このドキュメントでは、Spark ワークロードの自動チューニングについて説明します。Spark ワークロードのパフォーマンスと復元性を最適化するのは、Spark 構成オプションの数が多く、これらのオプションがワークロードに与える影響を評価するのが難しいため、難しい場合があります。Dataproc サーバーレスの自動チューニングは、Spark の最適化のベスト プラクティスとワークロード実行の分析に基づいて、繰り返される Spark ワークロードに Spark 構成設定を自動的に適用することで、手動ワークロード構成に代わる手段を提供します。
Dataproc Serverless の自動チューニングに登録する
このページで説明する Dataproc サーバーレス自動チューニングプレビュー リリースへのアクセスに登録するには、BigQuery の Gemini のプレビューサインアップフォームに記入して提出してください。フォームが承認されると、フォームにリストされているプロジェクトはプレビュー機能にアクセスできるようになります。
利点
Dataproc サーバーレスの自動チューニングには、次のメリットがあります。
- パフォーマンスの向上: パフォーマンスを向上させるための最適化のチューニング
- 迅速な最適化: 時間のかかる手動構成テストを回避する自動構成
- 復元性の向上: メモリ関連の障害を回避する自動メモリ割り当て
制限事項
Dataproc サーバーレスの自動チューニングには次の制限があります。
- 自動チューニングは計算され、ワークロードの 2 回目以降の実行に適用されます。Dataproc Serverless の自動チューニングでは、最適化にワークロード履歴を使用するため、繰り返し実行されるワークロードの最初の実行は自動チューニングされません。
- メモリのダウンサイジングはサポートされていません。
- 自動チューニングは、実行中のワークロードには遡及的に適用されず、新しく送信されたワークロード コホートにのみ適用されます。
自動チューニング コホート
自動チューニングは、バッチ ワークロードの定期的な実行(コホート)に適用されます。ワークロードを送信するときに指定するコホート名は、反復ワークロードの連続実行の 1 つとしてワークロードを識別します。ワークロードのタイプを説明するコホート名の使用をおすすめします。または、繰り返されるワークロードの一部としてワークロードの実行を識別しやすくすることも推奨されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名として daily_sales_aggregation を指定します。
自動チューニングのシナリオ
Dataproc サーバーレスの自動チューニングをワークロードに適用するには、次の自動チューニング シナリオの 1 つ以上を選択します。
MEMORY: Spark メモリ割り当てを自動チューニングして、ワークロードのメモリ不足エラーの可能性を予測し、回避します。メモリ不足(OOM)エラーが原因で以前に失敗したワークロードを修正します。SCALING: Spark 自動スケーリング構成設定を自動調整します。BROADCAST_HASH_JOIN: Spark 構成設定を自動チューニングして、SQL ブロードキャスト結合のパフォーマンスを最適化します。
料金
Dataproc サーバーレスの自動チューニングは、プレビュー期間中は追加料金なしで提供されます。標準の Dataproc Serverless の料金が適用されます。
ご利用いただけるリージョン
Dataproc サーバーレス自動チューニングは、利用可能な Compute Engine リージョンで送信されたバッチで使用できます。
Dataproc サーバーレスの自動チューニングを使用する
Google Cloud コンソール、Google Cloud CLI、または Dataproc API を使用して、ワークロードで Dataproc サーバーレス自動調整を有効にできます。
コンソール
定期的なバッチ ワークロードを送信するたびに Dataproc サーバーレス自動チューニングを有効にするには、次の手順を行います。
Google Cloud コンソールで、Dataproc バッチ ページに移動します。
バッチ ワークロードを作成するには、[作成] をクリックします。
[コンテナ] セクションで、Spark ワークロードの次のフィールドに値を入力します。
コホート: コホート名。バッチを一連の反復的なワークロードの 1 つとして識別します。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名として
daily_sales_aggregationを指定します。自動チューニングのシナリオ: 1 つ以上(たとえば、
BROADCAST_HASH_JOIN、MEMORY、SCALING)の 自動チューニングのシナリオワークロードの最適化に使用できます。シナリオの選択は、バッチ コホートの送信ごとに変更できます。
必要に応じて [バッチを作成] ページの他のセクションに入力し、[送信] をクリックします。これらのフィールドの詳細については、バッチ ワークロードを送信するをご覧ください。
gcloud
定期的なバッチ ワークロードが送信されるたびに Dataproc サーバーレスの自動チューニングを有効にするには、次の gcloud CLI の gcloud dataproc batches submit コマンドをターミナル ウィンドウまたは Cloud Shell でローカルに実行します。
gcloud dataproc batches submit COMMAND \ --region=REGION \ --cohort=COHORT \ --autotuning-scenarios=SCENARIOS \ other arguments ...
以下を置き換えます。
- COMMAND: Spark ワークロード タイプ(
Spark、PySpark、Spark-Sql、Spark-Rなど)。 - REGION: ワークロードが実行される リージョンを指定します。
COHORT: コホート名。バッチを一連の反復的なワークロードの 1 つとして識別します。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名として
daily_sales_aggregationを指定します。SCENARIOS: ワークロードの最適化に使用する 1 つ以上の自動チューニングのシナリオ(カンマ区切り)(例:
--autotuning-scenarios=MEMORY,SCALING)。シナリオ リストは、バッチ コホートの送信ごとに変更できます。
API
定期的なバッチ ワークロードを送信するたびに Dataproc サーバーレスの自動チューニングを有効にするには、次のフィールドを含む batches.create リクエストを送信します。
RuntimeConfig.cohort: コホート名。バッチが一連の繰り返しワークロードの 1 つとして識別されます。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名としてdaily_sales_aggregationを指定します。AutotuningConfig.scenarios: 1 つ以上(たとえば、BROADCAST_HASH_JOIN、MEMORY、SCALING)の 自動チューニングのシナリオワークロードの最適化に使用できます。シナリオ リストは、バッチ コホートの送信ごとに変更できます。
例:
...
runtimeConfig:
cohort: daily_sales_aggregation
autotuningConfig:
scenarios:
- BROADCAST_HASH_JOIN
- MEMORY
- SCALING
...
Java
このサンプルを試す前に、Dataproc クイックスタート: クライアント ライブラリの使用にある Java の設定手順を行ってください。 詳細については、Dataproc Java API のリファレンス ドキュメントをご覧ください。
Dataproc サーバーレスへの認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
定期的なバッチ ワークロードを送信するたびに Dataproc サーバーレスの自動チューニングを有効にするには、次のフィールドを含む CreateBatchRequest を使用して BatchControllerClient.createBatch を呼び出します。
Batch.RuntimeConfig.cohort: コホート名。バッチが一連の繰り返しワークロードの 1 つとして識別されます。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名としてdaily_sales_aggregationを指定します。Batch.RuntimeConfig.AutotuningConfig.scenarios: 1 つ以上(たとえば、BROADCAST_HASH_JOIN、MEMORY、SCALING)の自動チューニングのシナリオワークロードの最適化に使用できます。シナリオ リストは、バッチ コホートの送信ごとに変更できます。シナリオの一覧については、AutotuningConfig.Scenario Javadoc をご覧ください。
例:
...
Batch batch =
Batch.newBuilder()
.setRuntimeConfig(
RuntimeConfig.newBuilder()
.setCohort("daily_sales_aggregation")
.setAutotuningConfig(
AutotuningConfig.newBuilder()
.addScenarios(Scenario.SCALING))
...
.build();
batchControllerClient.createBatch(
CreateBatchRequest.newBuilder()
.setParent(parent)
.setBatchId(batchId)
.setBatch(batch)
.build());
...
API を使用するには、google-cloud-dataproc クライアント ライブラリのバージョン 4.43.0 以降を使用する必要があります。ライブラリをプロジェクトに追加するには、次のいずれかの構成を使用します。
Maven
<dependencies>
<dependency>
<groupId>com.google.cloud</groupId>
<artifactId>google-cloud-dataproc</artifactId>
<version>4.43.0</version>
</dependency>
</dependencies>
Gradle
implementation 'com.google.cloud:google-cloud-dataproc:4.43.0'
SBT
libraryDependencies += "com.google.cloud" % "google-cloud-dataproc" % "4.43.0"
Python
このサンプルを試す前に、Dataproc クイックスタート: クライアント ライブラリの使用にある Python の設定手順を行ってください。 詳細については、Dataproc Python API のリファレンス ドキュメントをご覧ください。
Dataproc サーバーレスへの認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証を設定するをご覧ください。
定期的なバッチ ワークロードを送信するたびに Dataproc サーバーレスの自動チューニングを有効にするには、次のフィールドを含む Batch を使用して BatchControllerClient.create_batch を呼び出します。
batch.runtime_config.cohort: コホート名。バッチが一連の繰り返しワークロードの 1 つとして識別されます。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名としてdaily_sales_aggregationを指定します。batch.runtime_config.autotuning_config.scenarios: ワークロードの最適化に使用する 1 つ以上の自動チューニングのシナリオ(BROADCAST_HASH_JOIN、MEMORY、SCALINGなど)。シナリオリストは、バッチ コホートの送信ごとに変更できます。シナリオの一覧については、シナリオのリファレンスをご覧ください。
例:
# Create a client
client = dataproc_v1.BatchControllerClient()
# Initialize request argument(s)
batch = dataproc_v1.Batch()
batch.pyspark_batch.main_python_file_uri = "gs://bucket/run_tpcds.py"
batch.runtime_config.cohort = "daily_sales_aggregation"
batch.runtime_config.autotuning_config.scenarios = [
Scenario.SCALING
]
request = dataproc_v1.CreateBatchRequest(
parent="parent_value",
batch=batch,
)
# Make the request
operation = client.create_batch(request=request)
API を使用するには、google-cloud-dataproc クライアント ライブラリのバージョン 5.10.1 以降を使用する必要があります。プロジェクトに追加するには、次の要件を使用します。
google-cloud-dataproc>=5.10.1
Airflow
定期的なバッチ ワークロードを送信するたびに Dataproc サーバーレスの自動チューニングを有効にするには、次のフィールドを含む Batch を使用して BatchControllerClient.create_batch を呼び出します。
batch.runtime_config.cohort: コホート名。バッチが一連の繰り返しワークロードの 1 つとして識別されます。自動チューニングは、このコホート名で送信された 2 回目以降のワークロードに適用されます。たとえば、毎日の販売集計タスクを実行するスケジュール設定されたワークロードのコホート名としてdaily_sales_aggregationを指定します。batch.runtime_config.autotuning_config.scenarios: ワークロードの最適化に使用する 1 つ以上の自動チューニングのシナリオ(BROADCAST_HASH_JOIN、MEMORY、SCALINGなど)。シナリオリストは、バッチ コホートの送信ごとに変更できます。シナリオの一覧については、シナリオのリファレンスをご覧ください。
例:
create_batch = DataprocCreateBatchOperator(
task_id="batch_create",
batch={
"pyspark_batch": {
"main_python_file_uri": PYTHON_FILE_LOCATION,
},
"environment_config": {
"peripherals_config": {
"spark_history_server_config": {
"dataproc_cluster": PHS_CLUSTER_PATH,
},
},
},
"runtime_config": {
"cohort": "daily_sales_aggregation",
"autotuning_config": {
"scenarios": [
Scenario.SCALING,
]
}
},
},
batch_id="BATCH_ID",
)
API を使用するには、google-cloud-dataproc クライアント ライブラリのバージョン 5.10.1 以降を使用する必要があります。次の Airflow 環境要件を使用できます。
google-cloud-dataproc>=5.10.1
Cloud Composer でパッケージを更新するには、Cloud Composer の Python 依存関係をインストールする をご覧ください。
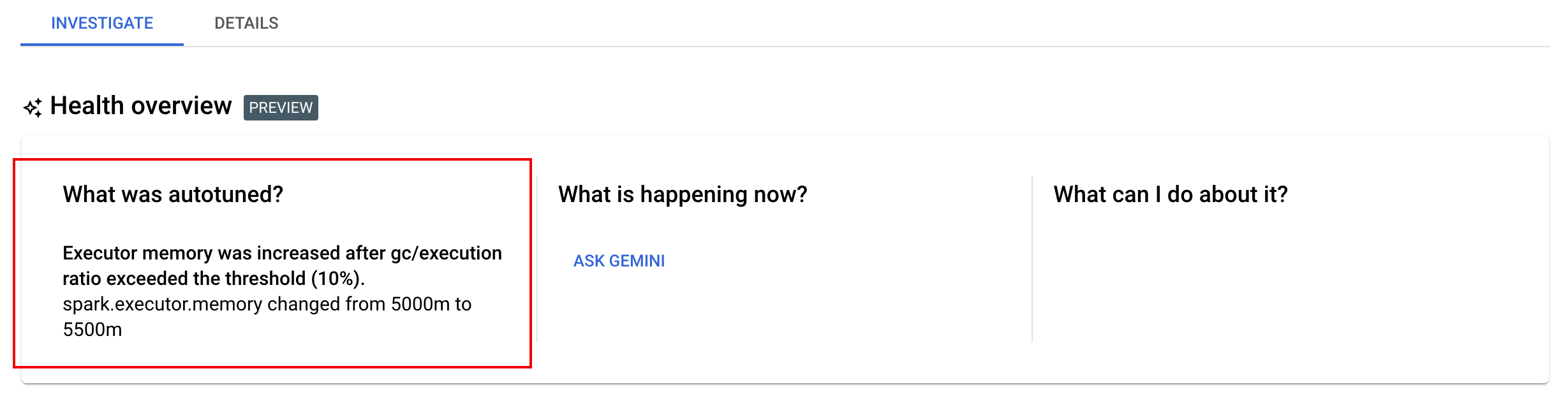
自動チューニングの変更を表示する
バッチ ワークロードに対する Dataproc Serverless 自動チューニングの変更を表示するには、gcloud dataproc batches describe コマンドを実行します。
例: gcloud dataproc batches describe 出力は次のようになります。
...
runtimeInfo:
propertiesInfo:
# Properties set by autotuning.
autotuningProperties
spark.driver.memory:
annotation: Driver OOM was detected
value: 11520m
spark.driver.memoryOverhead:
annotation: Driver OOM was detected
value: 4608m
# Old overwritten properties.
userProperties
...
実行中のワークロード、完了したワークロード、または失敗したワークロードに適用された最新の自動チューニングの変更は、Google Cloud コンソールの [バッチの詳細] ページの [Investigate] タブに適用されます。