Este documento descreve como instalar e usar a extensão JupyterLab numa máquina ou numa VM autogerida que tenha acesso aos serviços Google. Também descreve como desenvolver e implementar código de bloco de notas do Spark sem servidor.
Instale a extensão em poucos minutos para tirar partido das seguintes funcionalidades:
- Inicie o Spark sem servidor e os blocos de notas do BigQuery para desenvolver código rapidamente
- Procure e pré-visualize conjuntos de dados do BigQuery no JupyterLab
- Edite ficheiros do Cloud Storage no JupyterLab
- Agende um notebook no Composer
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se estiver a usar um fornecedor de identidade (IdP) externo, tem primeiro de iniciar sessão na CLI gcloud com a sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Enable the Dataproc API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Install the Google Cloud CLI.
-
Se estiver a usar um fornecedor de identidade (IdP) externo, tem primeiro de iniciar sessão na CLI gcloud com a sua identidade federada.
-
Para inicializar a CLI gcloud, execute o seguinte comando:
gcloud init Transfira e instale a versão 3.11 ou superior do Python a partir de
python.org/downloads.- Valide a instalação do Python 3.11 ou superior.
python3 --version
- Valide a instalação do Python 3.11 ou superior.
Virtualize o ambiente Python.
pip3 install pipenv
- Crie uma pasta de instalação.
mkdir jupyter
- Mude para a pasta de instalação.
cd jupyter
- Crie um ambiente virtual.
pipenv shell
- Crie uma pasta de instalação.
Instale o JupyterLab no ambiente virtual.
pipenv install jupyterlab
Instale a extensão do JupyterLab.
pipenv install bigquery-jupyter-plugin
jupyter lab
A página Launcher do JupyterLab é aberta no navegador. Contém uma secção Tarefas e sessões do Dataproc. Também pode conter secções Serverless para blocos de notas do Apache Spark e Blocos de notas do cluster do Dataproc se tiver acesso a blocos de notas sem servidor do Dataproc ou clusters do Dataproc com o componente opcional Jupyter em execução no seu projeto.

Por predefinição, a sessão interativa do Serverless para Apache Spark é executada no projeto e na região que definiu quando executou
gcloud initem Antes de começar. Pode alterar as definições do projeto e da região para as suas sessões a partir de JupyterLab Settings > Google Cloud Settings > Google Cloud Project Settings.Tem de reiniciar a extensão para que as alterações entrem em vigor.
Clique no cartão
New runtime templatena secção Serverless para blocos de notas do Apache Spark na página Launcher do JupyterLab.
Preencha o formulário Modelo de ambiente de execução.

Informações do modelo:
- Nome a apresentar, ID de tempo de execução e Descrição: aceite ou preencha um nome a apresentar do modelo, um ID de tempo de execução do modelo e uma descrição do modelo.
Configuração de execução: selecione Conta de utilizador para executar blocos de notas com a identidade do utilizador em vez da identidade da conta de serviço do Dataproc.
- Conta de serviço: se não especificar uma conta de serviço, é usada a conta de serviço predefinida do Compute Engine.
- Versão do tempo de execução: confirme ou selecione a versão do tempo de execução.
- Imagem de contentor personalizada: opcionalmente, especifique o URI de uma imagem de contentor personalizada.
- Contentor de preparação: opcionalmente, pode especificar o nome de um contentor de preparação do Cloud Storage para utilização pelo Serverless para Apache Spark.
- Repositório de pacotes Python: por predefinição, os pacotes Python são transferidos e instalados a partir da cache de obtenção do PyPI quando os utilizadores executam comandos de instalação nos respetivos blocos de notas.
pipPode especificar o repositório de artefactos privados da sua organização para que os pacotes Python sejam usados como o repositório de pacotes Python predefinido.
Encriptação: aceite a opção predefinida Google-owned and Google-managed encryption key ou selecione Chave de encriptação gerida pelo cliente (CMEK). Se for CMEK, selecione a opção para fornecer as informações da chave.
Configuração de rede: selecione uma sub-rede no projeto ou partilhada a partir de um projeto anfitrião (pode alterar o projeto em Definições do JupyterLab > Google Cloud Definições > Google Cloud Definições do projeto. Pode especificar etiquetas de rede para aplicar à rede especificada. Tenha em atenção que o Serverless para Apache Spark ativa o Acesso privado do Google (PGA) na sub-rede especificada. Para ver os requisitos de conetividade de rede, consulte o artigo Google Cloud Configuração de rede do Serverless para Apache Spark.
Configuração da sessão: opcionalmente, pode preencher estes campos para limitar a duração das sessões criadas com o modelo.
- Tempo de inatividade máximo: o tempo de inatividade máximo antes de a sessão ser terminada. Intervalo permitido: 10 minutos a 336 horas (14 dias).
- Tempo máximo da sessão: a duração total máxima de uma sessão antes de a sessão ser terminada. Intervalo permitido: 10 minutos a 336 horas (14 dias).
Metastore: para usar um serviço Dataproc Metastore com as suas sessões, selecione o ID do projeto e o serviço do metastore.
Servidor de histórico persistente: pode selecionar um servidor de histórico persistente do Spark disponível para lhe permitir aceder aos registos de sessões durante e após as sessões.
Propriedades do Spark: pode selecionar e, em seguida, adicionar propriedades de atribuição de recursos do Spark, dimensionamento automático ou GPU. Clique em Adicionar propriedade para adicionar outras propriedades do Spark. Para mais informações, consulte o artigo Propriedades do Spark.
Etiquetas: clique em Adicionar etiqueta para cada etiqueta a definir nas sessões criadas com o modelo.
Clique em Guardar para criar o modelo.
Para ver ou eliminar um modelo de tempo de execução.
- Clique em Definições > Google Cloud Definições.
A secção Definições do Dataproc > Modelos de tempo de execução sem servidor apresenta a lista de modelos de tempo de execução.
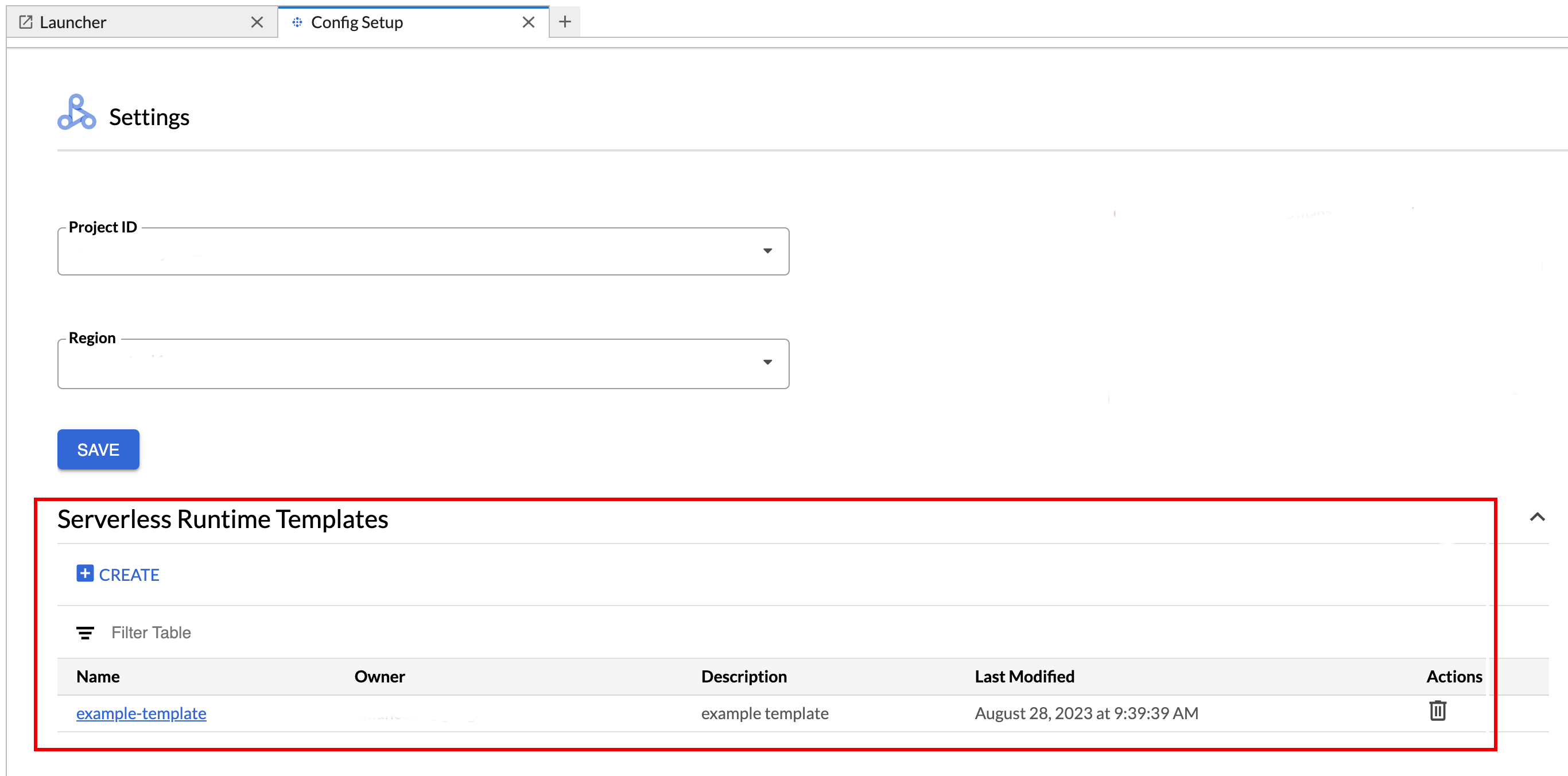
- Clique no nome de um modelo para ver os detalhes do modelo.
- Pode eliminar um modelo no menu Ação do modelo.
Abra e atualize a página do Launcher do JupyterLab para ver o cartão do modelo de bloco de notas guardado na página do Launcher do JupyterLab.

Crie um ficheiro YAML com a configuração do modelo de tempo de execução.
YAML simples
environmentConfig: executionConfig: networkUri: default jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing description: Team A Development Environment
YAML complexo
description: Example session template environmentConfig: executionConfig: serviceAccount: sa1 # Choose either networkUri or subnetworkUri networkUri: subnetworkUri: default networkTags: - tag1 kmsKey: key1 idleTtl: 3600s ttl: 14400s stagingBucket: staging-bucket peripheralsConfig: metastoreService: projects/my-project-id/locations/us-central1/services/my-metastore-id sparkHistoryServerConfig: dataprocCluster: projects/my-project-id/regions/us-central1/clusters/my-cluster-id jupyterSession: kernel: PYTHON displayName: Team A labels: purpose: testing runtimeConfig: version: "2.3" containerImage: gcr.io/my-project-id/my-image:1.0.1 properties: "p1": "v1" description: Team A Development Environment
Crie um modelo de sessão (tempo de execução) a partir do seu ficheiro YAML executando o seguinte comando gcloud beta dataproc session-templates import localmente ou no Cloud Shell:
gcloud beta dataproc session-templates import TEMPLATE_ID \ --source=YAML_FILE \ --project=PROJECT_ID \ --location=REGION
- Consulte gcloud beta dataproc session-templates para ver comandos para descrever, listar, exportar e eliminar modelos de sessões.
Inicie um bloco de notas do Jupyter no Serverless para Apache Spark.
Inicie um bloco de notas do Jupyter num cluster do Dataproc no Compute Engine.
Clique num cartão para criar uma sessão do Serverless para Apache Spark e iniciar um bloco de notas. Quando a criação da sessão estiver concluída e o kernel do bloco de notas estiver pronto a usar, o estado do kernel muda de
StartingparaIdle (Ready).Escrever e testar código de blocos de notas.
Copie e cole o seguinte código
Pi estimationPySpark na célula do bloco de notas do PySpark e, de seguida, prima Shift+Return para executar o código.import random def inside(p): x, y = random.random(), random.random() return x*x + y*y < 1 count = sc.parallelize(range(0, 10000)) .filter(inside).count() print("Pi is roughly %f" % (4.0 * count / 10000))
Resultado do bloco de notas:
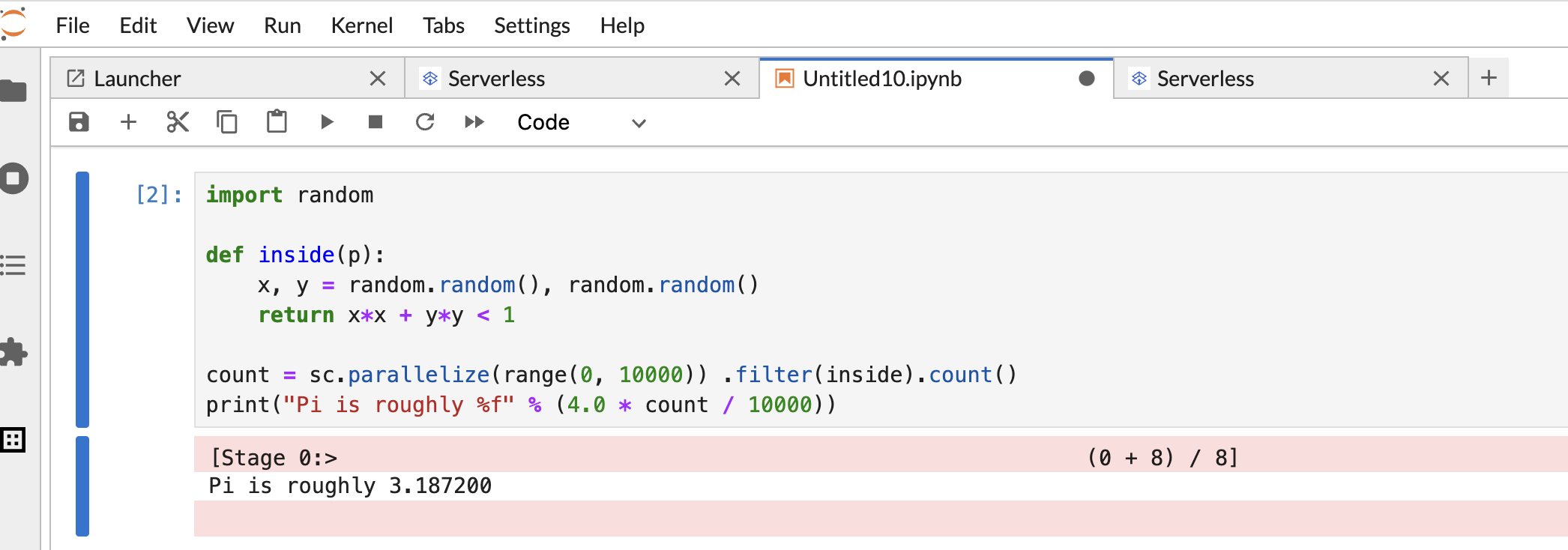
Depois de criar e usar um bloco de notas, pode terminar a sessão do bloco de notas clicando em Desativar kernel no separador Kernel.
- Para reutilizar a sessão, crie um novo notebook escolhendo Notebook no menu Ficheiro>>Novo. Depois de criar o novo notebook, escolha a sessão existente na caixa de diálogo de seleção do kernel. O novo bloco de notas vai reutilizar a sessão e manter o contexto da sessão do bloco de notas anterior.
Se não terminar a sessão, o Dataproc termina a sessão quando o temporizador de inatividade da sessão expira. Pode configurar o tempo de inatividade da sessão na configuração do modelo de tempo de execução. O tempo de inatividade da sessão predefinido é de uma hora.
Clique num cartão na secção Bloco de notas do cluster do Dataproc.
Quando o estado do kernel muda de
StartingparaIdle (Ready), pode começar a escrever e executar código do bloco de notas.Depois de criar e usar um bloco de notas, pode terminar a sessão do bloco de notas clicando em Desativar kernel no separador Kernel.
Para aceder ao navegador do Cloud Storage, clique no ícone do navegador do Cloud Storage na barra lateral da página Launcher do JupyterLab e, de seguida, clique duas vezes numa pasta para ver o respetivo conteúdo.
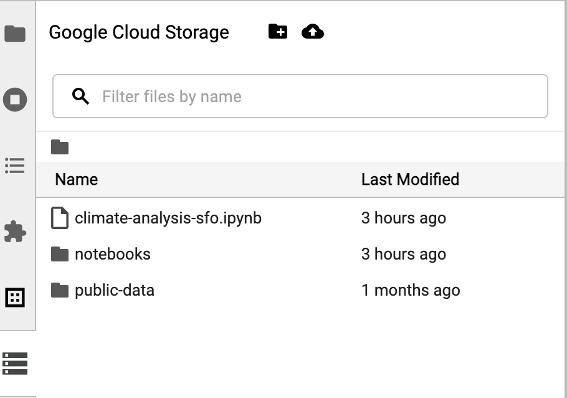
Pode clicar nos tipos de ficheiros suportados pelo Jupyter para os abrir e editar. Quando guarda as alterações aos ficheiros, estas são escritas no armazenamento na nuvem.
Para criar uma nova pasta de armazenamento na nuvem, clique no ícone de nova pasta e, em seguida, introduza o nome da pasta.
Para carregar ficheiros para um contentor ou uma pasta do Cloud Storage, clique no ícone de carregamento e, em seguida, selecione os ficheiros a carregar.
Clique num cartão do PySpark na secção Serverless for Apache Spark Notebooks ou Dataproc Cluster Notebook na página Launcher do JupyterLab para abrir um bloco de notas do PySpark.
Clique num cartão do kernel Python na secção Bloco de notas do cluster Dataproc na página Launcher do JupyterLab para abrir um bloco de notas Python.
Clique no cartão Apache Toree na secção Bloco de notas do cluster do Dataproc na página Iniciador do JupyterLab para abrir um bloco de notas para o desenvolvimento de código Scala.

Figura 1. Cartão do kernel do Apache Toree na página do Launcher do JupyterLab. - Desenvolva e execute código Spark em blocos de notas do Serverless para Apache Spark.
- Crie e faça a gestão de modelos de tempo de execução (sessão) sem servidor para Apache Spark, sessões interativas e cargas de trabalho em lote.
- Desenvolver e executar blocos de notas do BigQuery.
- Procure, inspecione e pré-visualize conjuntos de dados do BigQuery.
- Transfira e instale o VS Code.
- Abra o VS Code e, de seguida, na barra de atividade, clique em Extensões.
Na barra de pesquisa, encontre a extensão Jupyter e, de seguida, clique em Instalar. A extensão Jupyter da Microsoft é uma dependência obrigatória.
- Abra o VS Code e, de seguida, na barra de atividade, clique em Extensões.
Na barra de pesquisa, encontre a extensão Google Cloud Code e, de seguida, clique em Instalar.

Se lhe for pedido, reinicie o VS Code.
- Abra o VS Code e, de seguida, na barra de atividade, clique em Google Cloud Code.
- Abra a secção Dataproc.
- Clique em Iniciar sessão em Google Cloud. É redirecionado para iniciar sessão com as suas credenciais.
- Use a barra de tarefas da aplicação de nível superior para navegar para Código > Definições > Definições > Extensões.
- Encontre Google Cloud Código e clique no ícone Gerir para abrir o menu.
- Selecione Definições.
- Nos campos Projeto e Região do Dataproc, introduza o nome do Google Cloud projeto e da região a usar para desenvolver blocos de notas e gerir recursos sem servidor para Apache Spark.
- Abra o VS Code e, de seguida, na barra de atividade, clique em Google Cloud Code.
- Abra a secção Notebooks e, de seguida, clique em Novo notebook do Spark sem servidor.
- Selecione ou crie um novo modelo de tempo de execução (sessão) para usar na sessão do bloco de notas.
É criado um novo ficheiro
.ipynbcom código de exemplo e aberto no editor.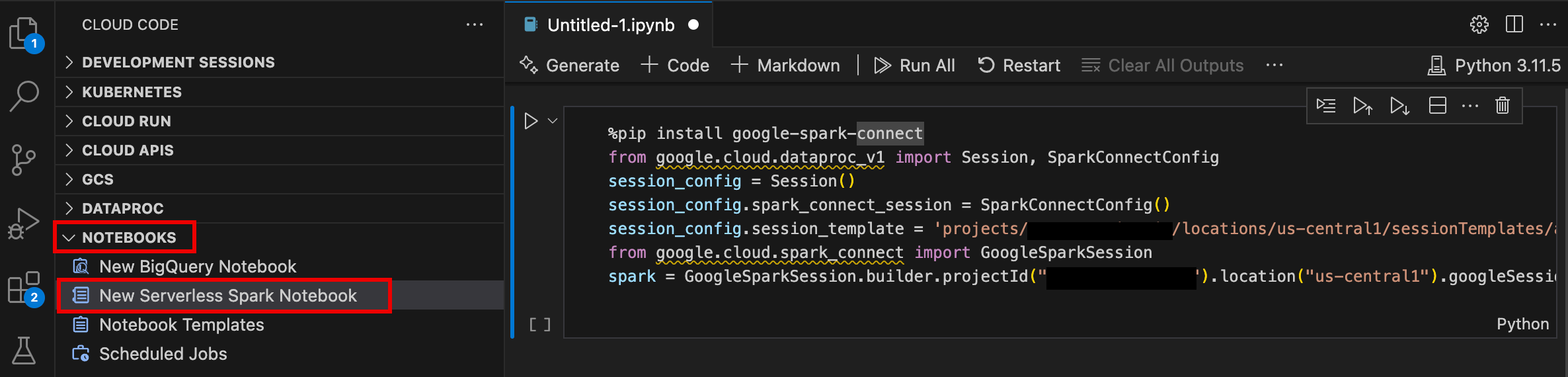
Já pode escrever e executar código no seu bloco de notas do Serverless para Apache Spark.
- Abra o VS Code e, de seguida, na barra de atividade, clique em Google Cloud Code.
Abra a secção Dataproc e, de seguida, clique nos seguintes nomes de recursos:
- Clusters: crie e faça a gestão de clusters e tarefas.
- Sem servidor: crie e faça a gestão de cargas de trabalho em lote e sessões interativas.
- Modelos do ambiente de execução do Spark: crie e faça a gestão de modelos de sessão.

Execute o código do bloco de notas na Google Cloud infraestrutura sem servidor para Apache Spark
Agende a execução de blocos de notas no Cloud Composer
Envie trabalhos em lote para a infraestrutura Google Cloud sem servidores para Apache Spark ou para o seu cluster do Dataproc no Compute Engine.
Clique no botão Agendador de tarefas na parte superior direita do bloco de notas.
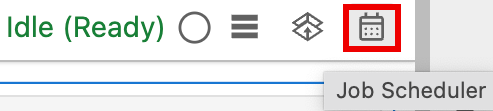
Preencha o formulário Criar uma tarefa agendada para fornecer as seguintes informações:
- Um nome exclusivo para a tarefa de execução do bloco de notas
- O ambiente do Cloud Composer a usar para implementar o bloco de notas
- Introduza parâmetros se o bloco de notas for parametrizado
- O cluster do Dataproc ou o modelo de tempo de execução sem servidor a usar
para executar o bloco de notas
- Se um cluster estiver selecionado, se deve parar o cluster depois de o bloco de notas terminar a execução no cluster
- Número de tentativas e atraso de tentativas em minutos se a execução do bloco de notas falhar na primeira tentativa
- Notificações de execução a enviar e a lista de destinatários. As notificações são enviadas através de uma configuração SMTP do Airflow.
- A programação de execução do bloco de notas
Clique em Criar.
Depois de agendar o bloco de notas com êxito, o nome da tarefa é apresentado na lista de tarefas agendadas no ambiente do Cloud Composer.

Clique no cartão Sem servidor na secção Tarefas e sessões do Dataproc na página Launcher do JupyterLab.
Clique no separador Lote e, de seguida, em Criar lote e preencha os campos Informações do lote.
Clique em Enviar para enviar o trabalho.
Clique no cartão Clusters na secção Dataproc Jobs and Sessions na página Launcher do JupyterLab.
Clique no separador Tarefas e, de seguida, em Enviar tarefa.
Selecione um Cluster e, de seguida, preencha os campos Trabalho.
Clique em Enviar para enviar o trabalho.
- Clique no cartão Sem servidor.
- Clique no separador Sessões e, de seguida, num ID de sessão para abrir a página Detalhes da sessão para ver as propriedades da sessão, ver Google Cloud registos no Explorador de registos e terminar uma sessão. Nota: é criada uma sessão única do Google Cloud Serverless para Apache Spark para iniciar cada bloco de notas do Google Cloud Serverless para Apache Spark.
- Clique no separador Lotes para ver a lista de lotes do Serverless para Apache Spark no projeto e na região atuais. Google Cloud Clique num ID do lote para ver os detalhes do lote.
- Clique no cartão Clusters. O separador Clusters está selecionado para listar clusters ativos do Dataproc no Compute Engine no projeto e região atuais. Pode clicar nos ícones na coluna Ações para iniciar, parar ou reiniciar um cluster. Clique no nome de um cluster para ver os detalhes do cluster. Pode clicar nos ícones na coluna Ações para clonar, parar ou eliminar uma tarefa.
- Clique no cartão Tarefas para ver a lista de tarefas no projeto atual. Clique num ID da tarefa para ver os detalhes da tarefa.
Instale a extensão do JupyterLab
Pode instalar e usar a extensão JupyterLab numa máquina ou numa VM que tenha acesso aos serviços Google, como a sua máquina local ou uma instância de VM do Compute Engine.
Para instalar a extensão, siga estes passos:
Crie um modelo de tempo de execução do Serverless para Apache Spark
Os modelos de tempo de execução sem servidor para Apache Spark (também denominados modelos de sessão) contêm definições de configuração para executar código Spark numa sessão. Pode criar e gerir modelos de tempo de execução através do Jupyterlab ou da CLI gcloud.
JupyterLab
gcloud
Inicie e faça a gestão de notebooks
Depois de instalar a extensão Dataproc JupyterLab, pode clicar nos cartões de modelos na página Launcher do JupyterLab para:
Inicie um bloco de notas do Jupyter no Serverless para Apache Spark
A secção Serverless for Apache Spark Notebooks na página do Launcher do JupyterLab apresenta cartões de modelos de blocos de notas que mapeiam para modelos de tempo de execução do Serverless for Apache Spark (consulte o artigo Crie um modelo de tempo de execução do Serverless for Apache Spark).

Inicie um bloco de notas num cluster do Dataproc no Compute Engine
Se criou um cluster do Jupyter do Dataproc no Compute Engine, a página do Launcher do JupyterLab contém uma secção Dataproc Cluster Notebook com cartões de kernel pré-instalados.
Para iniciar um bloco de notas do Jupyter no cluster do Dataproc no Compute Engine:
Faça a gestão de ficheiros de entrada e saída no Cloud Storage
A análise de dados exploratórios e a criação de modelos de AA envolvem frequentemente entradas e saídas baseadas em ficheiros. O Serverless para Apache Spark acede a estes ficheiros no Cloud Storage.
Desenvolva código de notebook Spark
Depois de instalar a extensão do Dataproc JupyterLab, pode iniciar blocos de notas do Jupyter a partir da página Launcher do JupyterLab para desenvolver código de aplicação.
Programação de código Python e PySpark
Os clusters sem servidor para Apache Spark e Dataproc no Compute Engine suportam kernels PySpark. O Dataproc no Compute Engine também suporta kernels Python.
Programação de código SQL
Para abrir um bloco de notas do PySpark para escrever e executar código SQL, na página Launcher do JupyterLab, na secção Serverless for Apache Spark Notebooks ou Dataproc Cluster Notebook, clique no cartão do kernel do PySpark.
Funcionalidade mágica do Spark SQL: uma vez que o kernel do PySpark que inicia o Serverless para blocos de notas do Apache Spark está pré-carregado com a funcionalidade mágica do Spark SQL, em vez de usar spark.sql('SQL STATEMENT').show() para encapsular a sua declaração SQL, pode escrever %%sparksql magic na parte superior de uma célula e, em seguida, escrever a sua declaração SQL na célula.
SQL do BigQuery: o conetor do BigQuery Spark permite que o código do bloco de notas carregue dados de tabelas do BigQuery, faça análises no Spark e, em seguida, escreva os resultados numa tabela do BigQuery.

Os tempos de execução sem servidor para o Apache Spark2.2
e posteriores incluem o
conetor do BigQuery Spark.
Se usar um tempo de execução anterior para iniciar blocos de notas do Serverless para Apache Spark,
pode instalar o conetor Spark BigQuery adicionando a seguinte propriedade do Spark
ao seu modelo de tempo de execução do Serverless para Apache Spark:
spark.jars: gs://spark-lib/bigquery/spark-bigquery-with-dependencies_2.12-0.25.2.jar
Programação de código Scala
Os clusters do Dataproc no Compute Engine criados com versões de imagens 2.0 e posteriores incluem o Apache Toree, um kernel Scala para a plataforma Jupyter Notebook que oferece acesso interativo ao Spark.
Desenvolva código com a extensão do Visual Studio Code
Pode usar a extensão Google Cloud Visual Studio Code (VS Code) para fazer o seguinte:
A extensão do Visual Studio Code é gratuita, mas são-lhe cobrados todos os Google Cloud serviços, incluindo o Dataproc, o Serverless para Apache Spark e os recursos do Cloud Storage que usar.
Use o VS Code com o BigQuery: também pode usar o VS Code com o BigQuery para fazer o seguinte:
Antes de começar
Instale a Google Cloud extensão
O ícone Google Cloud Código já está visível na barra de atividade do VS Code.
Configure a extensão
Desenvolva blocos de notas sem servidor para Apache Spark
Crie e faça a gestão de recursos do Serverless para Apache Spark
Explorador de conjuntos de dados
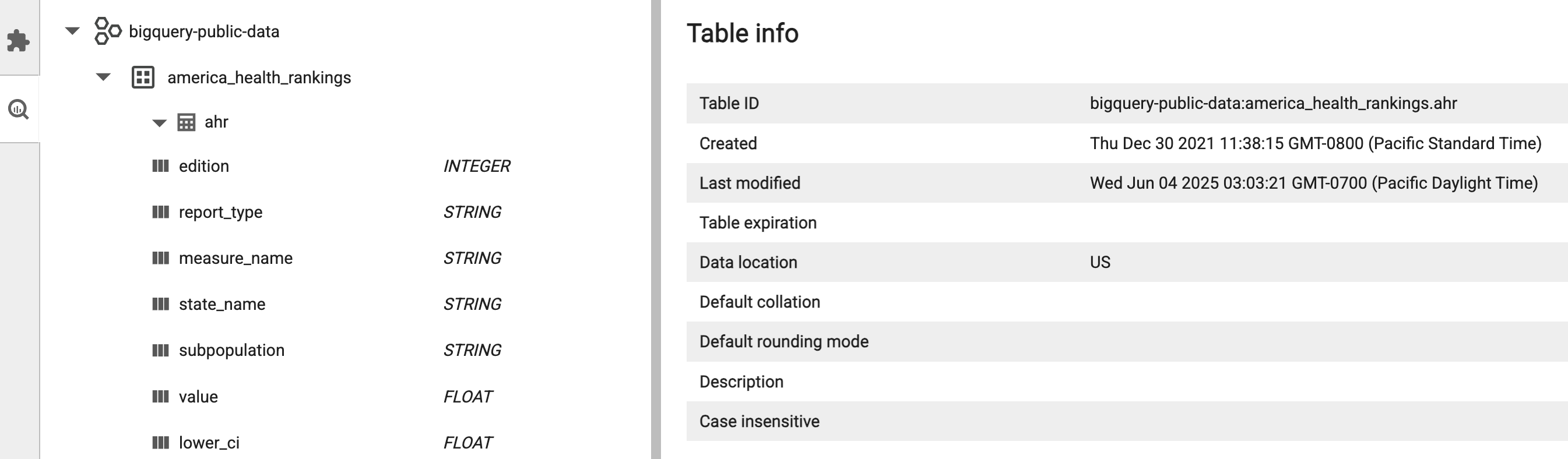
Use o explorador de conjuntos de dados do JupyterLab para ver conjuntos de dados do metastore do BigLake.
Para abrir o explorador de conjuntos de dados do JupyterLab, clique no respetivo ícone na barra lateral.
Pode pesquisar uma base de dados, uma tabela ou uma coluna no explorador de conjuntos de dados. Clique num nome de base de dados, tabela ou coluna para ver os metadados associados.
Implemente o seu código
Depois de instalar a extensão do Dataproc JupyterLab, pode usar o JupyterLab para:
Agende a execução de blocos de notas no Cloud Composer
Conclua os passos seguintes para agendar o código do bloco de notas no Cloud Composer para execução como uma tarefa em lote no Serverless para Apache Spark ou num cluster do Dataproc no Compute Engine.
Envie uma tarefa em lote para o Google Cloud Serverless para Apache Spark
Envie uma tarefa em lote para um cluster do Dataproc no Compute Engine
Veja e faça a gestão de recursos
Depois de instalar a extensão Dataproc JupyterLab, pode ver e gerir o Google Cloud Serverless para Apache Spark e Dataproc no Compute Engine na secção Tarefas e sessões do Dataproc na página Launcher do JupyterLab.
Clique na secção Tarefas e sessões do Dataproc para mostrar os cartões Clusters e Sem servidor.
Para ver e gerir Google Cloud sessões do Serverless para Apache Spark:
Para ver e gerir Google Cloud batches do Serverless para Apache Spark:
Para ver e gerir clusters do Dataproc no Compute Engine:
Para ver e gerir trabalhos do Dataproc no Compute Engine: