Dokumen ini menunjukkan cara menjalankan workload batch SQL dan PySpark Serverless untuk Apache Spark guna membuat tabel Apache Iceberg dengan metadata yang disimpan di metastore BigLake. Untuk mengetahui informasi tentang cara lain untuk menjalankan kode Spark, lihat Menjalankan kode PySpark di notebook BigQuery dan Menjalankan beban kerja Apache Spark
Sebelum memulai
Jika Anda belum melakukannya, buat Google Cloud project dan bucket Cloud Storage.
Menyiapkan project
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc, BigQuery, and Cloud Storage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. Buat bucket Cloud Storage di project Anda.
- In the Google Cloud console, go to the Cloud Storage Buckets page.
- Click Create.
- On the Create a bucket page, enter your bucket information. To go to the next
step, click Continue.
-
In the Get started section, do the following:
- Enter a globally unique name that meets the bucket naming requirements.
- To add a
bucket label,
expand the Labels section (),
click add_box
Add label, and specify a
keyand avaluefor your label.
-
In the Choose where to store your data section, do the following:
- Select a Location type.
- Choose a location where your bucket's data is permanently stored from the Location type drop-down menu.
- If you select the dual-region location type, you can also choose to enable turbo replication by using the relevant checkbox.
- To set up cross-bucket replication, select
Add cross-bucket replication via Storage Transfer Service and
follow these steps:
Set up cross-bucket replication
- In the Bucket menu, select a bucket.
In the Replication settings section, click Configure to configure settings for the replication job.
The Configure cross-bucket replication pane appears.
- To filter objects to replicate by object name prefix, enter a prefix that you want to include or exclude objects from, then click Add a prefix.
- To set a storage class for the replicated objects, select a storage class from the Storage class menu. If you skip this step, the replicated objects will use the destination bucket's storage class by default.
- Click Done.
-
In the Choose how to store your data section, do the following:
- Select a default storage class for the bucket or Autoclass for automatic storage class management of your bucket's data.
- To enable hierarchical namespace, in the Optimize storage for data-intensive workloads section, select Enable hierarchical namespace on this bucket.
- In the Choose how to control access to objects section, select whether or not your bucket enforces public access prevention, and select an access control method for your bucket's objects.
-
In the Choose how to protect object data section, do the
following:
- Select any of the options under Data protection that you
want to set for your bucket.
- To enable soft delete, click the Soft delete policy (For data recovery) checkbox, and specify the number of days you want to retain objects after deletion.
- To set Object Versioning, click the Object versioning (For version control) checkbox, and specify the maximum number of versions per object and the number of days after which the noncurrent versions expire.
- To enable the retention policy on objects and buckets, click the Retention (For compliance) checkbox, and then do the following:
- To enable Object Retention Lock, click the Enable object retention checkbox.
- To enable Bucket Lock, click the Set bucket retention policy checkbox, and choose a unit of time and a length of time for your retention period.
- To choose how your object data will be encrypted, expand the Data encryption section (), and select a Data encryption method.
- Select any of the options under Data protection that you
want to set for your bucket.
-
In the Get started section, do the following:
- Click Create.
Berikan peran BigQuery Data Editor (
roles/bigquery.dataEditor) kepada akun layanan default Compute Engine,PROJECT_NUMBER-compute@developer.gserviceaccount.com. Untuk mengetahui petunjuknya, lihat bagian Memberikan satu peran.Contoh Google Cloud CLI:
gcloud projects add-iam-policy-binding PROJECT_ID \ --member PROJECT_NUMBER-compute@developer.gserviceaccount.com \ --role roles/bigquery.dataEditor
Catatan:
- PROJECT_ID dan PROJECT_NUMBER tercantum di bagian Project info di Dasbor konsol Google Cloud .
Salin perintah Spark SQL berikut secara lokal atau di Cloud Shell ke dalam file
iceberg-table.sql.USE CATALOG_NAME; CREATE NAMESPACE IF NOT EXISTS example_namespace; DROP TABLE IF EXISTS example_table; CREATE TABLE example_table (id int, data string) USING ICEBERG LOCATION 'gs://BUCKET/WAREHOUSE_FOLDER'; INSERT INTO example_table VALUES (1, 'first row'); ALTER TABLE example_table ADD COLUMNS (newDoubleCol double); DESCRIBE TABLE example_table;
Ganti kode berikut:
- CATALOG_NAME: Nama katalog Iceberg.
- BUCKET dan WAREHOUSE_FOLDER: Bucket dan folder Cloud Storage yang digunakan sebagai direktori gudang Iceberg.
Jalankan perintah berikut secara lokal atau di Cloud Shell dari direktori yang berisi
iceberg-table.sqluntuk mengirimkan workload Spark SQL.gcloud dataproc batches submit spark-sql iceberg-table.sql \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"
Catatan:
- PROJECT_ID: ID project Google Cloud Anda. Project ID tercantum di bagian Project info di Google Cloud Dasbor konsol.
- REGION: Region Compute Engine yang tersedia untuk menjalankan workload.
- BUCKET_NAME: Nama bucket Cloud Storage Anda. Spark mengupload dependensi workload ke folder
/dependenciesdi bucket ini sebelum menjalankan workload batch. WAREHOUSE_FOLDER berada di bucket ini. --version: Serverless for Apache Spark versi runtime 2.2 atau yang lebih baru.- SUBNET_NAME: Nama subnet VPC di
REGION. Jika Anda menghilangkan tanda ini, Serverless untuk Apache Spark akan memilih subnetdefaultdi region sesi. Serverless for Apache Spark mengaktifkan Private Google Access (PGA) di subnet. Untuk persyaratan konektivitas jaringan, lihat Google Cloud Konfigurasi jaringan Serverless untuk Apache Spark. - LOCATION: Lokasi BigQuery yang didukung. Lokasi defaultnya adalah "US".
--propertiesProperti katalog.
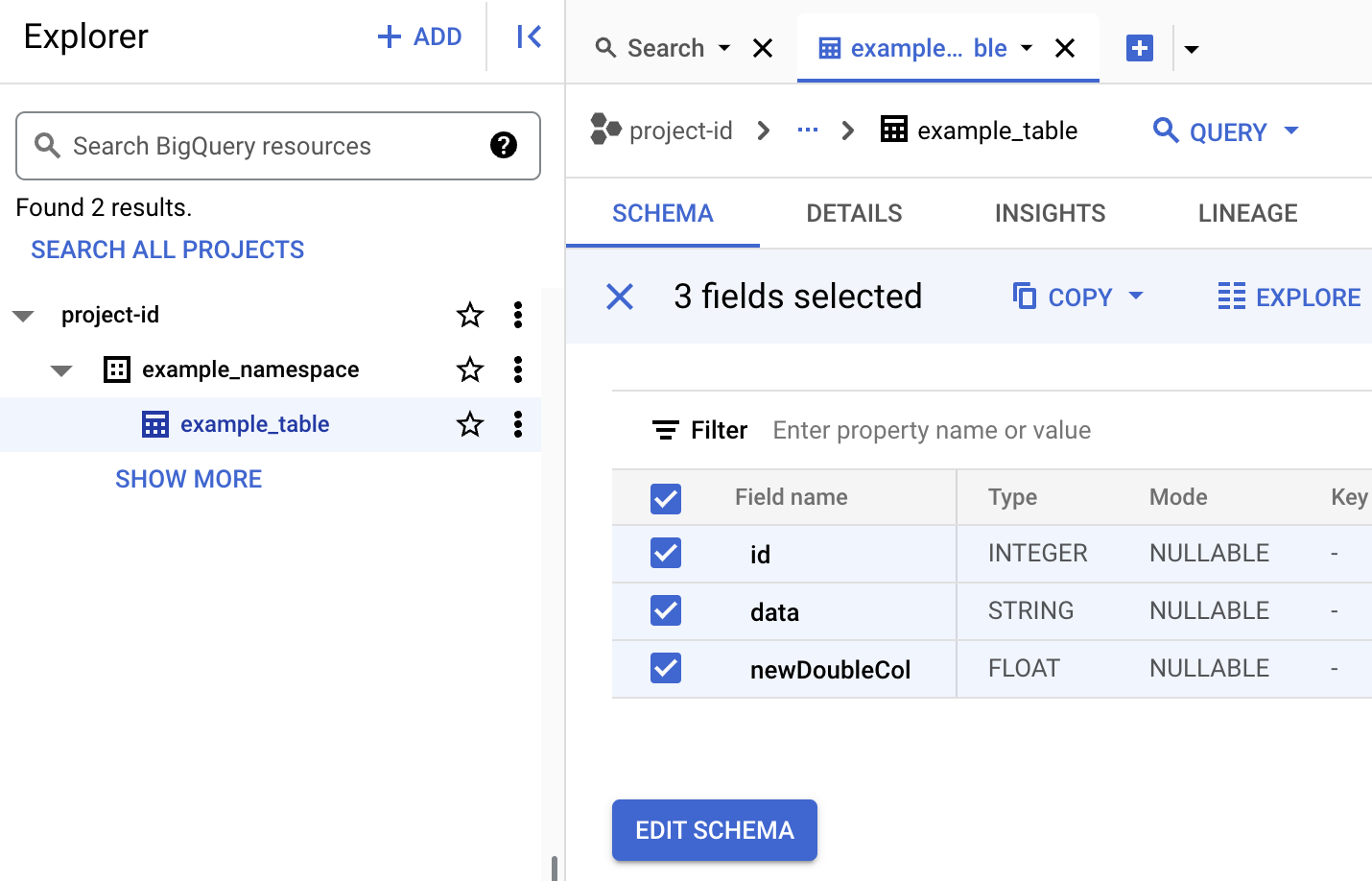
Melihat metadata tabel di BigQuery
Di konsol Google Cloud , buka halaman BigQuery.
Melihat metadata tabel Iceberg.
- Salin kode PySpark berikut secara lokal atau di
Cloud Shell
ke dalam file
iceberg-table.py.from pyspark.sql import SparkSession spark = SparkSession.builder.appName("iceberg-table-example").getOrCreate() catalog = "CATALOG_NAME" namespace = "NAMESPACE" spark.sql(f"USE `{catalog}`;") spark.sql(f"CREATE NAMESPACE IF NOT EXISTS `{namespace}`;") spark.sql(f"USE `{namespace}`;") # Create table and display schema spark.sql("DROP TABLE IF EXISTS example_iceberg_table") spark.sql("CREATE TABLE example_iceberg_table (id int, data string) USING ICEBERG") spark.sql("DESCRIBE example_iceberg_table;") # Insert table data. spark.sql("INSERT INTO example_iceberg_table VALUES (1, 'first row');") # Alter table, then display schema. spark.sql("ALTER TABLE example_iceberg_table ADD COLUMNS (newDoubleCol double);") spark.sql("DESCRIBE example_iceberg_table;")
Ganti kode berikut:
- CATALOG_NAME dan NAMESPACE: Nama katalog Iceberg
dan namespace digabungkan untuk mengidentifikasi tabel Iceberg (
catalog.namespace.table_name).
- CATALOG_NAME dan NAMESPACE: Nama katalog Iceberg
dan namespace digabungkan untuk mengidentifikasi tabel Iceberg (
-
Jalankan perintah berikut secara lokal atau di
Cloud Shell
dari direktori yang berisi
iceberg-table.pyuntuk mengirimkan workload PySpark.gcloud dataproc batches submit pyspark iceberg-table.py \ --project=PROJECT_ID \ --region=REGION \ --deps-bucket=BUCKET_NAME \ --version=2.2 \ --subnet=SUBNET_NAME \ --properties="spark.sql.catalog.CATALOG_NAME=org.apache.iceberg.spark.SparkCatalog,spark.sql.catalog.CATALOG_NAME.catalog-impl=org.apache.iceberg.gcp.bigquery.BigQueryMetastoreCatalog,spark.sql.catalog.CATALOG_NAME.gcp_project=PROJECT_ID,spark.sql.catalog.CATALOG_NAME.gcp_location=LOCATION,spark.sql.catalog.CATALOG_NAME.warehouse=gs://BUCKET/WAREHOUSE_FOLDER"Catatan:
- PROJECT_ID: ID project Google Cloud Anda. Project ID tercantum di bagian Project info di Google Cloud Dasbor konsol.
- REGION: Region Compute Engine yang tersedia untuk menjalankan beban kerja.
- BUCKET_NAME: Nama bucket Cloud Storage Anda. Spark mengupload
dependensi workload ke folder
/dependenciesdi bucket ini sebelum menjalankan workload batch. --version: Serverless for Apache Spark versi runtime 2.2 atau yang lebih baru.- SUBNET_NAME: Nama subnet VPC di
REGION. Jika Anda menghilangkan tanda ini, Serverless untuk Apache Spark akan memilih subnetdefaultdi region sesi. Serverless for Apache Spark mengaktifkan Akses Google Pribadi (PGA) di subnet. Untuk persyaratan konektivitas jaringan, lihat Google Cloud Konfigurasi jaringan Serverless untuk Apache Spark. - LOCATION: Lokasi BigQuery yang didukung. Lokasi defaultnya adalah "US".
- BUCKET dan WAREHOUSE_FOLDER: Bucket dan folder Cloud Storage yang digunakan sebagai direktori gudang Iceberg.
--properties: Properti katalog.
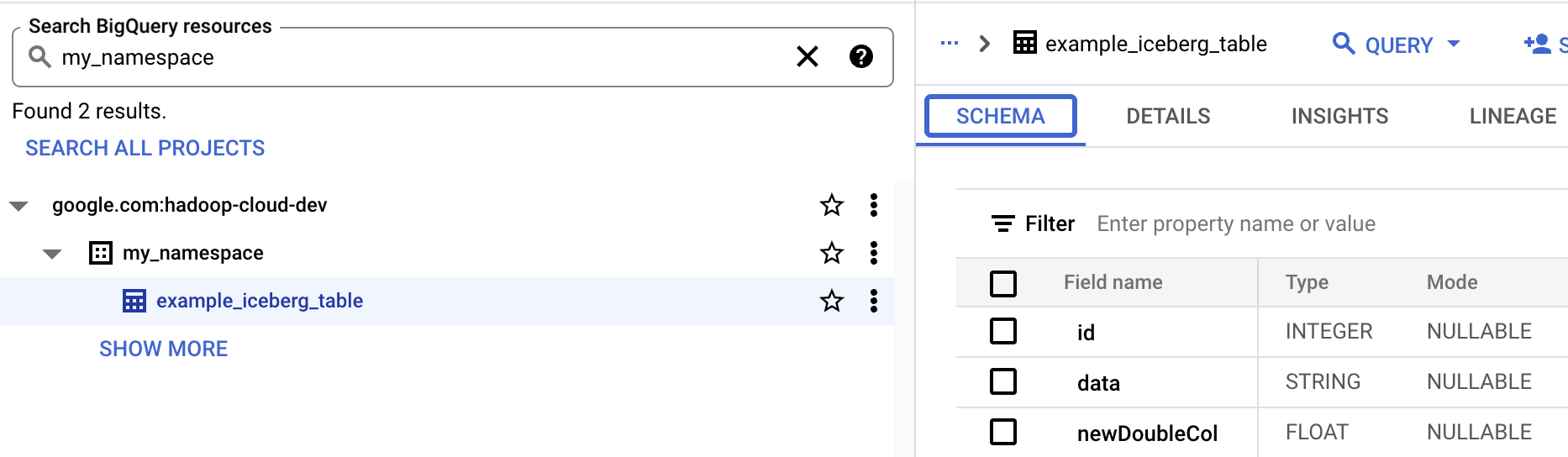
- Lihat skema tabel di BigQuery.
- Di konsol Google Cloud , buka halaman BigQuery. Buka BigQuery Studio
- Melihat metadata tabel Iceberg.
Pemetaan resource OSS ke resource BigQuery
Perhatikan pemetaan berikut antara istilah resource open source dan istilah resource BigQuery:
Resource OSS Resource BigQuery Namespace, Database Set data Tabel Berpartisi atau Tidak Berpartisi Tabel Lihat Lihat Membuat tabel Iceberg
Bagian ini menunjukkan cara membuat tabel Iceberg dengan metadata di metastore BigLake menggunakan Serverless for Apache Spark, Spark SQL, dan workload batch PySpark.
Spark SQL
Menjalankan beban kerja Spark SQL untuk membuat tabel Iceberg
Langkah-langkah berikut menunjukkan cara menjalankan workload batch Spark SQL Serverless for Apache Spark untuk membuat tabel Iceberg dengan metadata tabel yang disimpan di metastore BigLake.
PySpark
Langkah-langkah berikut menunjukkan cara menjalankan workload batch PySpark Serverless for Apache Spark untuk membuat tabel Iceberg dengan metadata tabel yang disimpan di metastore BigLake.