Questo tutorial propone una strategia di ripristino di emergenza e continuità aziendale a due regioni utilizzando Dataproc Metastore. Il tutorial utilizza bucket dual-region per archiviare sia i set di dati Hive sia le esportazioni di metadati Hive.
Dataproc Metastore è un servizio di metastore completamente gestito, ad alta disponibilità, con scalabilità automatica, autoriparazione e nativo OSS che semplifica notevolmente la gestione dei metadati tecnici. Il nostro servizio gestito si basa su Apache Hive Metastore e funge da componente critico per i data lake aziendali.
Questo tutorial è pensato per i clienti che richiedono un'elevata disponibilità per i dati e i metadati Hive. Google Cloud Utilizza Cloud Storage per l'archiviazione, Dataproc per il calcolo e Dataproc Metastore (DPMS), un servizio Hive Metastore completamente gestito su Google Cloud. Il tutorial presenta anche due modi diversi di orchestrare i failover: uno utilizza Cloud Run e Cloud Scheduler, l'altro utilizza Cloud Composer.
L'approccio a due regioni utilizzato nel tutorial presenta vantaggi e svantaggi:
Vantaggi
- I bucket a due regioni sono ridondanti a livello geografico.
- I bucket dual-region hanno uno SLA con disponibilità del 99,95%, rispetto al 99,9% di disponibilità dei bucket in una singola regione.
- I bucket a due regioni hanno prestazioni ottimizzate in due regioni, mentre i bucket a una regione non funzionano altrettanto bene quando si lavora con risorse in altre regioni.
Svantaggi
- Le scritture nel bucket a due regioni non vengono replicate immediatamente in entrambe le regioni.
- I bucket dual-region hanno costi di archiviazione più elevati rispetto ai bucket single-region.
Architettura di riferimento
I seguenti diagrammi dell'architettura mostrano i componenti utilizzati in questo tutorial. In entrambi i diagrammi, la X rossa grande indica l'errore della regione primaria:
 Figura 1: utilizzo di Cloud Run e Cloud Scheduler
Figura 1: utilizzo di Cloud Run e Cloud Scheduler
 Figura 2: utilizzo di Cloud Composer
Figura 2: utilizzo di Cloud Composer
I componenti della soluzione e le relative relazioni sono:
- Due bucket Cloud Storage multiregionali:crei un bucket per i dati Hive e un bucket per i backup periodici dei metadati Hive. Crea bucket dual-region in modo che utilizzino le stesse regioni dei cluster Hadoop che accedono ai dati.
- Un metastore Hive che utilizza DPMS: crei questo metastore Hive nella tua regione principale (regione A). La configurazione del metastore punta al bucket di dati Hive. Un cluster Hadoop che utilizza Dataproc deve trovarsi nella stessa regione dell'istanza DPMS a cui è collegato.
- Una seconda istanza DPMS: crei una seconda istanza DPMS nella regione di standby (regione B) per prepararti a un errore a livello di regione. Successivamente, importa il file di esportazione
hive.sqlpiù recente dal bucket di esportazione nel DPMS di standby. Crea anche un cluster Dataproc nella regione di standby e collegalo all'istanza DPMS di standby. Infine, in uno scenario di ripristino di emergenza, reindirizzi le applicazioni client dal cluster Dataproc nella regione A al cluster Dataproc nella regione B. Un deployment Cloud Run:crei un deployment Cloud Run nella regione A che esporta periodicamente i metadati DPMS in un bucket di backup dei metadati utilizzando Cloud Scheduler (come mostrato nella Figura 1). L'esportazione assume la forma di un file SQL che contiene un dump completo dei metadati DPMS.
Se hai già un ambiente Cloud Composer, puoi orchestrare le esportazioni e le importazioni dei metadati DPMS eseguendo un DAG Airflow in quell'ambiente (come mostrato nella Figura 2). Questo utilizzo di un DAG di Airflow sostituirebbe il metodo Cloud Run menzionato in precedenza.
Obiettivi
- Configura l'archiviazione dual-region per i dati Hive e i backup di Hive Metastore.
- Esegui il deployment di un cluster Dataproc Metastore e Dataproc nelle regioni A e B.
- Esegui il failover del deployment nella regione B.
- Esegui il failback del deployment nella regione A.
- Crea backup automatici di Hive Metastore.
- Orchestra le esportazioni e le importazioni di metadati tramite Cloud Run.
- Orchestra le esportazioni e le importazioni di metadati tramite Cloud Composer.
Costi
In questo documento vengono utilizzati i seguenti componenti fatturabili di Google Cloud:
Per generare una stima dei costi in base all'utilizzo previsto,
utilizza il calcolatore prezzi.
Prima di iniziare
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataproc, and Dataproc Metastore APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Create a service account:
-
Ensure that you have the Create Service Accounts IAM role
(
roles/iam.serviceAccountCreator). Learn how to grant roles. -
In the Google Cloud console, go to the Create service account page.
Go to Create service account - Select your project.
-
In the Service account name field, enter a name. The Google Cloud console fills in the Service account ID field based on this name.
In the Service account description field, enter a description. For example,
Service account for quickstart. - Click Create and continue.
-
Grant the Project > Owner role to the service account.
To grant the role, find the Select a role list, then select Project > Owner.
- Click Continue.
-
Click Done to finish creating the service account.
Do not close your browser window. You will use it in the next step.
-
Ensure that you have the Create Service Accounts IAM role
(
-
Create a service account key:
- In the Google Cloud console, click the email address for the service account that you created.
- Click Keys.
- Click Add key, and then click Create new key.
- Click Create. A JSON key file is downloaded to your computer.
- Click Close.
- In Cloud Shell, avvia un'istanza di Cloud Shell.
Clona il repository GitHub del tutorial:
git clone https://github.com/GoogleCloudPlatform/metastore-disaster-recovery.gitAbilita le seguenti Google Cloud API:
gcloud services enable dataproc.googleapis.com metastore.googleapis.comImposta alcune variabili di ambiente:
export PROJECT=$(gcloud info --format='value(config.project)') export WAREHOUSE_BUCKET=${PROJECT}-warehouse export BACKUP_BUCKET=${PROJECT}-dpms-backups export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms2 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
Inizializza l'ambiente
Creazione di spazio di archiviazione per i dati Hive e i backup di Hive Metastore
In questa sezione, creerai bucket Cloud Storage per ospitare i dati Hive e i backup di Hive Metastore.
Crea spazio di archiviazione dei dati Hive
In Cloud Shell, crea un bucket dual-region per ospitare i dati Hive:
gcloud storage buckets create gs://${WAREHOUSE_BUCKET} --location=NAM4Copia alcuni dati di esempio nel bucket di dati Hive:
gcloud storage cp gs://retail_csv gs://${WAREHOUSE_BUCKET}/retail --recursive
Crea spazio di archiviazione per i backup dei metadati
In Cloud Shell, crea un bucket multiregionale per ospitare i backup dei metadati DPMS:
gcloud storage buckets create gs://${BACKUP_BUCKET} --location=NAM4
Deployment delle risorse di computing nella regione principale
In questa sezione, esegui il deployment di tutte le risorse di calcolo nella regione principale, inclusa l'istanza DPMS e il cluster Dataproc. Inoltre, puoi compilare Dataproc Metastore con metadati di esempio.
Crea l'istanza DPMS
In Cloud Shell, crea l'istanza DPMS:
gcloud metastore services create ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --hive-metastore-version=3.1.2Il completamento di questo comando può richiedere diversi minuti.
Imposta il bucket di dati Hive come directory warehouse predefinita:
gcloud metastore services update ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}- warehouse"Il completamento di questo comando può richiedere diversi minuti.
Crea un cluster Dataproc
In Cloud Shell, crea un cluster Dataproc e collegalo all'istanza DPMS:
gcloud dataproc clusters create ${HADOOP_PRIMARY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_PRIMARY_REGION}/services/${DPMS_PRIMARY_INSTANCE} \ --region=${DPMS_PRIMARY_REGION} \ --image-version=2.0Specifica l'immagine del cluster come versione 2.0, che è l'ultima versione disponibile a giugno 2021. È anche la prima versione che supporta DPMS.
Compilare il metastore
In Cloud Shell, aggiorna l'esempio
retail.hqlfornito nel repository di questo tutorial con il nome del bucket di dati Hive:sed -i -- 's/${WAREHOUSE_BUCKET}/'"$WAREHOUSE_BUCKET"'/g' retail.hqlEsegui le query contenute nel file
retail.hqlper creare le definizioni delle tabelle nel metastore:gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --file=retail.hqlVerifica che le definizioni delle tabelle siano state create correttamente:
gcloud dataproc jobs submit hive \ --cluster=${HADOOP_PRIMARY} \ --region=${DPMS_PRIMARY_REGION} \ --execute=" desc departments; desc categories; desc products; desc order_items; desc orders; desc customers; select count(*) as num_departments from departments; select count(*) as num_categories from categories; select count(*) as num_products from products; select count(*) as num_order_items from order_items; select count(*) as num_orders from orders; select count(*) as num_customers from customers; "L'output è simile al seguente:
+------------------+------------+----------+ | col_name | data_type | comment | +------------------+------------+----------+ | department_id | int | | | department_name | string | | +------------------+------------+----------+
L'output contiene anche il numero di elementi in ogni tabella, ad esempio:
+----------------+ | num_customers | +----------------+ | 12435 | +----------------+
Failover alla regione di standby
Questa sezione fornisce i passaggi per eseguire il failover dalla regione primaria (regione A) alla regione di standby (regione B).
In Cloud Shell, esporta i metadati dell'istanza DPMS principale nel bucket dei backup:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}L'output è simile al seguente:
metadataManagementActivity: metadataExports: ‐ databaseDumpType: MYSQL destinationGcsUri: gs://qa01-300915-dpms-backups/hive-export-2021-05-04T22:21:53.288Z endTime: '2021-05-04T22:23:35.982214Z' startTime: '2021-05-04T22:21:53.308534Z' state: SUCCEEDEDPrendi nota del valore dell'attributo
destinationGcsUri. Questo attributo memorizza il backup che hai creato.Crea una nuova istanza DPMS nella regione di standby:
gcloud metastore services create ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --hive-metastore-version=3.1.2Imposta il bucket di dati Hive come directory warehouse predefinita:
gcloud metastore services update ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --update-hive-metastore-configs="hive.metastore.warehouse.dir=gs://${PROJECT}-warehouse"Recupera il percorso dell'ultimo backup dei metadati:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importa i metadati di cui è stato eseguito il backup nella nuova istanza Dataproc Metastore:
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Crea un cluster Dataproc nella regione di standby (regione B):
gcloud dataproc clusters create ${HADOOP_STANDBY} \ --dataproc-metastore=projects/${PROJECT}/locations/${DPMS_STANDBY_REGION}/services/${DPMS_STANDBY_INSTANCE} \ --region=${DPMS_STANDBY_REGION} \ --image-version=2.0Verifica che i metadati siano stati importati correttamente:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select count(*) as num_orders from orders;"L'
num_ordersoutput è la parte più importante del tutorial. Avrà un aspetto simile al seguente:+-------------+ | num_orders | +-------------+ | 68883 | +-------------+Il metastore Dataproc Metastore principale è diventato il nuovo metastore di standby e il metastore Dataproc Metastore di standby è diventato il nuovo metastore principale.
Aggiorna le variabili di ambiente in base a questi nuovi ruoli:
export DPMS_PRIMARY_REGION=us-east1 export DPMS_STANDBY_REGION=us-central1] export DPMS_PRIMARY_INSTANCE=dpms2 export DPMS_STANDBY_INSTANCE=dpms1 export HADOOP_PRIMARY=dataproc-cluster2 export HADOOP_STANDBY=dataproc-cluster1Verifica di poter scrivere nel nuovo Dataproc Metastore principale nella regione B:
gcloud dataproc jobs submit hive \ --cluster ${DPMS_PRIMARY_INSTANCE} \ --region ${DPMS_PRIMARY_REGION} \ --execute "create view completed_orders as select * from orders where order_status = 'COMPLETE';" gcloud dataproc jobs submit hive \ --cluster ${HADOOP_PRIMARY} \ --region ${DPMS_PRIMARY_REGION} \ --execute "select * from completed_orders limit 5;"L'output contiene quanto segue:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
Il failover è ora completato. Ora devi reindirizzare le tue applicazioni client al nuovo cluster Dataproc primario nella regione B aggiornando i file di configurazione del client Hadoop.
Failback alla regione originale
Questa sezione fornisce i passaggi per eseguire il failback alla regione originale (regione A).
In Cloud Shell, esporta i metadati dall'istanza DPMS:
gcloud metastore services export gcs ${DPMS_PRIMARY_INSTANCE} \ --location=${DPMS_PRIMARY_REGION} \ --destination-folder=gs://${BACKUP_BUCKET}Recupera il percorso dell'ultimo backup dei metadati:
IMPORT_DIR=`gcloud storage ls gs://${BACKUP_BUCKET} | sort -k 1 | tail -1` IMPORT_SQL="${IMPORT_DIR}hive.sql" echo ${IMPORT_SQL}Importa i metadati nell'istanza DPMS di standby nella regione originale (regione A):
gcloud metastore services import gcs ${DPMS_STANDBY_INSTANCE} \ --location=${DPMS_STANDBY_REGION} \ --dump-type=mysql \ --database-dump=${IMPORT_SQL} \ --import-id=import-$(date +"%Y-%m-%d-%H-%M-%S")Verifica che i metadati siano stati importati correttamente:
gcloud dataproc jobs submit hive \ --cluster ${HADOOP_STANDBY} \ --region ${DPMS_STANDBY_REGION} \ --execute "select * from completed_orders limit 5;"L'output include quanto segue:
+----------------------------+------------------------------+-------------------------------------+--------------------------------+ | completed_orders.order_id | completed_orders.order_date | completed_orders.order_customer_id | completed_orders.order_status | +----------------------------+------------------------------+-------------------------------------+--------------------------------+ | 3 | 2013-07-25 00:00:00.0 | 12111 | COMPLETE | | 5 | 2013-07-25 00:00:00.0 | 11318 | COMPLETE | | 6 | 2013-07-25 00:00:00.0 | 7130 | COMPLETE | | 7 | 2013-07-25 00:00:00.0 | 4530 | COMPLETE | | 15 | 2013-07-25 00:00:00.0 | 2568 | COMPLETE | +----------------------------+------------------------------+-------------------------------------+--------------------------------+
I servizi Dataproc Metastore primario e di standby hanno nuovamente invertito i ruoli.
Aggiorna le variabili di ambiente con questi nuovi ruoli:
export DPMS_PRIMARY_REGION=us-central1 export DPMS_STANDBY_REGION=us-east1 export DPMS_PRIMARY_INSTANCE=dpms1 export DPMS_STANDBY_INSTANCE=dpms12 export HADOOP_PRIMARY=dataproc-cluster1 export HADOOP_STANDBY=dataproc-cluster2
Il failback è ora completato. Ora devi reindirizzare le applicazioni client al nuovo cluster Dataproc primario nella regione A aggiornando i file di configurazione del client Hadoop.
Creazione di backup automatici dei metadati
Questa sezione descrive due diversi metodi per automatizzare l'esportazione e l'importazione dei backup dei metadati. Il primo metodo, Opzione 1: Cloud Run e Cloud Scheduler, utilizza Cloud Run e Cloud Scheduler. Il secondo metodo, Opzione 2: Cloud Composer, utilizza Cloud Composer. In entrambi gli esempi, un job di esportazione crea un backup dei metadati dal DPMS principale nella regione A. Un job di importazione popola il DPMS di riserva nella regione B dal backup.
Se hai già un cluster Cloud Composer esistente, ti consigliamo di prendere in considerazione l'opzione 2: Cloud Composer (supponendo che il cluster abbia capacità di calcolo sufficiente). In caso contrario, scegli l'opzione 1: Cloud Run e Cloud Scheduler. Questa opzione utilizza un modello di prezzo con pagamento a consumo ed è più economica di Cloud Composer, che richiede l'utilizzo di risorse di calcolo permanenti.
Opzione 1: Cloud Run e Cloud Scheduler
Questa sezione mostra come utilizzare Cloud Run e Cloud Scheduler per automatizzare le esportazioni delle importazioni dei metadati DPMS.
Servizi Cloud Run
Questa sezione mostra come creare due servizi Cloud Run per eseguire i job di esportazione e importazione dei metadati.
In Cloud Shell, abilita le API Cloud Run, Cloud Scheduler, Cloud Build e App Engine:
gcloud services enable run.googleapis.com cloudscheduler.googleapis.com cloudbuild.googleapis.com appengine.googleapis.comAbilita l'API App Engine perché il servizio Cloud Scheduler richiede App Engine.
Crea l'immagine Docker con il Dockerfile fornito:
cd metastore-disaster-recovery gcloud builds submit --tag gcr.io/$PROJECT/dpms_drEsegui il deployment dell'immagine container in un servizio Cloud Run nella regione principale (regione A). Questo deployment è responsabile della creazione dei backup dei metadati dal metastore primario:
gcloud run deploy dpms-export \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_PRIMARY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION} \ --allow-unauthenticated \ --timeout=10mPer impostazione predefinita, una richiesta di servizio Cloud Run va in timeout dopo 5 minuti. Per garantire che tutte le richieste abbiano tempo sufficiente per essere completate correttamente, l'esempio di codice precedente estende il valore di timeout ad almeno 10 minuti.
Recupera l'URL di deployment per il servizio Cloud Run:
EXPORT_RUN_URL=$(gcloud run services describe dpms-export --platform managed --region ${DPMS_PRIMARY_REGION} --format ` "value(status.address.url)") echo ${EXPORT_RUN_URL}Crea un secondo servizio Cloud Run nella regione di standby (regione B). Questo servizio è responsabile dell'importazione dei backup dei metadati da
BACKUP_BUCKETnel metastore di standby:gcloud run deploy dpms-import \ --image gcr.io/${PROJECT}/dpms_dr \ --region ${DPMS_STANDBY_REGION} \ --platform managed \ --update-env-vars DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE} \ --allow-unauthenticated \ --timeout=10mRecupera l'URL di deployment per il secondo servizio Cloud Run:
IMPORT_RUN_URL=$(gcloud run services describe dpms-import --platform managed --region ${REGION_B} --format "value(status.address.url)") echo ${IMPORT_RUN_URL}
Pianificazione dei job
Questa sezione mostra come utilizzare Cloud Scheduler per attivare i due servizi Cloud Run.
In Cloud Shell, crea un'applicazione App Engine, richiesta da Cloud Scheduler:
gcloud app create --region=${REGION_A}Crea un job Cloud Scheduler per pianificare le esportazioni di metadati dal metastore principale:
gcloud scheduler jobs create http dpms-export \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${EXPORT_RUN_URL}/export\
Il job Cloud Scheduler effettua una richiesta http al
servizio Cloud Run ogni 15 minuti. Il servizio Cloud Run esegue un'applicazione Flask in un container con una funzione di esportazione e una di importazione. Quando viene attivata la funzione di esportazione, i metadati vengono esportati in Cloud Storage utilizzando il comando gcloud metastore services export.
In generale, se i tuoi job Hadoop scrivono spesso nell'Hive Metastore, ti consigliamo di eseguire spesso il backup del metastore. Una buona pianificazione del backup prevede un intervallo compreso tra 15 e 60 minuti.
Attiva un test del servizio Cloud Run:
gcloud scheduler jobs run dpms-exportVerifica che Cloud Scheduler abbia attivato correttamente l'operazione di esportazione DPMS:
gcloud metastore operations list --location ${REGION_A}L'output è simile al seguente:
OPERATION_NAME LOCATION TYPE TARGET DONE CREATE_TIME DURATION ... operation-a520936204508-5v23bx4y23f60-920f0a0f-9c2b56b5 us-central1 update dpms1 True 2021-05-13T20:05:04 2M23S
Se il valore di
DONEèFalse, l'esportazione è ancora in corso. Per confermare che l'operazione è stata completata, esegui di nuovo il comandogcloud metastore operations list --location ${REGION_A}finché il valore non diventaTrue.Scopri di più sui comandi
gcloud metastore operationsnella documentazione di riferimento.(Facoltativo) Crea un job Cloud Scheduler per pianificare le importazioni nel metastore di standby:
gcloud scheduler jobs create http dpms-import \ --schedule "*/15 * * * *" \ --http-method=post \ --uri=${IMPORT_RUN_URL}/import
Questo passaggio dipende dai requisiti del Recovery Time Objective (RTO).
Se vuoi un hot standby per ridurre al minimo il tempo di failover, devi programmare questo job di importazione. Aggiorna la modalità DPMS in standby ogni 15 minuti.
Se un cold standby è sufficiente per le tue esigenze di RTO, puoi saltare questo passaggio ed eliminare anche il DPMS di standby e il cluster Dataproc per ridurre ulteriormente la fattura mensile complessiva. Quando esegui il failover nella regione di standby (regione B), esegui il provisioning di DPMS di standby e del cluster Dataproc ed esegui anche un job di importazione. Poiché i file di backup sono archiviati in un bucket dual-region, sono accessibili anche se la regione principale (regione A) non è disponibile.
Gestire i failover
Dopo il failover nella regione B, devi applicare i seguenti passaggi per mantenere i requisiti di ripristino di emergenza e proteggere la tua infrastruttura da un potenziale errore nella regione B:
- Metti in pausa i job Cloud Scheduler esistenti.
- Aggiorna la regione DPMS della primaria alla regione B (
us-east1). - Aggiorna la regione DPMS dello standby alla regione A (
us-central1). - Aggiorna l'istanza principale DPMS a
dpms2. - Aggiorna l'istanza di standby DPMS a
dpms1. - Esegui nuovamente il deployment dei servizi Cloud Run in base alle variabili aggiornate.
- Crea nuovi job Cloud Scheduler che puntano ai tuoi nuovi servizi Cloud Run.
I passaggi richiesti nell'elenco precedente ripetono molti passaggi delle sezioni precedenti, ma con piccole modifiche (come lo scambio dei nomi delle regioni). Utilizza le informazioni riportate in Opzione 1: Cloud Run e Cloud Scheduler per completare questo lavoro richiesto.
Opzione 2: Cloud Composer
Questa sezione mostra come utilizzare Cloud Composer per eseguire i job di esportazione e importazione all'interno di un singolo grafo diretto aciclico (DAG) di Airflow.
In Cloud Shell, abilita l'API Cloud Composer:
gcloud services enable composer.googleapis.comCrea un ambiente Cloud Composer:
export COMPOSER_ENV=comp-env gcloud beta composer environments create ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --image-version composer-1.17.0-preview.1-airflow-2.0.1 \ --python-version 3- L'immagine di Composer
composer-1.17.0-preview.1-airflow-2.0.1è l'ultima versione al momento della pubblicazione. - Gli ambienti Composer possono utilizzare una sola versione principale di Python. Python 3 è stato selezionato perché Python 2 presenta problemi di supporto.
- L'immagine di Composer
Configura l'ambiente Cloud Composer con queste variabili di ambiente:
gcloud composer environments update ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --update-env-variables=DPMS_PRIMARY_REGION=${DPMS_PRIMARY_REGION},DPMS_STANDBY_REGION=${DPMS_STANDBY_REGION},BACKUP_BUCKET=${BACKUP_BUCKET},DPMS_PRIMARY_INSTANCE=${DPMS_PRIMARY_INSTANCE},DPMS_STANDBY_INSTANCE=${DPMS_STANDBY_INSTANCE}Carica il file DAG nel tuo ambiente Composer:
gcloud composer environments storage dags import \ --environment ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --source dpms_dag.pyRecupera l'URL di Airflow:
gcloud composer environments describe ${COMPOSER_ENV} \ --location ${DPMS_PRIMARY_REGION} \ --format "value(config.airflowUri)"Nel browser, apri l'URL restituito dal comando precedente.
Dovresti visualizzare una nuova voce DAG denominata
dpms_dag. In una singola esecuzione, il DAG esegue un'esportazione, seguita da un'importazione. Il DAG presuppone che il DPMS in standby sia sempre attivo. Se non hai bisogno di un hot standby e vuoi solo eseguire l'attività di esportazione, devi commentare tutte le attività correlate all'importazione nel codice (find_backup, wait_for_ready_status, current_ts,dpms_import).Fai clic sull'icona Freccia per attivare il DAG e fare un test:
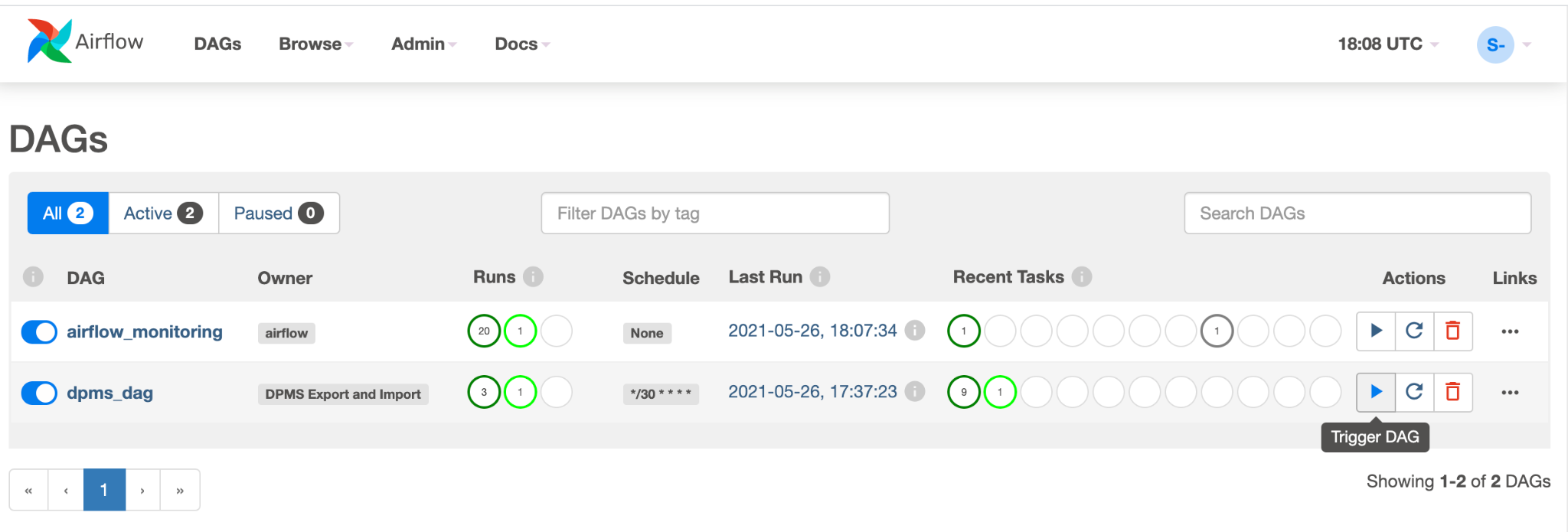
Fai clic su Visualizzazione grafica del DAG in esecuzione per controllare lo stato di ogni attività:
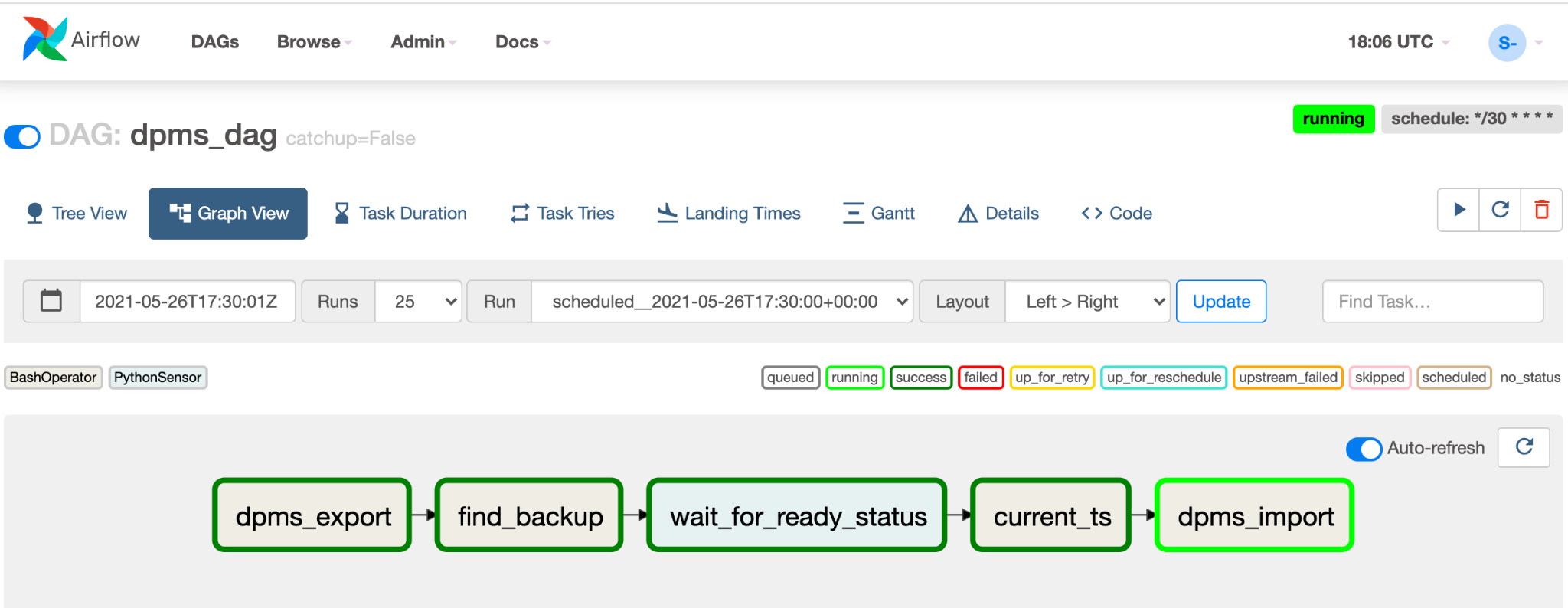
Una volta convalidato il DAG, lascia che Airflow lo esegua regolarmente. La pianificazione è impostata su un intervallo di 30 minuti, ma può essere modificata cambiando il parametro
schedule_intervalnel codice per soddisfare i tuoi requisiti di tempistica.
Gestire i failover
Dopo il failover nella regione B, devi applicare i seguenti passaggi per mantenere i requisiti di ripristino di emergenza e proteggere la tua infrastruttura da un potenziale errore nella regione B:
- Aggiorna la regione DPMS della primaria alla regione B (
us-east1). - Aggiorna la regione DPMS dello standby alla regione A (
us-central1). - Aggiorna l'istanza principale DPMS a
dpms2. - Aggiorna l'istanza di standby DPMS a
dpms1. - Crea un nuovo ambiente Cloud Composer nella regione B (
us-east1). - Configura l'ambiente Cloud Composer con le variabili di ambiente aggiornate.
- Importa lo stesso DAG Airflow
dpms_dagdi prima nel nuovo ambiente Cloud Composer.
I passaggi richiesti nell'elenco precedente ripetono molti passaggi delle sezioni precedenti, ma con piccole modifiche (come lo scambio dei nomi delle regioni). Utilizza le informazioni riportate in Opzione 2: Cloud Composer per completare questo lavoro richiesto.
Esegui la pulizia
Per evitare che al tuo account Google Cloud vengano addebitati costi relativi alle risorse utilizzate in questo tutorial, elimina il progetto che contiene le risorse oppure mantieni il progetto ed elimina le singole risorse.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Passaggi successivi
- Scopri come monitorare l'istanza Dataproc Metastore.
- Scopri come sincronizzare il tuo metastore Hive con Data Catalog
- Scopri di più sullo sviluppo dei servizi Cloud Run
- Per ulteriori architetture di riferimento, diagrammi e best practice, esplora il Cloud Architecture Center.