次のデータアセットを検索できます。
- Analytics Hub にリンクされたデータセット。
- BigQuery のデータセット、テーブル、ビュー、モデル
- Bigtable のインスタンス、クラスタ、テーブル(列ファミリーの詳細を含む)
- Data Catalog のタグ テンプレート、エントリ グループ、カスタム エントリ。
- Dataplex のレイク、ゾーン、テーブル、ファイルセット
- Dataproc Metastore のサービス、データベース、テーブル
- Pub/Sub データ ストリーム
- Spanner のインスタンス、データベース、テーブル、ビュー
- Vertex AI モデル、データセット、Vertex AI Feature Store リソース
- Data Catalog に接続されている、エンタープライズ データサイロ内のアセット
検索範囲
権限によっては検索結果が異なる場合があります。 Data Catalog の検索結果は、ロールに応じてスコープが設定されます。
Data Catalog で使用可能なさまざまな IAM ロールと権限を確認できます。たとえば、オブジェクトに対する BigQuery メタデータの読み取りアクセス権を持っている場合、そのオブジェクトが Data Catalog の検索結果に表示されます。
次のリストに、検索を実行するために必要な最小限の権限を示します。
テーブルを検索するには、そのテーブルに対する
bigquery.tables.get権限が必要です。データセットを検索するには、そのデータセットに対する
bigquery.datasets.get権限が必要です。データセットまたはテーブルのメタデータを検索するには、
roles/bigquery.metadataViewerIAM ロールが必要です。プロジェクト内または組織内のすべてのリソースを検索するには、
datacatalog.catalogs.searchAll権限が必要です。移行元システムに依存せず、すべてのリソースで機能します。
BigQuery テーブルにアクセスできるものの、そのテーブルを含むデータセットへのアクセス権がない場合でも、テーブルは Data Catalog の検索で想定どおりに表示されます。Pub/Sub や Data Catalog など、サポートされているすべてのシステムに同じアクセス ロジックが適用されます。
検索での再現率の問題
Data Catalog の検索クエリは、完全な再現率を保証するものではありません。以降の結果ページであっても、クエリに一致する結果が返されない場合があります。また、検索クエリを繰り返すと、返される(返されない)結果が変わることがあります。
再現率の問題があり、特定の順序で結果を取得する必要がない場合は、catalog.search メソッドを呼び出すときに orderBy パラメータを default に設定することを検討してください。
admin_search フラグを使用する
検索リクエストで admin_search フラグを使用すると、完全なレコールが保証されます。管理者検索では、検索範囲内のすべてのプロジェクトと組織に datacatalog.catalogs.searchAll 権限が設定されている必要があります。admin_search を使用する場合は、default orderBy のみが許可されます。
日付別テーブル
Data Catalog は、日付別テーブルを単一の論理エントリに集計します。このエントリには、最新の日付のテーブル シャードと同じスキーマが含まれ、シャードの合計数に関する集計情報が含まれます。このエントリは、自身が属するデータセットのアクセスレベルを継承します。論理エントリを含むデータセットへのアクセス権をユーザーが持っている場合、Data Catalog の検索には、これらの論理エントリのみが表示されます。個々の日付共有テーブルは Data Catalog の検索に表示されません。これは、Data Catalog に日付共有テーブルが存在していて、タグ付けできる場合でも変わりません。
フィルタ
フィルタを使用すると、検索結果を絞り込むことができます。すべてのフィルタはセクションに分かれています。
- スコープ: スター付きアイテムのみに検索を制限します。
- システム: BigQuery、Pub/Sub、Dataplex、Dataproc Metastore、カスタム システム、Vertex AI、Data Catalog など。Data Catalog システムには、ファイルセットとカスタム エントリが含まれています。
- レイクとゾーン: Dataplex から取得されます。
- データ型: データ ストリーム、データセット、レイク、ゾーン、ファイルセット、モデル、テーブル、ビュー、サービス、データベース、カスタムタイプなど。
- [プロジェクト] には、使用可能なすべてのプロジェクトが一覧表示されます。
- [タグ] には、利用可能なすべてのタグ テンプレート(およびその個々のフィールド)が表示されます。
- データセットは BigQuery と Vertex AI から取得されます。
- [一般公開データセット] は、BigQuery の一般公開データです。
複数のセクションのフィルタを組み合わせると、選択したすべてのセクションから 1 つ以上の条件に一致するアセットを見つけることができます。1 つのセクション内で選択した複数のフィルタは、OR 論理演算子を使用して評価されます。たとえば、次のフィルタの組み合わせについて考えてみます。

Data Catalog は以下を探します。
MyTemplate1テンプレートがタグ付けされた BigQuery データセット。MyTemplate2テンプレートがタグ付けされた BigQuery データセット。MyTemplate1テンプレートがタグ付けされた BigQuery テーブル。MyTemplate2テンプレートがタグ付けされた BigQuery テーブル。
タグ値でフィルタ
[タグ] フィルタを使用すると、特定のテンプレートを使用してタグ付けされたアセットにクエリを実行できます。 [カスタマイズ] メニューを使用すると、結果をさらに絞り込んだり、特定のタグ値でフィルタしたりできます。タグ値のフィルタ条件は、そのタグ フィールドのデータ型によって異なります。たとえば、日時フィールドと数値フィールドには、特定の日付または範囲を指定できます。
フィルタの可視性
各セクションに表示されるフィルタは、[検索] ボックスの現在のクエリによって異なります。検索結果セット全体に現在のクエリに一致するエントリが含まれていても、それらのエントリに対応するフィルタが [フィルタ] ペインに表示されない場合があります。
データアセットを検索する
コンソール
コンソール
Google Cloud コンソールで、Dataplex の [検索] ページに移動します。
[検索プラットフォームを選択] で、検索モードとして [Data Catalog] を選択します。
検索フィールドにクエリを入力するか、[フィルタ] ペインを使用して検索パラメータを絞り込みます。
次のフィルタを手動で追加できます。
- [プロジェクト] で、プロジェクト フィルタを追加します。[プロジェクトを追加] をクリックして、特定のプロジェクトを検索して選択し、[開く] をクリックします。
- [タグ] で、タグ テンプレート フィルタを追加します。[タグ テンプレートをさらに追加] メニューをクリックし、特定のテンプレートを検索して選択し、[OK] をクリックします。
使用可能なアセットに加えて、 Google Cloud で一般公開されているデータアセットを検索するには、[一般公開データセットを含める] を選択します。
また、次の操作も行うことができます。
検索フィールドの検索キーワードに「keyword:value」をつけて検索すると絞り込みができます。
キーワード 説明 name:データアセット名に一致する column:列名またはネストされた列名に一致する description:テーブルの説明に一致する 検索フィールドで検索キーワードに次のいずれかのタグ プレフィックスを追加すると、タグ検索を実行できます。
タグ 説明 tag:project-name.tag_template_nameタグ名に一致する tag:project-name.tag_template_name.keyタグキーに一致する tag:project-name.tag_template_name.key:valuekey:string valueタグのペアに一致
検索式のヒント
スペースが含まれている場合は、検索式を引用符で囲みます("
search terms")。キーワードの前に "NOT"(すべて大文字)を付けると、
keyword:termフィルタの論理否定に一致します。ブール演算子「AND」と「OR」(すべて大文字)を使って、検索式を結合することもできます。たとえば、
NOT column:termは、指定された用語に一致するもの以外のすべての列を一覧表示します。Data Catalog 検索式で使用できるキーワードとその他の用語のリストについては、Data Catalog の検索構文をご覧ください。
検索の例
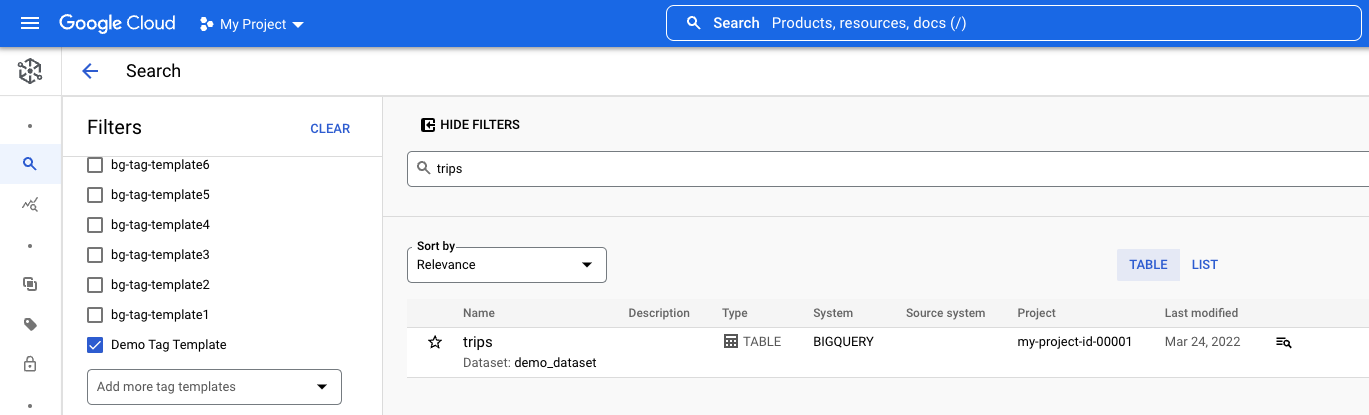
Data Catalog を使用して BigQuery テーブルにタグ付けするで設定した trips テーブルを検索する例について考えてみましょう。
- 検索フィールドに「
trips」と入力し、[検索] をクリックします。 [フィルタ] ペインで、以下を選択します。
- [システム] セクションで [BigQuery] を選択し、他のシステムに属する同じ名前のデータアセットを除外します。
- 他のプロジェクトのデータアセットを除外するには、[プロジェクト] セクションでプロジェクト ID を選択します。プロジェクトが表示されない場合は、[プロジェクトを追加] をクリックしてプロジェクトを選択します。
- [タグ] セクションで [デモ タグ テンプレート] を選択し、このテンプレートを使用するタグが
tripsテーブルに添付されているかどうかを確認します。このテンプレートが表示されない場合は、[タグ テンプレートをさらに追加] をクリックして、タグ テンプレートを検索して選択し、[OK] をクリックします。
選択したすべてのフィルタで、検索結果に含まれるエントリは、プロジェクト内の Demo Tag Template テンプレートを使用したタグが付いた BigQuery の trips テーブル 1 つだけです。
Java
このサンプルを試す前に、クライアント ライブラリを使用した Data Catalog のクイックスタートにある Java の設定手順を行ってください。 詳細については、Data Catalog Java API のリファレンス ドキュメントをご覧ください。
Data Catalog への認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Node.js
このサンプルを試す前に、クライアント ライブラリを使用した Data Catalog のクイックスタートにある Node.js の設定手順を行ってください。 詳細については、Data Catalog Node.js API のリファレンス ドキュメントをご覧ください。
Data Catalog への認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
Python
このサンプルを試す前に、クライアント ライブラリを使用した Data Catalog のクイックスタートにある Python の設定手順を行ってください。 詳細については、Data Catalog Python API のリファレンス ドキュメントをご覧ください。
Data Catalog への認証を行うには、アプリケーションのデフォルト認証情報を設定します。詳細については、ローカル開発環境の認証の設定をご覧ください。
REST とコマンドライン
REST
ご使用の言語の Cloud クライアント ライブラリにアクセスしない場合、または REST リクエストを使用して API をテストする場合は、次の例を参照して、Data Catalog REST API のドキュメントをご覧ください。
1. カタログを検索。
リクエストのデータを使用する前に、次のように置き換えます。
- organization-id: GCP 組織 ID
- project-id: GCP プロジェクト ID
HTTP メソッドと URL:
POST https://datacatalog.googleapis.com/v1/catalog:search
リクエストの本文(JSON):
{
"query":"trips",
"scope":{
"includeOrgIds":[
"organization-id"
]
}
}
リクエストを送信するには、次のいずれかのオプションを展開します。
次のような JSON レスポンスが返されます。
{
"results":[
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry1-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/taxi_trips"
},
{
"searchResultType":"ENTRY",
"searchResultSubtype":"entry.table",
"relativeResourceName":"projects/project-id/locations/US/entryGroups/@bigquery/entries/entry2-id",
"linkedResource":"//bigquery.googleapis.com/projects/project-id/datasets/demo_dataset/tables/tlc_yellow_trips_2018"
}
]
}
テーブルの詳細の表示
Data Catalog を使用してテーブルの詳細を表示します。
Google Cloud コンソールで、Dataplex の [検索] ページに移動します。
[検索プラットフォームを選択] で、検索モードとして [Data Catalog] を選択します。
検索ボックスに、テーブルを含むデータセットの名前を入力します。
たとえば、Data Catalog を使用して BigQuery テーブルにタグ付けするクイックスタートを完了した場合は、
demo-datasetを検索してtripsテーブルを選択できます。テーブルをクリックします。
BigQuery テーブルの詳細ページが開きます。
テーブルの詳細には次のセクションがあります。
BigQuery テーブルの詳細。作成日時、最終更新日時、有効期限、リソースの URL、ラベルなどの情報が含まれます。
タグ。適用されたタグを一覧表示します。このページからタグを編集したり、タグ テンプレートを表示したりできます。 [アクション] アイコンをクリックします。
スキーマと列のタグ。適用されたスキーマとその値を一覧表示します。
お気に入りのエントリにスターを付け、検索します
同じデータアセットを頻繁に閲覧する場合は、スターを使用してマークを付けて、パーソナライズされたリストにエントリを追加できます。
Google Cloud コンソールで、Dataplex の [検索] ページに移動します。
[検索プラットフォームを選択] で、検索モードとして [Data Catalog] を選択します。
アセットを見つけて、次の 2 つの方法のいずれかでエントリにスターを付けます。
- 検索結果のエントリの横にある をクリックします。
- エントリ名をクリックして詳細ページを開き、上部のアクションバーにある スターをクリックします。
スターを付けることができるエントリは 200 個までです。
スター付きのエントリは、検索バーに検索クエリを入力する前に、検索ページの [スター付きエントリ] リストに表示されます。このリストは、本人だけに表示されます。
スター付きエントリのみを検索するには、[フィルタ] ペインの [スコープ] セクションで [スター付き] を選択します。
Data Catalog API の対応するメソッドを使用して、エントリにスターを付けたり、外したりすることもできます。アセットを検索する場合は、scope オブジェクトの starredOnly パラメータを使用します。詳細については、catalog.search メソッドをご覧ください。
次のステップ
Data Catalog の検索構文を把握する。
Dataplex Catalog でリソースを検索する方法を確認する。