Viele Organisationen stellen Cloud Data Warehouses zum Speichern vertraulicher Informationen bereit, damit sie die Daten für verschiedene geschäftliche Zwecke analysieren können. In diesem Dokument wird beschrieben, wie Sie das vom Enterprise Data Management Council verwaltete CDMC Key Controls Framework (Cloud Data Management Capabilities) in einem BigQuery-Data-Warehouse implementieren können.
Das CDMC Key Controls Framework wurde hauptsächlich für Cloud-Dienstanbieter und Technologieanbieter veröffentlicht. Das Framework beschreibt 14 Schlüsselkontrollen, die Anbieter implementieren können, damit ihre Kunden vertrauliche Daten in der Cloud effektiv verwalten und steuern können. Die Kontrollen wurden von der CDMC Working Group geschrieben, an der mehr als 300 Fachleute aus 100 Unternehmen beteiligt sind. Beim Erstellen des Frameworks hat die CDMC-Working Group viele der rechtlichen und behördlichen Anforderungen berücksichtigt.
Diese BigQuery- und Data Catalog-Referenzarchitektur wurde hinsichtlich des CDMC Key Controls Framework als CDMC Certified Cloud Solution bewertet und zertifiziert. In der Referenzarchitektur werden verschiedene Google Cloud -Dienste und ‑Funktionen sowie öffentliche Bibliotheken verwendet, um die CDMC-Schlüsselkontrollen und die empfohlene Automatisierung zu implementieren. In diesem Dokument wird erläutert, wie Sie die Schlüsselkontrollen implementieren, um vertrauliche Daten in einem BigQuery-Data-Warehouse zu schützen.
Architektur
Die folgende Google Cloud Referenzarchitektur entspricht den Testspezifikationen des CDMC Key Controls Framework v1.1.1. Die Zahlen im Diagramm stellen die Schlüsselkontrollen dar, die mit Google Cloud -Diensten behandelt werden.

Die Referenzarchitektur baut auf dem gesicherten Data-Warehouse-Blueprint auf, der eine Architektur zum Schutz eines BigQuery-Data-Warehouse mit vertraulichen Informationen bereitstellt. Im obigen Diagramm sind Projekte oben im Diagramm (grau) Teil des gesicherten Data-Warehouse-Blueprints und das Data-Governance-Projekt (blau) enthält die Dienste, die hinzugefügt werden, um die Anforderungen des CDMC Key Controls Framework zu erfüllen. Die Architektur erweitert das Data-Governance-Projekt, um das CDMC Key Controls Framework zu implementieren. Das Data-Governance-Projekt bietet Kontrollen wie Klassifizierung, Lebenszyklusverwaltung und Datenqualitätsmanagement. Das Projekt bietet auch eine Möglichkeit, die Architektur zu prüfen und Berichte zu Ergebnissen zu erstellen.
Weitere Informationen zur Implementierung dieser Referenzarchitektur finden Sie in der Google Cloud CDMC-Referenzarchitektur auf GitHub.
Übersicht über das CDMC Key Controls Framework
In der folgenden Tabelle ist das CDMC Key Controls Framework zusammengefasst.
| # | CDMC-Schlüsselkontrolle | CDMC-Kontrollanforderung |
|---|---|---|
| 1 | Compliance mit der Datenkontrolle | Cloud-Datenverwaltungs-Geschäftsfälle werden definiert und gesteuert. Alle Daten-Assets, die vertrauliche Daten enthalten, müssen mithilfe von Messwerten und automatisierten Benachrichtigungen auf die Compliance mit den CDMC-Schlüsselkontrollen überwacht werden. |
| 2 | Dateninhaberschaft wird sowohl für migrierte als auch für in der Cloud generierte Daten eingerichtet | Das Feld Inhaberschaft in einem Datenkatalog muss für alle vertraulichen Daten gefüllt oder anderweitig an einen definierten Workflow gemeldet werden. |
| 3 | Datenbeschaffung und -nutzung werden durch Automatisierung gesteuert und unterstützt | Für alle Daten-Assets, die vertrauliche Daten enthalten, muss ein Register mit autoritativen Datenquellen und Bereitstellungspunkten ausgefüllt werden. Andernfalls müssen sie einem definierten Workflow gemeldet werden. |
| 4 | Datenhoheit und grenzüberschreitende Datenübertragungen werden verwaltet | Die Datenhoheit und die grenzüberschreitende Übertragung vertraulicher Daten müssen gemäß der definierten Richtlinie aufgezeichnet, geprüft und gesteuert werden. |
| 5 | Datenkataloge werden implementiert und verwendet und sind interoperabel | Die Katalogisierung muss für alle Daten zum Zeitpunkt der Erstellung oder Aufnahme in allen Umgebungen konsistent automatisiert sein. |
| 6 | Datenklassifizierungen werden definiert und verwendet | Die Klassifizierung muss für alle Daten zum Zeitpunkt der Erstellung oder Aufnahme automatisiert und immer aktiviert sein. Die Klassifizierung ist für Folgendes automatisiert:
|
| 7 | Datenberechtigungen werden verwaltet, erzwungen und nachverfolgt | Für diese Kontrolle ist Folgendes erforderlich:
|
| 8 | Zugriff, Verwendung und Ergebnisse von Daten nach ethischen Maßstäben werden verwaltet | Der Zweck der Datennutzung muss für alle Datenfreigabevereinbarungen zu vertraulichen Daten angegeben werden. Der Zweck muss die erforderlichen Datentypen und – für globale Organisationen – den Geltungsbereich in Bezug auf Land oder Rechtspersönlichkeit angeben. |
| 9 | Daten werden gesichert und Kontrollen werden nachgewiesen | Für diese Kontrolle ist Folgendes erforderlich:
|
| 10 | Ein Datenschutz-Framework ist definiert und betriebsbereit | Datenschutz-Folgenabschätzungen (DSFAs) müssen automatisch für alle personenbezogenen Daten gemäß der jeweiligen Rechtsprechung ausgelöst werden. |
| 11 | Der Datenlebenszyklus wird geplant und verwaltet | Datenaufbewahrung, -archivierung und -löschung müssen nach einem festgelegten Aufbewahrungsplan verwaltet werden. |
| 12 | Datenqualität wird verwaltet | Die Messung der Datenqualität muss für vertrauliche Daten mit verfügbaren Messwerten aktiviert werden. |
| 13 | Die Grundsätze des Kostenverwaltung werden festgelegt und angewendet | Technische Designprinzipien werden festgelegt und angewendet. Kostenmesswerte, die direkt mit der Datennutzung, -speicherung und -übertragung verknüpft sind, müssen im Katalog verfügbar sein. |
| 14 | Datenherkunft wird verstanden | Informationen zur Herkunft von Daten müssen für alle vertraulichen Daten verfügbar sein. Diese Informationen müssen mindestens die Quelle enthalten, aus der die Daten aufgenommen wurden oder in der sie in einer Cloud-Umgebung erstellt wurden. |
1. Compliance mit der Datenkontrolle
Bei dieser Kontrolle müssen Sie prüfen, ob alle vertraulichen Daten mithilfe von Messwerten auf die Compliance mit diesem Framework überwacht werden.
Die Architektur verwendet Messwerte, die angeben, inwieweit die einzelnen Schlüsselontrollen betriebsbereit sind. Die Architektur enthält auch Dashboards, die angeben, wenn die Messwerte nicht die definierten Grenzwerte erfüllen.
Die Architektur enthält Detektoren, die Ergebnisse und Abhilfeempfehlungen veröffentlichen, wenn Daten-Assets die Anforderungen einer Schlüsselkontrolle nicht erfüllen. Diese Ergebnisse und Empfehlungen liegen im JSON-Format vor und werden in einem Pub/Sub-Thema veröffentlicht, um an Abonnenten verteilt zu werden. Sie können Ihre internen Service-Desk- oder Service-Management-Tools in das Pub/Sub-Thema einbinden, damit Vorfälle automatisch in Ihrem Ticketsystem erstellt werden.
Die Architektur verwendet Dataflow, um einen Beispielabonnenten für die Ergebnisereignisse zu erstellen, die dann in einer BigQuery-Instanz gespeichert werden, die im Data-Governance-Projekt ausgeführt wird. Mit einer Reihe von bereitgestellten Ansichten können Sie die Daten mit BigQuery Studio in der Google Cloud -Konsole abfragen. Sie können Berichte auch mit Looker Studio oder anderen BigQuery-kompatiblen Business-Intelligence-Tools erstellen. Die Berichte sind verfügbar:
- Zusammenfassung der Ergebnisse der letzten Ausführung
- Details zu den Ergebnissen der letzten Ausführung
- Metadaten der letzten Ausführung
- Daten-Assets der letzten Ausführung im Geltungsbereich
- Dataset-Statistiken zur letzten Ausführung
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Pub/Sub veröffentlicht Ergebnisse.
- Dataflow lädt die Ergebnisse in eine BigQuery-Instanz.
- BigQuery speichert die Ergebnisdaten und bietet zusammenfassende Ansichten.
- Looker Studio bietet Dashboards und Berichte.
Der folgende Screenshot zeigt ein Beispiel für ein Zusammenfassungs-Dashboard in Looker Studio.
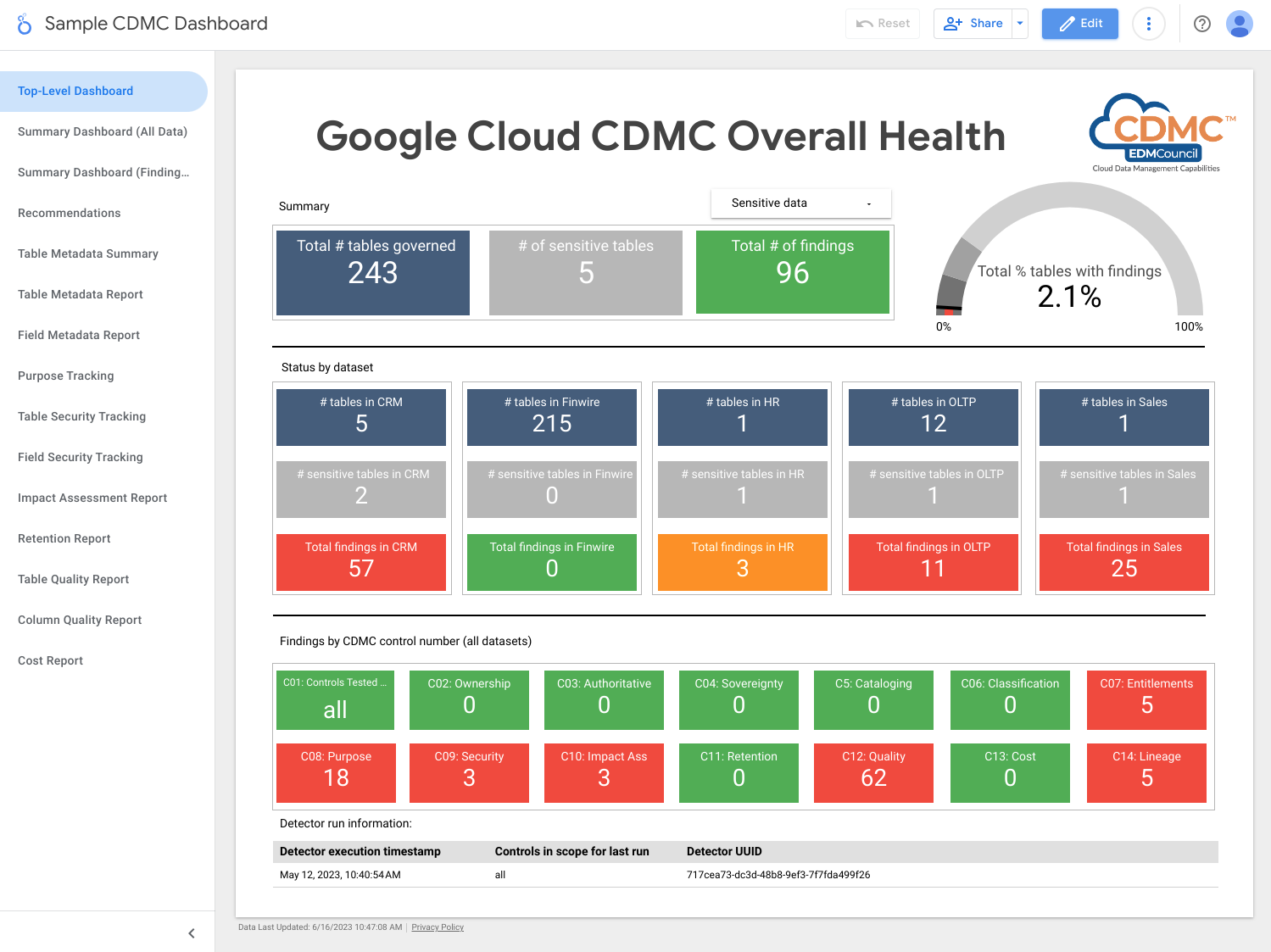
Der folgende Screenshot zeigt eine Beispielansicht für Ergebnisse nach Daten-Asset.
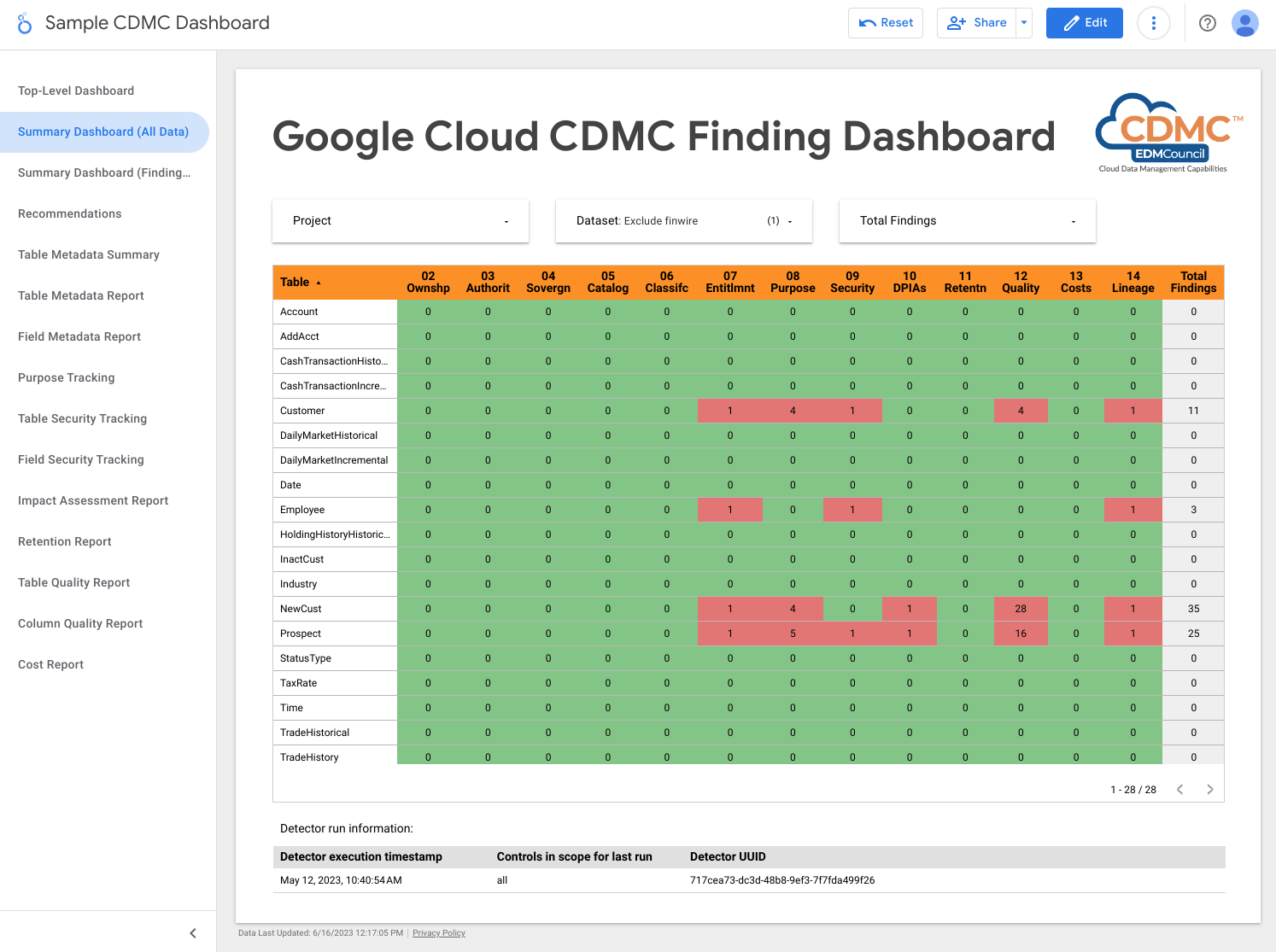
2. Dateninhaberschaft wird sowohl für migrierte als auch für in der Cloud generierte Daten eingerichtet
Zur Erfüllung der Anforderungen dieser Kontrolle prüft die Architektur automatisch die Daten im BigQuery-Data-Warehouse und fügt Datenklassifizierungs-Tags hinzu, die angeben, dass Inhaber für alle vertraulichen Daten identifiziert wurden.
Data Catalog verarbeitet zwei Arten von Metadaten: technische Metadaten und geschäftliche Metadaten. Für ein bestimmtes Projekt katalogisiert Data Catalog automatisch BigQuery-Datasets, -Tabellen und -Ansichten und füllt die technischen Metadaten aus. Die Synchronisierung zwischen Katalog und Daten-Assets erfolgt nahezu in Echtzeit.
Die Architektur verwendet Tag Engine, um einer CDMC controls-Tag-Vorlage in Data Catalog die folgenden geschäftlichen Metadaten-Tags hinzuzufügen:
is_sensitive: gibt an, ob das Daten-Asset vertrauliche Daten enthält (siehe Kontrolle 6 zur Datenklassifizierung)owner_name: der Inhaber der Datenowner_email: die E-Mail-Adresse des Inhabers
Die Tags werden mithilfe von Standardeinstellungen gefüllt, die in einer BigQuery-Referenztabelle im Data-Governance-Projekt gespeichert sind.
Standardmäßig legt die Architektur die Inhabermetadaten auf Tabellenebene fest. Sie können diese Architektur jedoch so ändern, dass die Metadaten auf der Spaltenebene festgelegt werden. Weitere Informationen finden Sie unter Data Catalog-Tags und Tag-Vorlagen.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten und das andere die Standardeinstellungen für die Inhaberschaft von Daten-Assets.
- Data Catalog speichert Inhaberschafts-Metadaten über Tag-Vorlagen und Tags.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Die Architektur prüft, ob vertraulichen Daten ein Inhabernamens-Tag zugewiesen ist, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen.
3. Datenbeschaffung und -nutzung werden durch Automatisierung gesteuert und unterstützt
Diese Kontrolle erfordert eine Klassifizierung von Daten-Assets und ein Datenregister von autoritativen Quellen und autorisierten Distributoren. Die Architektur verwendet Data Catalog, um das Tag is_authoritative der Tag-Vorlage CDMC
controls hinzuzufügen. Dieses Tag definiert, ob das Daten-Asset autoritativ ist.
Data Catalog katalogisiert BigQuery-Datasets, -Tabellen und -Ansichten mit technischen und geschäftlichen Metadaten. Technische Metadaten werden automatisch ausgefüllt und enthalten die Ressourcen-URL, also den Ort des Bereitstellungspunkts. Geschäftliche Metadaten sind in der Tag Engine-Konfigurationsdatei definiert und enthalten das Tag is_authoritative.
Bei der nächsten geplanten Ausführung füllt Tag Engine das Tag is_authoritative in der Tag-Vorlage CDMC controls mit Standardwerten, die in einer Referenztabelle in BigQuery gespeichert sind.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten und das andere die Standardeinstellungen für die autoritative Datenquelle.
- Data Catalog speichert autoritative Quellmetadaten über Tags.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Zur Erkennung von Problemen im Zusammenhang mit dieser Kontrolle prüft die Architektur, ob vertraulichen Daten das autoritativen Quell-Tag zugewiesen ist.
4. Datenhoheit und grenzüberschreitende Datenübertragungen werden verwaltet
Bei dieser Kontrolle muss die Architektur die Daten-Registry auf regionsspezifische Speicheranforderungen prüfen und Nutzungsregeln erzwingen. In einem Bericht wird der geografische Standort von Daten-Assets beschrieben.
Die Architektur verwendet Data Catalog, um das Tag approved_storage_location der Tag-Vorlage CDMC controls hinzuzufügen. Mit diesem Tag wird der geografische Standort definiert, an dem das Daten-Asset gespeichert werden darf.
Der tatsächliche Speicherort der Daten wird als technische Metadaten in den BigQuery-Tabellendetails gespeichert. Mit BigQuery können Administratoren den Speicherort eines Datasets oder einer Tabelle nicht ändern. Wenn Administratoren den Speicherort der Daten ändern möchten, müssen sie stattdessen das Dataset kopieren.
Die Einschränkung der Ressourcenstandorte durch den Organisationsrichtliniendienst definiert die Google Cloud Regionen, in denen Sie Daten speichern können. Standardmäßig legt die Architektur die Einschränkung für das Projekt mit vertraulichen Daten fest, aber Sie können die Einschränkung auf Organisations- oder Ordnerebene festlegen, wenn Sie dies bevorzugen. Tag Engine repliziert die zulässigen Speicherorte in der Data Catalog-Tag-Vorlage und speichert den Speicherort im Tag approved_storage_location. Wenn Sie die Premium-Stufe von Security Command Center aktivieren und jemand die Einschränkung der Ressourcenstandorte durch den Organisationsrichtliniendienst aktualisiert, generiert Security Command Center Sicherheitslückenergebnisse für Ressourcen, die außerhalb der aktualisierten Richtlinie gespeichert sind.
Access Context Manager definiert den geografischen Standort, an dem sich Nutzer befinden müssen, bevor sie auf Daten-Assets zugreifen können. Mit Zugriffsebenen können Sie angeben, aus welchen Regionen die Anfragen stammen dürfen. Anschließend fügen Sie die Zugriffsrichtlinie dem VPC Service Controls-Perimeter für das Projekt mit vertraulichen Daten hinzu.
BigQuery hat für jeden Job und jede Abfrage jedes Datasets einen vollständigen Audit-Trail, um die Datenübertragung zu verfolgen. Der Audit-Trail wird in der Ansicht INFORMATION_SCHEMA.JOBS von BigQuery gespeichert.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Der Organisationsrichtliniendienst definiert und erzwingt die Einschränkung der Ressourcenstandorte.
- Mit Access Context Manager werden die Standorte definiert, von denen Nutzer auf Daten zugreifen können.
- Zwei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten und das andere hostet eine Remote-Funktion, mit der die Standortrichtlinie geprüft wird.
- Data Catalog speichert genehmigte Speicherorte als Tags.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
- Cloud Logging schreibt die Audit-Logs.
- Security Command Center meldet alle Ergebnisse, die sich auf den Ressourcenstandort oder den Datenzugriff beziehen.
Um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen, enthält die Architektur ein Ergebnis darüber, ob das genehmigte Standort-Tag den Standort der vertraulichen Daten enthält.
5. Datenkataloge werden implementiert und verwendet und sind interoperabel
Für diese Kontrolle ist ein Datenkatalog erforderlich. Die Architektur kann neue und aktualisierte Assets scannen, um bei Bedarf Metadaten hinzuzufügen.
Die Architektur verwendet Data Catalog, um die Anforderungen dieser Kontrolle zu erfüllen. Data Catalog protokolliert automatischGoogle Cloud -Assets, einschließlich BigQuery-Datasets, -Tabellen und -Ansichten. Wenn Sie eine neue Tabelle in BigQuery erstellen, werden von Data Catalog automatisch die technischen Metadaten und das Schema der neuen Tabelle registriert. Wenn Sie eine Tabelle in BigQuery aktualisieren, aktualisiert Data Catalog die Einträge fast sofort.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei BigQuery-Data-Warehouses: In einem sind die vertraulichen Daten gespeichert, im anderen die nicht vertraulichen Daten.
- Data Catalog speichert die technischen Metadaten für Tabellen und Felder.
In dieser Architektur speichert Data Catalog standardmäßig technische Metadaten aus BigQuery. Bei Bedarf können Sie Data Catalog in andere Datenquellen einbinden.
6. Datenklassifizierungen werden definiert und verwendet
Bei dieser Bewertung müssen Daten anhand ihrer Vertraulichkeit klassifiziert werden können, z. B. ob es sich bei ihnen um personenidentifizierbare Informationen handelt, ob sie Clients identifizieren oder ob sie sonstige von Ihrer Organisation definierte Standards erfüllen. Die Architektur erstellt einen Bericht über Daten-Assets und ihre Vertraulichkeit, um die Anforderungen dieser Kontrolle zu erfüllen. Mit diesem Bericht können Sie prüfen, ob die Einstellungen für die Vertraulichkeit korrekt sind. Darüber hinaus führt jede neue Datenressource oder Änderung an einem vorhandenen Daten-Asset zu einer Aktualisierung des Datenkatalogs.
Klassifizierungen werden im Tag sensitive_category in der Data Catalog-Tag-Vorlage auf Tabellen- und auf Spaltenebene gespeichert. Mit einer Klassifizierungsreferenztabelle können Sie die verfügbaren Sensitive Data Protection-Informationstypen (infoTypes) einstufen, wobei vertraulichere Inhalte ein höheres Ranking erhalten.
Zur Erfüllung der Anforderungen dieser Einstellung verwendet die Architektur Sensitive Data Protection, Data Catalog und Tag Engine, um vertraulichen Spalten in BigQuery-Tabellen die folgenden Tags hinzuzufügen:
is_sensitive: gibt an, ob das Daten-Asset vertrauliche Informationen enthältsensitive_category: eine der folgenden Datenkategorien:- Vertrauliche personenidentifizierbare Informationen
- Personenidentifizierbare Informationen
- Vertrauliche personenbezogene Daten
- Personenbezogene Daten
- Öffentliche Informationen
Sie können die Datenkategorien entsprechend Ihren Anforderungen ändern. Sie können beispielsweise die MNPI-Klassifizierung (Material Non-Public Information) hinzufügen.
Nachdem Sensitive Data Protection die Daten geprüft hat, liest Tag Engine die DLP results-Tabellen pro Asset, um die Ergebnisse zu kompilieren. Wenn eine Tabelle Spalten mit einem oder mehreren vertraulichen infoTypes enthält, wird der wichtigste infoType ermittelt. Sowohl die vertraulichen Spalten als auch die gesamte Tabelle werden als die Kategorie mit dem höchsten Rang getaggt. Tag Engine weist der Spalte auch ein entsprechendes Richtlinien-Tag zu und weist der Tabelle das boolesche Tag is_sensitive zu.
Sie können Cloud Scheduler verwenden, um die Sensitive Data Protection-Prüfung zu automatisieren.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Vier BigQuery-Data-Warehouses speichern folgende Informationen:
- Vertrauliche Daten
- Informationen zu den Sensitive Data Protection-Ergebnissen
- Referenzdaten zur Datenklassifizierung
- Informationen zum Tag-Export
- Data Catalog speichert die Klassifizierungs-Tags.
- Sensitive Data Protection prüft Assets auf vertrauliche infoTypes.
- Compute Engine führt das Script "Datasets prüfen" aus, das für jedes BigQuery-Dataset einen Sensitive Data Protection-Job auslöst.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Die Architektur enthält die folgenden Ergebnisse, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen:
- Gibt an, ob vertraulichen Daten ein Tag der vertraulichen Kategorie zugewiesen ist.
- Gibt an, ob vertraulichen Daten ein Vertraulichkeits-Tag auf Spaltenebene zugewiesen ist.
7. Datenberechtigungen werden verwaltet, erzwungen und nachverfolgt
Standardmäßig werden nur Erstellern und Inhabern Berechtigungen und Zugriff auf vertrauliche Daten zugewiesen. Darüber hinaus erfordert diese Kontrolle, dass die Architektur den gesamten Zugriff auf vertrauliche Daten erfasst.
Zur Erfüllung der Anforderungen dieser Kontrolle, verwendet die Architektur die cdmc
sensitive data classification-Richtlinien-Tag-Taxonomie in BigQuery, um den Zugriff auf Spalten zu steuern, die vertrauliche Daten in BigQuery-Tabellen enthalten. Die Taxonomie umfasst die folgenden Richtlinien-Tags:
- Vertrauliche personenidentifizierbare Informationen
- Personenidentifizierbare Informationen
- Vertrauliche personenbezogene Daten
- Personenbezogene Daten
Mit Richtlinien-Tags können Sie steuern, wer sich vertrauliche Spalten in BigQuery-Tabellen ansehen kann. Die Architektur ordnet diese Richtlinien-Tags Vertraulichkeitsklassifizierungen zu, die von Sensitive Data Protection-infoTypes abgeleitet wurden. Beispiel: Das Richtlinien-Tag sensitive_personal_identifiable_information und die vertrauliche Kategorie werden infoTypes wie AGE, DATE_OF_BIRTH, PHONE_NUMBER und EMAIL_ADDRESS zugeordnet.
Die Architektur verwendet die Identity and Access Management (IAM), um die Gruppen, Nutzer und Dienstkonten zu verwalten, die Zugriff auf die Daten benötigen. IAM-Berechtigungen werden einem bestimmten Asset für Zugriff auf Tabellenebene gewährt. Darüber hinaus ermöglicht der auf Richtlinien-Tags basierende Spaltenzugriff einen differenzierten Zugriff auf vertrauliche Datenressourcen. Standardmäßig haben Nutzer keinen Zugriff auf Spalten mit definierten Richtlinien-Tags.
Damit nur authentifizierte Nutzer auf Daten zugreifen können, verwendetGoogle Cloud Cloud Identity, das Sie mit Ihren vorhandenen Identitätsanbietern zur Authentifizierung von Nutzern verbinden können.
Diese Kontrolle erfordert auch, dass die Architektur regelmäßig auf Daten-Assets prüft, für die keine Berechtigungen definiert sind. Der von Cloud Scheduler verwaltete Detektor prüft auf die folgenden Szenarien:
- Ein Daten-Asset enthält eine vertrauliche Kategorie, aber es gibt kein entsprechendes Richtlinien-Tag.
- Eine Kategorie stimmt nicht mit dem Richtlinien-Tag überein.
In diesen Szenarien generiert der Detektor Ergebnisse, die von Pub/Sub veröffentlicht und dann von Dataflow in die Tabelle events in BigQuery geschrieben werden. Anschließend können Sie die Ergebnisse an Ihr Korrekturtool weiterleiten, wie in 1. Compliance mit der Datenkontrolle beschrieben.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Ein BigQuery-Data-Warehouse speichert die vertraulichen Daten und die Richtlinien-Tag-Bindungen für eine detaillierte Zugriffssteuerung.
- IAM verwaltet den Zugriff.
- Data Catalog speichert die Tags auf Tabellen- und Spaltenebene für die vertrauliche Kategorie.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
Zur Erkennung von Problemen im Zusammenhang mit dieser Kontrolle prüft die Architektur, ob vertrauliche Daten ein entsprechendes Richtlinien-Tag haben.
8. Zugriff, Verwendung und Ergebnisse von Daten nach ethischen Maßstäben werden verwaltet
Für diese Kontrolle ist es erforderlich, dass die Architektur Datenfreigabevereinbarungen sowohl vom Datenanbieter als auch von Datennutzern speichert, einschließlich einer Liste genehmigter Nutzungszwecke. Der Nutzungszweck für die vertraulichen Daten wird dann in BigQuery mithilfe von Abfragelabels den Berechtigungen zugeordnet.
Wenn ein Nutzer vertrauliche Daten in BigQuery abfragt, muss er einen gültigen Zweck angeben, der mit seiner Berechtigung übereinstimmt (z. B. SET @@query_label = “use:3”;).
Die Architektur verwendet Data Catalog, um der Tag-Vorlage CDMC controls die folgenden Tags hinzuzufügen. Diese Tags stellen die Datenfreigabevereinbarung mit dem Datenanbieter dar:
approved_use: die genehmigte Nutzung oder die Nutzer des Daten-Assetssharing_scope_geography: die Liste der geografischen Standorte, an denen das Daten-Asset freigegeben werden kannsharing_scope_legal_entity: die Liste der vereinbarten Entitäten, die das Daten-Asset gemeinsam nutzen können
Ein separates BigQuery-Data-Warehouse enthält das Dataset entitlement_management mit den folgenden Tabellen:
provider_agreement: die Datenfreigabevereinbarung mit dem Datenanbieter, einschließlich des vereinbarten Rechtssubjekts und des geografischen Geltungsbereichs. Diese Daten sind die Standardeinstellungen für die Tagsshared_scope_geographyundsharing_scope_legal_entity.consumer_agreement: die Datenfreigabevereinbarung mit dem Datennutzer, einschließlich des vereinbarten Rechtssubjekts und des geografischen Geltungsbereichs. Jede Vereinbarung ist einer IAM-Bindung für das Daten-Asset zugeordnet.use_purpose: der Nutzungszweck, z. B. die Nutzungsbeschreibung und die zulässigen Vorgänge für das Daten-Assetdata_asset: Informationen zum Daten-Asset, z. B. der Asset-Name und Details zum Dateninhaber
Zur Prüfung von Datenfreigabevereinbarungen hat BigQuery für jeden Job und jede Abfrage einen vollständigen Audit-Trail. Der Audit-Trail wird in der Ansicht INFORMATION_SCHEMA.JOBS von BigQuery gespeichert. Nachdem Sie einer Sitzung ein Abfragelabel zugeordnet und Abfragen innerhalb der Sitzung ausgeführt haben, können Sie Audit-Logs für Abfragen mit diesem Abfragelabel erfassen. Weitere Informationen finden Sie in der Referenz zu Audit-Logs für BigQuery.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten und das andere die Berechtigungsdaten, einschließlich der Vereinbarungen zu Anbieter- und Nutzerdatenfreigaben und des genehmigten Verwendungszwecks.
- Data Catalog speichert die Informationen der Anbieterdatenfreigabevereinbarung als Tags.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Die Architektur enthält die folgenden Ergebnisse, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen:
- Ob es im Dataset
entitlement_managementeinen Eintrag für ein Daten-Asset gibt. - Ob ein Vorgang für eine vertrauliche Tabelle mit einem abgelaufenen Anwendungsfall ausgeführt wird (z. B. ist das
valid_until_datein derconsumer_agreement tableverstrichen). - Ob ein Vorgang für eine vertrauliche Tabelle mit einem falschen Labelschlüssel ausgeführt wird.
- Ob ein Vorgang für eine vertrauliche Tabelle mit einem leeren oder nicht genehmigten Anwendungsfall-Labelwert ausgeführt wird.
- Ob eine vertrauliche Tabelle mit einer nicht genehmigten Vorgangsmethode abgefragt wird (z. B.
SELECToderINSERT). - Ob der aufgezeichnete Zweck, den der Nutzer beim Abfragen der vertraulichen Daten angegeben hat, mit der Datenfreigabevereinbarung übereinstimmt.
9. Daten werden gesichert und Kontrollen werden nachgewiesen
Diese Kontrolle erfordert die Implementierung der Datenverschlüsselung und De-Identifikation, um vertrauliche Daten zu schützen und eine Aufzeichnung dieser Kontrollen bereitzustellen.
Diese Architektur baut auf der Standardsicherheit von Google auf, einschließlich der Verschlüsselung ruhender Daten. Darüber hinaus können Sie mit der Architektur Ihre eigenen Schlüssel mithilfe von vom Kunden verwalteten Verschlüsselungsschlüsseln (Customer-Managed Encryption Keys, CMEKs) verwalten. Mit Cloud KMS können Sie Ihre Daten mit softwaregestützten Verschlüsselungsschlüsseln oder gemäß FIPS 140-2 Level 3 validierten Hardwaresicherheitsmodulen (HSMs) verschlüsseln.
Die Architektur verwendet die dynamische Datenmaskierung auf Spaltenebene, die über Richtlinien-Tags konfiguriert wird, und speichert vertrauliche Daten in einem separaten VPC Service Controls-Perimeter. Sie können auch eine De-Identifikation auf Anwendungsebene hinzufügen, die Sie entweder lokal oder als Teil der Datenaufnahme-Pipeline implementieren können.
Standardmäßig implementiert die Architektur die CMEK-Verschlüsselung mit HSMs, unterstützt aber auch Cloud External Key Manager (Cloud EKM).
In der folgenden Tabelle wird die beispielhafte Sicherheitsrichtlinie beschrieben, die die Architektur für die Region us-central1 implementiert. Sie können die Richtlinie an Ihre Anforderungen anpassen, indem Sie beispielsweise verschiedene Richtlinien für verschiedene Regionen hinzufügen.
| Vertraulichkeit der Daten | Standardverschlüsselungsmethode | Weitere zulässige Verschlüsselungsmethoden | Standard-De-Identifikationsmethode | Weitere zulässige De-Identifikationsmethoden |
|---|---|---|---|---|
| Öffentliche Informationen | Standardverschlüsselung | Beliebig | – | Beliebig |
| Vertrauliche personenidentifizierbare Informationen | CMEK mit HSM | EKM | Auf null setzen | SHA-256-Hash oder Standardmaskierungswert |
| Personenidentifizierbare Informationen | CMEK mit HSM | EKM | SHA-256-Hash | Auf null setzen oder Standardmaskierungswert |
| Vertrauliche personenbezogene Daten | CMEK mit HSM | EKM | Standardmaskierungswert | SHA-256-Hash oder auf null setzen |
| Personenbezogene Daten | CMEK mit HSM | EKM | Standardmaskierungswert | SHA-256-Hash oder auf null setzen |
Die Architektur verwendet Data Catalog, um das Tag encryption_method der Tag-Vorlage CDMC controls auf Tabellenebene hinzuzufügen. encryption_method definiert die vom Daten-Asset verwendete Verschlüsselungsmethode.
Darüber hinaus erstellt die Architektur ein security policy template-Tag, um zu ermitteln, welche De-Identifikationsmethode auf ein bestimmtes Feld angewendet wird. Die Architektur verwendet die platform_deid_method, die mit dynamischer Datenmaskierung angewendet wird. Sie können die app_deid_method hinzufügen und mit den Dataflow- und Sensitive Data Protection-Datenaufnahme-Pipelines füllen, die im Blueprint des gesicherten Data Warehouse enthalten sind.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei optionale Instanzen von Dataflow, wobei eine die De-Identifikation auf Anwendungsebene und die andere die Re-Identifikation ausführt.
- Drei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten, eines die nicht vertraulichen Daten und das dritte die Sicherheitsrichtlinie.
- Data Catalog speichert die Tag-Vorlagen für die Verschlüsselung und De-Identifikation.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub hat Ergebnisse veröffentlicht.
Die Architektur enthält die folgenden Ergebnisse, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen:
- Der Wert für das Tag der Verschlüsselungsmethode stimmt nicht mit den zulässigen Verschlüsselungsmethoden für die angegebene Vertraulichkeit und den angegebenen Standort überein.
- Eine Tabelle enthält vertrauliche Spalten, aber das Tag für die Sicherheitsrichtlinienvorlage enthält eine ungültige De-Identifikationsmethode auf Plattformebene.
- Eine Tabelle enthält vertrauliche Spalten, aber das Tag für die Sicherheitsrichtlinienvorlage fehlt.
10. Ein Datenschutz-Framework ist definiert und betriebsbereit
Bei dieser Kontrolle muss die Architektur den Datenkatalog und die Klassifizierungen prüfen, um festzustellen, ob Sie einen DSFA-Bericht (Datenschutz-Folgenabschätzung) oder einen PIA-Bericht (Privacy Impact Assessment, Privatsphäre-Folgenabschätzung) erstellen müssen. Die Privatsphäre-Abschätzungen variieren je nach Region und Aufsichtsbehörden erheblich. Zur Bestimmung, ob eine Folgenabschätzung erforderlich ist, muss die Architektur den Datenstandort und den Standort der betroffenen Person berücksichtigen.
Die Architektur verwendet Data Catalog, um der Tag-Vorlage Impact assessment die folgenden Tags hinzuzufügen:
subject_locations: der Standort der betroffenen Personen, auf die in den Daten in diesem Asset verwiesen wird.is_dpia: gibt an, ob für dieses Asset eine Datenschutz-Folgenabschätzung (DSFA) durchgeführt wurde.is_pia: gibt an, ob für dieses Asset eine Privatsphäre-Folgenabschätzung (PIA) durchgeführt wurde.impact_assessment_reports: externer Link zum Speicherort des Berichts zur Folgenabschätzung.most_recent_assessment: das Datum der letzten Folgenabschätzung.oldest_assessment: das Datum der ersten Folgenabschätzung.
Tag Engine fügt diese Tags jedem vertraulichen Daten-Asset hinzu, wie in Kontrolle 6 definiert. Der Detektor validiert diese Tags anhand einer Richtlinientabelle in BigQuery, die gültige Kombinationen aus Datenstandort, Standort der betroffenen Person und Datenvertraulichkeit enthält (z. B. ob es sich um personenidentifizierbare Informationen handelt) und angibt, welche Art von Folgenabschätzung (entweder PIA oder DSFA) erforderlich ist.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Vier BigQuery-Data-Warehouses speichern folgende Informationen:
- Vertrauliche Daten
- Nicht vertrauliche Daten
- Richtlinie zur Folgenabschätzung und Zeitstempel von Berechtigungen
- Tag-Exporte, die für das Dashboard verwendet werden
- Data Catalog speichert die Folgenabschätzungsdetails in Tags in Tag-Vorlagen.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Die Architektur enthält die folgenden Ergebnisse, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen:
- Vertrauliche Daten sind ohne Vorlage für die Folgenabschätzung vorhanden.
- Vertrauliche Daten sind ohne Link zu einem DSFA- oder PIA-Bericht vorhanden.
- Tags erfüllen nicht die Anforderungen der Richtlinientabelle.
- Die Folgenabschätzung ist älter als die zuletzt genehmigte Berechtigung für das Daten-Asset in der Nutzervereinbarungstabelle.
11. Der Datenlebenszyklus wird geplant und verwaltet
Diese Kontrolle erfordert die Möglichkeit, alle Daten-Assets zu prüfen, um festzustellen, ob eine Datenlebenszyklus-Richtlinie vorhanden ist und eingehalten wird.
Die Architektur verwendet Data Catalog, um der Tag-Vorlage CDMC controls die folgenden Tags hinzuzufügen:
retention_period: die Zeit in Tagen, für die die Tabelle aufbewahrt werden sollexpiration_action: gibt an, ob die Tabelle nach Ablauf der Aufbewahrungsdauer archiviert oder dauerhaft gelöscht werden soll
Standardmäßig verwendet die Architektur die folgende Aufbewahrungsdauer und die folgende Ablaufaktion:
| Datenkategorie | Aufbewahrungsdauer in Tagen | Ablaufaktion |
|---|---|---|
| Vertrauliche personenidentifizierbare Informationen | 60 | Dauerhaft löschen |
| Personenidentifizierbare Informationen | 90 | Archivieren |
| Vertrauliche personenbezogene Daten | 180 | Archivieren |
| Personenbezogene Daten | 180 | Archivieren |
Record Manager, ein Open-Source-Asset für BigQuery, automatisiert das dauerhafte Löschen und das Archivieren von BigQuery-Tabellen anhand der oben genannten Tag-Werte und einer Konfigurationsdatei. Beim dauerhaften Löschen wird ein Ablaufdatum für eine Tabelle festgelegt und eine Snapshot-Tabelle mit einer Ablaufzeit erstellt, die in der Record Manager-Konfiguration definiert ist. Standardmäßig beträgt die Ablaufzeit 30 Tage. Während des vorläufigen Löschens können Sie die Tabelle abrufen. Das Archivierungsverfahren erstellt eine externe Tabelle für jede BigQuery-Tabelle, die die Aufbewahrungsdauer überschreitet. Die Tabelle wird im Parquet-Format in Cloud Storage gespeichert und auf eine BigLake-Tabelle aktualisiert. Damit kann die externe Datei mit Metadaten in Data Catalog getaggt werden.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei BigQuery-Data-Warehouses: In einem sind die vertraulichen Daten gespeichert, im anderen die Richtlinien zur Datenaufbewahrung.
- Zwei Cloud Storage-Instanzen: Eine bietet Archivspeicher und die andere speichert Datensätze.
- Data Catalog speichert die Aufbewahrungsdauer und die Aktion in Tag-Vorlagen und den Tags.
- Zwei Cloud Run-Instanzen: eine führt Record Manager aus und die andere stellt die Detektoren bereit.
- Drei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Auf der dritten Instanz wird Record Manager ausgeführt, das das dauerhafte Löschen und das Archivieren von BigQuery-Tabellen automatisiert.
- Pub/Sub veröffentlicht Ergebnisse.
Die Architektur enthält die folgenden Ergebnisse, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen:
- Achten Sie bei vertraulichen Assets darauf, dass die Aufbewahrungsmethode der Richtlinie für den Speicherort des Assets entspricht.
- Achten Sie bei vertraulichen Assets darauf, dass die Aufbewahrungsdauer mit der Richtlinie für den Speicherort des Assets übereinstimmt.
12. Datenqualität wird verwaltet
Mit dieser Kontrolle kann die Qualität der Daten basierend auf Datenprofilen oder benutzerdefinierten Messwerten gemessen werden.
Die Architektur umfasst die Möglichkeit, Regeln für Datenqualität für einen einzelnen oder aggregierten Wert zu definieren und einer bestimmten Tabellenspalte Grenzwerte zuzuweisen. Sie enthält Tag-Vorlagen für Richtigkeit und Vollständigkeit. Data Catalog fügt jeder Tag-Vorlage die folgenden Tags hinzu:
column_name: der Name der Spalte, für die der Messwert giltmetric: der Name des Messwerts oder der Qualitätsregelrows_validated: die Anzahl der validierten Zeilensuccess_percentage: der Prozentsatz der Werte, die diesen Messwert erfüllenacceptable_threshold: der akzeptable Grenzwert für diesen Messwertmeets_threshold: gibt an, ob der Qualitätsfaktor (der Wertsuccess_percentage) zum akzeptablen Grenzwert passtmost_recent_run: der Zeitpunkt, zu dem der Messwert oder die Qualitätsregel zuletzt ausgeführt wurde
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Drei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten, eines die nicht vertraulichen Daten und das dritte die Messwerte der Qualitätsregel.
- Data Catalog speichert die Ergebnisse zur Datenqualität in Tag-Vorlagen und Tags.
- Cloud Scheduler definiert, wann die Cloud Data Quality Engine ausgeführt wird.
- Drei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Auf der dritten Instanz wird Cloud Data Quality Engine ausgeführt.
- Mit Cloud Data Quality Engine werden Datenqualitätsregeln definiert und Datenqualitätsprüfungen für Tabellen und Spalten geplant.
- Pub/Sub veröffentlicht Ergebnisse.
Im Looker Studio-Dashboard werden die Datenqualitätsberichte sowohl für die Tabellen- als auch für die Spaltenebene angezeigt.
Die Architektur enthält die folgenden Ergebnisse, um Probleme im Zusammenhang mit dieser Kontrolle zu erkennen:
- Daten sind vertraulich, aber es werden keine Tag-Vorlagen für Datenqualität angewendet (Richtigkeit und Vollständigkeit).
- Die Daten sind vertraulich, aber das Datenqualitäts-Tag wird nicht auf die vertrauliche Spalte angewendet.
- Die Daten sind vertraulich, aber die Ergebnisse zur Datenqualität liegen nicht innerhalb des in der Regel festgelegten Grenzwerts.
- Die Daten sind nicht vertraulich und die Ergebnisse zur Datenqualität liegen nicht innerhalb des Grenzwerts, der von der Regel festgelegt wurde.
Als Alternative zu Cloud Data Quality Engine können Sie Datenqualitätsaufgaben in Dataplex Universal Catalog konfigurieren.
13. Die Grundsätze des Kostenverwaltung werden festgelegt und angewendet
Diese Kontrolle erfordert die Möglichkeit, Daten-Assets anhand der Richtlinienanforderungen und der Datenarchitektur zu prüfen, um die Kostennutzung zu bestätigen. Kostenmesswerte sollten umfassend und nicht nur auf die Speichernutzung und -übertragung beschränkt sein.
Die Architektur verwendet Data Catalog, um die folgenden Tags zur Tag-Vorlage cost_metrics hinzuzufügen:
total_query_bytes_billed: Gesamtzahl der Abfragebyte, die für dieses Daten-Asset seit Beginn des aktuellen Monats in Rechnung gestellt wurden.total_storage_bytes_billed: Gesamtzahl der Speicherbyte, die für dieses Daten-Asset seit Beginn des aktuellen Monats in Rechnung gestellt wurden.total_bytes_transferred: Summe der Byte, die regionenübergreifend in dieses Daten-Asset übertragen wurden.estimated_query_cost: geschätzte Abfragekosten in US-Dollar für das Daten-Asset für den aktuellen Monat.estimated_storage_cost: geschätzten Speicherkosten in US-Dollar für das Daten-Asset für den aktuellen Monat.estimated_egress_cost: geschätzter ausgehender Traffic in US-Dollar für den aktuellen Monat, in dem das Daten-Asset als Zieltabelle verwendet wurde.
Die Architektur exportiert Preisinformationen aus Cloud Billing in eine BigQuery-Tabelle mit dem Namen cloud_pricing_export.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Cloud Billing bietet Zahlungsinformationen.
- Data Catalog speichert die Kosteninformationen in Tag-Vorlagen und Tags.
- BigQuery speichert die exportierten Preisinformationen und die Verlaufsinformationen zum Abfragejob über die integrierte Ansicht INFORMATION_SCHEMA.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Zur Erkennung von Problemen im Zusammenhang mit dieser Kontrolle prüft die Architektur, ob vertrauliche Daten-Assets vorhanden sind, ohne dass Kostenmesswerte damit verknüpft sind.
14. Datenherkunft wird verstanden
Diese Kontrolle erfordert die Möglichkeit, die Rückverfolgbarkeit des Daten-Assets aus seiner Quelle sowie Änderungen an der Herkunft des Daten-Assets zu prüfen.
Die Architektur verwendet die integrierten Features zur Datenherkunft in Data Catalog, um Informationen zur Datenherkunft zu speichern. Darüber hinaus definieren die Datenaufnahmeskripts die ultimative Quelle und fügen die Quelle als zusätzlichen Knoten zum Datenherkunftsdiagramm hinzu.
Zur Erfüllung der Anforderungen dieser Kontrolle verwendet die Architektur Data Catalog, um das Tag ultimate_source zur Tag-Vorlage CDMC
controls hinzuzufügen. Das Tag ultimate_source definiert die Quelle für dieses Daten-Asset.
Das folgende Diagramm zeigt die Dienste, die für diese Kontrolle gelten.

Die Architektur verwendet die folgenden Dienste, um die Anforderungen dieser Kontrolle zu erfüllen:
- Zwei BigQuery-Data-Warehouses: Eines speichert die vertraulichen Daten und das andere die Daten der ultimativen Quelle.
- Data Catalog speichert die ultimative Quelle in Tag-Vorlagen und Tags.
- Datenaufnahmeskripts laden die Daten aus Cloud Storage, definieren die ultimative Quelle und fügen die Quelle dem Datenherkunftsdiagramm hinzu.
- Zwei Cloud Run-Instanzen:
- Eine Instanz führt Report Engine aus, das prüft, ob Tags angewendet werden, und veröffentlicht Ergebnisse.
- Eine andere Instanz führt Tag Engine aus, das die Daten im gesicherten Data Warehouse mit Tags versieht.
- Pub/Sub veröffentlicht Ergebnisse.
Die Architektur enthält die folgenden Prüfungen, um mit dieser Kontrolle verbundene Probleme zu erkennen:
- Vertrauliche Daten werden ohne Tag zur ultimativen Quelle.
- Das Herkunftsdiagramm wird nicht für vertrauliche Daten-Assets ausgefüllt.
Tag-Referenz
In diesem Abschnitt werden die Tag-Vorlagen und Tags beschrieben, die diese Architektur verwendet, um die Anforderungen der CDMC-Schlüsselkontrollen zu erfüllen.
CDMC-Kontroll-Tag-Vorlagen auf Tabellenebene
In der folgenden Tabelle sind die Tags aufgeführt, die Teil der Vorlage für CDMC-Kontroll-Tags sind und auf Tabellen angewendet werden.
| Tag | Tag-ID | Anwendbare Schlüsselkontrolle |
|---|---|---|
| Genehmigter Speicherort | approved_storage_location |
4 |
| Genehmigte Nutzung | approved_use |
8 |
| E-Mail-Adresse des Dateninhabers | data_owner_email |
2 |
| Name des Dateninhabers | data_owner_name |
2 |
| Verschlüsselungsmethode | encryption_method |
9 |
| Ablaufaktion | expiration_action |
11 |
| Ist autoritativ | is_authoritative |
3 |
| Ist vertraulich | is_sensitive |
6 |
| Vertrauliche Kategorie | sensitive_category |
6 |
| Region des Freigabebereichs | sharing_scope_geography |
8 |
| Rechtspersönlichkeit des Freigabebereichs | sharing_scope_legal_entity |
8 |
| Aufbewahrungsdauer | retention_period |
11 |
| Ultimative Quelle | ultimate_source |
14 |
Tag-Vorlage für die Folgenabschätzung
In der folgenden Tabelle sind die Tags aufgeführt, die Teil der Tag-Vorlage für die Folgenabschätzung sind und auf Tabellen angewendet werden.
| Tag | Tag-ID | Anwendbare Schlüsselkontrolle |
|---|---|---|
| Standorte der betroffenen Personen | subject_locations |
10 |
| Ist DSFA-Folgenabschätzung | is_dpia |
10 |
| Ist PIA-Folgenabschätzung | is_pia |
10 |
| Berichte zur Folgenabschätzung | impact_assessment_reports |
10 |
| Letzte Folgenabschätzung | most_recent_assessment |
10 |
| Älteste Folgenabschätzung | oldest_assessment |
10 |
Tag-Vorlage für Kostenmesswerte
In der folgenden Tabelle sind die Tags aufgeführt, die Teil der Tag-Vorlage für Kostenmesswerte sind und auf Tabellen angewendet werden.
| Tag | Tab ID | Anwendbare Schlüsselkontrolle |
|---|---|---|
| Geschätzte Abfragekosten | estimated_query_cost |
13 |
| Geschätzte Speicherkosten | estimated_storage_cost |
13 |
| Geschätzte Kosten für ausgehenden Traffic | estimated_egress_cost |
13 |
| Gesamtzahl der in Rechnung gestellten Abfragebyte | total_query_bytes_billed |
13 |
| Gesamtzahl der in Rechnung gestellten Speicherbyte | total_storage_bytes_billed |
13 |
| Gesamtzahl der übertragenen Byte | total_bytes_transferred |
13 |
Tag-Vorlage für Datenvertraulichkeit
In der folgenden Tabelle sind die Tags aufgeführt, die Teil der Tag-Vorlage für die Datenvertraulichkeit sind und auf Felder angewendet werden.
| Tag | Tag-ID | Anwendbare Schlüsselkontrolle |
|---|---|---|
| Vertrauliches Feld | sensitive_field |
6 |
| Vertraulicher Typ | sensitive_category |
6 |
Tag-Vorlage für Sicherheitsrichtlinien
In der folgenden Tabelle sind die Tags aufgeführt, die Teil der Tag-Vorlage für Sicherheitsrichtlinien sind und auf Felder angewendet werden.
| Tag | Tag-ID | Anwendbare Schlüsselkontrolle |
|---|---|---|
| De-Identifikationsmethode der Anwendung | app_deid_method |
9 |
| De-Identifikationsmethode der Plattform | platform_deid_method |
9 |
Tag-Vorlagen für Datenqualität
In der folgenden Tabelle sind die Tags aufgeführt, die Teil der Datenqualitäts-Tag-Vorlagen für die Vollständigkeit und Richtigkeit sind und auf Felder angewendet werden.
| Tag | Tag-ID | Anwendbare Schlüsselkontrolle |
|---|---|---|
| Zulässiger Grenzwert | acceptable_threshold |
12 |
| Spaltenname | column_name |
12 |
| Passt zum Grenzwert | meets_threshold |
12 |
| Messwert | metric |
12 |
| Letzte Ausführung | most_recent_run |
12 |
| Validierte Zeilen | rows_validated |
12 |
| Erfolgsprozentsatz | success_percentage |
12 |
CDMC-Richtlinien-Tags auf Feldebene
In der folgenden Tabelle sind die Richtlinien-Tags aufgeführt, die Teil der Taxonomie von CDMC-Richtlinien-Tags sind und auf Felder angewendet werden. Diese Richtlinien-Tags schränken den Zugriff auf Feldebene ein und ermöglichen die De-Identifikation von Daten auf Plattformebene.
| Datenklassifizierung | Tag-Name | Anwendbare Schlüsselkontrolle |
|---|---|---|
| Personenidentifizierbare Informationen | personal_identifiable_information |
7 |
| Personenbezogene Daten | personal_information |
7 |
| Vertrauliche personenidentifizierbare Informationen | sensitive_personal_identifiable_information |
7 |
| Vertrauliche personenbezogene Daten | sensitive_personal_data |
7 |
Vorab ausgefüllte technische Metadaten
In der folgenden Tabelle sind die technischen Metadaten aufgeführt, die standardmäßig in Data Catalog für alle BigQuery-Daten-Assets synchronisiert werden.
| Metadaten | Anwendbare Schlüsselkontrolle |
|---|---|
| Assettyp | – |
| Erstellungszeitpunkt | – |
| Ablaufzeit | 11 |
| Standort | 4 |
| Ressourcen-URL | 3 |
Nächste Schritte
- Weitere Informationen zu CDMC
- Lesen Sie mehr über die Sicherheitskontrollen, die im gesicherten Data Warehouse-Blueprint verwendet werden.
- Data Catalog entdecken
- Weitere Informationen zu Dataplex Universal Catalog
- Weitere Informationen zu Tag Engine
- Implementieren Sie diese Lösung mithilfe der Google Cloud CDMC-Referenzarchitektur in GitHub.