Document AI 使用 Enterprise Knowledge Graph 来对实体提取结果(针对受支持的字段)进行归一化和扩充。例如,地址 123 Main St Apt 1 和 123 Main street # 1 可以标准化为同一标准化地址。
对于每个受支持的字段,Document AI 除了返回原始提取字段之外,还会返回 normalizedValue,用于对字面文本进行归一化处理。
此文件包含采用标准化格式的数据,可减少后处理。
大多数数据属于以下类别之一:
- 金额
- 日期
- 时间戳
- 地址
- 布尔值
- 整数
- 浮点数
示例响应
您可以在 entities.normalizedValue 字段中找到丰富后的值,如下面的截断示例所示:
{
"entities": [
{
"textAnchor": {
"textSegments": [ ... ],
"content": "Google Singapore"
},
"type": "employer_name",
"mentionText": "Google Singapore",
"confidence": 0.69933707,
"pageAnchor": {
"pageRefs": [
{
"boundingPoly": {
"normalizedVertices": [ ... ]
}
}
]
},
"id": "9",
"normalizedValue": {
"text": "Google Asia Pacific, Singapore"
}
}
]
}
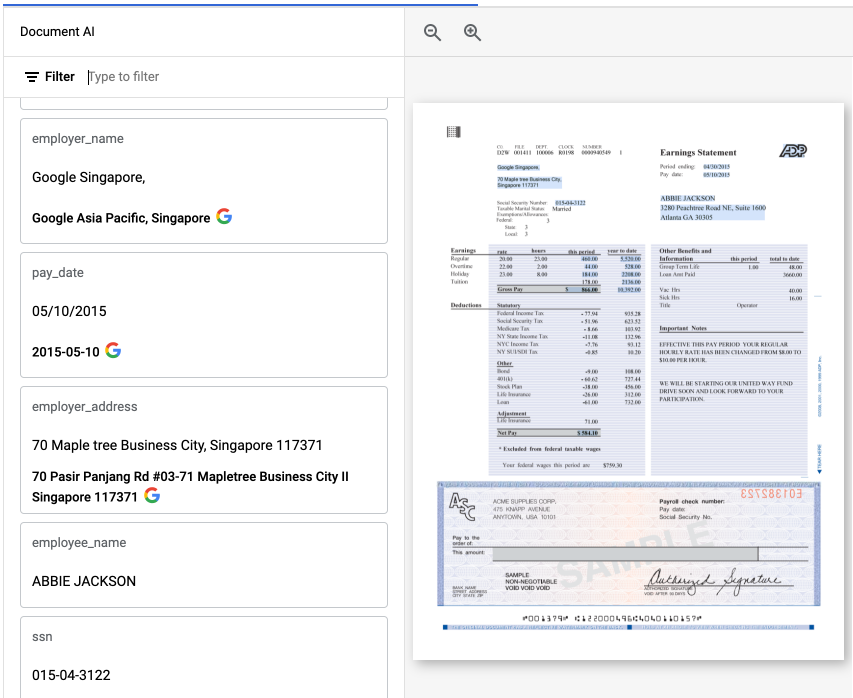
在示例中,原始 employer_name“Google 新加坡”已归一化为“Google 亚太地区,新加坡”。
在 Google Cloud 控制台中,经过丰富和归一化的字段会带有 G 注释。例如:
支持的处理器
以下是支持实体丰富功能的处理器和字段。
| 处理器 | 扩展字段 | ||||||||||||
|---|---|---|---|---|---|---|---|---|---|---|---|---|---|
银行对账单解析器
|
|
||||||||||||
W2 解析器
|
|
||||||||||||
工资单解析器
|
|
||||||||||||
Expense Parser
|
|
||||||||||||
账单解析器
|
|