이 튜토리얼에서는 Dataproc Metastore를 사용하는 이중 리전 재해 복구 및 비즈니스 연속성 전략을 제안합니다. 이 튜토리얼에서는 Hive 데이터 세트 및 Hive 메타데이터 내보내기 모두를 저장하기 위해 이중 리전 버킷을 사용합니다.
Dataproc Metastore는 기술적인 메타데이터 관리를 크게 간소화해주는 완전 관리형의 고가용성, 자동 확장, 자동 복구, OSS 기본 Metastore 서비스입니다. 이 관리형 서비스는 Apache Hive Metastore를 기반으로 하며 기업 데이터 레이크에 대해 핵심 구성요소로 작동합니다.
이 튜토리얼은 Hive 데이터 및 메타데이터에 대해 고가용성이 필요한 Google Cloud 고객을 대상으로 합니다. 여기에서는 스토리지를 위한 Cloud Storage, 컴퓨팅을 위한 Dataproc, Google Cloud의 완전 관리형 Hive Metastore 서비스인 Dataproc Metastore(DPMS)가 사용됩니다. 또한 이 튜토리얼에서는 Cloud Run과 Cloud Scheduler를 사용하는 경우와 Cloud Composer를 사용하는 경우의 두 가지 서로 다른 장애 조치 조정 방법을 보여줍니다.
이 튜토리얼에서 사용되는 이중 리전 접근법에는 장단점이 있습니다.
장점
- 이중 리전 버킷은 지리적으로 중복됩니다.
- 이중 리전 버킷은 단일 리전 버킷의 99.9% 가용성에 비해 99.95% 가용성 SLA를 지원합니다.
- 이중 리전 버킷은 두 리전에서 최적화된 성능을 갖지만, 단일 리전 버킷은 다른 리전의 리소스로 작업하는 경우 잘 작동하지 않습니다.
단점
- 이중 리전 버킷 쓰기는 두 리전에 즉시 복제되지 않습니다.
- 이중 리전 버킷은 단일 리전 버킷보다 스토리지 비용이 높습니다.
참조 아키텍처
다음 다이어그램은 이 튜토리얼에서 사용하는 구성요소를 보여줍니다. 두 다이어그램 모두 큰 빨간색 X는 기본 리전의 실패를 나타냅니다.
 그림 1: Cloud Run 및 Cloud Scheduler 사용
그림 1: Cloud Run 및 Cloud Scheduler 사용
 그림 2: Cloud Composer 사용
그림 2: Cloud Composer 사용
솔루션의 구성요소 및 해당 관계는 다음과 같습니다.
- 2개의 Cloud Storage 이중 리전 버킷: Hive 데이터용으로 버킷 하나를 만들고 Hive 메타데이터의 주기적 백업용으로 또 다른 버킷 하나를 만듭니다. 이중 리전 버킷 모두가 데이터에 액세스하는 Hadoop 클러스터와 동일한 리전을 사용하도록 만듭니다.
- DPMS를 사용하는 Hive Metastore: 기본 리전(리전 A)에 이 Hive Metastore를 만듭니다. Metastore 구성은 Hive 데이터 버킷을 가리킵니다. Dataproc을 사용하는 Hadoop 클러스터는 연결된 DPMS 인스턴스와 동일한 리전에 있어야 합니다.
- 두 번째 DPMS 인스턴스: 리전 전체 오류를 대비하기 위해 보조 리전(리전 B)에서 두 번째 DPMS 인스턴스를 만듭니다. 그런 후 내보내기 버킷에서 대기 DPMS로 최근의
hive.sql익스포트 파일을 가져옵니다. 또한 대기 리전에서 Dataproc 클러스터를 만들고 이를 대기 DPMS 인스턴스에 연결합니다. 마지막으로 재해 복구 시나리오에서 리전 A의 Dataproc 클러스터에서 리전 B의 Dataproc 클러스터로 클라이언트 애플리케이션을 리디렉션합니다. Cloud Run 배포: 리전 A에 Cloud Scheduler를 사용하여 메타데이터 백업 버킷으로 DPMS 메타데이터를 주기적으로 내보내는 Cloud Run 배포를 만듭니다(그림 1 참조). 내보내기에는 DPMS 메타데이터의 전체 덤프가 포함된 SQL 파일의 형식이 사용됩니다.
Cloud Composer 환경이 이미 있으면 해당 환경에서 Airflow DAG를 실행하여 DPMS 메타데이터 내보내기 및 가져오기를 조정할 수 있습니다(그림 2 참조). 이러한 Airflow DAG 사용은 이전에 언급한 Cloud Run 메서드 대신 사용됩니다.
목표
- Hive 데이터 및 Hive Metastore 백업을 위해 이중 리전 스토리지를 설정합니다.
- 리전 A 및 B에 Dataproc Metastore 및 Dataproc 클러스터를 배포합니다.
- 배포를 리전 B로 장애 조치합니다.
- 배포를 리전 A로 장애 복구합니다.
- 자동화된 Hive Metastore 백업을 만듭니다.
- Cloud Run을 통해 메타데이터 내보내기 및 가져오기를 조정합니다.
- Cloud Composer를 통해 메타데이터 내보내기 및 가져오기를 조정합니다.
비용
이 문서에서는 비용이 청구될 수 있는 Google Cloud구성요소( )를 사용합니다.
프로젝트 사용량을 기준으로 예상 비용을 산출하려면 가격 계산기를 사용합니다.
시작하기 전에
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- Cloud Shell에서 Cloud Shell 인스턴스를 시작합니다.
튜토리얼의 GitHub 저장소를 클론합니다.
git clone https://github.com/GoogleCloudPlatform/metastore-disaster-recovery.git다음 Google Cloud API를 사용 설정합니다.
gcloud services enable dataproc.googleapis.com metastore.googleapis.com몇 가지 환경 변수를 설정합니다.
export PROJECT=$(gcloud info --format='value(config.project)') export WAREHOUSE_BUCKET=${PROJECT}-warehouse export BACKUP_BUCKET=${PROJECT}-dpms-backups export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms2 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
환경 초기화
Hive 데이터 및 Hive Metastore 백업을 위해 스토리지 만들기
이 섹션에서는 Hive 데이터 및 Hive Metastore 백업을 호스팅하기 위해 Cloud Storage 버킷을 만듭니다.
Hive 데이터 스토리지 만들기
Cloud Shell에서 이중 리전 버킷을 만들어 하이브 데이터를 호스팅합니다.
gcloud storage buckets create gs://${WAREHOUSE_BUCKET} --location=NAM4일부 샘플 데이터를 Hive 데이터 버킷에 복사합니다.
gcloud storage cp gs://retail_csv gs://${WAREHOUSE_BUCKET}/retail --recursive
메타데이터 백업을 위해 스토리지 만들기
Cloud Shell에서 DPMS 메타데이터 백업을 호스팅할 이중 리전 버킷을 만듭니다.
gcloud storage buckets create gs://${BACKUP_BUCKET} --location=NAM4
기본 리전에 컴퓨팅 리소스 배포
이 섹션에서는 DPMS 인스턴스 및 Dataproc 클러스터를 포함하여 기본 리전에 모든 컴퓨팅 리소스를 배포합니다. 또한 Dataproc Metastore에 샘플 메타데이터를 채웁니다.
DPMS 인스턴스 만들기
Cloud Shell에서 DPMS 인스턴스를 만듭니다.
gcloud metastore services create ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --hive-metastore-version=3.1.2이 명령어를 완료하는 데 몇 분이 소요될 수 있습니다.
Hive 데이터 버킷을 기본 웨어하우스 디렉터리로 설정합니다.
gcloud metastore services update ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}- warehouse"이 명령어를 완료하는 데 몇 분이 소요될 수 있습니다.
Dataproc 클러스터 만들기
Cloud Shell에서 Dataproc 클러스터를 만들고 이를 DPMS 인스턴스에 연결합니다.
gcloud dataproc clusters create ${HADOOP_PRIMARY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_PRIMARY_REGION}/services/${DPMS_PRIMARY_INSTANCE} \ --region=${DPMS_PRIMARY_REGION} \ --image-version=2.02021년 6월 기준 사용 가능한 최신 버전인 버전 2.0으로 클러스터 이미지를 지정합니다. 이 버전은 또한 DPMS를 지원하는 첫 번째 버전입니다.
Metastore 채우기
Cloud Shell에서 이 튜토리얼의 저장소에 제공된 샘플
retail.hql을 Hive 데이터 버킷의 이름으로 업데이트합니다.sed -i -- 's/${WAREHOUSE_BUCKET}/'"$WAREHOUSE_BUCKET"'/g' retail.hqlretail.hql파일에 포함된 쿼리를 실행하여 Metastore에 테이블 정의를 만듭니다.gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --file=retail.hql테이블 정의가 올바르게 생성되었는지 확인합니다.
gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --execute=" desc departments; desc categories; desc products; desc order_items; desc orders; desc customers; select count(*) as num_departments from departments; select count(*) as num_categories from categories; select count(*) as num_products from products; select count(*) as num_order_items from order_items; select count(*) as num_orders from orders; select count(*) as num_customers from customers; "다음과 유사한 결과가 출력됩니다.
+------------------+------------+----------+ | col_name | data_type | comment | +------------------+------------+----------+ | department_id | int | | | department_name | string | | +------------------+------------+----------+
출력에는 각 테이블의 요소 수도 포함됩니다. 예를 들면 다음과 같습니다.
+----------------+ | num_customers | +----------------+ | 12435 | +----------------+
대기 리전으로 장애 조치
이 섹션에서는 기본 리전(리전 A)에서 대기 리전(리전 B)으로의 장애 조치 단계를 보여줍니다.
Cloud Shell에서 기본 DPMS 인스턴스의 메타데이터를 백업 버킷으로 내보냅니다.
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}다음과 유사한 결과가 출력됩니다.
metadataManagementActivity: metadataExports: ‐ databaseDumpType: MYSQL destinationGcsUri: gs://qa01-300915-dpms-backups/hive-export-2021-05-04T22:21:53.288Z endTime: '2021-05-04T22:23:35.982214Z' startTime: '2021-05-04T22:21:53.308534Z' state: SUCCEEDEDdestinationGcsUri속성의 값을 확인합니다. 이 속성은 생성된 백업을 저장합니다.대기 리전에 새 DPMS 인스턴스를 만듭니다.
gcloud metastore services create ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --hive-metastore-version=3.1.2Hive 데이터 버킷을 기본 웨어하우스 디렉터리로 설정합니다.
gcloud metastore services update ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse"최신 메타데이터 백업의 경로를 검색합니다.
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}백업된 메타데이터를 새로운 Dataproc Metastore 인스턴스로 가져옵니다.
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")대기 리전(리전 B)에 Dataproc 클러스터를 만듭니다.
gcloud dataproc clusters create ${HADOOP_STANDBY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_STANDBY_REGION}/services/${DPMS_STANDBY_INSTANCE} \ --region=${DPMS_STANDBY_REGION} \ --image-version=2.0메타데이터를 올바르게 가져왔는지 확인합니다.
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select count(*) as num_orders from orders;"num_orders출력은 이 튜토리얼에서 가장 중요합니다. 다음과 유사합니다.+-------------+ | num_orders | +-------------+ | 68883 | +-------------+기본 Dataproc Metastore가 새로운 대기 Metastore가 되고 대기 Dataproc Metastore는 새로운 기본 Metastore가 되었습니다.
이러한 새 역할을 기반으로 환경 변수를 업데이트합니다.
export DPMS_PRIMARY_REGION=us-east1 export DPMS_STANDBY_REGION=us-central1] export DPMS_PRIMARY_INSTANCE=dpms2 export DPMS_STANDBY_INSTANCE=dpms1 export HADOOP_PRIMARY=dataproc-cluster2 export HADOOP_STANDBY=dataproc-cluster1리전 B의 새로운 기본 Dataproc Metastore에 데이터를 기록할 수 있는지 확인합니다.
gcloud dataproc jobs submit hive \ --cluster ${DPMS_PRIMARY_INSTANCE} \ --region ${DPMS_PRIMARY_REGION} \ --execute "create view completed_orders as select * from orders where order_status = 'COMPLETE';" gcloud dataproc jobs submit hive \ --cluster ${HADOOP_PRIMARY} \ --region ${DPMS_PRIMARY_REGION} \ --execute "select * from completed_orders limit 5;"출력에는 다음이 포함됩니다.
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
이제 장애 조치가 완료되었습니다. 이제 Hadoop 클라이언트 구성 파일을 업데이트하여 클라이언트 애플리케이션을 리전 B의 새로운 기본 Dataproc 클러스터로 리디렉션해야 합니다.
원래 리전으로 장애 조치
이 섹션에서는 원래 리전(리전 A)으로 장애 조치하는 단계를 보여줍니다.
Cloud Shell에서 DPMS 인스턴스에서 메타데이터를 내보냅니다.
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}최신 메타데이터 백업의 경로를 검색합니다.
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}원래 리전(리전 A)의 대기 DPMS 인스턴스로 메타데이터를 가져옵니다.
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")메타데이터를 올바르게 가져왔는지 확인합니다.
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select * from completed_orders limit 5;"출력은 다음과 같습니다.
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
기본 Dataproc Metastore 및 대기 Dataproc Metastore의 역할이 다시 바뀌었습니다.
이러한 새로운 역할에 맞게 환경 변수를 업데이트합니다.
export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms12 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
이제 장애 복구가 완료되었습니다. 이제 Hadoop 클라이언트 구성 파일을 업데이트하여 클라이언트 애플리케이션을 리전 A의 새로운 기본 Dataproc 클러스터로 리디렉션해야 합니다.
자동 메타데이터 백업 만들기
이 섹션에서는 메타데이터 백업 내보내기 및 가져오기를 자동화하는 두 가지 서로 다른 방법을 간단히 설명합니다. 첫 번째 방법인 옵션 1: Cloud Run 및 Cloud Scheduler에서는 Cloud Run과 Cloud Scheduler가 사용됩니다. 두 번째 방법인 옵션 2: Cloud Composer에서는 Cloud Composer가 사용됩니다. 두 예시 모두 내보내기 작업을 수행하면 리전 A의 기본 DPMS에서 메타데이터 백업이 생성됩니다. 가져오기 작업을 수행하면 백업으로부터 리전 B의 대기 DPMS를 채웁니다.
기존 Cloud Composer 클러스터가 이미 있으면 옵션 2: Cloud Composer를 고려해야 합니다(클러스터에 컴퓨팅 용량이 충분한 경우). 그렇지 않으면 옵션 1: Cloud Run 및 Cloud Scheduler를 선택합니다. 이 옵션은 사용한 만큼만 지불하는 가격 책정 모델을 사용하며 영구적인 컴퓨팅 리소스를 사용해야 하는 Cloud Composer보다 더 경제적입니다.
옵션 1: Cloud Run 및 Cloud Scheduler
이 섹션에서는 Cloud Run 및 Cloud Scheduler를 사용하여 DPMS 메타데이터의 내보내기 또는 가져오기를 자동화하는 방법을 보여줍니다.
Cloud Run 서비스
이 섹션에서는 메타데이터 내보내기 및 가져오기 작업을 실행하기 위해 2개의 Cloud Run 서비스를 빌드하는 방법을 보여줍니다.
Cloud Shell에서 Cloud Run, Cloud Scheduler, Cloud Build, App Engine API를 사용 설정합니다.
gcloud services enable run.googleapis.com cloudscheduler.googleapis.com cloudbuild.googleapis.com appengine.googleapis.comCloud Scheduler 서비스에 App Engine이 필요하기 때문에 App Engine API를 사용 설정합니다.
제공된 Dockerfile을 사용하여 Docker 이미지를 빌드합니다.
cd metastore-disaster-recovery gcloud builds submit --tag gcr.io/$PROJECT/dpms_dr기본 리전(리전 A)에서 Cloud Run 서비스에 컨테이너 이미지를 배포합니다. 이 배포는 기본 Metastore에서 메타데이터 백업을 만듭니다.
gcloud run deploy dpms-export \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_PRIMARY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION} \ --allow-unauthenticated \ --timeout=10m기본적으로 Cloud Run 서비스 요청은 5분 후 타임아웃됩니다. 모든 요청을 성공적으로 완료하기 위해 시간이 충분하도록 이전 코드 샘플은 제한 시간 값을 최소 10분 이상으로 늘립니다.
Cloud Run 서비스의 배포 URL을 검색합니다.
EXPORT_RUN_URL=$(gcloud run services describe dpms-export --platform managed --region ${DPMS_PRIMARY_REGION} --format ` "value(status.address.url)") echo ${EXPORT_RUN_URL}대기 리전(리전 B)에서 보조 Cloud Run 서비스를 만듭니다. 이 서비스는
BACKUP_BUCKET에서 대기 Metastore로 메타데이터 백업을 가져옵니다.gcloud run deploy dpms-import \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_STANDBY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE} \ --allow-unauthenticated \ --timeout=10m두 번째 Cloud Run 서비스의 배포 URL을 검색합니다.
IMPORT_RUN_URL=$(gcloud run services describe dpms-import --platform managed --region ${REGION_B} --format "value(status.address.url)") echo ${IMPORT_RUN_URL}
작업 예약
이 섹션에서는 Cloud Scheduler를 사용하여 2개의 Cloud Run 서비스를 트리거하는 방법을 보여줍니다.
Cloud Shell에서 Cloud Scheduler에 필요한 App Engine 애플리케이션을 만듭니다.
gcloud app create --region=${REGION_A}기본 Metastore에서 메타데이터 내보내기를 예약하기 위해 Cloud Scheduler 작업을 만듭니다.
gcloud scheduler jobs create http dpms-export \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${EXPORT_RUN_URL}/export\
Cloud Scheduler 작업은 Cloud Run 서비스에 대해 15분 간격으로 http 요청을 수행합니다. Cloud Run 서비스는 내보내기 및 가져오기 함수를 모두 사용하여 컨테이너화된 Flask 애플리케이션을 실행합니다. 내보내기 함수가 트리거되면 gcloud metastore services export 명령어를 사용하여 Cloud Storage로 메타데이터를 내보냅니다.
일반적으로 Hadoop 작업이 Hive Metastore에 쓰기 작업을 빈번하게 수행하면 Metastore를 자주 백업하는 것이 좋습니다. 백업 일정은 15분~60분 사이로 설정하는 것이 좋습니다.
Cloud Run 서비스 테스트 실행을 트리거합니다.
gcloud scheduler jobs run dpms-exportCloud Scheduler가 DPMS 내보내기 작업을 올바르게 트리거했는지 확인합니다.
gcloud metastore operations list --location ${REGION_A}다음과 유사한 결과가 출력됩니다.
OPERATION_NAME LOCATION TYPE TARGET DONE CREATE_TIME DURATION ... operation-a520936204508-5v23bx4y23f60-920f0a0f-9c2b56b5 us-central1 update dpms1 True 2021-05-13T20:05:04 2M23S
DONE값이False이면 내보내기가 아직 진행 중입니다. 작업이 완료되었는지 확인하려면 값이True가 될 때까지gcloud metastore operations list --location ${REGION_A}명령어를 다시 실행합니다.gcloud metastore operations명령어에 대한 자세한 내용은 참조 문서를 확인하세요.(선택사항) 대기 Metastore로 가져오기를 예약하기 위해 Cloud Scheduler 작업을 만듭니다.
gcloud scheduler jobs create http dpms-import \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${IMPORT_RUN_URL}/import
이 단계는 복구 시간 목표(RTO) 요구사항에 따라 달라집니다.
장애 조치 시간을 최소화하기 위해 핫 대기가 필요하면 이 가져오기 작업을 예약해야 합니다. 그러면 대기 DPMS가 15분 간격으로 새로고침됩니다.
RTO 요구에 따라 콜드 대기만으로 충분하면 이 단계를 건너뛰고 대기 DPMS와 Dataproc 클러스터도 삭제하여 전반적인 월간 비용을 더 줄일 수 있습니다. 대기 리전(리전 B)으로 장애 조치할 때는 대기 DPMS 및 Dataproc 클러스터를 프로비저닝하고 가져오기 작업도 실행합니다. 백업 파일이 이중 리전 버킷에 저장되기 때문에 기본 리전(리전 A)이 작동 중지되어도 액세스할 수 있습니다.
장애 조치 처리
리전 B로 장애 조치한 후에는 재해 복구 요구사항을 지키고 리전 B에서의 잠재적인 오류로부터 인프라를 보호하기 위해 다음 단계를 적용해야 합니다.
- 기존 Cloud Scheduler 작업을 일시중지합니다.
- 기본 DPMS 리전을 리전 B로 업데이트합니다(
us-east1). - 대기 DPMS 리전을 리전 A로 업데이트합니다(
us-central1). - DPMS 기본 인스턴스를
dpms2로 업데이트합니다. - DPMS 대기 인스턴스를
dpms1로 업데이트합니다. - 업데이트된 변수를 기반으로 Cloud Run 서비스를 다시 배포합니다.
- 새 Cloud Run 서비스를 가리키는 새로운 Cloud Scheduler 작업을 만듭니다.
앞에 표시된 목록에 필요한 단계는 이전 섹션의 많은 단계를 반복하며, 리전 이름 스왑과 같은 약간의 조정만 수행됩니다. 옵션 1: Cloud Run 및 Cloud Scheduler의 정보를 사용하여 이 필수 작업을 완료합니다.
옵션 2: Cloud Composer
이 섹션에서는 Cloud Composer를 사용하여 단일 Airflow 방향성 비순환 그래프(DAG) 내에서 내보내기 및 가져오기 작업을 실행하는 방법을 보여줍니다.
Cloud Shell에서 Cloud Composer API를 사용 설정합니다.
gcloud services enable composer.googleapis.comCloud Composer 환경을 만듭니다.
export COMPOSER_ENV=comp-env gcloud beta composer environments create ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --image-version composer-1.17.0-preview.1-airflow-2.0.1 \ --python-version 3다음 환경 변수로 Cloud Composer 환경을 구성합니다.
gcloud composer environments update ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --update-env-variables=DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION},DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE}Composer 환경에 DAG 파일을 업로드합니다.
gcloud composer environments storage dags import \ --environment ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --source dpms_dag.pyAirflow URL을 검색합니다.
gcloud composer environments describe ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --format "value(config.airflowUri)"브라우저에서 이전 명령어로 반환된 URL을 엽니다.
dpms_dag라는 새로운 DAG 항목이 표시됩니다. 단일 실행 내에서 DAG가 내보내기를 실행하고, 가져오기가 이어집니다. DAG는 대기 DPMS가 항상 작동된다고 가정합니다. 핫 대기가 필요하지 않고 내보내기 태스크만 실행하길 원하는 경우에는 코드에서 가져오기와 관련된 모든 태스크를 주석 처리해야 합니다(find_backup, wait_for_ready_status, current_ts,dpms_import).화살표 아이콘을 클릭하여 테스트 실행을 수행하도록 DAG를 트리거합니다.
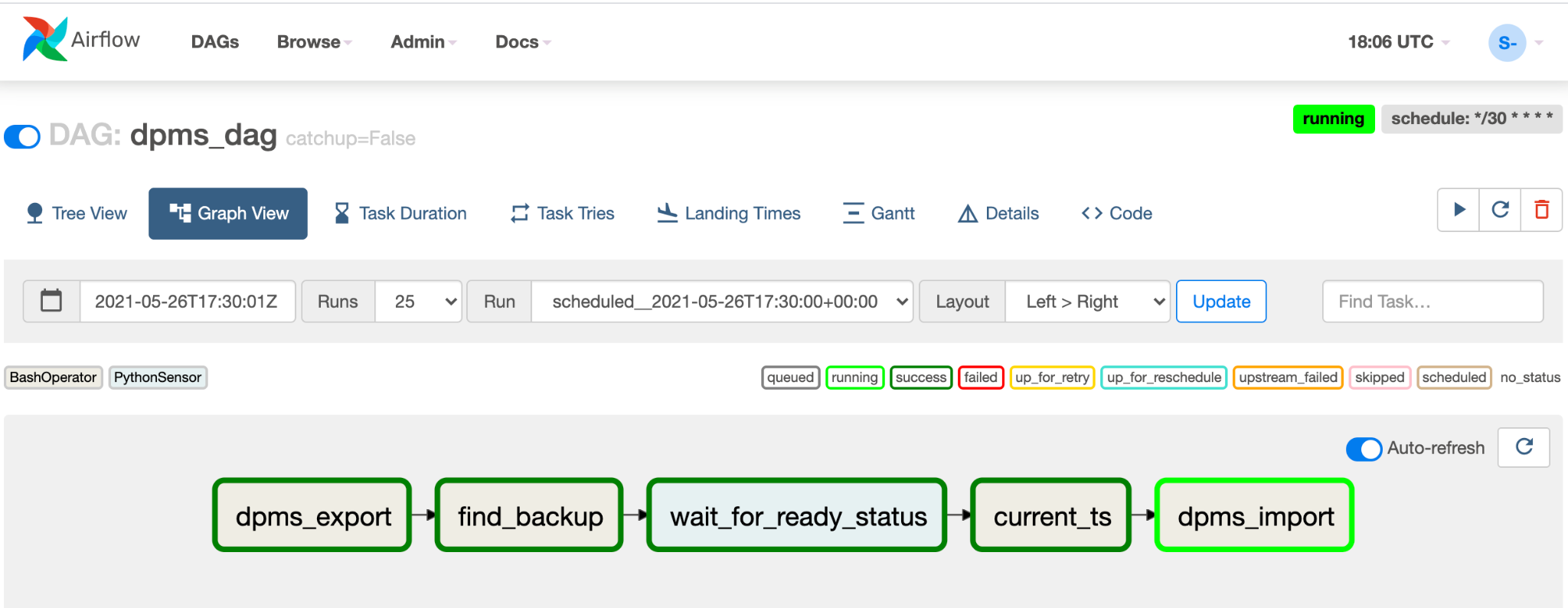
실행 중인 DAG의 그래프 뷰를 클릭하여 각 태스크의 상태를 확인합니다.
DAG 검증이 완료되었으면 Airflow가 정기적으로 실행되도록 합니다. 일정이 30분 간격으로 설정되지만 타이밍 요구사항에 맞게 코드에서
schedule_interval매개변수를 변경하여 조정할 수 있습니다.
장애 조치 처리
리전 B로 장애 조치한 후에는 재해 복구 요구사항을 지키고 리전 B에서의 잠재적인 오류로부터 인프라를 보호하기 위해 다음 단계를 적용해야 합니다.
- 기본 DPMS 리전을 리전 B로 업데이트합니다(
us-east1). - 대기 DPMS 리전을 리전 A로 업데이트합니다(
us-central1). - DPMS 기본 인스턴스를
dpms2로 업데이트합니다. - DPMS 대기 인스턴스를
dpms1로 업데이트합니다. - 리전 B에서 새 Cloud Composer 환경을 만듭니다(
us-east1). - 업데이트된 환경 변수로 Cloud Composer 환경을 구성합니다.
- 이전과 동일한
dpms_dagAirflow DAG를 새로운 Cloud Composer 환경으로 가져옵니다.
앞에 표시된 목록에 필요한 단계는 이전 섹션의 많은 단계를 반복하며, 리전 이름 스왑과 같은 약간의 조정만 수행됩니다. 옵션 2: Cloud Composer의 정보를 사용하여 이 필수 작업을 완료합니다.
삭제
이 튜토리얼에서 사용된 리소스 비용이 Google Cloud 계정에 청구되지 않도록 하려면 리소스가 포함된 프로젝트를 삭제하거나 프로젝트를 유지하고 개별 리소스를 삭제하세요.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
다음 단계
- Dataproc Metastore 인스턴스 모니터링 방법 알아보기
- Hive Metastore를 Data Catalog와 동기화하는 방법 이해
- Cloud Run 서비스 개발에 대해 자세히 알아보기
- 그 밖의 참조 아키텍처, 다이어그램, 튜토리얼, 권장사항을 알아보려면 클라우드 아키텍처 센터를 확인하세요.