必须使用加标签的文档数据集才能训练、追加训练或评估处理器版本。
本页面介绍了如何创建数据集、导入文档以及定义架构。 如需为导入的文档添加标签,请参阅为文档添加标签。
本页面假定您已创建支持训练、追加训练或评估的处理器。如果您的处理器受支持,您会在 Google Cloud 控制台中看到训练标签页。
数据集存储选项
您可以选择以下两种方式来保存数据集:
- 由 Google 管理
- 自定义位置 Cloud Storage
除非您有特殊要求(例如将文档保存在一组启用 CMEK 的文件夹中),否则我们建议您选择更简单的 Google 管理的存储选项。创建数据集后,无法再更改处理器的存储选项。
自定义 Cloud Storage 位置的文件夹或子文件夹必须一开始为空,并且必须被视为严格只读。对其内容进行任何手动更改都可能会导致数据集无法使用,从而导致数据丢失。由 Google 管理的存储空间选项不存在此风险。
请按照以下步骤配置存储位置。
由 Google 管理的存储空间(推荐)
在创建新处理器时显示高级选项。
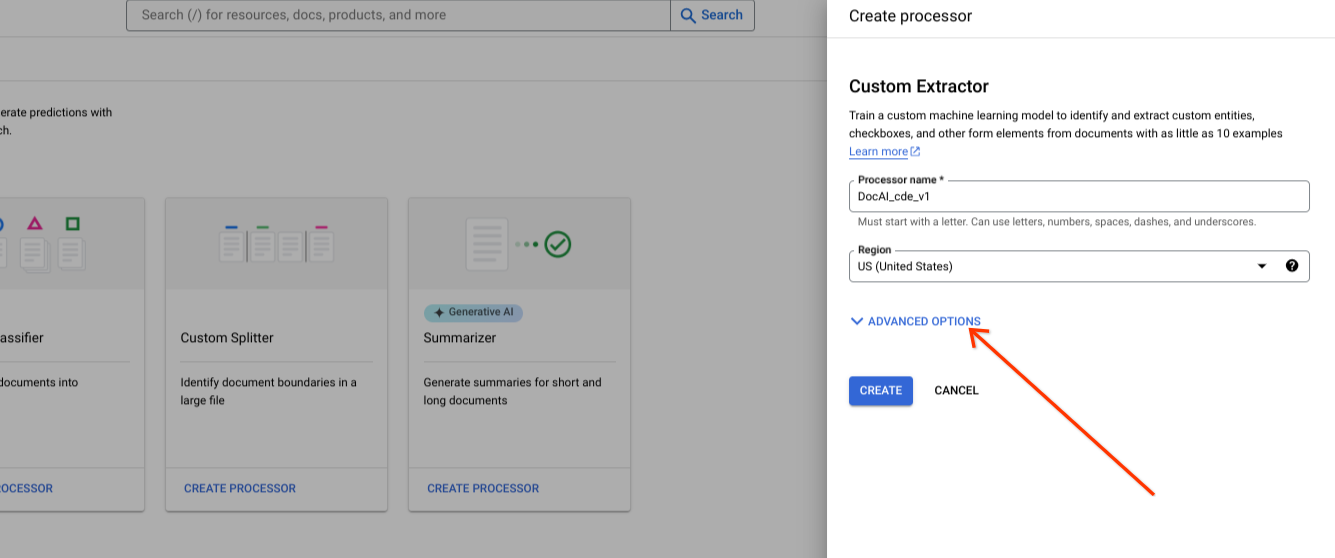
将默认单选组选项保留为 Google 管理的存储空间。
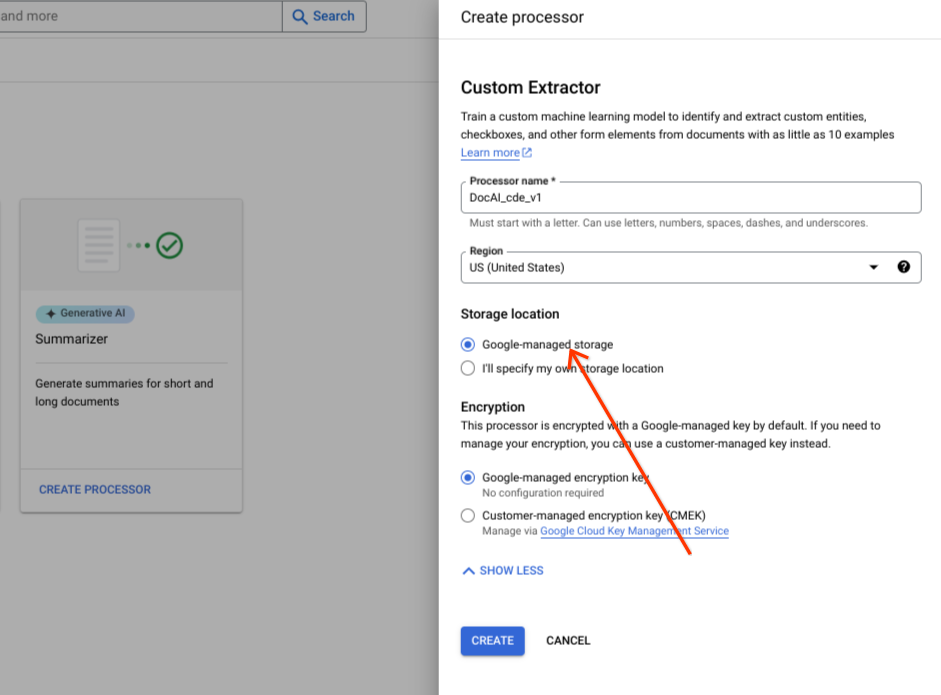
选择创建。
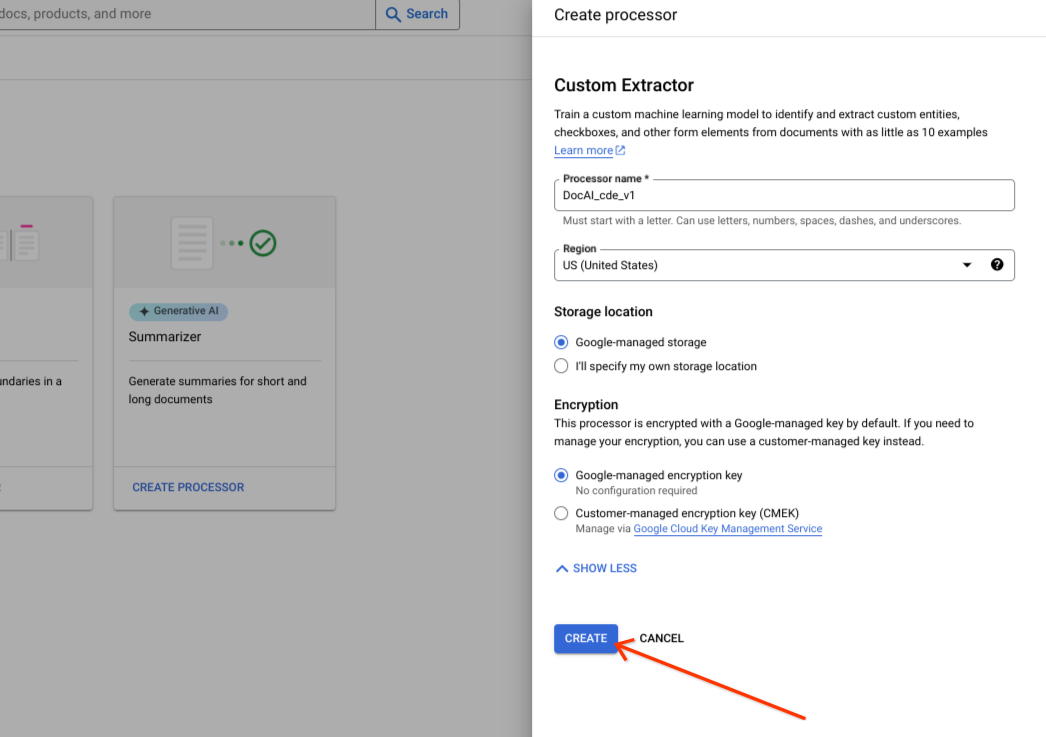
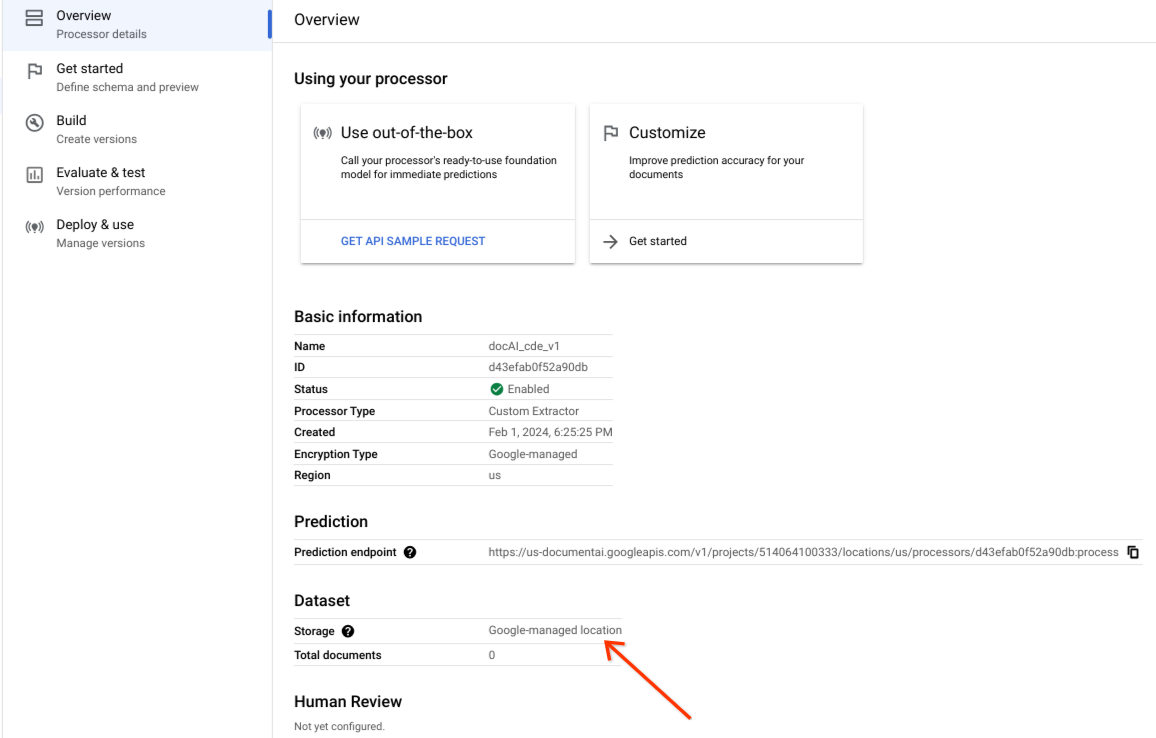
确认数据集已成功创建,并且数据集位置为 Google 管理的位置。
自定义存储选项
开启或关闭高级选项。
选择我将指定自己的存储位置。
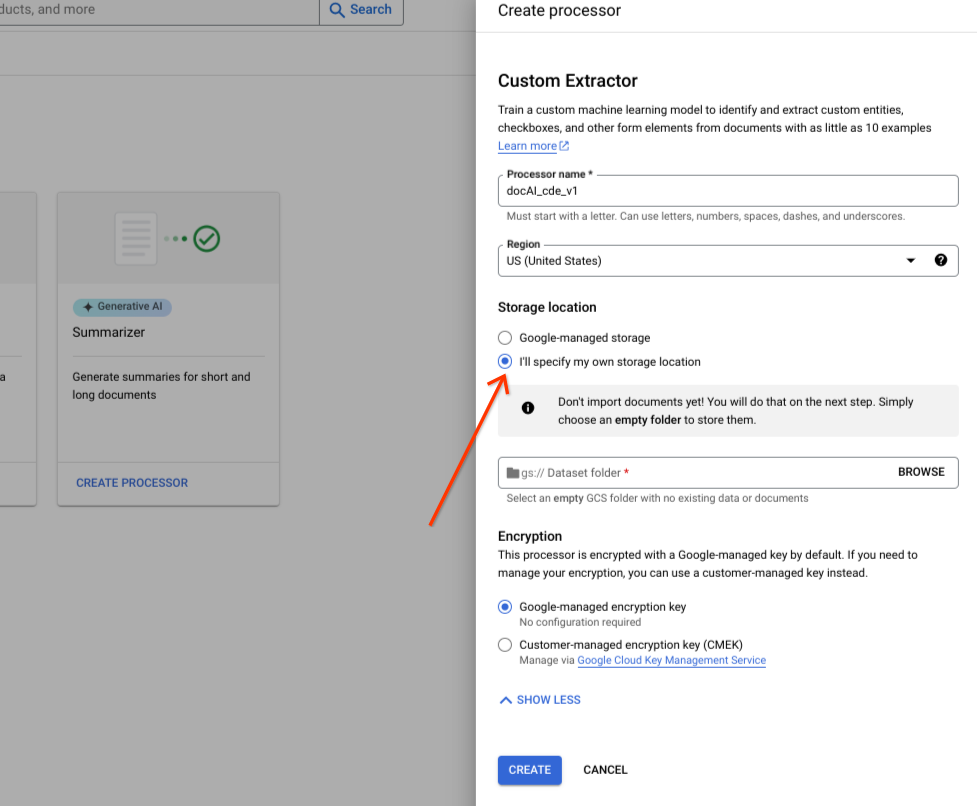
从输入组件中选择 Cloud Storage 文件夹。
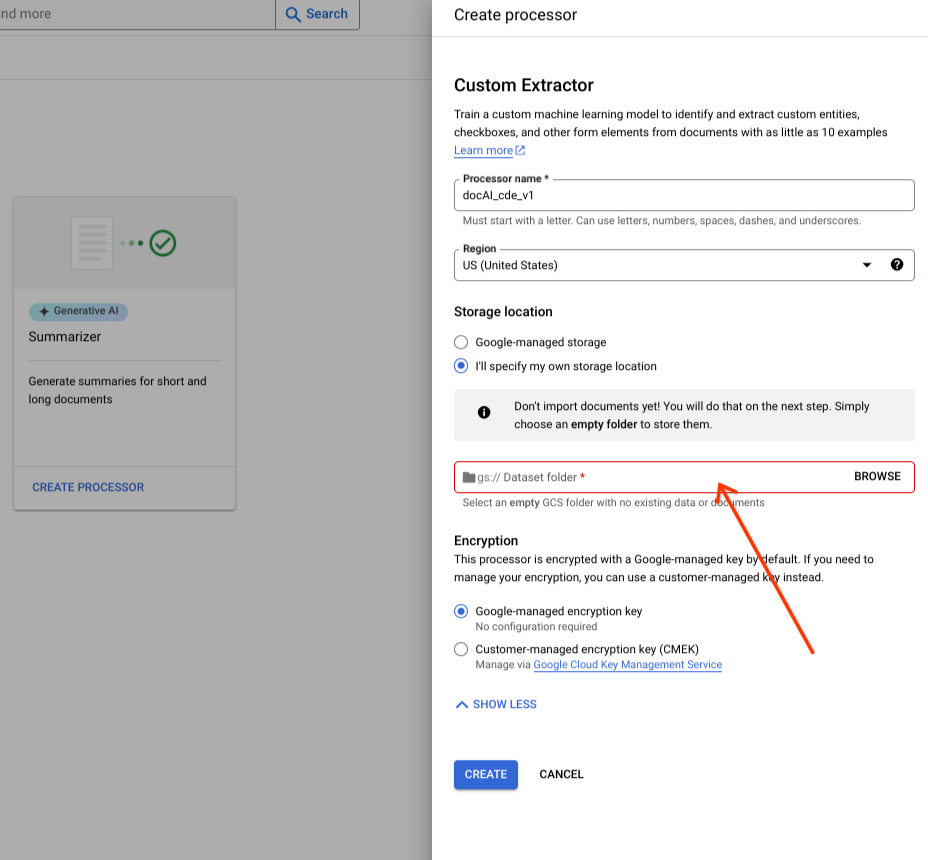
选择创建。
Dataset API 操作
此示例展示了如何使用 processors.updateDataset 方法创建数据集。数据集资源是处理器中的单例资源,这意味着没有创建资源 RPC。您可以改用 updateDataset RPC 来设置偏好设置。Document AI 提供以下选项:将数据集文档存储在您提供的 Cloud Storage 存储桶中,或由 Google 自动管理这些文档。
在使用任何请求数据之前,请先进行以下替换:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
提供的分桶
按照后续步骤操作,使用您提供的 Cloud Storage 存储桶创建数据集请求。
HTTP 方法
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset请求 JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"gcs_managed_config" {
"gcs_prefix" {
"gcs_uri_prefix": "GCS_URI"
}
}
"spanner_indexing_config" {}
}由 Google 管理
如果您想创建由 Google 管理的数据集,请更新以下信息:
HTTP 方法
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset请求 JSON:
{
"name":"projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"
"unmanaged_dataset_config": {}
"spanner_indexing_config": {}
}如需发送请求,您可以使用 Curl:
将请求正文保存在名为 request.json 的文件中。执行以下命令:
CURL
curl -X PATCH \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset"您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}导入文档
新创建的数据集是空的。如需添加文档,请选择导入文档,然后选择一个或多个包含要添加到数据集中的文档的 Cloud Storage 文件夹。
如果您的 Cloud Storage 位于其他 Google Cloud 项目中,请务必授予访问权限,以便 Document AI 可以从该位置读取文件。具体来说,您必须向 Document AI 的核心服务代理 service-{project-id}@gcp-sa-prod-dai-core.iam.gserviceaccount.com 授予 Storage Object Viewer 角色。如需了解详情,请参阅服务代理。
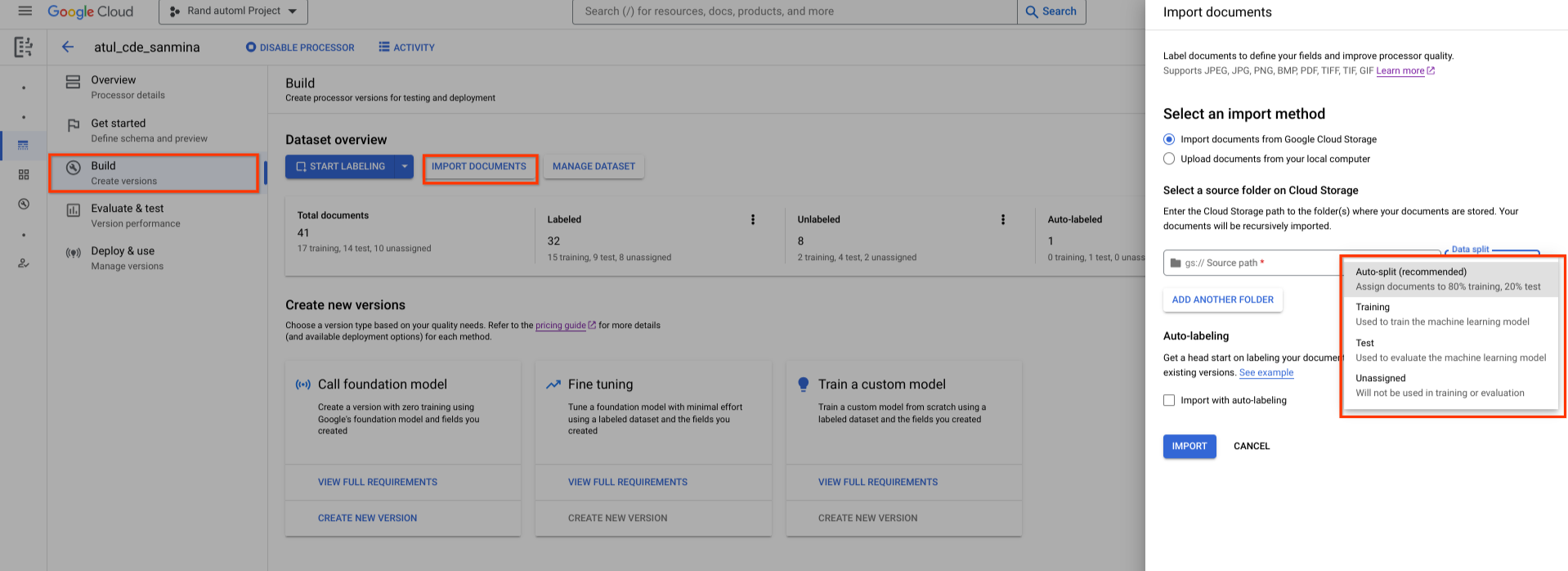
然后,选择以下作业选项之一:
- 训练:分配给训练集。
- 测试:分配给测试集。
- 自动拆分:随机对训练集和测试集中的文档执行 shuffle 操作。
- 未分配:不用于训练或评估。您稍后可以手动分配。
您日后随时可以修改作业。
选择导入后,Document AI 会将所有支持的文件类型以及 JSON Document 文件导入到数据集中。对于 JSON Document 文件,Document AI 会导入文档并将其 entities 转换为标签实例。
Document AI 不会修改导入文件夹,也不会在导入完成后从该文件夹读取数据。
选择页面顶部的活动,打开活动面板,其中列出了成功导入的文件以及导入失败的文件。
如果您已有处理器的现有版本,可以在导入文档对话框中选中使用自动添加标签功能导入复选框。系统会在导入文档时使用之前的处理器自动为文档添加标签。您不能使用自动加标签的文档进行训练或再训练,也不能将其用于测试集,除非将其标记为已加标签。导入自动添加标签的文档后,请手动审核并更正这些文档。然后,选择保存以保存更正并将相应文档标记为已添加标签。然后,您可以根据需要分配文档。请参阅自动添加标签。
导入文档 RPC
此示例展示了如何使用 dataset.importDocuments 方法将文档导入数据集。
在使用任何请求数据之前,请先进行以下替换:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
GCS_URI: Your Cloud Storage URI where dataset documents are stored
DATASET_TYPE: The dataset type to which you want to add documents. The value should be either `DATASET_SPLIT_TRAIN` or `DATASET_SPLIT_TEST`.
TRAINING_SPLIT_RATIO: The ratio of documents which you want to autoassign to the training set.
训练或测试数据集
如果您想向训练数据集或测试数据集添加文档,请执行以下操作:
HTTP 方法
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments请求 JSON:
{
"batch_documents_import_configs": {
"dataset_split": DATASET_TYPE
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": GCS_URI
}
}
}
}训练和测试数据集
如果您想在训练数据集和测试数据集之间自动拆分文档,请执行以下操作:
HTTP 方法
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments请求 JSON:
{
"batch_documents_import_configs": {
"auto_split_config": {
"training_split_ratio": TRAINING_SPLIT_RATIO
},
"batch_input_config": {
"gcs_prefix": {
"gcs_uri_prefix": "gs://test_sbindal/pdfs-1-page/"
}
}
}
}将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/importDocuments"您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}删除文档 RPC
此示例展示了如何使用 dataset.batchDeleteDocuments 方法从数据集中删除文档。
在使用任何请求数据之前,请先进行以下替换:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
DOCUMENT_ID: The document ID blob returned by <code>ImportDocuments</code> request
删除文档
HTTP 方法
POST https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments请求 JSON:
{
"dataset_documents": {
"individual_document_ids": {
"document_ids": DOCUMENT_ID
}
}
}将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/batchDeleteDocuments"您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/locations/LOCATION/operations/OPERATION_ID"
}将文档分配给训练集或测试集
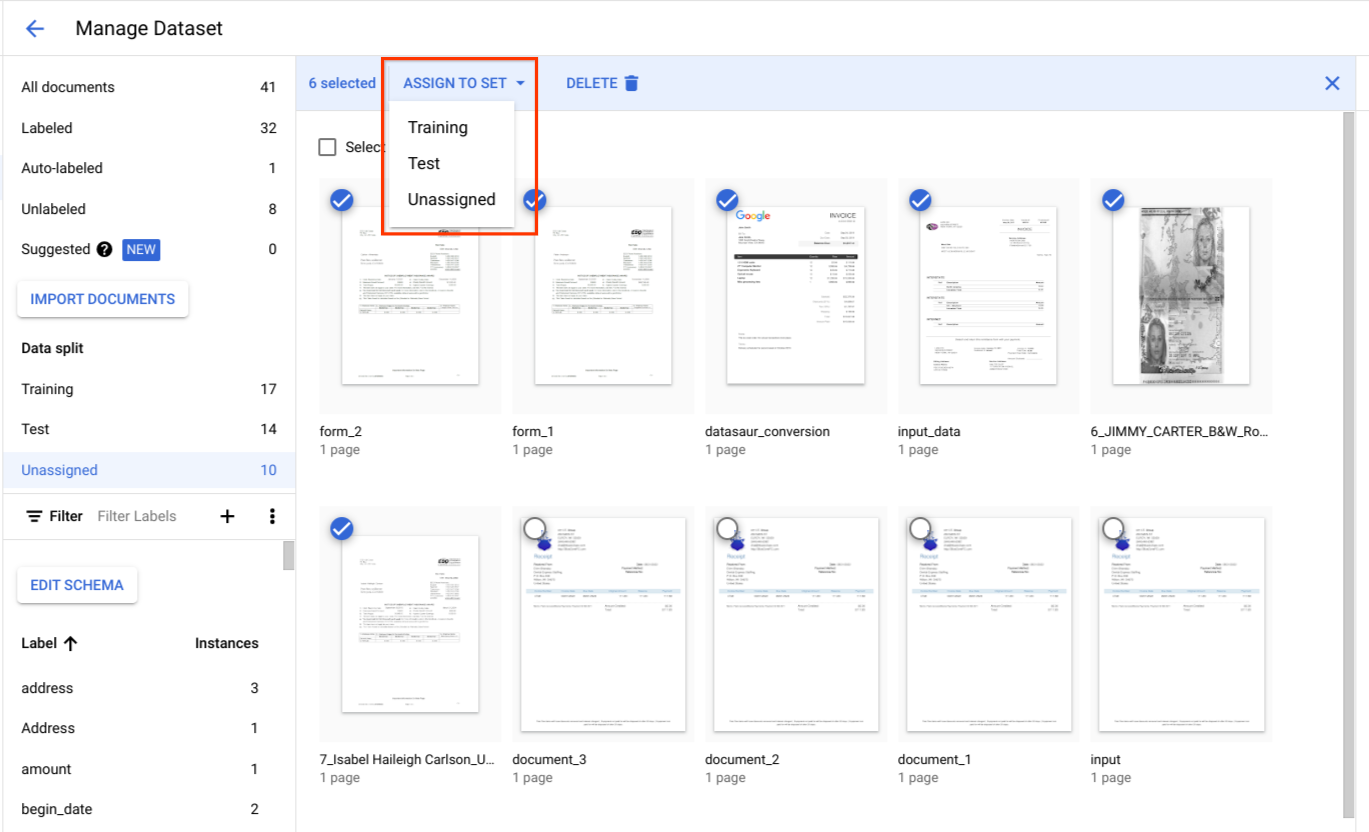
在数据拆分下,选择文档并将其分配给训练集、测试集或未分配。
测试集的最佳实践
测试集的质量决定了评估的质量。
测试集应在处理器开发周期的开始阶段创建并锁定,以便您随时间推移跟踪处理器的质量。
我们建议测试集中的每种文档类型至少包含 100 个文档。务必要确保测试集能代表客户正在为所开发模型使用的文档类型。
测试集在频率方面应能代表生产流量。例如,如果您正在处理 W2 表单,并预计 70% 的表单是 2020 年的,30% 是 2019 年的,那么测试集中应有约 70% 的 W2 表单是 2020 年的文档。这种测试集构成可确保在评估处理器的性能时,为每个文档子类型赋予适当的重要性。此外,如果您要从国际表单中提取人名,请确保您的测试集包含来自所有目标国家/地区的表单。
训练集的最佳实践
已包含在测试集中的任何文档都不应包含在训练集中。
与测试集不同,最终训练集在文档多样性或频率方面不需要严格代表客户使用情况。有些标签比其他标签更难训练。因此,通过使训练集偏向这些标签,您可能会获得更好的性能。
一开始,我们很难确定哪些标签是难的。您应先使用与测试集相同的方法,从随机抽样的小型初始训练集开始。此初始训练集应包含您计划注释的文档总数的 10% 左右。然后,您可以迭代评估处理器质量(寻找特定的错误模式),并添加更多训练数据。
定义处理器架构
创建数据集后,您可以在导入文档之前或之后定义处理器架构。
处理器的 schema 定义了要从文档中提取的标签,例如姓名和地址。
选择修改架构,然后根据需要创建、修改、启用和停用标签。
完成后,请务必选择保存。
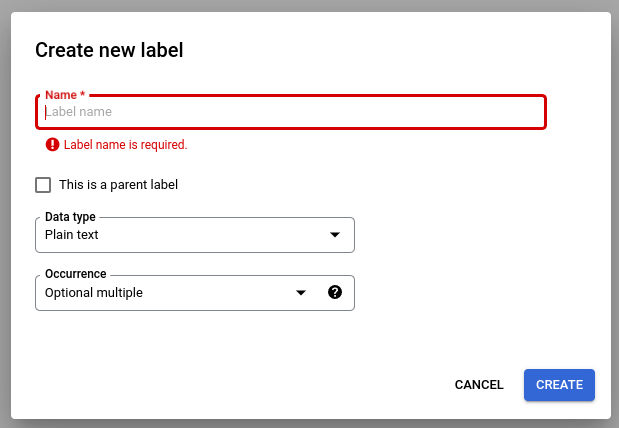
有关架构标签管理的注意事项:
架构标签创建后,其名称便无法修改。
只有在没有经过训练的处理器版本时,才能修改或删除架构标签。只能修改数据类型和出现次数类型。
停用标签也不会影响预测。当您发送处理请求时,处理器版本会提取训练时处于有效状态的所有标签。
获取数据架构
此示例展示了如何使用数据集的 getDatasetSchema 来获取当前架构。DatasetSchema 是一种单例资源,在您创建数据集资源时会自动创建。
在使用任何请求数据之前,请先进行以下替换:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
获取数据架构
HTTP 方法
GET https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchemaCURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"您应该收到类似以下内容的 JSON 响应:
{
"name": "projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema",
"documentSchema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": $LABEL_NAME,
"valueType": $VALUE_TYPE,
"occurrenceType": $OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}更新文档架构
此示例展示了如何使用 dataset.updateDatasetSchema 更新当前架构。此示例展示了用于更新数据集架构以使其包含一个标签的命令。如果您想添加新标签,而不是删除或更新现有标签,则可以先调用 getDatasetSchema,然后在响应中进行适当的更改。
在使用任何请求数据之前,请先进行以下替换:
LOCATION: Your processor location
PROJECT_ID: Your Google Cloud project ID
PROCESSOR_ID: The ID of your custom processor
LABEL_NAME: The label name which you want to add
LABEL_DESCRIPTION: Describe what the label represents
DATA_TYPE: The type of the label. You can specify this as string, number, currency, money, datetime, address, boolean.
OCCURRENCE_TYPE: Describes the number of times this label is expected. Pick an enum value.
更新架构
HTTP 方法
PATCH https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema请求 JSON:
{
"document_schema": {
"entityTypes": [
{
"name": $SCHEMA_NAME,
"baseTypes": [
"document"
],
"properties": [
{
"name": LABEL_NAME,
"description": LABEL_DESCRIPTION,
"valueType": DATA_TYPE,
"occurrenceType": OCCURRENCE_TYPE,
"propertyMetadata": {}
},
],
"entityTypeMetadata": {}
}
]
}
}将请求正文保存在名为 request.json 的文件中,然后执行以下命令:
CURL
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://LOCATION-documentai.googleapis.com/v1beta3/projects/PROJECT_ID/locations/LOCATION/processors/PROCESSOR_ID/dataset/datasetSchema"选择标签属性
数据类型
Plain text:字符串值。Number:一个数字 - 整数或浮点数。Money:货币价值金额。添加标签时,请勿添加币种符号。- 提取实体后,系统会将其规范化为
google.type.Money。
- 提取实体后,系统会将其规范化为
Currency:货币符号。Datetime:日期或时间值。- 提取实体后,系统会将其标准化为
ISO 8601文本格式。
- 提取实体后,系统会将其标准化为
Address- 位置地址。- 提取实体后,系统会使用 EKG 对其进行归一化和丰富。
Checkbox-true或false布尔值。Signature-normalized_value.signature_value中的true或false布尔值,用于指示是否存在签名。它支持derive方法。mention_text-has_signed中的Detected或空""布尔值,用于指示是否存在签名。它支持derive方法。normalized_value.text-has_signed中的Detected或空""布尔值,用于指示是否存在签名。它支持derive方法。- 未填充
normalized_value.boolean_value。
方法
- 当实体为
extracted时,系统会填充textAnchor、type、mentionText和pageAnchor字段。 - 当实体为
derived时,派生值可能不会出现在文档文本中。未填充textAnchor和pageAnchor.pageRefs[].bounding_poly字段。
出现次数
如果实体应始终出现在给定类型的文档中,请选择 REQUIRED。如果没有此类预期,请选择 OPTIONAL。
如果实体应具有一个值,即使同一值在同一文档中多次出现,也请选择 ONCE。如果实体应具有多个值,请选择 MULTIPLE。
父级标签和子级标签
父子标签(也称为表格实体)用于标记表格中的数据。下表包含 3 行和 4 列。

您可以使用父子标签定义此类表。在此示例中,父标签 line-item 定义了表的一行。
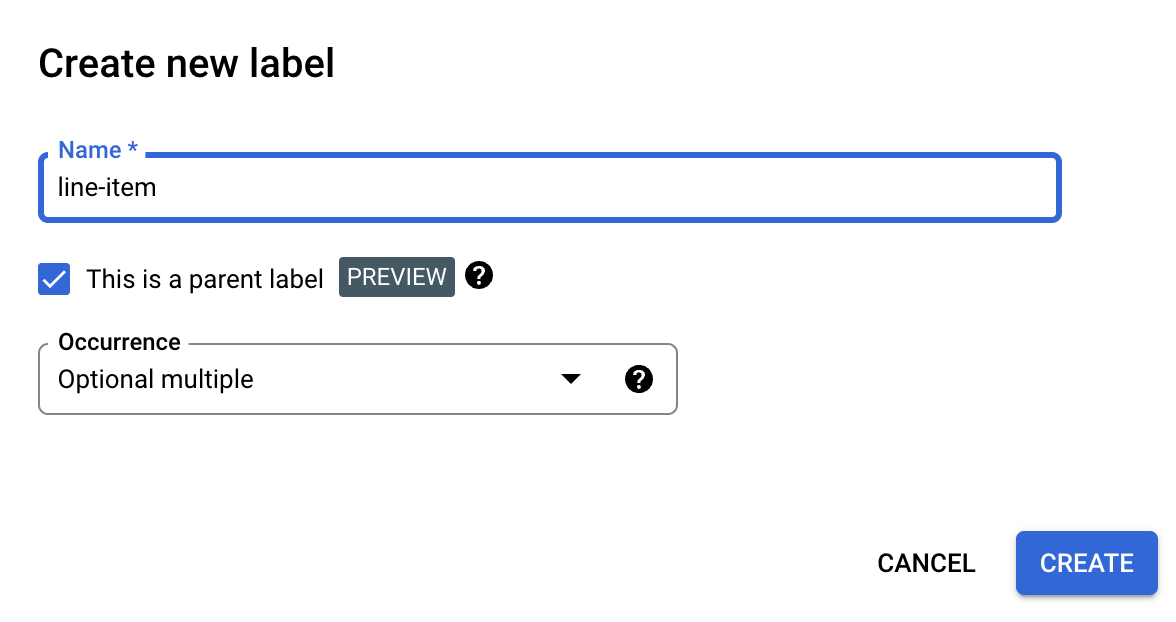
创建父标签
在修改架构页面上,选择创建标签。
选中这是父标签复选框,然后输入其他信息。 父标签必须包含
optional_multiple或require_multiple,以便重复使用该标签来捕获表格中的所有行。选择保存。
父标签会显示在修改架构页面上,旁边会显示添加子标签选项。
创建子标签
在修改架构页面上,选择父标签旁边的添加子标签。
输入子标签的相关信息。
选择保存。
针对您要添加的每个子标签重复上述步骤。
子标签会以缩进形式显示在修改架构页面上的父标签下方。

父子标签是一项预览版功能,仅支持用于表格。 嵌套深度限制为 1,这意味着子实体不能包含其他子实体。
基于带标签的文档创建架构标签
通过导入预先标记的 Document JSON 文件自动创建架构标签。
在 Document 导入过程中,新添加的架构标签会添加到架构编辑器中。选择“修改架构”,以验证或更改新架构标签的数据类型和出现类型。确认后,选择架构标签,然后选择启用。
示例数据集
为了帮助您开始使用 Document AI Workbench,我们提供了一个公共 Cloud Storage 存储桶,其中包含多种文档类型的预先添加标签和未添加标签的示例 Document JSON 文件。
这些数据可用于重新训练或自定义提取器,具体取决于文档类型。
gs://cloud-samples-data/documentai/Custom/
gs://cloud-samples-data/documentai/Custom/1040/
gs://cloud-samples-data/documentai/Custom/Invoices/
gs://cloud-samples-data/documentai/Custom/Patents/
gs://cloud-samples-data/documentai/Custom/Procurement-Splitter/
gs://cloud-samples-data/documentai/Custom/W2-redacted/
gs://cloud-samples-data/documentai/Custom/W2/
gs://cloud-samples-data/documentai/Custom/W9/