이 문서에서는 Google 서비스에 액세스할 수 있는 머신 또는 자체 관리 VM에 JupyterLab 확장 프로그램을 설치하고 사용하는 방법을 설명합니다. 또한 서버리스 Spark 노트북 코드를 개발하고 배포하는 방법도 설명합니다.
몇 분 안에 확장 프로그램을 설치하여 다음 기능을 활용하세요.
- 서버리스 Spark 및 BigQuery 노트북을 실행하여 코드를 빠르게 개발
- JupyterLab에서 BigQuery 데이터 세트 찾아보기 및 미리보기
- JupyterLab에서 Cloud Storage 파일 수정
- Composer에서 노트북 예약
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면 다음 명령어를 실행합니다.
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Enable the Dataproc API.
-
Install the Google Cloud CLI.
-
외부 ID 공급업체(IdP)를 사용하는 경우 먼저 제휴 ID로 gcloud CLI에 로그인해야 합니다.
-
gcloud CLI를 초기화하려면 다음 명령어를 실행합니다.
gcloud init python.org/downloads에서 Python 버전 3.11 이상을 다운로드하여 설치합니다.- Python 3.11 이상이 설치되었는지 확인합니다.
python3 --version
- Python 3.11 이상이 설치되었는지 확인합니다.
Python 환경을 가상화합니다.
pip3 install pipenv
- 설치 폴더를 만듭니다.
mkdir jupyter
- 설치 폴더로 변경합니다.
cd jupyter
- 가상 환경을 만듭니다.
pipenv shell
- 설치 폴더를 만듭니다.
가상 환경에 JupyterLab을 설치합니다.
pipenv install jupyterlab
JupyterLab 확장 프로그램을 설치합니다.
pipenv install bigquery-jupyter-plugin
jupyter lab
JupyterLab 런처 페이지가 브라우저에 열립니다. 여기에 Dataproc 작업 및 세션 섹션이 포함되어 있습니다. 프로젝트에서 실행되는 Jupyter 선택적 구성요소를 사용하는 Dataproc Serverless 노트북 또는 Dataproc 클러스터에 액세스할 수 있는 경우 Apache Spark용 서버리스 노트북 및 Dataproc 클러스터 노트북 섹션도 포함될 수 있습니다.
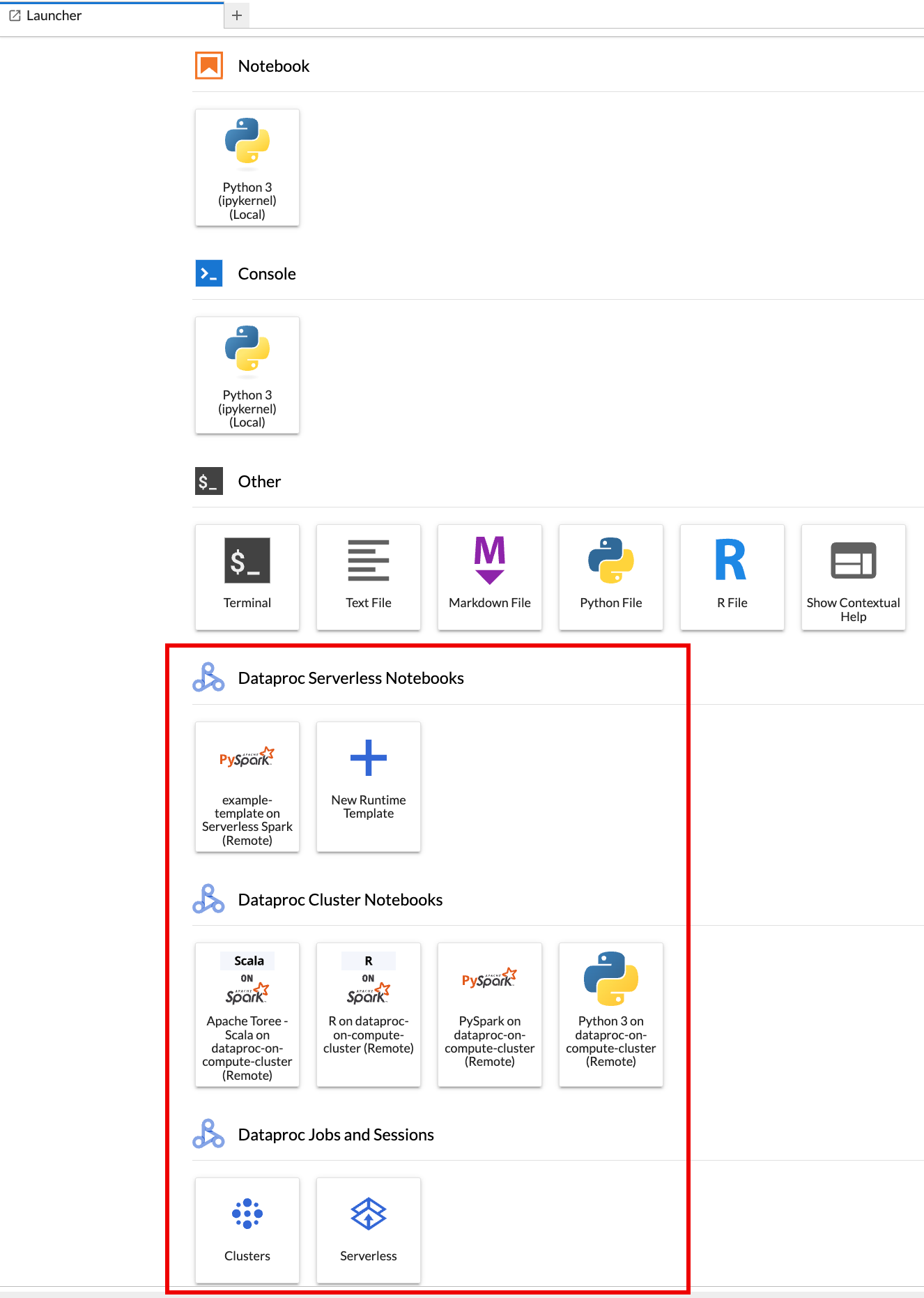
기본적으로 Apache Spark용 Serverless Interactive 세션은 시작하기 전에에서
gcloud init를 실행할 때 설정한 프로젝트 및 리전에서 실행됩니다. JupyterLab 설정 > Google Cloud 설정 > Google Cloud 프로젝트 설정에서 세션의 프로젝트 및 리전 설정을 변경할 수 있습니다.변경사항을 적용하려면 확장 프로그램을 다시 시작해야 합니다.
JupyterLab 런처 페이지의 Apache Spark용 서버리스 노트북 섹션에서
New runtime template카드를 클릭합니다.
런타임 템플릿 양식을 작성합니다.
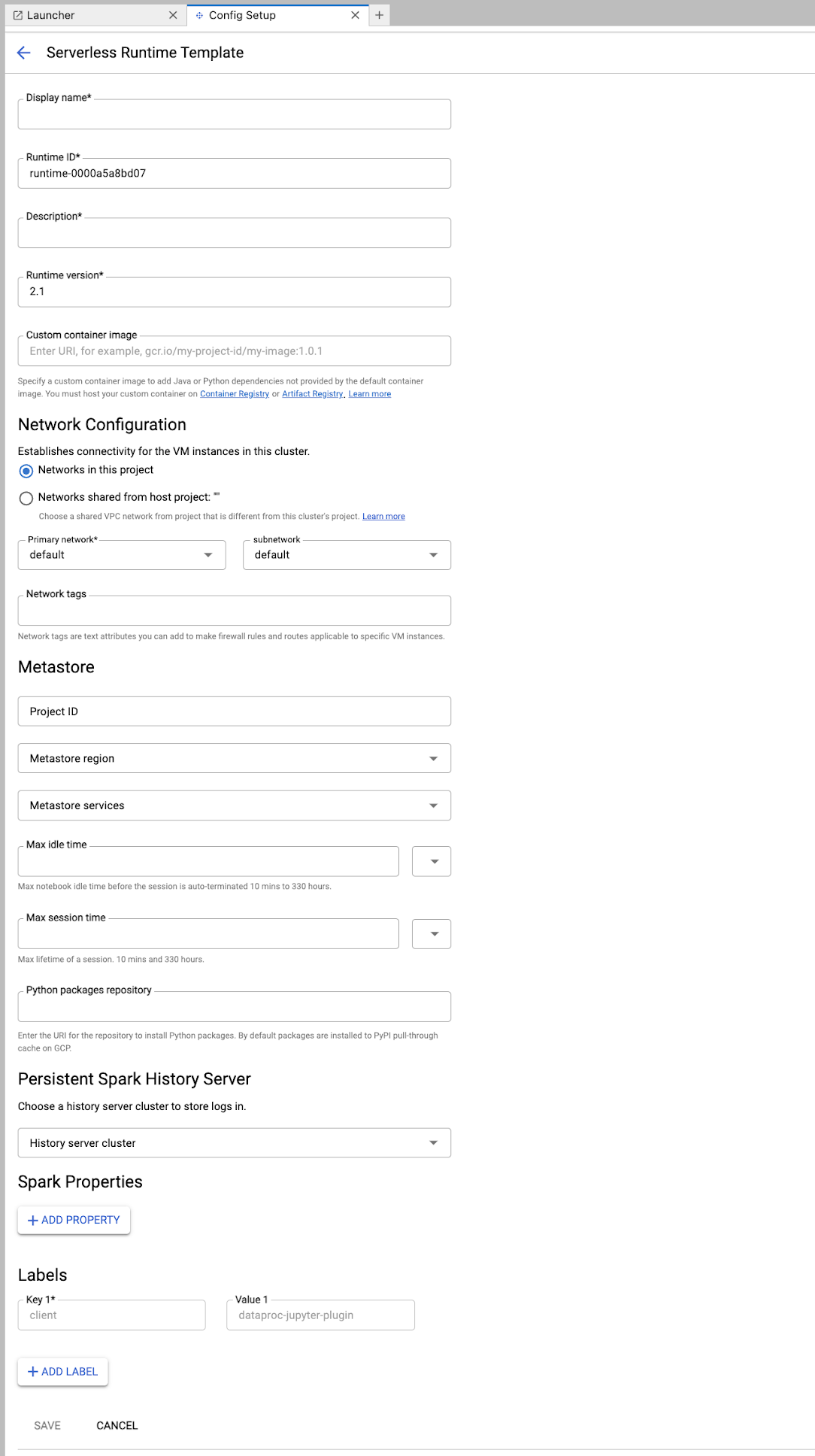
템플릿 정보:
- 표시 이름, 런타임 ID, 설명: 템플릿 표시 이름, 템플릿 런타임 ID, 템플릿 설명을 수락하거나 입력합니다.
실행 구성: Dataproc 서비스 계정 ID 대신 사용자 ID로 노트북을 실행하려면 사용자 계정을 선택합니다.
- 서비스 계정: 서비스 계정을 지정하지 않으면 Compute Engine 기본 서비스 계정이 사용됩니다.
- 런타임 버전: 런타임 버전을 확인하거나 선택합니다.
- 커스텀 컨테이너 이미지: 선택적으로 커스텀 컨테이너 이미지의 URI를 지정합니다.
- 스테이징 버킷: Apache Spark용 서버리스에서 사용할 Cloud Storage 스테이징 버킷의 이름을 선택적으로 지정할 수 있습니다.
- Python 패키지 저장소: 기본적으로 사용자가 노트북에서
pip설치 명령어를 실행하면 Python 패키지가 PyPI 풀스루 캐시에서 다운로드되고 설치됩니다. Python 패키지의 조직 비공개 아티팩트 저장소를 기본 Python 패키지 저장소로 사용하도록 지정할 수 있습니다.
암호화: 기본값인 Google-owned and Google-managed encryption key를 그대로 사용하거나 고객 관리 암호화 키 (CMEK)를 선택합니다. CMEK인 경우 키 정보를 선택하거나 제공합니다.
네트워크 구성: 프로젝트에서 서브네트워크를 선택하거나 호스트 프로젝트에서 공유합니다. JupyterLab 설정 > Google Cloud 설정 > Google Cloud 프로젝트 설정에서 프로젝트를 변경할 수 있습니다. 지정된 네트워크에 적용할 네트워크 태그를 지정할 수 있습니다. Apache Spark용 서버리스는 지정된 서브넷에서 비공개 Google 액세스 (PGA)를 사용 설정합니다. 네트워크 연결 요구사항은 Google Cloud Apache Spark용 서버리스 네트워크 구성을 참고하세요.
세션 구성: 원하는 경우 이 필드를 작성하여 템플릿으로 생성된 세션의 기간을 제한할 수 있습니다.
- 최대 유휴 시간: 세션이 종료되기 전 최대 유휴 시간입니다. 허용 범위는 10분~336시간(14일)입니다.
- 최대 세션 시간: 세션이 종료되기 전 세션의 최대 수명 시간입니다. 허용 범위는 10분~336시간(14일)입니다.
Metastore: 세션에서 Dataproc Metastore 서비스를 사용하려면 메타스토어 프로젝트 ID와 서비스를 선택합니다.
영구 기록 서버: 사용 가능한 영구 Spark 기록 서버를 선택하여 세션 중 및 세션 후에 세션 로그에 액세스할 수 있도록 허용할 수 있습니다.
Spark 속성: Spark 리소스 할당, 자동 확장 또는 GPU 속성을 선택한 후 추가할 수 있습니다. 속성 추가를 클릭하여 다른 Spark 속성을 추가합니다. 자세한 내용은 Spark 속성을 참고하세요.
라벨: 각 라벨마다 라벨 추가를 클릭하여 템플릿으로 만든 세션에 설정합니다.
저장을 클릭하여 템플릿을 만듭니다.
런타임 템플릿을 보거나 삭제합니다.
- 설정 > Google Cloud 설정을 클릭합니다.
Dataproc 설정 > 서버리스 런타임 템플릿 섹션에 런타임 템플릿 목록이 표시됩니다.
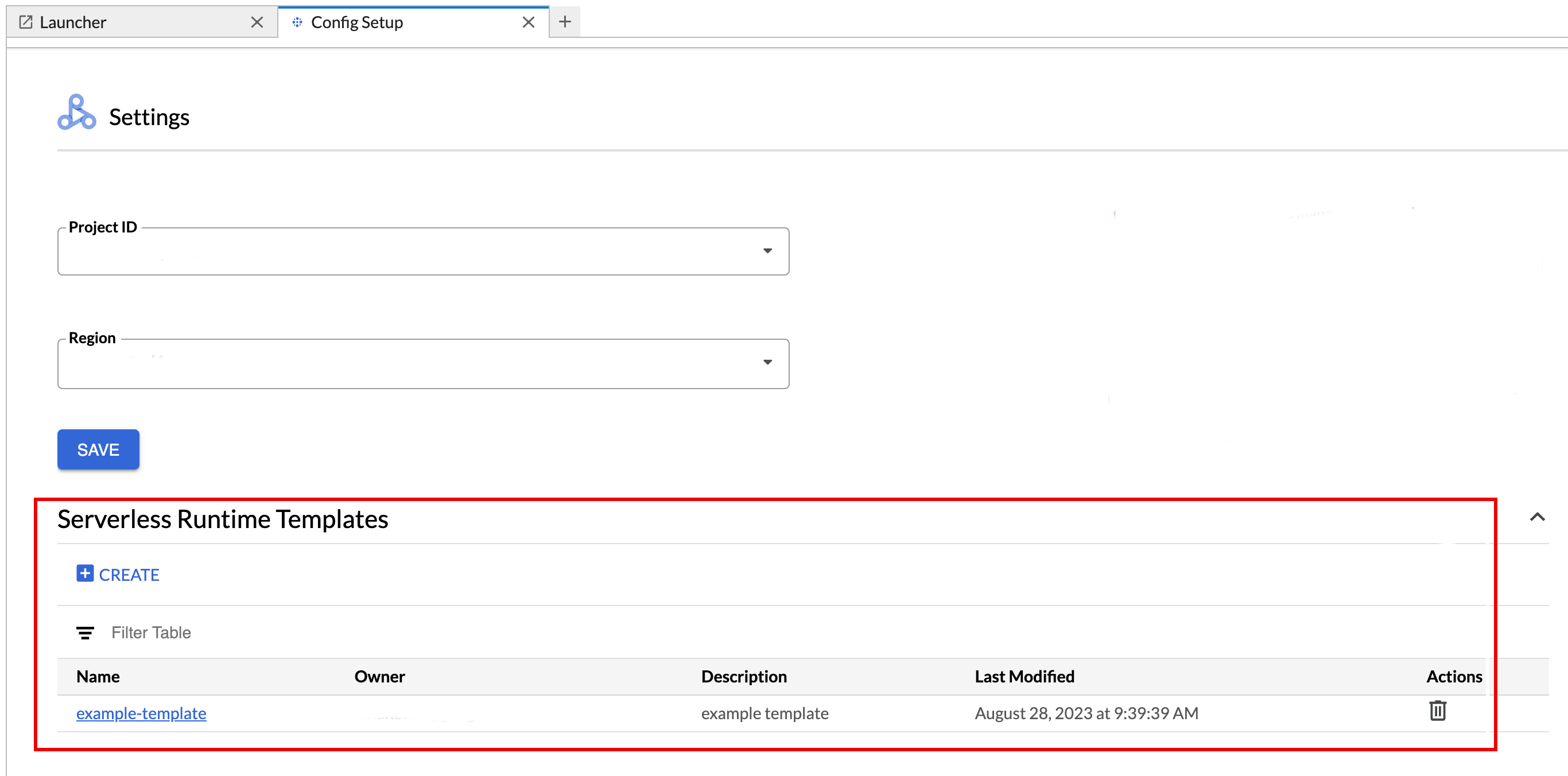
- 템플릿 이름을 클릭하여 템플릿 세부정보를 확인합니다.
- 템플릿의 작업 메뉴에서 템플릿을 삭제할 수 있습니다.
JupyterLab 런처 페이지를 열고 새로고침하여 JupyterLab 런처 페이지의 저장된 노트북 템플릿 카드를 확인합니다.

런타임 템플릿 구성으로 YAML 파일을 만듭니다.
간단한 YAML
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
복잡한 YAML
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
로컬 또는 Cloud Shell에서 다음 gcloud beta dataproc session-templates import 명령어를 실행하여 YAML 파일에서 세션(런타임) 템플릿을 만듭니다.
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- 세션 템플릿을 설명, 나열, 내보내기, 삭제하는 명령어는 gcloud beta dataproc session-templates를 참조하세요.
카드를 클릭하여 Apache Spark용 서버리스 세션을 만들고 노트북을 실행합니다. 세션 생성이 완료되고 노트북 커널을 사용할 준비가 되면 커널 상태가
Starting에서Idle (Ready)로 변경됩니다.노트북 코드를 작성하고 테스트합니다.
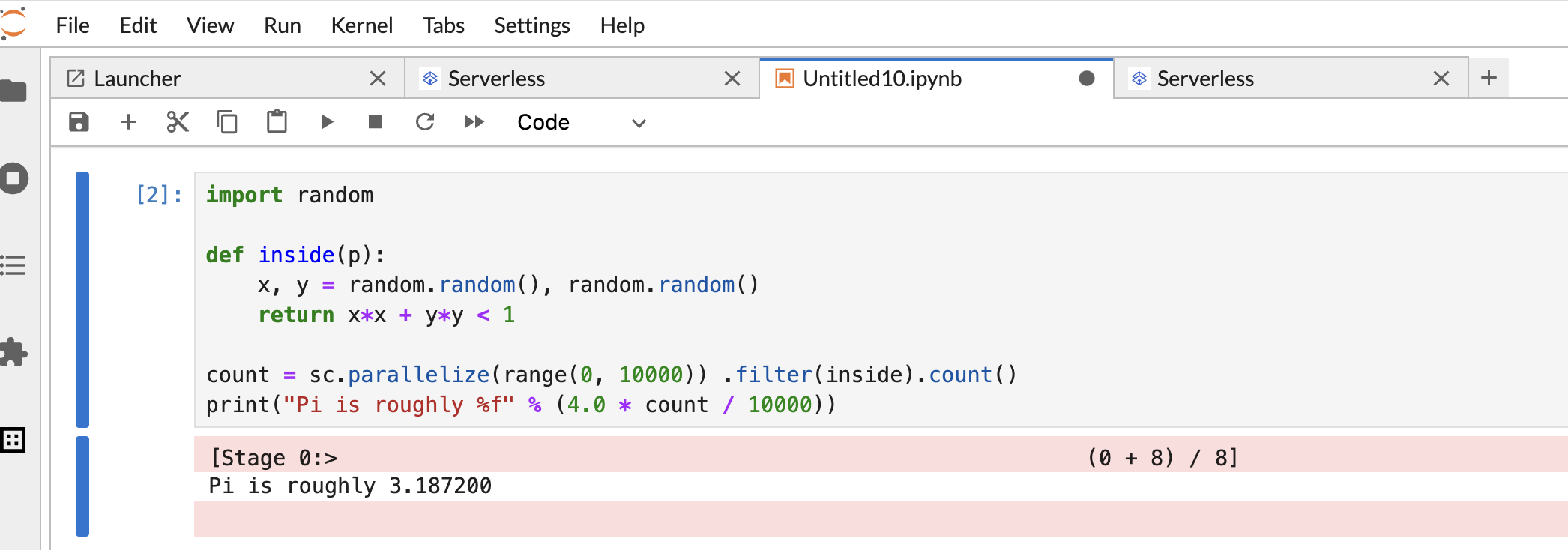
PySpark 노트북 셀에 다음 PySpark
Pi estimation코드를 복사하여 붙여넣은 후 Shift+Return을 눌러 코드를 실행합니다.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
노트북 결과:
메모장을 만들고 사용한 후 커널 탭에서 커널 종료를 클릭하여 메모장 세션을 종료할 수 있습니다.
- 세션을 재사용하려면 파일>>새로 만들기 메뉴에서 노트북을 선택하여 새 노트북을 만듭니다. 새 노트북이 생성된 후 커널 선택 대화상자에서 기존 세션을 선택합니다. 새 노트북은 세션을 재사용하고 이전 노트북의 세션 컨텍스트를 유지합니다.
세션을 종료하지 않으면 Dataproc에서 세션 유휴 타이머가 만료될 때 세션을 종료합니다. 런타임 템플릿 구성에서 세션 유휴 시간을 구성할 수 있습니다. 기본 세션 유휴 시간은 1시간입니다.
Dataproc 클러스터 노트북 섹션에서 카드를 클릭합니다.
커널 상태가
Starting에서Idle (Ready)로 변경되면 메모장 코드 작성 및 실행을 시작할 수 있습니다.메모장을 만들고 사용한 후 커널 탭에서 커널 종료를 클릭하여 메모장 세션을 종료할 수 있습니다.
Cloud Storage 브라우저에 액세스하려면 JupyterLab 런처 페이지 사이드바에서 Cloud Storage 브라우저 아이콘을 클릭한 다음 폴더를 더블클릭하여 콘텐츠를 확인합니다.
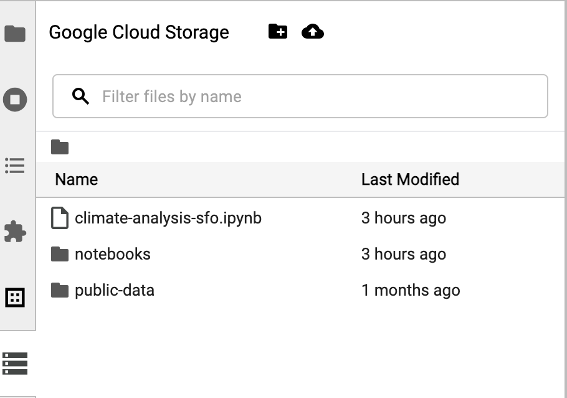
Jupyter에서 지원하는 파일 형식을 클릭하여 열고 수정할 수 있습니다. 파일에 대한 변경 사항을 저장하면 Cloud Storage에 기록됩니다.
새 Cloud Storage 폴더를 만들려면 새 폴더 아이콘을 클릭한 다음 폴더 이름을 입력하세요.
Cloud Storage 버킷 또는 폴더에 파일을 업로드하려면 업로드 아이콘을 클릭한 다음 업로드할 파일을 선택합니다.
JupyterLab 런처 페이지의 Apache Spark용 서버리스 노트북 또는 Dataproc 클러스터 노트북 섹션에서 PySpark 카드를 클릭하여 PySpark 노트북을 엽니다.
JupyterLab 런처 페이지의 Dataproc 클러스터 노트북 섹션에서 Python 커널 카드를 클릭하여 Python 노트북을 엽니다.
JupyterLab 런처 페이지의 Dataproc 클러스터 노트북 섹션에서 Apache Toree 카드를 클릭하여 Scala 코드 개발을 위한 노트북을 엽니다.

그림 1. JupyterLab 런처 페이지의 Apache Toree 커널 카드 - Apache Spark용 서버리스 노트북에서 Spark 코드를 개발하고 실행합니다.
- Apache Spark용 Dataproc Serverless 런타임 (세션) 템플릿, 대화형 세션, 배치 워크로드를 만들고 관리합니다.
- BigQuery 노트북을 개발하고 실행합니다.
- BigQuery 데이터 세트를 탐색, 검사, 미리보기합니다.
- VS Code 다운로드 및 설치
- VS Code를 열고 작업 표시줄에서 확장 프로그램을 클릭합니다.
검색창을 사용하여 Jupyter 확장 프로그램을 찾은 다음 설치를 클릭합니다. Microsoft의 Jupyter 확장 프로그램은 필수 종속 항목입니다.
- VS Code를 열고 작업 표시줄에서 확장 프로그램을 클릭합니다.
검색창을 사용하여 Google Cloud Code 확장 프로그램을 찾은 다음 설치를 클릭합니다.

메시지가 표시되면 VS Code를 다시 시작합니다.
- VS Code를 열고 작업 표시줄에서 Google Cloud Code를 클릭합니다.
- Dataproc 섹션을 엽니다.
- Google Cloud에 로그인을 클릭합니다. 사용자 인증 정보로 로그인하도록 리디렉션됩니다.
- 최상위 애플리케이션 작업 표시줄을 사용하여 코드 > 설정 > 설정 > 확장 프로그램으로 이동합니다.
- Google Cloud 코드를 찾아 관리 아이콘을 클릭하여 메뉴를 엽니다.
- 설정을 선택합니다.
- 프로젝트 및 Dataproc 리전 필드에 Google Cloud 프로젝트 이름과 서버리스 Apache Spark 리소스를 개발하고 관리하는 데 사용할 리전을 입력합니다.
- VS Code를 열고 작업 표시줄에서 Google Cloud Code를 클릭합니다.
- 노트북 섹션을 열고 새 서버리스 Spark 노트북을 클릭합니다.
- 노트북 세션에 사용할 새 런타임 (세션) 템플릿을 선택하거나 만듭니다.
샘플 코드가 포함된 새
.ipynb파일이 생성되어 편집기에서 열립니다.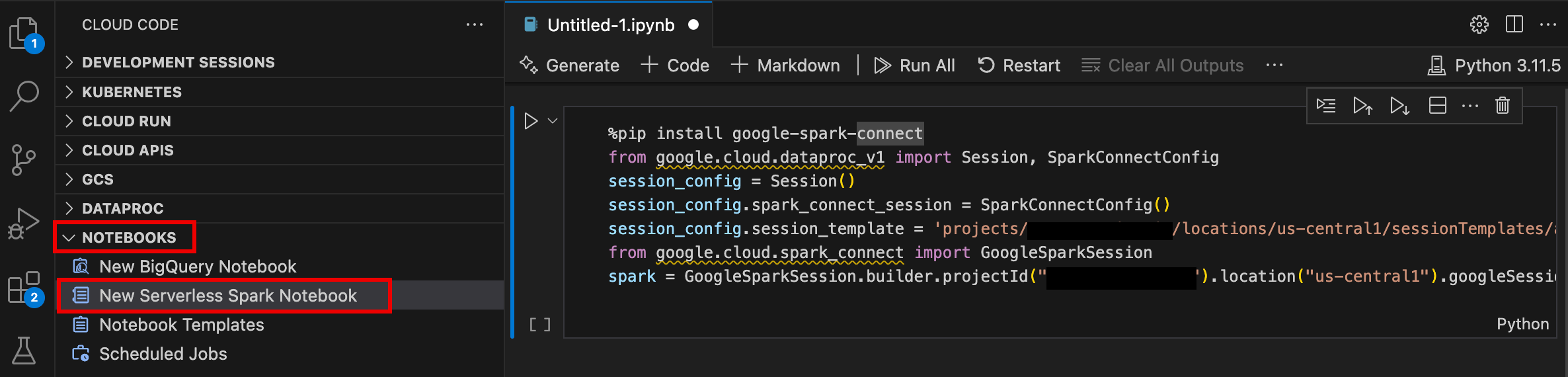
이제 Apache Spark용 서버리스 노트북에서 코드를 작성하고 실행할 수 있습니다.
- VS Code를 열고 작업 표시줄에서 Google Cloud Code를 클릭합니다.
Dataproc 섹션을 열고 다음 리소스 이름을 클릭합니다.
- 클러스터: 클러스터 및 작업을 만들고 관리합니다.
- 서버리스: 배치 워크로드 및 대화형 세션을 만들고 관리합니다.
- Spark 런타임 템플릿: 세션 템플릿을 만들고 관리합니다.

Google Cloud Apache Spark용 서버리스 인프라에서 노트북 코드 실행
Cloud Composer에서 노트북 실행 예약
Google Cloud Apache Spark용 서버리스 인프라 또는 Compute Engine 기반 Dataproc 클러스터에 일괄 작업을 제출합니다.
노트북 오른쪽 상단의 작업 스케줄러 버튼을 클릭합니다.
예약된 작업 만들기 양식을 작성하여 다음 정보를 제공합니다.
- 노트북 실행 작업의 고유한 이름
- 노트북을 배포하는 데 사용할 Cloud Composer 환경
- 노트북이 매개변수화된 경우 입력 매개변수
- 노트북을 실행하는 데 사용할 Dataproc 클러스터 또는 서버리스 런타임 템플릿입니다.
- 클러스터가 선택된 경우 노트북이 클러스터에서 실행을 완료한 후 클러스터를 중지할지 여부
- 첫 번째 시도에서 노트북 실행이 실패한 경우 재시도 횟수 및 재시도 지연 시간(분)
- 전송할 실행 알림 및 수신자 목록입니다. 알림은 Airflow SMTP 구성을 사용하여 전송됩니다.
- 노트북 실행 일정
만들기를 클릭합니다.
노트북이 예약되면 Cloud Composer 환경의 예약된 작업 목록에 작업 이름이 표시됩니다.

JupyterLab 런처 페이지의 Dataproc 작업 및 세션 섹션에서 서버리스 카드를 클릭합니다.
일괄 탭을 클릭한 다음 일괄 만들기를 클릭하고 일괄 정보 필드를 입력합니다.
제출을 클릭하여 작업을 제출합니다.
JupyterLab 런처 페이지의 Dataproc 작업 및 세션 섹션에서 클러스터 카드를 클릭합니다.
작업 탭을 클릭한 다음 작업 제출을 클릭합니다.
클러스터를 선택한 후 작업 필드를 작성합니다.
제출을 클릭하여 작업을 제출합니다.
- 서버리스 카드를 클릭합니다.
- 세션 탭을 클릭한 다음 세션 ID를 클릭하여 세션 세부정보 페이지를 연 후 세션 속성을 보고 로그 탐색기에서 Google Cloud 로그를 확인하고 세션을 종료합니다. 참고: 각 Google Cloud Apache Spark용 서버리스 노트북을 실행하기 위해 고유한 Google Cloud Apache Spark용 서버리스 세션이 생성됩니다.
- 배치 탭을 클릭하여 현재 프로젝트와 리전의 Google Cloud Apache Spark를 위한 서버리스 배치 목록을 봅니다. 일괄 ID를 클릭하여 일괄 세부정보를 확인합니다.
- 클러스터 카드를 클릭합니다. 현재 프로젝트와 리전의 활성 Compute Engine 기반 Dataproc 클러스터를 나열하려면 클러스터 탭을 선택합니다. 작업 열의 아이콘을 클릭하여 클러스터를 시작, 중지 또는 다시 시작할 수 있습니다. 클러스터 이름을 클릭하여 클러스터 세부정보를 확인합니다. 작업 열의 아이콘을 클릭하여 작업을 클론, 중지 또는 삭제할 수 있습니다.
- 작업 카드를 클릭하여 현재 프로젝트의 작업 목록을 확인하세요. 세부정보를 보려면 작업 ID를 클릭하세요.
JupyterLab 확장 프로그램 설치
로컬 머신 또는 Compute Engine VM 인스턴스와 같은 Google 서비스에 액세스할 수 있는 머신 또는 VM에 JupyterLab 확장 프로그램을 설치하고 사용할 수 있습니다.
확장 프로그램을 설치하려면 다음 단계를 따르세요.
Apache Spark용 서버리스 런타임 템플릿 만들기
Apache Spark용 서버리스 런타임 템플릿 (세션 템플릿이라고도 함)에는 세션에서 Spark 코드를 실행하기 위한 구성 설정이 포함됩니다. Jupyterlab 또는 gcloud CLI를 사용하여 런타임 템플릿을 만들고 관리할 수 있습니다.
JupyterLab
gcloud
노트북 실행 및 관리
Dataproc JupyterLab 확장 프로그램을 설치한 후 JupyterLab 런처 페이지에서 템플릿 카드를 클릭하여 다음 작업을 할 수 있습니다.
Apache Spark용 서버리스에서 Jupyter 노트북 실행
JupyterLab 런처 페이지의 Apache Spark용 서버리스 노트북 섹션에는 Apache Spark용 서버리스 런타임 템플릿에 매핑되는 노트북 템플릿 카드가 표시됩니다 (Apache Spark용 서버리스 런타임 템플릿 만들기 참고).

Compute Engine 기반 Dataproc 클러스터에서 노트북 실행
Compute Engine 기반 Dataproc Jupyter 클러스터를 만든 경우 JupyterLab 런처 페이지에 커널 카드가 사전 설치된 Dataproc 클러스터 노트북 섹션이 포함되어 있습니다.
Compute Engine 기반 Dataproc 클러스터에서 Jupyter 노트북을 실행하려면 다음 단계를 따르세요.
Cloud Storage에서 입력 및 출력 파일 관리
탐색적 데이터를 분석하고 ML 모델을 빌드하는 데는 파일 기반 입력과 출력이 필요한 경우가 많습니다. Apache Spark용 서버리스는 Cloud Storage의 이러한 파일에 액세스합니다.
Spark 노트북 코드 개발
Dataproc JupyterLab 확장 프로그램을 설치한 후 JupyterLab 런처 페이지에서 Jupyter 노트북을 실행하여 애플리케이션 코드를 개발할 수 있습니다.
PySpark 및 Python 코드 개발
Apache Spark를 위한 서버리스 및 Compute Engine 기반 Dataproc 클러스터는 PySpark 커널을 지원합니다. Compute Engine 기반 Dataproc은 Python 커널도 지원합니다.
SQL 코드 개발
SQL 코드를 작성하고 실행할 PySpark 노트북을 열려면 JupyterLab 런처 페이지의 Apache Spark용 서버리스 노트북 또는 Dataproc 클러스터 노트북 섹션에서 PySpark 커널 카드를 클릭합니다.
Spark SQL 매직: Apache Spark용 서버리스 노트북을 실행하는 PySpark 커널에는 Spark SQL 매직이 미리 로드되어 있으므로 spark.sql('SQL STATEMENT').show()를 사용하여 SQL 문을 래핑하는 대신에 셀의 상단에 %%sparksql magic을 입력한 다음 셀의 SQL 문을 입력합니다.
BigQuery SQL: BigQuery Spark 커넥터를 사용하면 노트북 코드가 BigQuery 테이블에서 데이터를 로드하고, Spark에서 분석을 수행한 다음 결과를 BigQuery 테이블에 쓸 수 있습니다.
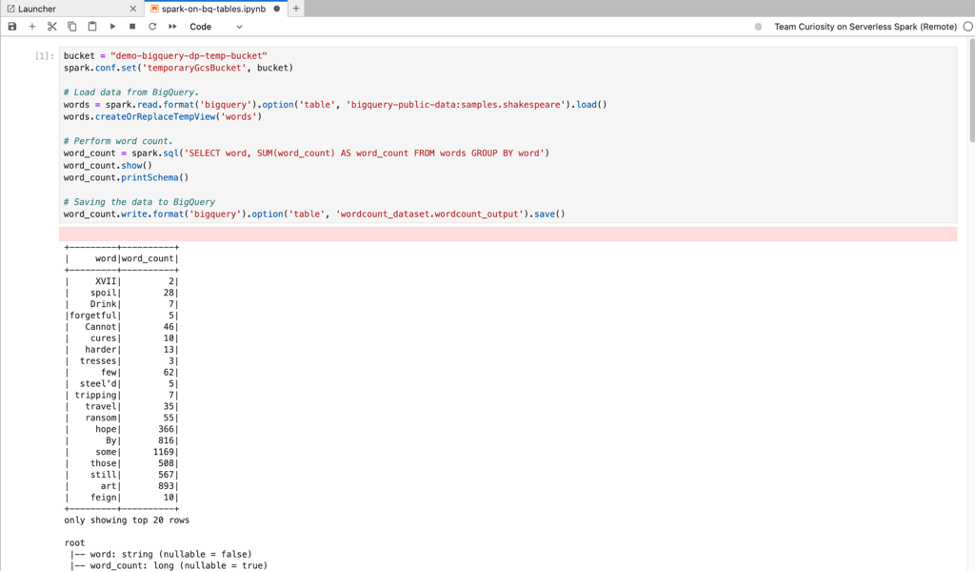
Apache Spark용 서버리스 2.2 이상의 런타임에는 BigQuery Spark 커넥터가 포함되어 있습니다.
이전 런타임을 사용하여 Apache Spark용 서버리스 노트북을 실행하는 경우 Apache Spark용 서버리스 런타임 템플릿에 다음 Spark 속성을 추가하여 Spark BigQuery 커넥터를 설치할 수 있습니다.
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Scala 코드 개발
이미지 버전 2.0 이상으로 생성된 Compute Engine 기반 Dataproc 클러스터에는 Spark에 대한 대화형 액세스를 제공하는 Jupyter 노트북 플랫폼용 Scala 커널인 Apache Toree가 포함되어 있습니다.
Visual Studio Code 확장 프로그램으로 코드 개발
Google Cloud Visual Studio Code (VS Code) 확장 프로그램을 사용하면 다음 작업을 할 수 있습니다.
Visual Studio Code 확장 프로그램은 무료이지만 Dataproc, Apache Spark용 서버리스, Cloud Storage 리소스 등 사용하는Google Cloud 서비스에 대한 요금이 청구됩니다.
BigQuery와 함께 VS Code 사용: BigQuery와 함께 VS Code를 사용하여 다음 작업을 할 수도 있습니다.
시작하기 전에
Google Cloud 확장 프로그램 설치
이제 VS Code 작업 표시줄에 Google Cloud 코드 아이콘이 표시됩니다.
확장 프로그램 구성
Apache Spark용 서버리스 노트북 개발
Apache Spark용 서버리스 리소스 만들기 및 관리
데이터 세트 탐색기
JupyterLab 데이터 세트 탐색기를 사용하여 BigLake metastore 데이터 세트를 확인합니다.
JupyterLab 데이터 세트 탐색기를 열려면 사이드바에서 해당 아이콘을 클릭합니다.
데이터 세트 탐색기에서 데이터베이스, 테이블 또는 열을 검색할 수 있습니다. 데이터베이스, 테이블 또는 열 이름을 클릭하여 연결된 메타데이터를 확인합니다.
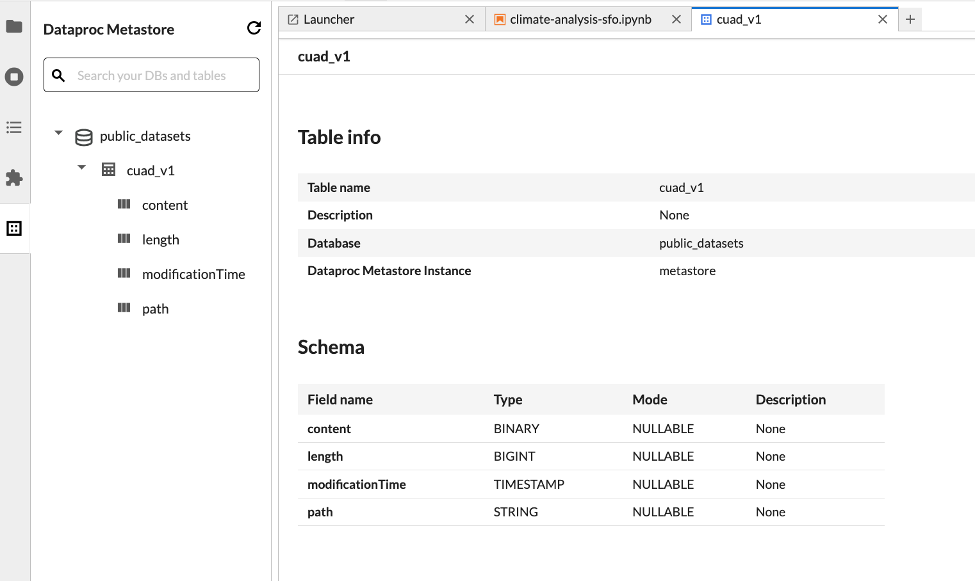
코드 배포
Dataproc JupyterLab 확장 프로그램을 설치한 후 JupyterLab을 사용하여 다음 작업을 할 수 있습니다.
Cloud Composer에서 노트북 실행 예약
다음 단계에 따라 Cloud Composer에서 노트북 코드를 예약하여 Apache Spark용 서버리스 또는 Compute Engine 기반 Dataproc 클러스터에서 일괄 작업으로 실행합니다.
Google Cloud Apache Spark용 서버리스에 일괄 작업 제출
Compute Engine 기반 Dataproc 클러스터에 일괄 작업 제출
리소스 보기 및 관리
Dataproc JupyterLab 확장 프로그램을 설치한 후 JupyterLab 런처 페이지의 Dataproc 작업 및 세션 섹션에서 Google Cloud Apache Spark용 Serverless와 Compute Engine의 Dataproc을 보고 관리할 수 있습니다.
Dataproc 작업 및 세션 섹션을 클릭하여 클러스터와 서버리스 카드를 표시합니다.
Google Cloud Apache Spark용 서버리스 세션을 보고 관리하려면 다음 단계를 따르세요.
Google Cloud Apache Spark용 서버리스 배치를 보고 관리하려면 다음 안내를 따르세요.
Compute Engine 기반 Dataproc 클러스터를 보고 관리하려면 다음 안내를 따르세요.
Compute Engine 기반 Dataproc 작업을 보고 관리하려면 다음 안내를 따르세요.