Auf dieser Seite wird erläutert, warum und wie Sie mit dem Feature MLTransform Daten für das Trainieren von ML-Modellen vorbereiten. Durch die Kombination mehrerer Datenverarbeitungstransformationen in einer Klasse optimiert MLTransform den Prozess der Anwendung von Apache Beam ML-Datenverarbeitungsabläufe auf Ihren Workflow.
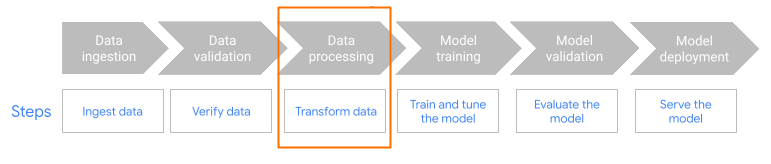
MLTransform im Vorverarbeitungsschritt des Workflows.
Vorteile
Die Klasse MLTransform bietet folgende Vorteile:
- Transformieren Sie Daten, ohne komplexen Code zu schreiben oder zugrundeliegende Bibliotheken zu verwalten.
- Einbettungen erstellen, mit denen Sie Daten in Vektordatenbanken verschieben oder Inferenzen ausführen können.
- Mehrere Arten von Verarbeitungsvorgängen lassen sich mit einer Schnittstelle effizient verketten.
Unterstützung und Einschränkungen
Für die Klasse MLTransform gelten die folgenden Einschränkungen:
- Verfügbar für Pipelines, die das Apache Beam Python SDK Version 2.53.0 und höher verwenden.
- Pipelines müssen Standardfenster verwenden.
Texteinbettungstransformationen:
- Unterstützung von Python 3.8, 3.9, 3.10, 3.11 und 3.12.
- Sie unterstützen sowohl Batch- als auch Streamingpipelines.
- Unterstützt die Vertex AI Text-Einbettungs-API und das Hugging Face Sentence Transformers-Modul.
Transformationen zur Datenverarbeitung, die TFT verwenden:
- Unterstützung von Python 3.9, 3.10, 3.11.
- Batchpipelines unterstützen
Anwendungsfälle
Die Beispiel-Notebooks zeigen, wie MLTransform für bestimmte Anwendungsfälle verwendet wird.
- Ich möchte Texteinbettungen für mein LLM mit Vertex AI generieren
- Verwenden Sie die Apache Beam-Klasse
MLTransformmit der Vertex AI Text-Einbettungs-API, um Texteinbettungen zu generieren. Texteinbettungen sind eine Möglichkeit, Text als numerische Vektoren darzustellen, was für viele NLP-Aufgaben (Natural Language Processing) erforderlich ist. - Ich möchte mithilfe von Hugging Face Texteinbettungen für mein LLM generieren
- Verwenden Sie die Apache Beam-Klasse
MLTransformmit Hugging Face Hub-Modellen, um Texteinbettungen zu generieren. Das Hugging Face-FrameworkSentenceTransformersverwendet Python, um Satz-, Text- und Bildeinbettungen zu generieren. - Ich möchte ein Vokabular aus einem Dataset berechnen
- Berechnen Sie ein eindeutiges Vokabular aus einem Dataset und ordnen Sie dann jedes Wort oder Token einem bestimmten Ganzzahlindex zu. Mit dieser Transformation können Sie Textdaten in Aufgaben für maschinelles Lernen in numerische Darstellungen umwandeln.
- Ich möchte meine Daten skalieren, um mein ML-Modell zu trainieren
- Skalieren Sie Ihre Daten, damit Sie sie zum Trainieren Ihres ML-Modells verwenden können. Die Apache Beam-Klasse
MLTransformenthält mehrere Datenskalierungstransformationen.
Eine vollständige Liste der verfügbaren Transformationen finden Sie unter Transformationen in der Apache Beam-Dokumentation.
MLTransform verwenden
Wenn Sie Daten mit der Klasse MLTransform vorverarbeiten möchten, fügen Sie den folgenden Code in Ihre Pipeline ein:
import apache_beam as beam
from apache_beam.ml.transforms.base import MLTransform
from apache_beam.ml.transforms.tft import TRANSFORM_NAME
import tempfile
data = [
{
DATA
},
]
artifact_location = gs://BUCKET_NAME
TRANSFORM_FUNCTION_NAME = TRANSFORM_NAME (columns=['x'])
with beam.Pipeline() as p:
transformed_data = (
p
| beam.Create(data)
| MLTransform(write_artifact_location=artifact_location).with_transform(
TRANSFORM_FUNCTION_NAME )
| beam.Map(print))
Ersetzen Sie die folgenden Werte:
TRANSFORM_NAME: der Name der Transformation zur VerwendungBCUKET_NAME: der Name Ihres Cloud Storage-BucketsDATA: die zu transformierenden EingabedatenTRANSFORM_FUNCTION_NAME: der Name, den Sie der Transformationsfunktion in Ihrem Code zuweisen
Nächste Schritte
- Weitere Informationen zu
MLTransformfinden Sie in der Apache Beam-Dokumentation unter Daten vorverarbeiten. - Weitere Beispiele finden Sie im Apache Beam-Transformationskatalog unter MLTransform für die Datenverarbeitung
MLTransform. - Führen Sie ein Interaktives Notebook in Colab aus.