このチュートリアルでは、障害復旧(DR)ソリューションとして 2 つの Google Cloud リージョンに Hyperdisk Balanced 非同期レプリケーションを有効にする方法と、障害発生時に DR インスタンスを起動する方法について説明します。
Microsoft SQL Server のフェイルオーバー クラスタ インスタンス(FCI)は、複数の高可用性 Windows Server フェイルオーバー クラスタ(WSFC)ノードにデプロイされる単一の SQL Server インスタンスです。どの時点においても、いずれかのクラスタノードが、SQL インスタンスをアクティブにホストします。ゾーンの停止や VM の問題が発生した場合、WSFC はインスタンス リソースの所有権をクラスタ内の別のノードに自動的に移し、クライアントが再接続できるようにします。SQL Server FCI では、すべての WSFC ノードからアクセスできるように、データを共有ディスクに配置する必要があります。
SQL Server のデプロイがリージョンの停止に耐えられるようにするには、非同期レプリケーションを有効にして、プライマリ リージョンのディスクデータをセカンダリ リージョンに複製します。このチュートリアルでは、Hyperdisk Balanced High Availability マルチライター ディスクを使用して、SQL Server FCI の障害復旧(DR)ソリューションとして 2 つの Google Cloud リージョン間で非同期レプリケーションを有効にする方法と、障害発生時に DR インスタンスを起動する方法について説明します。このドキュメントでは、障害とは、クラスタのリージョンが使用できなくなる(おそらく自然災害が原因)ことにより、プライマリ データベース クラスタで障害が発生するか、使用できなくなるイベントを意味します。
このチュートリアルは、データベース アーキテクト、管理者、エンジニアを対象としています。
目標
- Google Cloudで実行されているすべての SQL Server FCI クラスタノードで、Hyperdisk 非同期レプリケーションを有効にします。
- 障害イベントをシミュレートし、完全な DR プロセスを実行して DR 構成を検証します。
費用
このドキュメントでは、課金対象である次の Google Cloudコンポーネントを使用します。
料金計算ツールを使うと、予想使用量に基づいて費用の見積もりを生成できます。
このドキュメントに記載されているタスクの完了後、作成したリソースを削除すると、それ以上の請求は発生しません。詳細については、クリーンアップをご覧ください。
始める前に
このチュートリアルでは Google Cloud プロジェクトが必要です。新しいプロジェクトを作成することも、すでに作成済みのプロジェクトを選択することもできます。
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
Roles required to select or create a project
- Select a project: Selecting a project doesn't require a specific IAM role—you can select any project that you've been granted a role on.
-
Create a project: To create a project, you need the Project Creator
(
roles/resourcemanager.projectCreator), which contains theresourcemanager.projects.createpermission. Learn how to grant roles.
-
Verify that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, activate Cloud Shell.
この Hyperdisk Balanced High Availability マルチライター モードで SQL Server FCI クラスタを構成するガイドの手順に沿って、プライマリ リージョンに SQL Server クラスタを設定します。クラスタを設定したら、このチュートリアルに戻ってセカンダリ リージョンで DR を有効にします。
バックアップと復元を実行するための Google Cloud プロジェクトと SQL Server の両方の適切な権限。
- Microsoft SQL Server の 2 つのインスタンス(プライマリ インスタンスとスタンバイ インスタンス)は FCI クラスタの一部であり、プライマリ リージョン(R1)にありますが、ゾーンは異なります(ゾーン A とゾーン B)。両方のインスタンスが Hyperdisk Balanced High Availability ディスクを共有しているため、両方の VM からデータにアクセスできます。手順については、Hyperdisk Balanced High Availability マルチライター モードで SQL Server FCI クラスタを構成するをご覧ください。
- 両方の SQL ノードのディスクが整合性グループに追加され、DR リージョン R2 に複製されます。Compute Engine は、R1 から R2 にデータを非同期的に複製します。
- 非同期レプリケーションでは、ディスク上のデータのみが R2 にレプリケートされ、VM メタデータはレプリケートされません。DR 中に新しい VM が作成され、既存のレプリケートされたディスクが VM にアタッチされて、ノードがオンラインになります。
- プライマリ データベース インスタンスを実行している最初のリージョン(R1)が使用できなくなります。
- オペレーション チームが障害を認識して正式に応答し、フェイルオーバーが必要かどうかを判断します。
- フェイルオーバーが必要な場合は、プライマリ ディスクとセカンダリ ディスク間のレプリケーションを終了する必要があります。ディスク レプリカから新しい VM が作成され、オンラインになります。
- DR リージョンである R2 のデータベースが検証され、オンラインに移行されます。R2 のデータベースが新しいプライマリ データベースになり、接続が可能になります。
- ユーザーは、新しいプライマリ データベースで処理を再開し、R2 のプライマリ インスタンスにアクセスします。
- SQL Server 2016 Enterprise および Standard Edition
- SQL Server 2017 Enterprise および Standard Edition
- SQL Server 2019 Enterprise および Standard エディション
- SQL Server 2022 Enterprise Edition と Standard Edition
SQL Server ノードと、監視ロールとドメイン コントローラ ロールをホストするノードの両方の整合性グループを作成します。整合性グループの制限事項の一つは、ゾーンをまたいで配置できないことです。そのため、各ノードを個別の整合性グループに追加する必要があります。
gcloud compute resource-policies create disk-consistency-group node-1-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group node-2-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group witness-disk-const-grp \ --region=$REGION gcloud compute resource-policies create disk-consistency-group multiwriter-disk-const-grp \ --region=$REGION
プライマリ VM とスタンバイ VM のディスクを、対応する整合性グループに追加します。
gcloud compute disks add-resource-policies node-1 \ --zone=$REGION-a \ --resource-policies=node-1-disk-const-grp gcloud compute disks add-resource-policies node-2 \ --zone=$REGION-b \ --resource-policies=node-2-disk-const-grp gcloud compute disks add-resource-policies mw-datadisk-1 \ --region=$REGION \ --resource-policies=multiwriter-disk-const-grp gcloud compute disks add-resource-policies witness \ --zone=$REGION-c \ --resource-policies=witness-disk-const-grp
セカンダリ リージョンに空のセカンダリ ディスクを作成します。
DR_REGION="us-west1" gcloud compute disks create node-1-replica \ --zone=$DR_REGION-a \ --size=50 \ --primary-disk=node-1 \ --primary-disk-zone=$REGION-a gcloud compute disks create node-2-replica \ --zone=$DR_REGION-b \ --size=50 \ --primary-disk=node-2 \ --primary-disk-zone=$REGION-b gcloud compute disks create multiwriter-datadisk-1-replica \ --replica-zones=$DR_REGION-a,$DR_REGION-b \ --size=$PD_SIZE \ --type=hyperdisk-balanced-high-availability \ --access-mode READ_WRITE_MANY \ --primary-disk=multiwriter-datadisk-1 \ --primary-disk-region=$REGION gcloud compute disks create witness-replica \ --zone=$DR_REGION-c \ --size=50 \ --primary-disk=witness \ --primary-disk-zone=$REGION-c
ディスク レプリケーションを開始します。データは、プライマリ ディスクから DR リージョンに新しく作成された空のディスクに複製されます。
gcloud compute disks start-async-replication node-1 \ --zone=$REGION-a \ --secondary-disk=node-1-replica \ --secondary-disk-zone=$DR_REGION-a gcloud compute disks start-async-replication node-2 \ --zone=$REGION-b \ --secondary-disk=node-2-replica \ --secondary-disk-zone=$DR_REGION-b gcloud compute disks start-async-replication multiwriter-datadisk-1 \ --region=$REGION \ --secondary-disk=multiwriter-datadisk-1-replica \ --secondary-disk-region=$DR_REGION gcloud compute disks start-async-replication witness \ --zone=$REGION-c \ --secondary-disk=witness-replica \ --secondary-disk-zone=$DR_REGION-c
復元用 VPC を作成します。
DRVPC_NAME="default-dr" DRSUBNET_NAME="default-recovery" gcloud compute networks create $DRVPC_NAME \ --subnet-mode=custom CIDR=$(gcloud compute networks subnets describe default \ --region=$REGION --format=value\(ipCidrRange\)) gcloud compute networks subnets create $DRSUBNET_NAME \ --network=$DRVPC_NAME --range=$CIDR --region=$DR_REGION
データ レプリケーションを終了または停止します。
PROJECT=$(gcloud config get-value project) gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-1-disk-const-grp \ --zone=$REGION-a gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/node-2-disk-const-grp \ --zone=$REGION-b gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/multiwriter-disk-const-grp \ --zone=$REGION-c gcloud compute disks stop-group-async-replication projects/$PROJECT/regions/$REGION/resourcePolicies/witness-disk-const-grp \ --zone=$REGION-c
プライマリ リージョンのソース VM を停止します。
gcloud compute instances stop node-1 \ --zone=$REGION-a gcloud compute instances stop node-2 \ --zone=$REGION-b gcloud compute instances stop witness \ --zone=$REGION-c
プロジェクト内で名前が重複しないように、既存の VM の名前を変更します。
gcloud compute instances set-name witness \ --new-name=witness-old \ --zone=$REGION-c gcloud compute instances set-name node-1 \ --new-name=node-1-old \ --zone=$REGION-a gcloud compute instances set-name node-2 \ --new-name=node-2-old \ --zone=$REGION-b
セカンダリ ディスクを使用して DR リージョンに VM を作成します。これらの VM には、移行元 VM の IP アドレスが割り当てられます。
NODE1IP=$(gcloud compute instances describe node-1-old --zone $REGION-a --format=value\(networkInterfaces[0].networkIP\)) NODE2IP=$(gcloud compute instances describe node-2-old --zone $REGION-b --format=value\(networkInterfaces[0].networkIP\)) WITNESSIP=$(gcloud compute instances describe witness-old --zone $REGION-c --format=value\(networkInterfaces[0].networkIP\)) gcloud compute instances create node-1 \ --zone=$DR_REGION-a \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE1IP\ --disk=boot=yes,device-name=node-1-replica,mode=rw,name=node-1-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional gcloud compute instances create witness \ --zone=$DR_REGION-c \ --machine-type=n2-standard-2 \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $WITNESSIP \ --disk=boot=yes,device-name=witness-replica,mode=rw,name=witness-replica gcloud compute instances create node-2 \ --zone=$DR_REGION-b \ --machine-type $MACHINE_TYPE \ --network=$DRVPC_NAME \ --subnet=$DRSUBNET_NAME \ --private-network-ip $NODE2IP\ --disk=boot=yes,device-name=node-2-replica,mode=rw,name=node-2-replica \ --disk=boot=no,device-name=mw-datadisk-1-replica,mode=rw,name=mw-datadisk-1-replica,scope=regional
- リモート デスクトップを使用して SQL Server VM に接続します。
- SQL Server Management Studio を開きます。
- [サーバーに接続] ダイアログで、サーバー名が
node-1に設定されていることを確認し、[接続] を選択します。 ファイル メニューで、現在の接続で [File] > [New] > [Query] を選択します。
USE [bookshelf]; SELECT * FROM Books;
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。
Google Cloudでの障害復旧
Google Cloud の DR は、リージョンで障害が発生した場合やアクセスできなくなった場合に、データへの継続的なアクセスを維持します。DR サイトには複数のデプロイ オプションがあり、目標復旧時点(RPO)と目標復旧時間(RTO)の要件によって決まります。このチュートリアルでは、仮想マシンにアタッチされたディスクがプライマリから DR リージョンに複製されるオプションの一つについて説明します。
Hyperdisk Asynchronous Replication を使用した障害復旧
Hyperdisk Asynchronous Replication は、2 つのリージョン間でディスクのレプリケーションを行うための非同期ストレージ コピーを提供するストレージ オプションです。リージョンが停止することはまれですが、そのような場合でも、Hyperdisk Asynchronous Replication によってデータをセカンダリ リージョンにフェイルオーバーし、そのリージョンでワークロードを再起動できます。
Hyperdisk Asynchronous Replication は、実行中のワークロードにアタッチされているディスク(プライマリ ディスク)から、別のリージョンにある別のディスクにデータを複製します。複製されたデータを受信するディスクをセカンダリ ディスクと呼びます。プライマリ ディスクが実行されているリージョンをプライマリ リージョンと呼び、セカンダリ ディスクが実行されているリージョンをセカンダリ リージョンと呼びます。各 SQL Server ノードにアタッチされているすべてのディスクのレプリカに同じ時点のデータが含まれるように、ディスクは整合性グループに追加されます。整合性グループを使用すると、複数のディスクで DR と DR のテストを実行できます。
障害復旧アーキテクチャ
次の図は、Hyperdisk Asynchronous Replication の場合に、プライマリ リージョン R1 のデータベース HA と、プライマリ リージョンからセカンダリ リージョン R2 へのディスク レプリケーションをサポートする最小限のアーキテクチャを示しています。
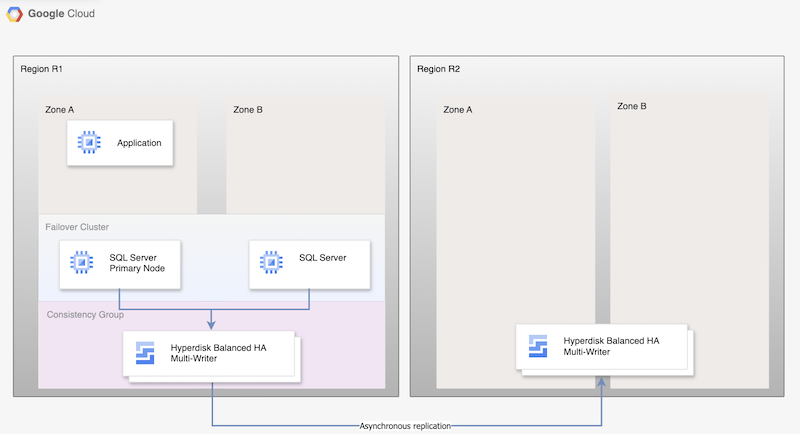
図 1. Microsoft SQL Server と Hyperdisk Asynchronous Replication を使用した障害復旧アーキテクチャ
このアーキテクチャは次のように機能します。
障害復旧プロセス
DR プロセスでは、リージョンが使用できなくなった後に別のリージョンでワークロードを再開するために実行する必要がある運用ステップが規定されます。
基本的なデータベース DR プロセスは、次の手順で構成されます。
この基本的なプロセスは、稼働中のプライマリ データベースを再度確立しますが、新しいプライマリ データベースが複製されないため、完全な HA アーキテクチャを確立しません。
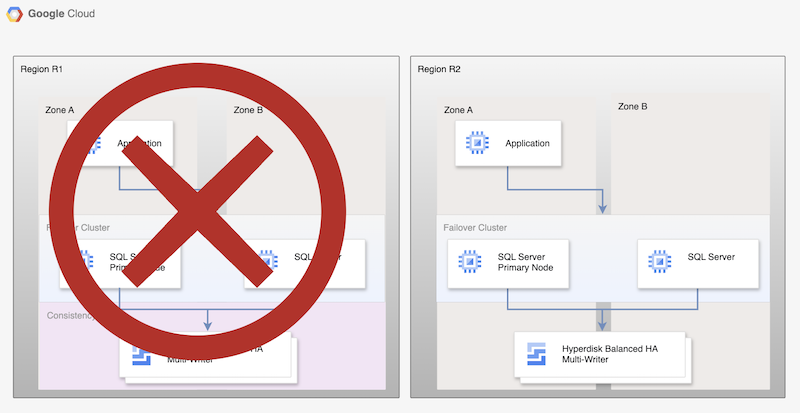
図 2. Persistent Disk 非同期レプリケーションを使用した障害復旧後の SQL Server デプロイ
復元したリージョンへのフォールバック
プライマリ リージョン(R1)がオンラインに戻ったら、フェイルバック プロセスを計画して実行できます。フェイルバック プロセスは、このチュートリアルで説明するすべての手順で構成されますが、この場合、R2 がソースで、R1 が復元リージョンです。
SQL Server のエディションを選択する
このチュートリアルは、次のバージョンの Microsoft SQL Server に対応しています。
このチュートリアルでは、Hyperdisk Balanced High Availability ディスクを使用する SQL Server フェイルオーバー クラスタ インスタンスを使用します。
SQL Server Enterprise の機能が必要ない場合は、SQL Server の Standard エディションを使用できます。
SQL Server の 2016 年、2017 年、2019 年、2022 年のバージョンは、Microsoft SQL Server Management Studio がイメージにインストールされています。別途インストールする必要はありません。ただし本番環境では、Microsoft SQL Server Management Studio の 1 つのインスタンスを、各リージョンの個別の VM にインストールすることをおすすめします。HA 環境を設定する場合は、ゾーンごとに Microsoft SQL Server Management Studio をインストールして、他のゾーンが使用できなくなっても、使用を継続できるようにしてください。
Microsoft SQL Server の障害復旧を設定する
このチュートリアルでは、Microsoft SQL Server Enterprise の
sql-ent-2022-win-2022イメージを使用します。イメージの完全なリストについては、OS イメージをご覧ください。
2 インスタンス高可用性クラスタを設定する
2 つのリージョン間で SQL Server のディスク レプリケーションを設定するには、まずリージョンにインスタンスが 2 つの HA クラスタを作成します。一方のインスタンスはプライマリとして機能し、もう一方はセカンダリとして機能します。この手順を完了するには、Hyperdisk Balanced High Availability マルチライター モードで SQL Server FCI クラスタを構成するの手順に沿って操作します。このチュートリアルでは、プライマリ リージョン R1 に
us-central1を使用します。Hyperdisk Balanced High Availability マルチライター モードで SQL Server FCI クラスタを構成するの手順を実施した場合、同じリージョン(us-central1)に 2 つの SQL Server インスタンスを作成することになります。プライマリ SQL Server インスタンス(node-1)をus-central1-aにデプロイし、スタンバイ インスタンス(node-2)をus-central1-bにデプロイします。ディスクの Asynchronous Replication を有効にする
すべての VM を作成して構成したら、次の手順で 2 つのリージョン間のディスク レプリケーションを有効にします。
この時点で、データはリージョン間で複製されているはずです。各ディスクのレプリケーション ステータスは
Activeになります。障害復旧をシミュレートする
このセクションでは、このチュートリアルで設定した障害復旧アーキテクチャをテストします。
停止をシミュレートして障害復旧フェイルオーバーを実行する
フェイルオーバー中に、DR リージョンに新しい VM を作成し、複製されたディスクを VM にアタッチします。フェイルオーバーを簡素化するには、DR リージョンで別の Virtual Private Cloud(VPC)を使用して復元します。こうすることで、同じ IP アドレスを使用できます。
フェイルオーバーを開始する前に、作成した AlwaysOn 可用性グループのプライマリ ノードが
node-1であることを確認します。2 つのノードは 2 つの個別の整合性グループによって保護されているため、データ同期の問題を回避するために、ドメイン コントローラとプライマリ SQL Server ノードを起動します。停止をシミュレートする手順は次のとおりです。停止をシミュレートして DR リージョンにフェイルオーバーしました。これで、セカンダリ インスタンスが正しく機能しているかどうかをテストできます。
SQL Server の接続を確認する
VM を作成したら、データベースが正常に復元され、サーバーが想定どおりに動作していることを確認します。データベースをテストするには、復元されたデータベースからクエリを実行します。
クリーンアップ
このチュートリアルで使用したリソースについて、 Google Cloud アカウントに課金されないようにするには、このセクションの手順に沿って、作成したリソースを削除します。
プロジェクトを削除する
次のステップ
-