Datenherkunft für eine BigQuery-Tabelle nachverfolgen
Mit der Datenherkunft können Sie nachvollziehen, wie Daten sich durch Ihre Systeme bewegen: woher sie stammen, wohin sie übertragen werden und welche Transformationen auf sie angewendet werden.
In dieser Kurzanleitung erfahren Sie, wie Sie mit der Nachverfolgung der Datenherkunft für BigQuery-Kopier- und ‑Abfragejobs beginnen:
Kopieren Sie zwei Tabellen aus einem öffentlich verfügbaren
new_york_taxi_trips-Dataset.Kombinieren Sie die Gesamtzahl der Taxifahrten aus beiden Tabellen in einer neuen Tabelle.
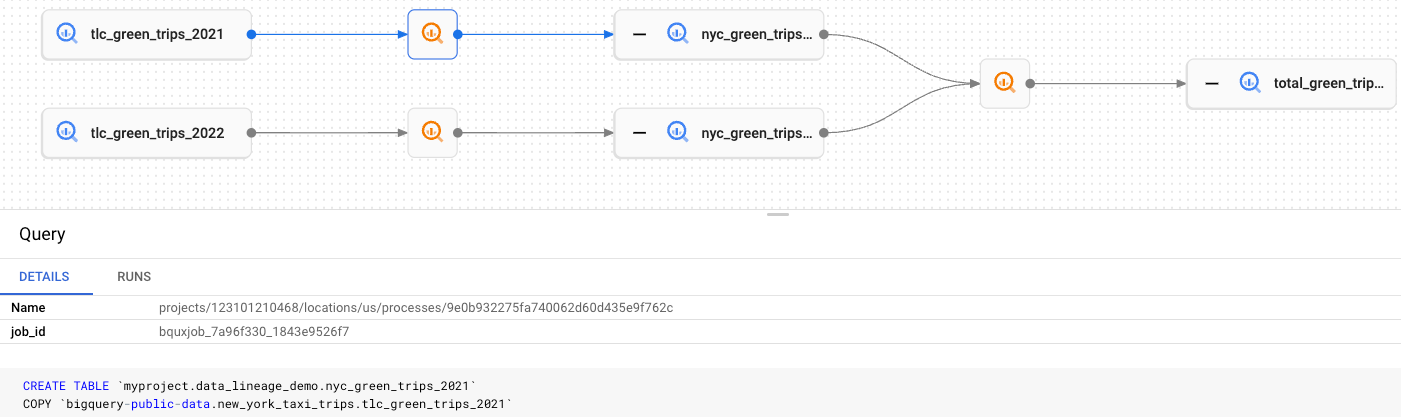
Sie können sich ein Lineage-Visualisierungsdiagramm für alle drei Vorgänge ansehen.
Hinweise
Projekt einrichten:
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataplex, BigQuery, and Data Lineage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
Enable the Dataplex, BigQuery, and Data Lineage APIs.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM role (
roles/serviceusage.serviceUsageAdmin), which contains theserviceusage.services.enablepermission. Learn how to grant roles. -
Dataplex Catalog Viewer (
roles/dataplex.catalogViewer) für das Ressourcenprojekt des Dataplex Universal Catalog -
Data Lineage-Betrachter (
roles/datalineage.viewer) für das Projekt, in dem Sie BigQuery verwenden -
BigQuery Data Viewer (
roles/bigquery.dataViewer) für das Projekt, in dem Sie BigQuery verwenden Rufen Sie in der Google Cloud Console die Seite "BigQuery" auf.
Klicken Sie im Bereich Explorer auf Daten hinzufügen.
Wählen Sie im Bereich Daten hinzufügen die Option Öffentliche Datasets aus.
Suchen Sie im Bereich Marketplace nach
NYC TLC Tripsund klicken Sie auf das Ergebnis NYC TLC Trips.Klicken Sie auf Dataset aufrufen.
Wählen Sie im Bereich Explorer das Projekt aus, in dem Sie das Dataset erstellen möchten.
Klicken Sie auf Aktionen und dann auf Dataset erstellen.
Geben Sie auf der Seite Dataset erstellen im Feld Dataset-ID Folgendes ein:
data_lineage_demo. Übernehmen Sie für alle anderen Felder die Standardwerte.Klicken Sie auf Dataset erstellen.
Klicken Sie im Bereich Explorer auf das neu hinzugefügte
data_lineage_demo.Öffnen Sie einen Abfrageeditor: Klicken Sie im Detailbereich neben dem Tab
data_lineage_demoauf (Neue Abfrage erstellen). Mit diesem Schritt wird ein Tab mit dem NamenUntitlederstellt.Kopieren Sie im Abfrageeditor die erste Tabelle, indem Sie die folgende Abfrage eingeben. Ersetzen Sie
PROJECT_IDdurch die Kennung Ihres Projekts.CREATE TABLE `PROJECT_ID.data_lineage_demo.nyc_green_trips_2021` COPY `bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2021`Klicken Sie auf Ausführen. In diesem Schritt wird die erste Tabelle mit dem Namen
nyc_green_trips_2021erstellt.Klicken Sie im Bereich Abfrageergebnisse auf Tabelle aufrufen. In diesem Schritt wird der Inhalt der ersten Tabelle angezeigt.
Kopieren Sie im Abfrageeditor die zweite Tabelle, indem Sie die vorherige Abfrage durch die folgende Abfrage ersetzen. Ersetzen Sie
PROJECT_IDdurch die Kennung Ihres Projekts.CREATE TABLE `PROJECT_ID.data_lineage_demo.nyc_green_trips_2022` COPY `bigquery-public-data.new_york_taxi_trips.tlc_green_trips_2022`Klicken Sie auf Ausführen. In diesem Schritt wird die zweite Tabelle mit dem Namen
nyc_green_trips_2022erstellt.Klicken Sie im Bereich Abfrageergebnisse auf Tabelle aufrufen. In diesem Schritt wird der Inhalt der zweiten Tabelle angezeigt.
Geben Sie im Abfrageeditor die folgende Abfrage ein. Ersetzen Sie
PROJECT_IDdurch die ID Ihres Projekts.CREATE TABLE `PROJECT_ID.data_lineage_demo.total_green_trips_22_21` AS SELECT vendor_id, COUNT(*) AS number_of_trips FROM ( SELECT vendor_id FROM `PROJECT_ID.data_lineage_demo.nyc_green_trips_2022` UNION ALL SELECT vendor_id FROM `PROJECT_ID.data_lineage_demo.nyc_green_trips_2021` ) GROUP BY vendor_idKlicken Sie auf Ausführen. In diesem Schritt wird eine kombinierte Tabelle mit dem Namen
total_green_trips_22_21erstellt.Klicken Sie im Bereich Abfrageergebnisse auf Tabelle aufrufen. In diesem Schritt wird die zusammengeführte Tabelle angezeigt.
Rufen Sie in der Google Cloud Console die Dataplex Universal Catalog-Seite Suche auf.
Wählen Sie unter Suchplattform auswählen den Suchmodus Dataplex Universal Catalog aus.
Geben Sie
total_green_trips_22_21in das Suchfeld ein und klicken Sie auf Suchen.Klicken Sie in der Ergebnisliste auf
total_green_trips_22_21. In diesem Schritt wird der Tab Details der BigQuery-Tabelle angezeigt.Klicken Sie auf den Tab Herkunft.
Wenn Sie die Quelle einer Tabelle ein- oder ausblenden möchten, klicken Sie auf + (Maximieren) oder – (Minimieren).
Klicken Sie auf einen Knoten, um Tabelleninformationen aufzurufen. In diesem Schritt wird der Bereich Knotendetails angezeigt.
Klicken Sie auf
 , um Prozessinformationen aufzurufen.
In diesem Schritt wird der Bereich Details für den Prozess angezeigt, in dem der Job zu sehen ist, mit dem eine Quelltabelle in eine Zieltabelle umgewandelt wurde.
, um Prozessinformationen aufzurufen.
In diesem Schritt wird der Bereich Details für den Prozess angezeigt, in dem der Job zu sehen ist, mit dem eine Quelltabelle in eine Zieltabelle umgewandelt wurde.- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Öffnen Sie in der Google Cloud Console die Seite BigQuery.
Suchen Sie im Bereich Explorer nach dem von Ihnen erstellten Dataset
data_lineage_demo.Klicken Sie mit der rechten Maustaste auf das Dataset und wählen Sie Löschen aus.
Bestätigen Sie den Löschvorgang.
Erforderliche Rollen
Bitten Sie Ihren Administrator, Ihnen die folgenden IAM-Rollen zuzuweisen, um die Berechtigungen zu erhalten, die Sie zum Aufrufen von Diagrammen zur Herkunftsvisualisierung benötigen:
Weitere Informationen zum Zuweisen von Rollen finden Sie unter Zugriff auf Projekte, Ordner und Organisationen verwalten.
Sie können die erforderlichen Berechtigungen auch über benutzerdefinierte Rollen oder andere vordefinierte Rollen erhalten.
Öffentliches Dataset zum Projekt hinzufügen
Dadurch wird das Projekt des öffentlichen Datasets als Referenz hinzugefügt, die Sie im Bereich Explorer aufrufen können. Im Detailbereich werden die Dataset-Informationen angezeigt, einschließlich Informationen wie Dataset-ID, Speicherort der Daten und Zuletzt geändert.
Dataset in Ihrem Projekt erstellen
Im Detailbereich werden die Dataset-Informationen angezeigt.
Zwei öffentlich zugängliche Tabellen in Ihr Dataset kopieren
Daten in einer neuen Tabelle zusammenfassen
Lineage-Diagramm in Dataplex Universal Catalog ansehen

Im Lineage-Diagramm stellt jeder rechteckige Knoten eine Tabelle dar, entweder eine Original-, eine kopierte oder eine kombinierte Tabelle. In diesem Fall können Sie folgende Aktionen ausführen:
Bereinigen
Mit den folgenden Schritten vermeiden Sie, dass Ihrem Google Cloud -Konto die auf dieser Seite verwendeten Ressourcen in Rechnung gestellt werden: