_ONCE也是如此。例如,如果invoice_id在文档中出现两次,请为所有出现的位置添加标签。 - 一般而言,最好先使用默认的边界框工具进行标记。如果失败,请使用文本选择工具。
- 如果 OCR 未正确检测到标签的值,请勿手动更正该值。这样一来,该数据就无法用于训练目的。
以下是一些标签说明示例:
- 培训注释者:确保注释者理解并能遵循准则,不会出现任何系统性错误。实现这一目标的一种方法是让不同的受训者为同一组文档添加注释。然后,训练员可以检查每位受训人员的注解工作质量。您可能需要重复此流程,直到学员达到基准准确度水平。
- 初始审核:新注释者针对某个使用情形标记的前几个(大约 10 个)文档应先经过审核,然后再标记大量文档,以防出现大量需要更正的错误。
- 注解质量审核:鉴于注解工作非常耗时,即使是经过培训的注解者也可能会犯错。我们建议至少再由一位经过训练的注释者检查注释。
添加说明提示
在自定义提取器和自定义分类器中向架构添加标签时,您可以为标签添加说明。这有助于训练处理器,方法是提供一个提示来识别标签。您可以尝试稍加修改以测试回答质量。例如,“总金额”“账单总金额”或“账单的总金额”。
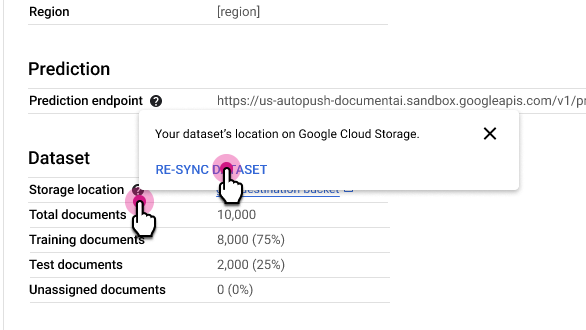
重新同步数据集
重新同步可使数据集的 Cloud Storage 文件夹与 Document AI 的内部元数据索引保持一致。如果您不小心更改了 Cloud Storage 文件夹,并希望同步数据,此功能会非常有用。
如需重新同步,请执行以下操作:
在处理器详细信息标签页中,选择存储位置行旁边的 ,然后选择重新同步数据集。
使用说明:
- 如果您从 Cloud Storage 文件夹中删除文档,重新同步会将其从数据集中移除。
- 如果您向 Cloud Storage 文件夹添加文档,重新同步不会将其添加到数据集。如需添加文档,请导入文档。
- 如果您修改了 Cloud Storage 文件夹中的文档标签,重新同步会更新数据集中的文档标签。
迁移数据集
借助导入和导出功能,您可以将数据集中的所有文档从一个处理器移至另一个处理器。如果您有不同区域或 Google Cloud 项目中的处理器,如果您有用于预演和生产的不同处理器,或者有用于一般离线消费的不同处理器,那么此功能会非常有用。
请注意,系统只会导出文档及其标签。数据集元数据(例如处理器架构、文档分配情况 [训练/测试/未分配] 和文档标签状态 [已加标签、未加标签、自动加标签])不会导出。
复制并导入数据集,然后训练目标处理器的过程与训练源处理器的过程并不完全相同。这是因为在训练过程开始时使用了随机值。使用 importProcessorVersion API 调用在项目之间导入迁移完全相同的模型。如果政策允许,这是将处理器迁移到更高环境(例如从开发环境到预发布环境再到生产环境)的最佳实践。
导出数据集
如需将所有文档以 JSON Document 文件的形式导出到 Cloud Storage 文件夹,请选择导出数据集。
请注意以下几点重要事项:
导出期间,系统会创建三个子文件夹:Test、Train 和 Unassigned。您的文件会相应地放入这些子文件夹中。
不会导出文档的标记状态。如果您稍后导入这些文档,它们将不会被标记为自动标记。
如果您的 Cloud Storage 位于其他 Google Cloud 项目中,请务必授予访问权限,以便 Document AI 可以将文件写入该位置。具体来说,您必须向 Document AI 的核心服务代理
service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com授予 Storage Object Creator 角色。如需了解详情,请参阅服务代理。
导入数据集
该流程与导入文档相同。
选择性添加标签用户指南
选择性标记有助于获得有关标记哪些文档的建议。您可以创建多样化的训练数据集和测试数据集,以训练具有代表性的模型。每次执行选择性标记时,系统都会从数据集中选择最多 30 份最多样化的文档。
获取建议的文档
创建 CDE 处理器并导入文档。
- 训练至少需要 100 个(测试需要 25 个)。
- 导入足够多的文档并进行选择性标记后,信息栏应会显示。
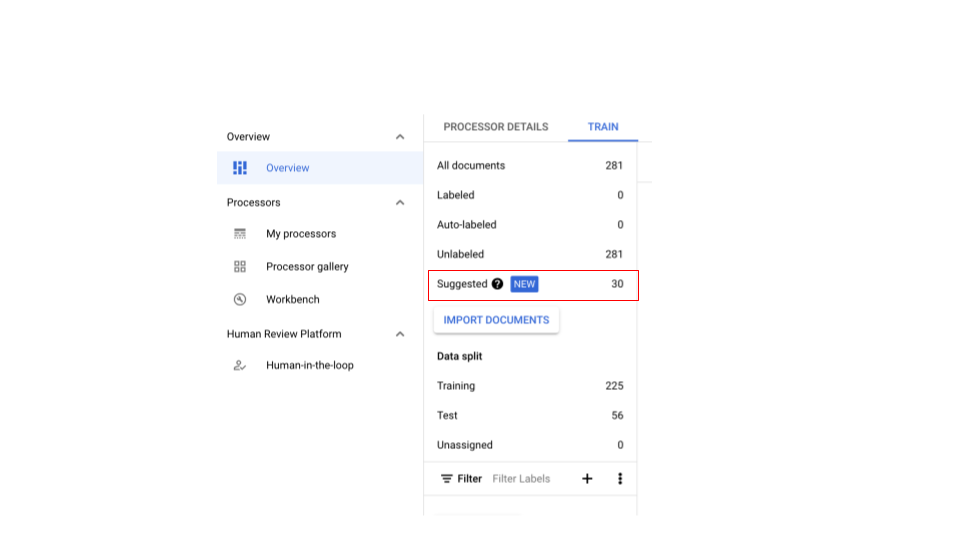
如果 CDE 处理器的建议文档数量为零,请导入更多文档,以便在任一拆分中都有足够的文档用于抽样。
- 此操作应会在建议的类别中启用建议的文档。您应该能够手动请求建议的文档。
- 顶部新增了一个过滤器,用于过滤掉建议的文档。
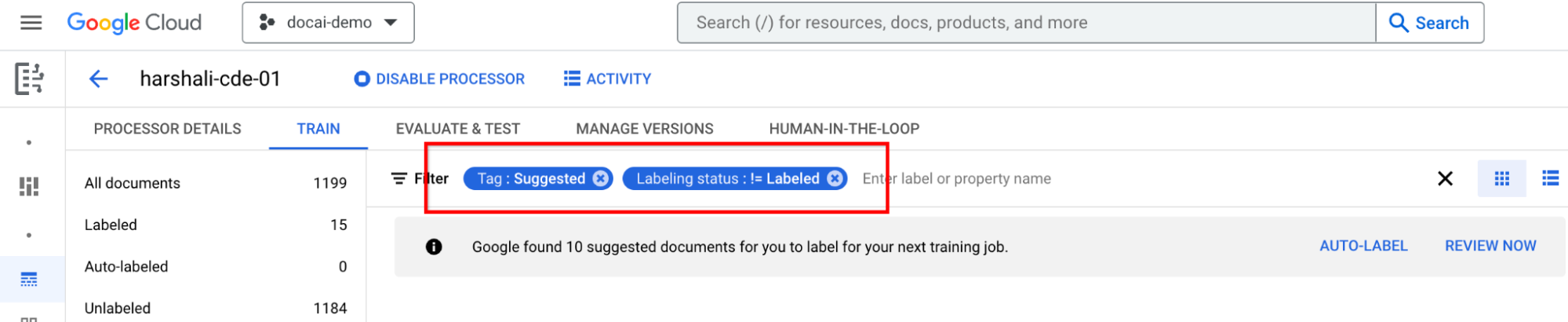
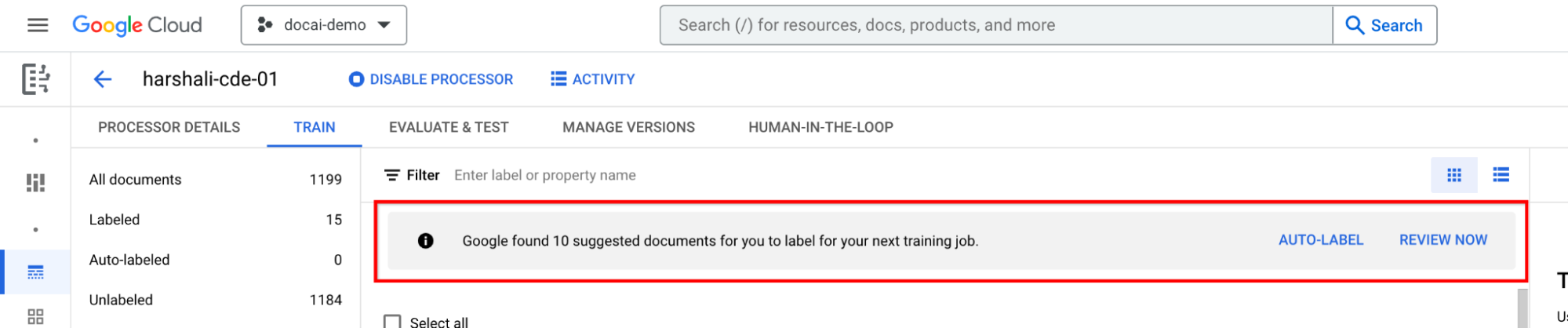
为建议的文档加标签
前往左侧标签列表面板中的建议的类别。开始为这些文档添加标签。
如果处理器已训练,请在信息栏中选择自动标记。 为建议的文档添加标签。
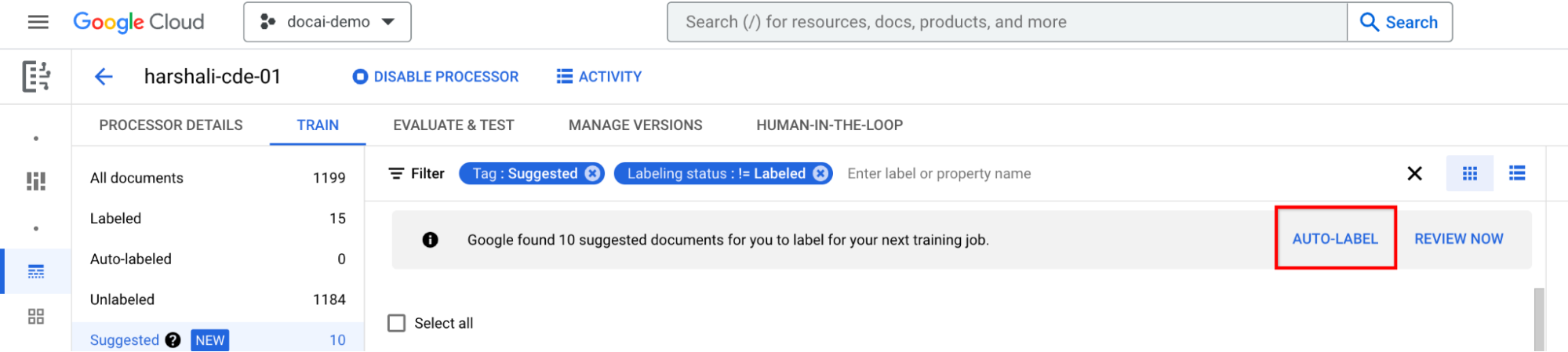
然后,当处理器中出现建议的文档时,您可以选择该栏上的立即查看以导航到该文档。应检查所有自动添加标签的文档,确保其准确无误。开始审核。
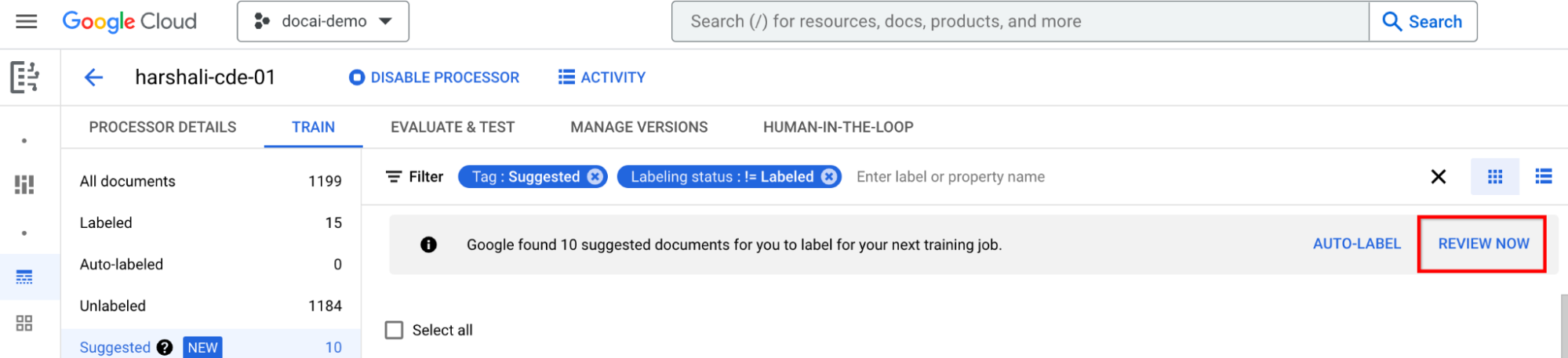
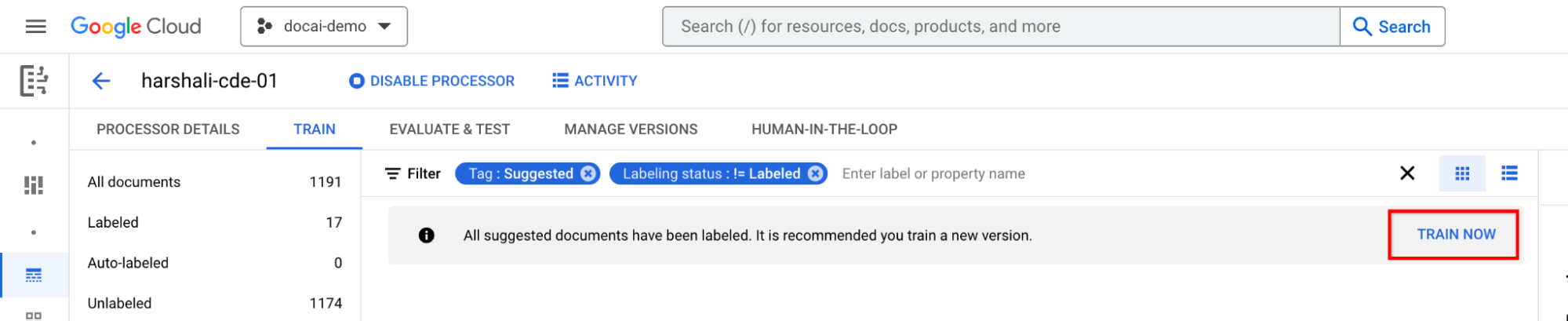
在为所有建议的文档添加标签后进行训练
在信息栏中移动到立即训练。当建议的文档被标记时,您应该会看到以下建议进行训练的信息栏。
支持的功能和限制
| 功能 | 说明 | 支持 |
|---|---|---|
| 支持旧处理器 | 可能无法很好地与之前导入的数据集搭配使用旧处理器 |