このドキュメントでは、Google サービスにアクセスできるマシンまたはセルフマネージド VM に JupyterLab 拡張機能をインストールして使用する方法について説明します。また、サーバーレス Spark ノートブック コードを開発してデプロイする方法についても説明します。
拡張機能を数分でインストールして、次の機能を活用できます。
- サーバーレスの Spark ノートブックと BigQuery ノートブックを起動して、コードを迅速に開発する
- JupyterLab で BigQuery データセットをブラウジングしてプレビューする
- JupyterLab で Cloud Storage ファイルを編集する
- Composer でノートブックのスケジュールを設定する
始める前に
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
外部 ID プロバイダ(IdP)を使用している場合は、まず連携 ID を使用して gcloud CLI にログインする必要があります。
-
gcloud CLI を初期化するには、次のコマンドを実行します。
gcloud init python.org/downloadsから Python バージョン 3.11 以降をダウンロードしてインストールします。- Python 3.11 以降のインストールを確認します。
python3 --version
- Python 3.11 以降のインストールを確認します。
Python 環境を仮想化します。
pip3 install pipenv
- インストール フォルダを作成します。
mkdir jupyter
- インストール フォルダに移動します。
cd jupyter
- 仮想環境を作成します。
pipenv shell
- インストール フォルダを作成します。
仮想環境に JupyterLab をインストールします。
pipenv install jupyterlab
JupyterLab 拡張機能をインストールします。
pipenv install bigquery-jupyter-plugin
jupyter lab
ブラウザで JupyterLab の [Launcher] ページが開きます。これには、[Dataproc Jobs and Sessions] セクションが含まれています。また、次のものが含まれる場合もあります:プロジェクトで Jupyter のオプション コンポーネントを実行している Dataproc サーバーレス ノートブックまたは Dataproc クラスタにアクセスできる場合は、Apache Spark ノートブック向けサーバーレスおよび Dataproc クラスタ ノートブックのセクションを含めることもできます。
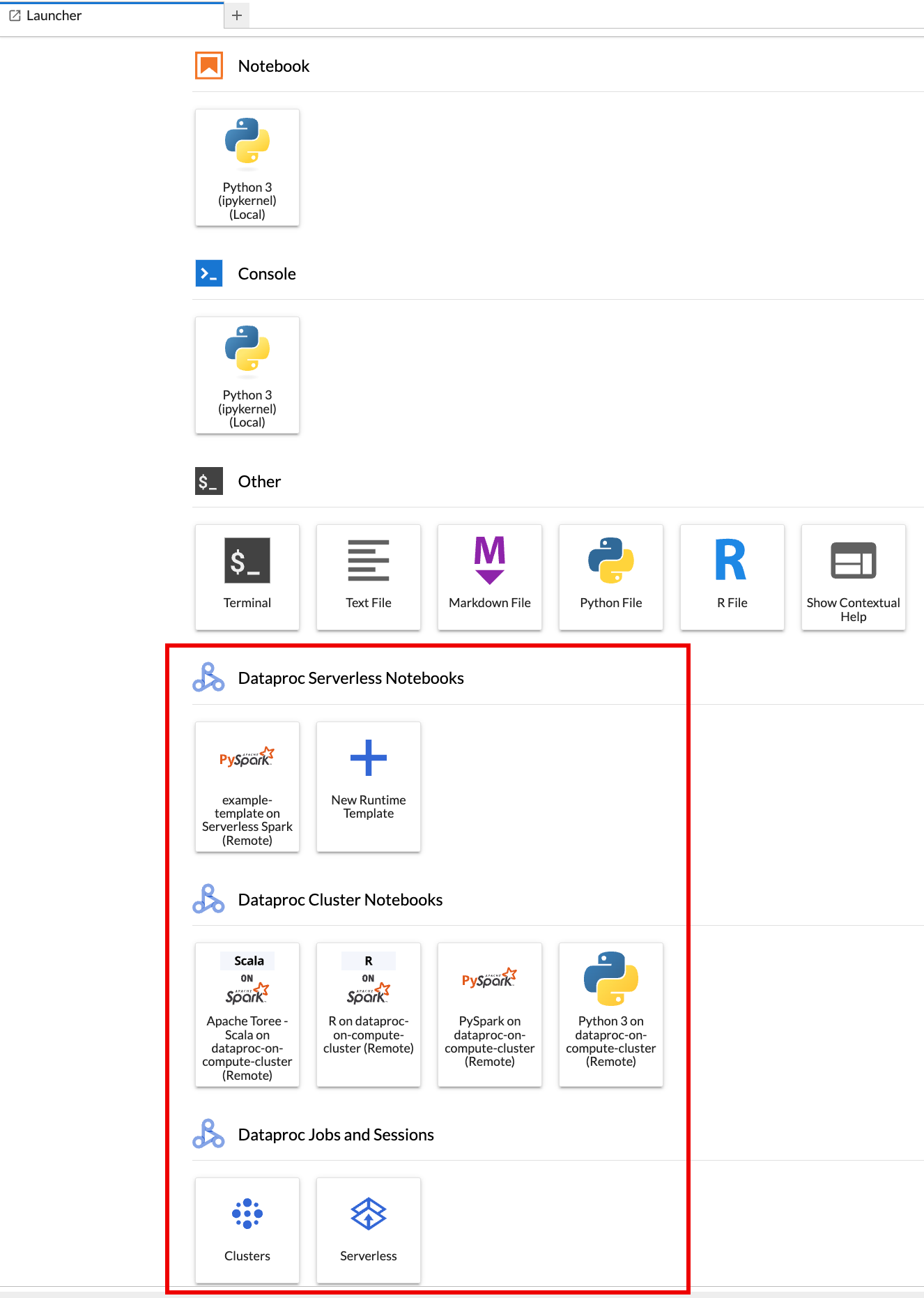
デフォルトでは、Apache Spark 向け Serverless のインタラクティブ セッションは、始める前にで
gcloud initを実行したときに設定したプロジェクトとリージョンで実行されます。セッションのプロジェクトとリージョンの設定は、JupyterLab の [設定] > Google Cloud [設定] > Google Cloud [プロジェクトの設定] で変更できます。変更を有効にするには、拡張機能を再起動する必要があります。
JupyterLab の [ランチャー] ページの [Apache Spark 用 Serverless ノートブック] セクションで
New runtime templateカードをクリックします。
ランタイム テンプレート フォームに入力します。
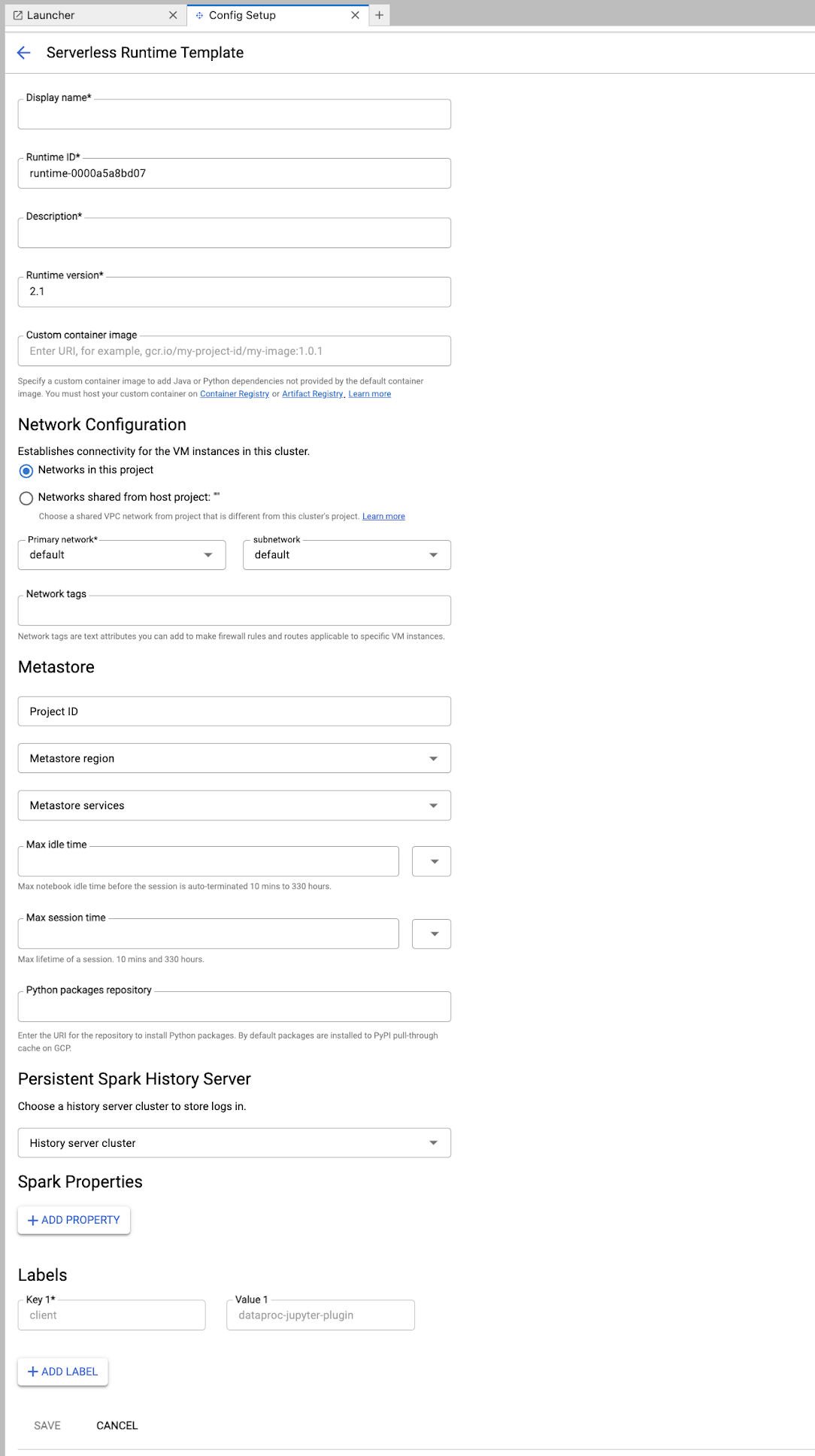
テンプレート情報:
- 表示名、ランタイム ID、説明: テンプレートの表示名、テンプレートのランタイム ID、テンプレートの説明を受け入れるか、入力します。
実行構成: Dataproc サービス アカウント ID ではなくユーザー ID でノートブックを実行するには、[ユーザー アカウント] を選択します。
- サービス アカウント: サービス アカウントを指定しない場合は、Compute Engine のデフォルトのサービス アカウントが使用されます。
- ランタイム バージョン: ランタイム バージョンを確認または選択します。
- カスタム コンテナ イメージ: 必要に応じて、カスタム コンテナ イメージの URI を指定します。
- ステージング バケット: Serverless for Apache Spark で使用する Cloud Storage のステージング バケットの名前を必要に応じて指定できます。
- Python パッケージ リポジトリ: デフォルトでは、ユーザーがノートブックで
pipインストール コマンドを実行すると、Python パッケージは PyPI プルスルー キャッシュからダウンロードされてインストールされます。組織のプライベート アーティファクト リポジトリを、デフォルトの Python パッケージ リポジトリとして使用する Python パッケージ用に指定できます。
暗号化: デフォルトの Google-owned and Google-managed encryption key をそのまま使用するか、[顧客管理の暗号鍵(CMEK)] を選択します。CMEK の場合は、鍵情報を選択または指定します。
ネットワーク構成: プロジェクト内のサブネットワーク、またはホスト プロジェクトから共有されたサブネットワークを選択します(プロジェクトは、JupyterLab の [設定] > [ Google Cloud 設定] > [ Google Cloud プロジェクト設定] で変更できます)。指定したネットワークに適用するネットワーク タグを指定できます。Apache Spark 用サーバーレスは、指定されたサブネットでプライベート Google アクセス(PGA)を有効にします。ネットワーク接続の要件については、Google Cloud Apache Spark 用サーバーレス ネットワーク構成をご覧ください。
セッションの構成: 必要に応じて、これらのフィールドに入力して、テンプレートで作成されたセッションの期間を制限できます。
- 最大アイドル時間: セッションが終了するまでの最大アイドル時間。指定できる範囲: 10 分~336 時間(14 日)。
- 最大セッション時間: セッションが終了するまでのセッションの最大存続時間。指定できる範囲: 10 分~336 時間(14 日)。
Metastore: セッションで Dataproc Metastore サービスを使用するには、メタストアのプロジェクト ID とサービスを選択します。
Persistent History Server: 使用可能な Persistent Spark History Server を選択して、セッション中とセッション後にセッションログにアクセスできるようにします。
Spark プロパティ: Spark のリソース割り当て、自動スケーリング、または GPU のプロパティを選択して追加できます。[プロパティを追加] をクリックして、他の Spark プロパティを追加します。詳細については、Spark プロパティをご覧ください。
ラベル: テンプレートで作成されたセッションに設定する各ラベルの [ラベルを追加] をクリックします。
[保存] をクリックしてテンプレートを作成します。
ランタイム テンプレートを表示または削除します。
- [設定] > [ Google Cloud 設定] をクリックします。
[Dataproc の設定 > サーバーレス ランタイム テンプレート] セクションに、ランタイム テンプレートのリストが表示されます。
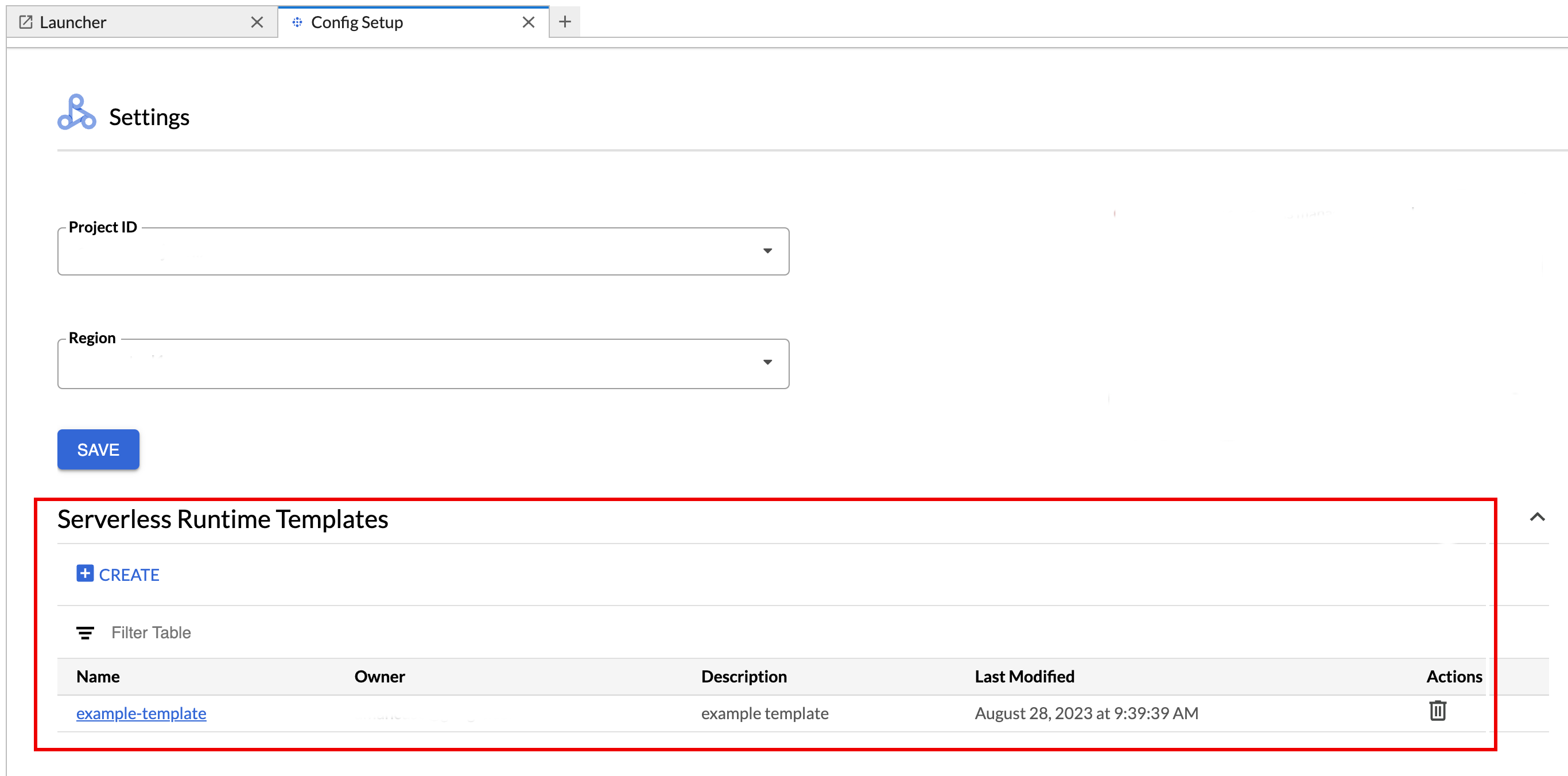
- テンプレート名をクリックして、テンプレートの詳細を表示します。
- テンプレートを削除するには、テンプレートの [操作] メニューを使用します。
JupyterLab の [ランチャー] ページを開いて再読み込みし、JupyterLab の [ランチャー] ページに保存したノートブック テンプレート カードを表示します。

ランタイム テンプレート構成を含む YAML ファイルを作成します。
単純な YAML
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
複雑な YAML
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
次の gcloud beta dataproc session-templates import コマンドをローカル、または Cloud Shell で実行して、YAML ファイルからセッション(ランタイム)テンプレートを作成します。
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- セッション テンプレートを記述、一覧表示、エクスポート、削除するコマンドについては、gcloud beta dataproc session-templates をご覧ください。
カードをクリックして Apache Spark 向け Serverless セッションを作成し、ノートブックを起動します。セッションの作成が完了し、ノートブック カーネルが使用可能になると、カーネルのステータスは
StartingからIdle (Ready)に変わります。ノートブックのコードを記述してテストします。
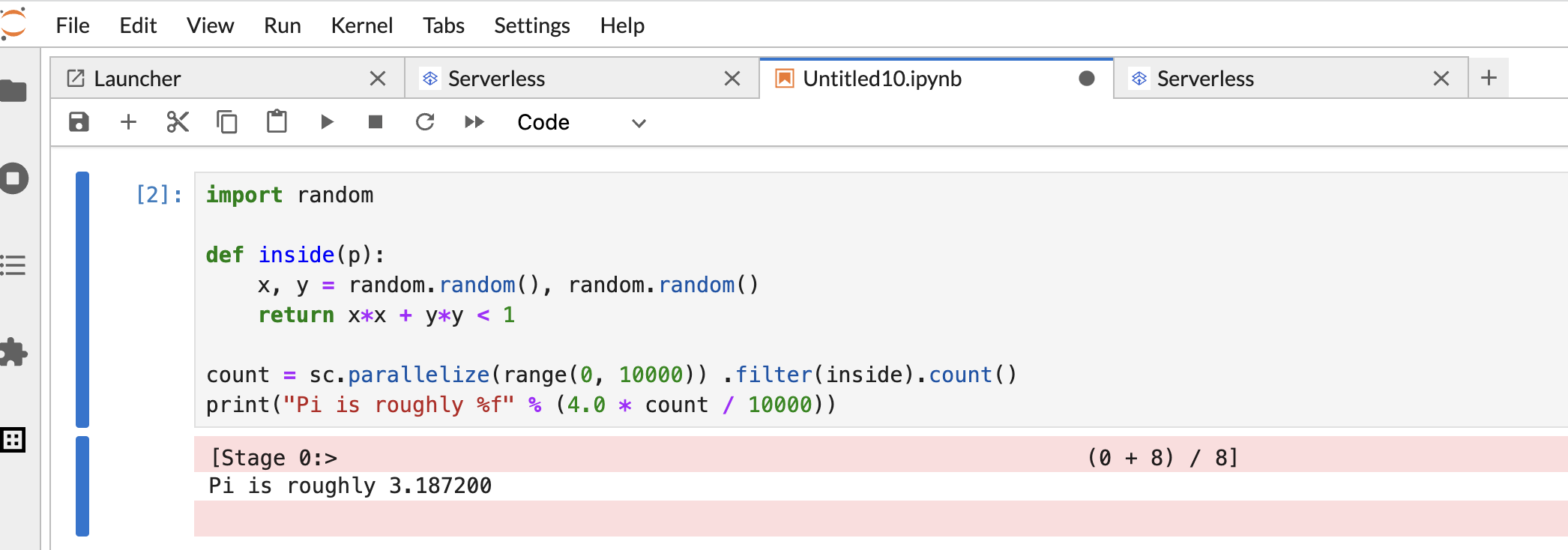
次の PySpark
Pi estimationコードをコピーして PySpark ノートブック セルに貼り付け、Shift+Return キーを押してコードを実行します。import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
ノートブックの結果:
ノートブックを作成して使用した後、[Kernel] タブで [Shut down Kernel] をクリックすると、ノートブック セッションを終了できます。
- セッションを再利用するには、[ファイル>>新規作成] メニューから [ノートブック] を選択して、新しいノートブックを作成します。新しいノートブックが作成されたら、カーネル選択ダイアログで既存のセッションを選択します。新しいノートブックは、セッションを再利用し、以前のノートブックのセッション コンテキストを保持します。
セッションを終了しない場合、セッションのアイドル タイマーが期限切れになると、Dataproc によってセッションが終了します。セッションのアイドル時間を設定するには、ランタイム テンプレートの構成を使用します。デフォルトのセッション アイドル時間は 1 時間です。
[Dataproc クラスタ ノートブック] セクションでカードをクリックします。
カーネルのステータスが
StartingからIdle (Ready)に変わったら、ノートブック コードの作成と実行を開始できます。ノートブックを作成して使用した後、[Kernel] タブで [Shut down Kernel] をクリックすると、ノートブック セッションを終了できます。
Cloud Storage ブラウザにアクセスするには、JupyterLab の [ランチャー] ページのサイドバーで Cloud Storage ブラウザ アイコンをクリックし、フォルダをダブルクリックして内容を表示します。
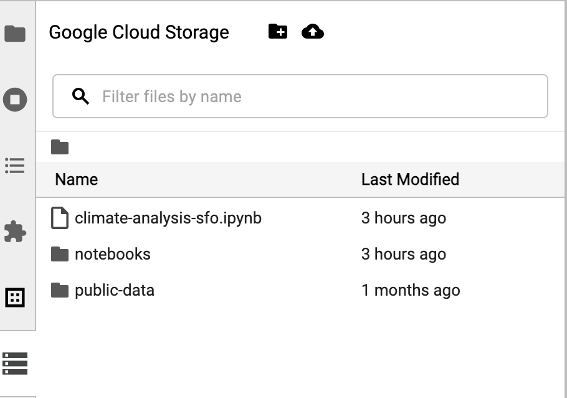
Jupyter でサポートされているファイル形式をクリックして開き、編集できます。ファイルへの変更を保存すると、Cloud Storage に書き込まれます。
新しい Cloud Storage フォルダを作成するには、新しいフォルダ アイコンをクリックして、フォルダの名前を入力します。
Cloud Storage バケットまたはフォルダにファイルをアップロードするには、アップロード アイコンをクリックして、アップロードするファイルを選択します。
JupyterLab の [ランチャー] ページの [Serverless for Apache Spark Notebooks] セクションまたは [Dataproc クラスタ ノートブック] セクションの PySpark カードをクリックして、PySpark ノートブックを開きます。
JupyterLab の [ランチャー] ページの [Dataproc クラスタ ノートブック] セクションで Python カーネルカードをクリックして、Python ノートブックを開きます。
JupyterLab の [ランチャー] ページの [Dataproc クラスタ ノートブック] セクションの Apache Toree カードをクリックして、Scala コード開発用のノートブックを開きます。

図 1. JupyterLab の [Launcher] ページの Apache Toree カーネルカード。 - Apache Spark 向け Serverless ノートブックで Spark コードを開発して実行します。
- Apache Spark 向け Serverless ランタイム(セッション)テンプレート、インタラクティブ セッション、バッチ ワークロードを作成して管理します。
- BigQuery ノートブックを開発して実行する。
- BigQuery データセットをブラウジング、検査、プレビューする。
- VS Code をダウンロードしてインストールします。
- VS Code を開き、アクティビティ バーで [Extensions] をクリックします。
検索バーを使用して Jupyter 拡張機能を見つけ、[Install] をクリックします。Microsoft の Jupyter 拡張機能は必須の依存関係です。

- VS Code を開き、アクティビティ バーで [Extensions] をクリックします。
検索バーを使用して Google Cloud Code 拡張機能を見つけ、[Install] をクリックします。

プロンプトが表示されたら、VS Code を再起動します。
- VS Code を開き、アクティビティ バーで [Google Cloud Code] をクリックします。
- [Dataproc] セクションを開きます。
- [Login to Google Cloud] をクリックします。認証情報を使用してログインするようにリダイレクトされます。
- 最上位のアプリケーション タスクバーを使用して、[Code] > [Settings] > [Settings] > [Extensions] に移動します。
- [Google Cloud Code] を見つけ、[Manage] アイコンをクリックしてメニューを開きます。
- [設定] を選択します。
- [プロジェクト] フィールドと [Dataproc リージョン] フィールドに、ノートブックの開発と Serverless for Apache Spark リソースの管理に使用する Google Cloud プロジェクトとリージョンの名前を入力します。
- VS Code を開き、アクティビティ バーで [Google Cloud Code] をクリックします。
- [ノートブック] セクションを開き、[新しいサーバーレス Spark ノートブック] をクリックします。
- ノートブック セッションで使用する新しいランタイム(セッション)テンプレートを選択または作成します。
サンプルコードを含む新しい
.ipynbファイルが作成され、エディタで開きます。
これで、Apache Spark 向け Serverless ノートブックでコードを記述して実行できるようになりました。
- VS Code を開き、アクティビティ バーで [Google Cloud Code] をクリックします。
[Dataproc] セクションを開き、次のリソース名をクリックします。
- クラスタ: クラスタとジョブを作成して管理します。
- サーバーレス: バッチ ワークロードとインタラクティブ セッションを作成して管理します。
- Spark ランタイム テンプレート: セッション テンプレートを作成して管理します。

Google Cloud Apache Spark 向け Serverless インフラストラクチャでノートブック コードを実行する
Cloud Composer でノートブックの実行をスケジュールする
Google Cloud Apache Spark 用 Serverless インフラストラクチャまたは Dataproc on Compute Engine クラスタにバッチジョブを送信します。
ノートブックの右上にある [ジョブ スケジューラ] ボタンをクリックします。

[Create A Scheduled Job] フォームに次の情報を入力します。
- ノートブック実行ジョブの一意の名前
- ノートブックのデプロイに使用する Cloud Composer 環境
- ノートブックがパラメータ化されている場合は入力パラメータ
- ノートブックの実行に使用する Dataproc クラスタまたはサーバーレス ランタイム テンプレート
- クラスタが選択されている場合、クラスタでノートブックの実行が完了した後にクラスタを停止するかどうか
- ノートブックの実行が初回で失敗した場合の再試行回数と再試行遅延(分単位)
- 送信する実行通知と受信者リスト。通知は Airflow の SMTP 構成を使用して送信されます。
- ノートブックの実行スケジュール
[作成] をクリックします。
ノートブックのスケジュールが正常に設定されると、ジョブ名が Cloud Composer 環境のスケジュールされたジョブのリストに表示されます。

JupyterLab の [ランチャー] ページの [Dataproc のジョブとセッション] セクションにある [サーバーレス] カードをクリックします。
[バッチ] タブをクリックし、[バッチを作成] をクリックして [バッチ情報] フィールドに入力します。
[送信] をクリックしてジョブを送信します。
JupyterLab の [ランチャー] ページの [Dataproc のジョブとセッション] セクションで [クラスタ] カードをクリックします。
[ジョブ] タブをクリックし、[ジョブを送信] をクリックします。
[クラスタ] を選択し、[ジョブ] フィールドに入力します。
[送信] をクリックしてジョブを送信します。
- [Serverless] カードをクリックします。
- [セッション] タブをクリックしてから、セッション ID をクリックして [セッションの詳細] ページを開き、セッション プロパティを表示し、ログ エクスプローラで Google Cloud ログを表示して、セッションを終了します。注: 各 Google Cloud Apache Spark 向け Serverless ノートブックを起動するための一意の Google Cloud Apache Spark 向け Serverless セッションが作成されます。
- [バッチ] タブをクリックすると、現在のプロジェクトとリージョンの Google Cloud Serverless for Apache Spark バッチのリストが表示されます。バッチ ID をクリックして、バッチの詳細を表示します。
- [クラスタ] カードをクリックします。[クラスタ] タブが選択され、現在のプロジェクトとリージョン内のアクティブな Dataproc on Compute Engine クラスタが一覧表示されます。[アクション] 列のアイコンをクリックして、クラスタを起動、停止、再起動できます。クラスタ名をクリックして、クラスタの詳細を表示します。[アクション] 列のアイコンをクリックして、ジョブのクローン作成、停止、削除を行えます。
- [ジョブ] カードをクリックして、現在のプロジェクトに存在するジョブのリストを表示します。ジョブの詳細を表示するには、ジョブ ID をクリックします。
JupyterLab 拡張機能をインストールする
ローカルマシンや Compute Engine VM インスタンスなど、Google サービスにアクセスできるマシンまたは VM に JupyterLab 拡張機能をインストールして使用できます。
拡張機能をインストールする手順は次のとおりです。
Apache Spark 向け Serverless ランタイム テンプレートを作成する
Apache Spark 向け Serverless ランタイム テンプレート(セッション テンプレートとも呼ばれます)には、セッションで Spark コードを実行するための構成設定が含まれています。ランタイム テンプレートの作成と管理は、Jupyterlab または gcloud CLI を使用して行うことができます。
JupyterLab
gcloud
ノートブックを起動して管理する
Dataproc JupyterLab 拡張機能をインストールした後、JupyterLab の [ランチャー] ページでテンプレート カードをクリックして、次の操作を行うことができます。
Apache Spark 向け Serverless で Jupyter ノートブックを起動する
JupyterLab ランチャー ページの [Apache Spark 用サーバーレス ノートブック] セクションには、Apache Spark 用サーバーレス ランタイム テンプレートにマッピングされるノートブック テンプレート カードが表示されます(Apache Spark 用サーバーレス ランタイム テンプレートを作成するを参照してください)。

Dataproc on Compute Engine クラスタ でノートブックを起動する
Compute Engine に Dataproc Jupyter クラスタを作成した場合、JupyterLab の [ランチャー] ページに、事前にインストールしたカーネル カードが表示された [Dataproc クラスタ ノートブック] セクションが表示されます。
Dataproc on Compute Engine クラスタ で Jupyter ノートブックを起動するには:
Cloud Storage で入出力ファイルを管理する
探索的データの分析と ML モデルの構築には、多くの場合、ファイルベースの入力と出力が含まれます。Apache Spark 向け Serverless は、Cloud Storage 上のこれらのファイルにアクセスします。
Spark ノートブック コードを開発する
Dataproc JupyterLab 拡張機能をインストールした後、JupyterLab の [ランチャー] ページから Jupyter ノートブックを起動してアプリケーション コードを開発できます。
PySpark と Python のコード開発
Apache Spark 向け Serverless と Compute Engine 上の Dataproc クラスタは、PySpark カーネルをサポートしています。Dataproc on Compute Engine は Python カーネルもサポートしています。
SQL のコード開発
SQL コードを記述して実行する PySpark ノートブックを開くには、JupyterLab の [ランチャー] ページの [Apache Spark ノートブック用サーバーレス] セクションまたは [Dataproc クラスタ ノートブック] セクションで、PySpark カーネルカードをクリックします。
Spark SQL マジック: Serverless for Apache Spark ノートブックを起動する PySpark カーネルは、Spark SQL マジックがプリロードされています。SQL ステートメントでラップするには、spark.sql('SQL STATEMENT').show() を使用する代わりに、セルの先頭に「%%sparksql magic」と入力し、セルに SQL ステートメントを入力します。
BigQuery SQL: BigQuery Spark コネクタを使用すると、ノートブック コードで BigQuery テーブルからデータを読み込み、Spark で分析を実行して、結果を BigQuery テーブルに書き込むことができます。
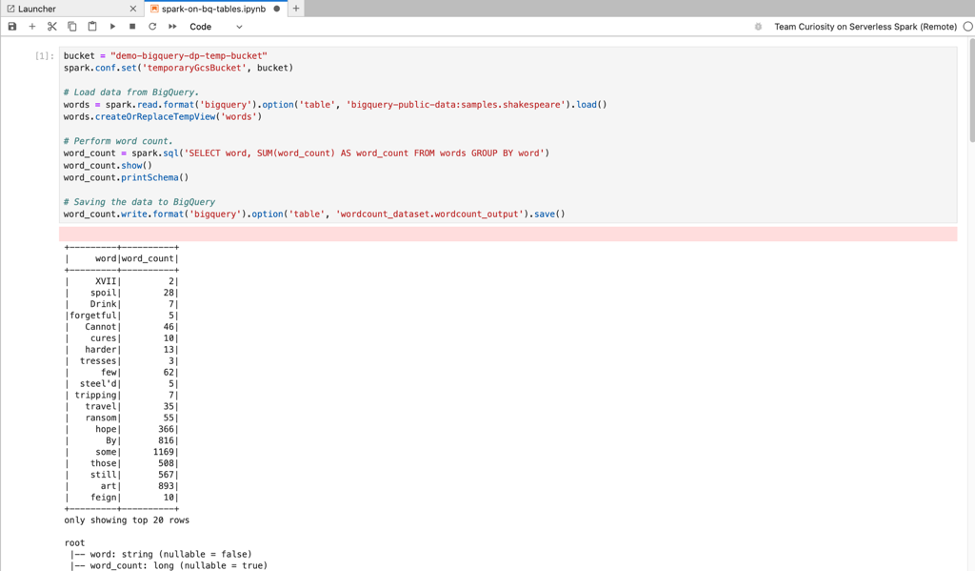
Apache Spark 用サーバーレス 2.2 以降のランタイムには、BigQuery Spark コネクタが含まれています。以前のランタイムを使用して Apache Spark 用 Serverless ノートブックを起動する場合は、次の Spark プロパティを Apache Spark 用 Serverless ランタイム テンプレートに追加して、Spark BigQuery コネクタをインストールできます。
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Scala のコード開発
イメージ バージョン 2.0 以降で作成された Dataproc on Compute Engine クラスタには、Apache Toree(Spark へのインタラクティブなアクセスを可能にする Jupyter ノートブック プラットフォーム用の Scala カーネル)が含まれています。
Visual Studio Code 拡張機能を使用してコードを開発する
Google Cloud Visual Studio Code(VS Code)拡張機能を使用すると、次のことができます。
Visual Studio Code 拡張機能は無料ですが、使用するGoogle Cloud サービス(Dataproc、Apache Spark 用 Serverless、Cloud Storage リソースなど)の料金が発生します。
BigQuery で VS Code を使用する: BigQuery で VS Code を使用すると、次のこともできます。
始める前に
Google Cloud 拡張機能をインストールする
VS Code のアクティビティ バーに Google Cloud Code アイコンが表示されます。
拡張機能の設定
Apache Spark 向け Serverless ノートブックを開発する
Apache Spark 向け Serverless リソースを作成して管理する
データセット エクスプローラ
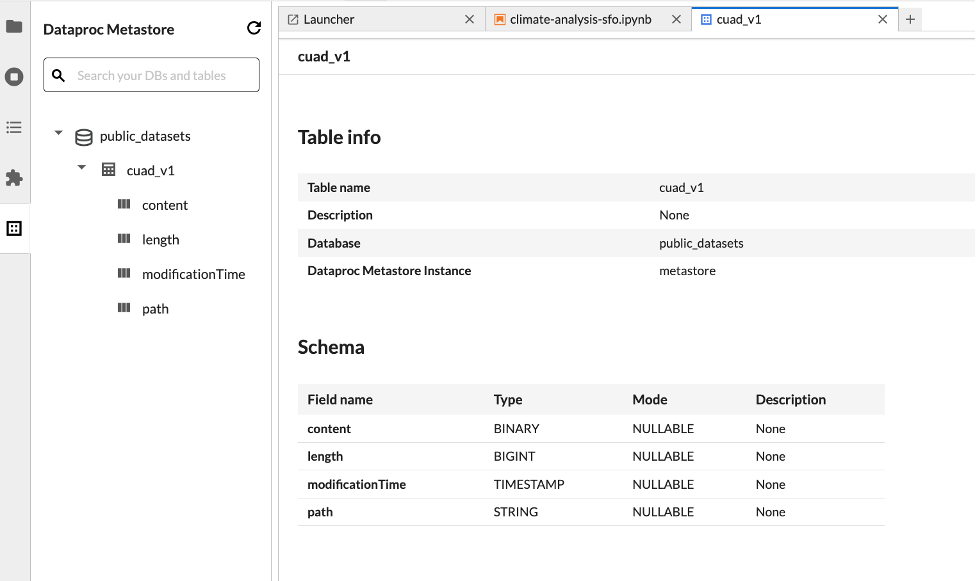
JupyterLab データセット エクスプローラを使用して、BigLake metastore データセットを表示します。
JupyterLab データセット エクスプローラを開くには、サイドバーのアイコンをクリックします。
データベース、テーブル、列は、データセット エクスプローラで検索できます。データベース、テーブル、列の名前をクリックして、関連するメタデータを表示します。
コードをデプロイする
Dataproc JupyterLab 拡張機能をインストールした後、JupyterLab を使用して次のことができます。
Cloud Composer でノートブックの実行をスケジュールする
Cloud Composer でノートブック コードをスケジュールして、Serverless for Apache Spark または Dataproc on Compute Engine クラスタでバッチジョブとして実行するには、次の操作を行います。
Google Cloud Apache Spark 向け Serverless にバッチジョブを送信する
Dataproc on Compute Engine クラスタにバッチジョブを送信する
リソースを表示して管理する
Dataproc JupyterLab 拡張機能をインストールしたら、JupyterLab の [ランチャー] ページの [Dataproc のジョブとセッション] セクションで、 Google Cloud Serverless for Apache Spark と Dataproc on Compute Engine を表示して管理できます。
[Dataproc のジョブとセッション] セクションをクリックして、[クラスタ] カードと [サーバーレス] カードを表示します。
Google Cloud Apache Spark 用サーバーレス セッションを表示して管理するには:
Google Cloud Apache Spark 用サーバーレス バッチを表示して管理するには:
Dataproc on Compute Engine クラスタを表示して管理するには:
Dataproc on Compute Engine ジョブを表示して管理するには: