SAP との統合
このページでは、Cortex Framework Data Foundation で SAP オペレーショナル ワークロード(SAP ECC と SAP S/4 HANA)を統合する手順について説明します。Cortex Framework は、Dataflow パイプラインを使用して SAP データを BigQuery に統合する処理を高速化します。一方、Cloud Composer は、SAP の運用データから分析情報を取得するために、これらの Dataflow パイプラインをスケジュールしてモニタリングします。
Cortex Framework Data Foundation リポジトリの config.json ファイルは、SAP を含む任意のデータソースからデータを転送するために必要な設定を構成します。このファイルには、運用 SAP ワークロードの次のパラメータが含まれています。
"SAP": {
"deployCDC": true,
"datasets": {
"cdc": "",
"raw": "",
"reporting": "REPORTING"
},
"SQLFlavor": "ecc",
"mandt": "100"
}
次の表に、各 SAP 運用パラメータの値を示します。
| パラメータ | 意味 | デフォルト値 | 説明 |
SAP.deployCDC
|
CDC をデプロイする | true
|
Cloud Composer で DAG として実行する CDC 処理スクリプトを生成します。 |
SAP.datasets.raw
|
未加工のランディング データセット | - | CDC プロセスで使用されます。レプリケーション ツールが SAP からデータを取得する場所です。テストデータを使用する場合は、空のデータセットを作成します。 |
SAP.datasets.cdc
|
CDC 処理済みデータセット | - | レポートビューのソースとして機能し、処理された DAG のレコードのターゲットとなるデータセット。テストデータを使用する場合は、空のデータセットを作成します。 |
SAP.datasets.reporting
|
レポート用データセット SAP | "REPORTING"
|
レポート用にエンドユーザーがアクセスできるデータセットの名前。ビューとユーザー向けテーブルがデプロイされます。 |
SAP.SQLFlavor
|
移行元システムの SQL フレーバー | "ecc"
|
s4 または ecc。テストデータの場合は、デフォルト値(ecc)のままにします。 |
SAP.mandt
|
Mandant or Client | "100"
|
SAP のデフォルトの mandant またはクライアント。テストデータの場合は、デフォルト値(100)のままにします。 |
SAP.languages
|
言語フィルタ | ["E","S"]
|
関連するフィールド(名前など)に使用する SAP 言語コード(SPRAS)。 |
SAP.currencies
|
通貨フィルタ | ["USD"]
|
通貨換算用の SAP の目標通貨コード(TCURR)。 |
必要な SAP の最小バージョンはありませんが、ECC モデルは、現在サポートされている最も古いバージョンの SAP ECC で開発されています。バージョンに関係なく、Google のシステムと他のシステムの間でフィールドに違いが生じることは想定されています。
データモデル
このセクションでは、エンティティ関連図(ERD)を使用して SAP(ECC および S/4 HANA)データモデルについて説明します。
SAP ECC

SAP S/4 HANA
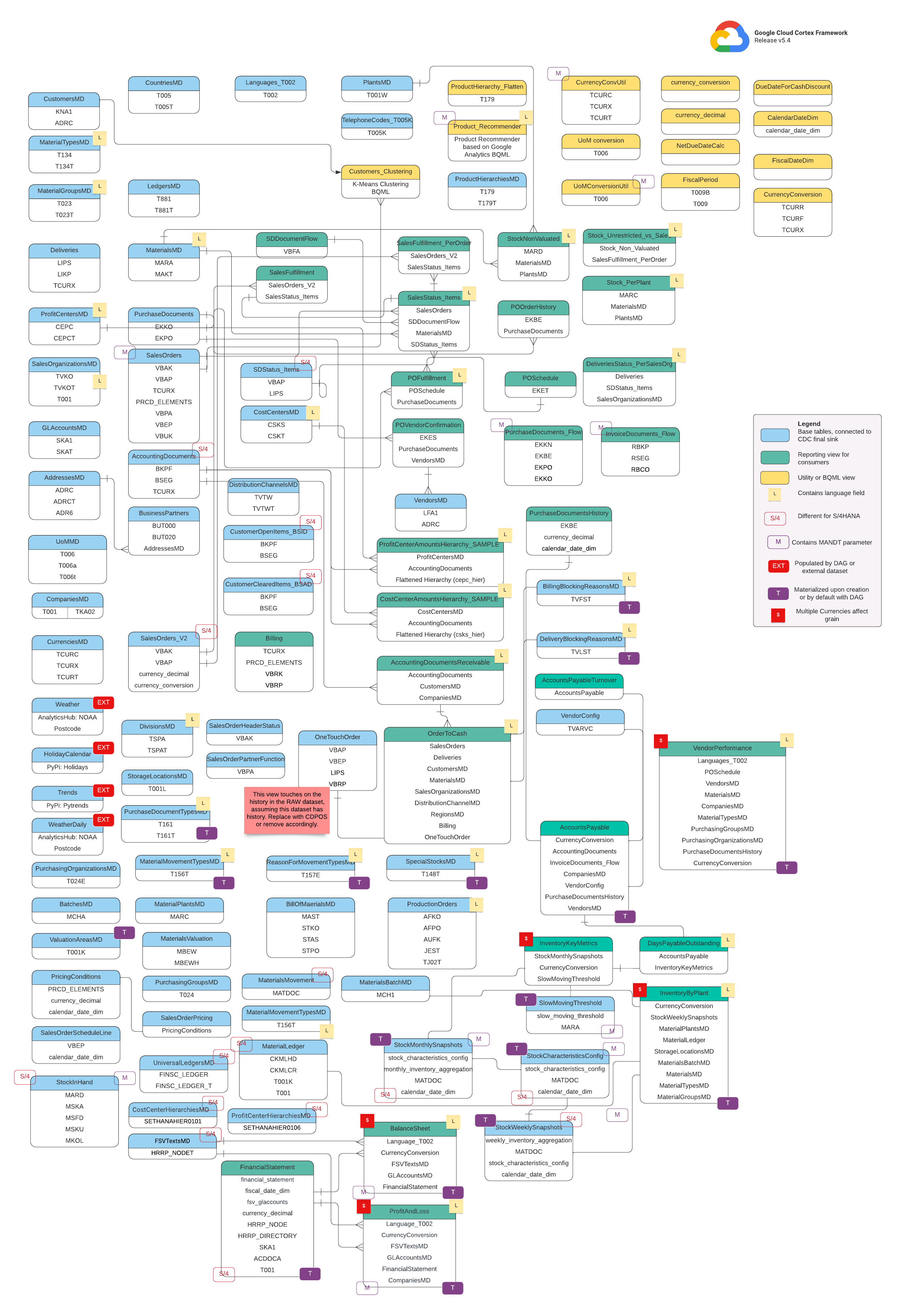
ベースビュー
これらは ERD の青いオブジェクトであり、一部の列名エイリアス以外の変換がない CDC テーブルのビューです。src/SAP/SAP_REPORTING のスクリプトをご覧ください。
レポートビュー
これらは ERD の緑色のオブジェクトで、レポート テーブルで使用される関連するディメンション属性が含まれています。src/SAP/SAP_REPORTING のスクリプトをご覧ください。
ユーティリティ ビューまたは BQML ビュー
これらは ERD の黄色のオブジェクトであり、データ分析とレポート作成に使用される特定のタイプのビューの結合されたファクトとディメンションが含まれています。src/SAP/SAP_REPORTING のスクリプトをご覧ください。
追加のタグ
この ERD の色分けされたタグは、レポート テーブルの次の機能を表しています。
| タグ | 色 | 説明 |
L
|
黄色 | このタグは、データの保存または表示に使用される言語を指定するデータ要素または属性を指します。 |
S/4
|
赤 | このタグは、特定の属性が SAP S/4 HANA に固有であることを示します(このオブジェクトは SAP ECC に存在しない可能性があります)。 |
MANDT
|
紫 | このタグは、特定の属性に MANDT パラメータ(クライアントまたはクライアント ID を表す)が含まれており、特定のデータレコードがどのクライアントまたは会社インスタンスに属するかを判断することを示します。 |
EXT
|
赤 | このタグは、特定のオブジェクトが DAG または外部データセットによって入力されることを示します。これは、マークされたエンティティまたはテーブルが SAP システム自体に直接保存されていないことを意味します。ただし、DAG などのメカニズムを使用して、抽出して SAP に読み込むことはできます。 |
T
|
紫 | このタグは、構成された DAG を使用して特定の属性が自動的にマテリアライズされることを示します。 |
S
|
赤 | このタグは、エンティティまたはテーブル内のデータが複数の通貨の影響を受けていることを示します。 |
SAP レプリケーションの前提条件
Cortex Framework Data Foundation を使用した SAP レプリケーション データの前提条件は次のとおりです。
- データの完全性: Cortex Framework Data Foundation では、SAP テーブルが SAP に存在するのと同じフィールド名、型、データ構造で複製されることが想定されています。テーブルがソースと同じ形式、フィールド名、粒度で複製される限り、特定の複製ツールを使用する必要はありません。
- テーブルの命名: BigQuery テーブル名は小文字で作成する必要があります。
- テーブル構成: SAP モデルで使用されるテーブルのリストは、CDC(変更データ キャプチャ)の
cdc_settings.yamlファイルで確認および構成できます。デプロイ中にテーブルがリストに表示されない場合、そのテーブルに依存するモデルは失敗しますが、依存しない他のモデルは正常にデプロイされます。 - BigQuery Connector for SAP に関する具体的な考慮事項:
- テーブル マッピング: 変換オプションについては、デフォルトのテーブル マッピングのドキュメントをご覧ください。
- レコード圧縮の無効化: Cortex CDC レイヤと Cortex レポート データセットの両方に影響する可能性があるため、レコード圧縮を無効にすることをおすすめします。
- メタデータのレプリケーション: テストデータをデプロイせず、デプロイ中に CDC DAG スクリプトを生成しない場合は、ソース プロジェクトの SAP から SAP メタデータのテーブル
DD03Lがレプリケートされていることを確認します。このテーブルには、キーのリストなどのテーブルに関するメタデータが含まれており、CDC ジェネレータと依存関係リゾルバが機能するために必要です。このテーブルでは、モデルでカバーされていないテーブル(カスタム テーブルや Z テーブルなど)を追加して、CDC スクリプトを生成することもできます。 テーブル名のわずかな違いの処理: テーブル名にわずかな違いがある場合、SAP システムのバージョンやアドオンによってわずかな違いが生じているか、一部のレプリケーション ツールで特殊文字の処理がわずかに異なるため、一部のビューで必要なフィールドが見つからず、失敗することがあります。
turboMode : falseを使用してデプロイを実行し、1 回の試行で最も多くの障害を特定することをおすすめします。一般的な問題の例を次に示します。_で始まるフィールド(_DATAAGINGなど)から_が削除されます。- BigQuery では、フィールドを
/で始めることはできません。
この場合、選択したレプリケーション ツールでフィールドが着地したときに、そのフィールドを選択するように失敗したビューを調整できます。
SAP からの元データの複製
データ基盤の目的は、レポートとアプリケーション用にデータと分析モデルを公開することです。モデルは、SAP 向けデータ統合ガイドに記載されているような、優先するレプリケーション ツールを使用して SAP システムから複製されたデータを使用します。
SAP システム(ECC または S/4 HANA)のデータは、未加工の形式で複製されます。データは、構造を変更せずに SAP から BigQuery に直接コピーされます。基本的には、SAP システムのテーブルのミラーイメージです。BigQuery は、データモデルに小文字のテーブル名を使用します。そのため、SAP テーブルの名前が大文字(MANDT など)であっても、BigQuery では小文字(mandt など)に変換されます。
変更データ キャプチャ(CDC)の処理
Cortex Framework がレプリケーション ツールに提供する次のいずれかの CDC 処理モードを選択して、SAP からレコードを読み込みます。
- Append-always: タイムスタンプとオペレーション フラグ(挿入、更新、削除)を使用して、レコードのすべての変更を挿入します。これにより、最新バージョンを特定できます。
- 着地時に更新(マージまたは upsert):
change data capture processedで着地時にレコードの更新バージョンを作成します。BigQuery で CDC オペレーションを実行します。
Cortex Framework Data Foundation は両方のモードをサポートしていますが、追加専用モードの場合は CDC 処理テンプレートを提供します。ランディングでの更新のために、一部の機能はコメントアウトする必要があります。たとえば、OneTouchOrder.sql とその依存クエリすべて。この機能は、CDPOS などのテーブルに置き換えることができます。

追加専用モードで複製するツールの CDC テンプレートを構成する
ニーズに合わせて cdc_settings.yaml を構成することを強くおすすめします。ビジネスでそのレベルのデータ更新頻度が必要ない場合、デフォルトの頻度によっては不要な費用が発生する可能性があります。追加専用モードで実行されるツールを使用している場合、Cortex Framework Data Foundation は CDC テンプレートを提供して、更新を自動化し、CDC 処理済みデータセットに最新バージョンの信頼できる情報またはデジタル ツインを作成します。
CDC 処理スクリプトを生成する必要がある場合は、ファイル cdc_settings.yaml の構成を使用できます。オプションについては、CDC 処理を設定するをご覧ください。テストデータの場合、このファイルはデフォルトのままにできます。
Airflow または Cloud Composer のインスタンスに応じて、DAG テンプレートに必要な変更を加えます。詳細については、Cloud Composer の設定の収集をご覧ください。
省略可: デプロイ後にテーブルを個別に追加して処理する場合は、cdc_settings.yaml ファイルを変更して、必要なテーブルのみを処理し、src/SAP_CDC/cloudbuild.cdc.yaml を直接呼び出す指定されたモジュールを再実行します。
CDC 処理を設定する
デプロイ時に、BigQuery のビューを使用するか、Cloud Composer(または Apache Airflow の他のインスタンス)でマージ オペレーションをスケジュールして、変更をリアルタイムでマージできます。Cloud Composer は、マージ オペレーションを定期的に処理するスクリプトをスケジュールできます。データは、マージ オペレーションが実行されるたびに最新バージョンに更新されますが、マージ オペレーションの頻度が高いほど、コストが高くなります。ビジネスニーズに合わせてスケジュールされた頻度をカスタマイズします。詳細については、Apache Airflow でサポートされているスケジューリングをご覧ください。
次のスクリプトの例は、構成ファイルからの抽出を示しています。
data_to_replicate:
- base_table: adrc
load_frequency: "@hourly"
- base_table: adr6
target_table: adr6_cdc
load_frequency: "@daily"
この構成サンプル ファイルでは、次の処理が行われます。
TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrcが存在しない場合は、SOURCE_PROJECT_ID.REPLICATED_DATASET.adrcからTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adrcにコピーを作成します。- 指定されたバケットに CDC スクリプトを作成します。
TARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdcが存在しない場合は、SOURCE_PROJECT_ID.REPLICATED_DATASET.adr6からTARGET_PROJECT_ID.DATASET_WITH_LATEST_RECORDS.adr6_cdcにコピーを作成します。- 指定されたバケットに CDC スクリプトを作成します。
SAP に存在し、ファイルにリストされていないテーブルの変更を処理する DAG またはランタイム ビューを作成する場合は、デプロイ前にこのファイルに追加します。これは、テーブル DD03L がソース データセットに複製され、カスタム テーブルのスキーマがそのテーブルに存在する場合に機能します。たとえば、次の構成では、カスタム テーブル zztable_customer の CDC スクリプトと、zzspecial_table という別のカスタム テーブルの変更をリアルタイムでスキャンするランタイム ビューが作成されます。
- base_table: zztable_customer
load_frequency: "@daily"
- base_table: zzspecial_table
load_frequency: "RUNTIME"
生成されたテンプレートのサンプル
次のテンプレートは、変更の処理を生成します。この時点で、タイムスタンプ フィールドの名前や追加のオペレーションなどの変更を行うことができます。
MERGE `${target_table}` T
USING (
SELECT *
FROM `${base_table}`
WHERE
recordstamp > (
SELECT IF(
MAX(recordstamp) IS NOT NULL,
MAX(recordstamp),
TIMESTAMP("1940-12-25 05:30:00+00"))
FROM `${target_table}` )
) S
ON ${p_key}
WHEN MATCHED AND S.operation_flag='D' AND S.is_deleted = true THEN
DELETE
WHEN NOT MATCHED AND S.operation_flag='I' THEN
INSERT (${fields})
VALUES
(${fields})
WHEN MATCHED AND S.operation_flag='U' THEN
UPDATE SET
${update_fields}
また、ビジネスでほぼリアルタイムの分析情報が必要で、レプリケーション ツールがそれをサポートしている場合、デプロイ ツールはオプション RUNTIME を受け入れます。つまり、CDC スクリプトは生成されません。代わりに、ビューは実行時にスキャンして、即時整合性のために利用可能な最新のレコードを取得します。
CDC DAG とスクリプトのディレクトリ構造
SAP CDC DAG の Cloud Storage バケット構造では、次の例のように、SQL ファイルが /data/bq_data_replication で生成されることを想定しています。このパスはデプロイ前に変更できます。Cloud Composer の環境がまだない場合は、後で作成して、ファイルを DAG バケットに移動できます。
with airflow.DAG("CDC_BigQuery_${base table}",
template_searchpath=['/home/airflow/gcs/data/bq_data_replication/'], ##example
default_args=default_dag_args,
schedule_interval="${load_frequency}") as dag:
start_task = DummyOperator(task_id="start")
copy_records = BigQueryOperator(
task_id='merge_query_records',
sql="${query_file}",
create_disposition='CREATE_IF_NEEDED',
bigquery_conn_id="sap_cdc_bq", ## example
use_legacy_sql=False)
stop_task = DummyOperator (task_id="stop")
start_task >> copy_records >> stop_task
Airflow または Cloud Composer でデータを処理するスクリプトは、Airflow 固有のスクリプトとは別に生成されます。これにより、これらのスクリプトを別のツールに移植できます。
MERGE オペレーションに必要な CDC フィールド
CDC バッチ処理の自動生成用に次のパラメータを指定します。
- ソース プロジェクトとデータセット: SAP データがストリーミングまたは複製されるデータセット。CDC スクリプトがデフォルトで動作するには、テーブルにタイムスタンプ フィールド(recordstamp)と、次の値を持つオペレーション フィールドが必要です。これらはすべてレプリケーション中に設定されます。
- I: 挿入。
- U: 更新。
- D: 削除。
- CDC 処理のターゲット プロジェクトとデータセット: デフォルトで生成されるスクリプトは、テーブルが存在しない場合、コピー元データセットのコピーからテーブルを生成します。
- 複製されたテーブル: スクリプトを生成する必要があるテーブル
- 処理頻度: Cron 表記に従って、DAG の実行頻度を指定します。
- CDC 出力ファイルがコピーされるターゲット Cloud Storage バケット。
- 接続の名前: Cloud Composer で使用される接続の名前。
- (省略可)ターゲット テーブルの名前: CDC 処理の結果がターゲットと同じデータセットに残っている場合に使用できます。
CDC テーブルのパフォーマンスの最適化
特定の CDC データセットでは、BigQuery のテーブル パーティショニング、テーブル クラスタリング、またはその両方を活用することが望ましい場合があります。この選択は、次の要因によって異なります。
- テーブルのサイズとデータ。
- テーブルで使用できる列。
- ビューを含むリアルタイム データが必要。
- テーブルとして実体化されたデータ。
デフォルトでは、CDC 設定はテーブルのパーティショニングやテーブルのクラスタリングを適用しません。最適な方法で構成してください。パーティションまたはクラスタを含むテーブルを作成するには、関連する構成で cdc_settings.yaml ファイルを更新します。詳細については、テーブル パーティションとクラスタ設定をご覧ください。
- この機能は、
cdc_settings.yamlのデータセットがテーブルとしてレプリケーション用に構成されている場合(load_frequency = "@daily"など)にのみ適用され、ビュー(load_frequency = "RUNTIME")として定義されている場合は適用されません。 - テーブルは、パーティション分割テーブルとクラスタ化テーブルの両方にできます。
BigQuery Connector for SAP など、未加工データセットのパーティションを許可するレプリケーション ツールを使用している場合は、未加工テーブルに時間ベースのパーティションを設定することをおすすめします。パーティションのタイプは、cdc_settings.yaml 構成の CDC DAG の頻度と一致している場合に効果的です。詳細については、BigQuery における SAP データ モデリングの設計上の考慮事項をご覧ください。
省略可: SAP 在庫モジュールを構成する
Cortex Framework SAP Inventory モジュールには、在庫に関する重要な分析情報を提供する InventoryKeyMetrics ビューと InventoryByPlant ビューが含まれています。これらのビューは、専用の DAG を使用して月次と週次のスナップショット テーブルによってバックアップされます。両方を同時に実行でき、互いに干渉することはありません。
スナップショット テーブルのいずれかまたは両方を更新する手順は次のとおりです。
要件に基づいて
SlowMovingThreshold.sqlとStockCharacteristicsConfig.sqlを更新し、さまざまな品目タイプに対して、低速移動のしきい値と在庫特性を定義します。初期読み込みまたは完全更新の場合は、
Stock_Monthly_Snapshots_InitialDAG とStock_Weekly_Snapshots_InitialDAG を実行します。以降の更新では、次の DAG をスケジュールするか、実行します。
- 月次および週次の更新:
Stock_Monthly_Snapshots_Periodical_UpdateStock_Weekly_Snapshots_periodical_Update
- 毎日の更新:
Stock_Monthly_Snapshots_Daily_UpdateStock_Weekly_Snapshots_Update_Daily
- 月次および週次の更新:
中間
StockMonthlySnapshotsビューとStockWeeklySnapshotsビューを更新し、続いてInventoryKeyMetricsビューとInventoryByPlantsビューを更新して、更新されたデータを公開します。
省略可: Product Hierarchy Texts ビューを構成する
[Product Hierarchy Texts] ビューでは、マテリアルとその商品階層が平坦化されます。結果のテーブルを使用して、Trends アドオンに用語のリストを渡し、インタレストの推移を取得できます。次の手順でこのビューを構成します。
## CORTEX-CUSTOMERのマーカーの下にあるprod_hierarchy_texts.sqlファイルで、階層のレベルと言語を調整します。商品階層に複数のレベルが含まれている場合は、共通テーブル式
h1_h2_h3と同様の SELECT ステートメントを追加する必要がある場合があります。ソースシステムによっては、追加のカスタマイズが必要になる場合があります。ビジネス ユーザーやアナリストをプロセスの早い段階から参加させることで、このような問題を特定しやすくなります。
省略可: 階層のフラット化ビューを構成する
リリース v6.0 以降、Cortex Framework はレポートビューとして階層の平坦化をサポートしています。これは、以前の階層フラット化ツールからの大幅な改善です。階層全体がフラット化され、以前の ECC テーブルではなく S/4 固有のテーブルを利用することで S/4 向けに最適化され、パフォーマンスも大幅に向上します。
レポートビューの概要
階層のフラット化に関連する次のビューを見つけます。
| 階層のタイプ | 階層をフラット化したテーブルのみ | フラット化された階層を可視化するビュー | この階層を使用する損益計算書の統合ロジック |
| 財務諸表バージョン(FSV) | fsv_glaccounts
|
FSVHierarchyFlattened
|
ProfitAndLossOverview
|
| プロフィット センター | profit_centers
|
ProfitCenterHierarchyFlattened
|
ProfitAndLossOverview_ProfitCenterHierarchy
|
| コストセンター | cost_centers
|
CostCenterHierarchyFlattened
|
ProfitAndLossOverview_CostCenterHierarchy
|
階層の平坦化ビューを使用する場合は、次の点を考慮してください。
- 階層をフラット化したビューのみは、以前の階層フラット化ソリューションによって生成されたテーブルと機能的に同等です。
- 概要ビューは、BI ロジックのみを示すことを目的としているため、デフォルトではデプロイされません。ソースコードは
src/SAP/SAP_REPORTINGディレクトリにあります。
階層のフラット化を構成する
操作する階層に応じて、次の入力パラメータが必要です。
| 階層のタイプ | 必須パラメータ | Source field(ECC) | Source field(S4) |
| 財務諸表バージョン(FSV) | 勘定科目 | ktopl
|
nodecls
|
| 階層名 | versn
|
hryid
|
|
| プロフィット センター | セットのクラス | setclass
|
setclass
|
| 組織部門: セットの制御領域または追加のキー。 | subclass
|
subclass
|
|
| コストセンター | セットのクラス | setclass
|
setclass
|
| 組織部門: セットの制御領域または追加のキー。 | subclass
|
subclass
|
正確なパラメータがわからない場合は、財務または管理の SAP コンサルタントにお問い合わせください。
パラメータが収集されたら、要件に基づいて、対応する各ディレクトリ内の ## CORTEX-CUSTOMER コメントを更新します。
| 階層のタイプ | コードの場所 |
| 財務諸表バージョン(FSV) | src/SAP/SAP_REPORTING/local_k9/fsv_hierarchy
|
| プロフィット センター | src/SAP/SAP_REPORTING/local_k9/profitcenter_hierarchy
|
| コストセンター | src/SAP/SAP_REPORTING/local_k9/costcenter_hierarchy
|
該当する場合は、src/SAP/SAP_REPORTING ディレクトリの関連するレポートビュー内の ## CORTEX-CUSTOMER コメントを適切に更新してください。
ソリューションの詳細
階層の平坦化には、次のソーステーブルが使用されます。
| 階層のタイプ | ソーステーブル(ECC) | ソーステーブル(S4) |
| 財務諸表バージョン(FSV) |
|
|
| プロフィット センター |
|
|
| コストセンター |
|
|
階層を可視化する
Cortex の SAP 階層フラット化ソリューションは、階層全体をフラット化します。SAP が UI に表示する内容に匹敵する、読み込まれた階層の視覚的な表現を作成する場合は、IsLeafNode=True 条件を使用して、フラット化された階層を視覚化するためのビューのいずれかをクエリします。
以前の階層フラット化ソリューションからの移行
Cortex v6.0 より前の従来の階層の平坦化ソリューションから移行するには、次の表に示すようにテーブルを置き換えます。フィールド名が若干変更されているため、フィールド名が正確であることを確認してください。たとえば、cepc_hier の prctr は、profit_centers テーブルの profitcenter になりました。
| 階層のタイプ | この表を置き換えます。 | With: |
| 財務諸表バージョン(FSV) | ska1_hier
|
fsv_glaccounts
|
| プロフィット センター | cepc_hier
|
profit_centers
|
| コストセンター | csks_hier
|
cost_centers
|
省略可: SAP Finance Module を構成する
Cortex Framework SAP Finance モジュールには、主要な財務分析情報を提供する FinancialStatement、BalanceSheet、ProfitAndLoss ビューが含まれています。
これらの財務テーブルを更新する手順は次のとおりです。
初期読み込みの場合
- デプロイ後、CDC データセットが正しく入力されていることを確認します(必要に応じて CDC DAG を実行します)。
- 使用している階層のタイプ(FSV、コストセンター、利益センター)に対して、階層のフラット化ビューが正しく構成されていることを確認します。
financial_statement_initial_loadDAG を実行します。テーブルとしてデプロイされている場合(推奨)、対応する DAG を実行して、次の順序で更新します。
Financial_StatementsBalanceSheetsProfitAndLoss
定期的な更新の場合
- 使用している階層のタイプ(FSV、コストセンター、利益センター)に対して、階層のフラット化ビューが正しく構成され、最新の状態に更新されていることを確認します。
financial_statement_periodical_loadDAG をスケジュール設定または実行します。テーブルとしてデプロイされている場合(推奨)、対応する DAG を実行して、次の順序で更新します。
Financial_StatementsBalanceSheetsProfitAndLoss
これらのテーブルのデータを可視化するには、次の概要ビューをご覧ください。
- FSV 階層を使用している場合は
ProfitAndLossOverview.sql。 ProfitAndLossOverview_CostCenter.sql(費用センター階層を使用している場合)。- 収益センター階層を使用している場合は
ProfitAndLossOverview_ProfitCenter.sql。
省略可: タスク依存 DAG を有効にする
Cortex Framework は、ほとんどの SAP SQL テーブル(ECC と S/4 HANA)に推奨される依存関係設定をオプションで提供します。この設定では、すべての依存テーブルを 1 つの DAG で更新できます。さらにカスタマイズすることもできます。詳細については、タスク依存 DAG をご覧ください。
次のステップ
- 他のデータソースとワークロードの詳細については、データソースとワークロードをご覧ください。
- 本番環境でのデプロイの手順の詳細については、Cortex Framework Data Foundation のデプロイの前提条件をご覧ください。