このドキュメントでは、永続ディスクに仮想マシン(VM)インスタンスからアクセスする方法と、永続ディスクのレプリケーションのプロセスについて説明します。また、永続ディスクのコア インフラストラクチャについても説明します。このドキュメントは、システムで永続ディスクを使用する Google Cloud のエンジニアとアーキテクトを対象としています。
永続ディスクは、物理マシンにアタッチされたローカル ディスクではなく、ネットワーク ブロック デバイスとして VM にアタッチされたネットワーク サービスです。永続ディスクから読み取りや書き込みを行うと、データはネットワーク経由で転送されます。永続ディスクはネットワーク ストレージ デバイスですが、従来のディスクでは提供できない容量、汎用性、信頼性の面で多くのユースケースと機能を可能にします。
永続ディスクと Colossus
永続ディスクは、分散型ブロック ストレージ システムである Colossus という Google のファイル システムと連動して実行するように設計されています。永続ディスクのドライバは、VM からネットワークに転送される前に、VM 上のデータを自動的に暗号化します。その後、Colossus がデータを保持します。Colossus がデータを読み取ると、ドライバは受信データを復号します。
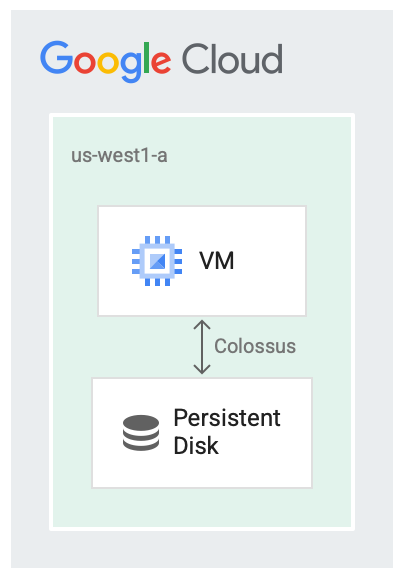
永続ディスクは、ストレージ バックエンドに Colossus を使用します。
ディスクをサービスとして使用すると、次のような多くの場合に便利です。
- VM の実行中にディスクのサイズを変更すると、VM を停止するよりも簡単です。VM を停止せずにディスクサイズを増やせます。
- ディスクと VM が同じライフサイクルを共有することや、同じ場所に配置する必要がない場合、ディスクのアタッチとデタッチが簡単になります。VM を停止し、その永続ブートディスクを使用して別の VM を起動できます。
- ディスク ドライバはレプリケーションの詳細を隠し、自動書き込み時レプリケーションを提供できるため、レプリケーションなどの高可用性機能が容易になります。
ディスク レイテンシ
ディスクをネットワーク サービスとして使用することで発生するオーバーヘッドのレイテンシをモニタリングするには、さまざまなベンチマーク ツールを使用できます。次の例では、NVMe インターフェースではなく SCSI ディスク インターフェースを使用し、永続ディスクから 4 KiB ブロックを数回読み取る VM の出力を示しています。以下に、読み取りのレイテンシの例を示します。
$ ioping -c 5 /dev/sda1
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=293.7 us (warmup)
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=330.0 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=278.1 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=307.7 us
4 KiB <<< /dev/sda1 (block device 10.00 GiB): time=310.1 us
--- /dev/sda1 (block device 10.00 GiB) ioping statistics ---
4 requests completed in 1.23 ms, 16 KiB read, 3.26 k iops, 12.7 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 278.1 us / 306.5 us / 330.0 us / 18.6 us
Compute Engine は、処理をできるだけ速く行う必要がある場合に、ローカル SSD を仮想マシンにアタッチすることもできます。キャッシュ サーバーを実行する場合や、中間出力がある大規模なデータ処理ジョブを実行する場合は、ローカル SSD を選択することをおすすめします。永続ディスクとは異なり、ローカル SSD のデータは永続化されないため、仮想マシンが再起動するたびに VM はデータをクリアします。ローカル SSD は、最適化のケースにのみ適しています。
次の出力は、NVMe ディスク インターフェースを使用してローカル SSD から 4 KiB を読み取った場合のレイテンシの例です。
$ ioping -c 5 /dev/nvme0n1
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=245.3 us(warmup)
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=252.3 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=244.8 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=289.5 us
4 KiB <<< /dev/nvme0n1 (block device 375 GiB): time=219.9 us
--- /dev/nvme0n1 (block device 375 GiB) ioping statistics ---
4 requests completed in 1.01 ms, 16 KiB read, 3.97 k iops, 15.5 MiB/s
generated 5 requests in 4.00 s, 20 KiB, 1 iops, 5.00 KiB/s
min/avg/max/mdev = 219.9 us / 251.6 us / 289.5 us / 25.0 us
レプリケーション
新しい Persistent Disk を作成する場合、1 つのゾーンにディスクを作成することも、同じリージョン内の 2 つのゾーンにディスクをレプリケーションすることもできます。
たとえば、us-west1-a のようにゾーンにディスクを 1 つ作成すると、ディスクのコピーが 1 つ作成されます。これらはゾーンディスクと呼ばれます。ディスクの可用性を高めるには、リージョン内の別のゾーン(us-west1-b など)にディスクの別のコピーを保存します。
同じリージョン内の 2 つのゾーンにレプリケーションされたディスクは、リージョン Persistent Disk と呼ばれます。
1 つのリージョンが完全に停止することはほとんどありませんが、ゾーンの障害は発生する可能性があります。次の図に示すように、異なるゾーンにあるリージョン内でレプリケーションを行うと、可用性が向上し、ディスク レイテンシが短縮されます。両方のレプリケーション ゾーンで障害が発生した場合、リージョン全体の障害とみなされます。

ディスクが 2 つのゾーンに複製されている。
複製されたシナリオでは、データは、仮想マシンが実行されているゾーンであるローカルゾーン(us-west1-a)で利用できます。その後、データは別のゾーン(us-west1-b)にある別の Colossus インスタンスに複製されます。少なくとも 1 つのゾーンは、VM が実行されているゾーンと同じである必要があります。
永続ディスクのレプリケーションはディスクの高可用性のためのみです。ゾーンの停止は仮想マシンやその他のコンポーネントに影響することがあり、それも停止を引き起こす可能性があります。
読み取り / 書き込みシーケンス
読み取り / 書き込みシーケンス、つまりデータがディスクに読み書きされる順序を決定する際に、作業の大部分は VM 内のディスク ドライバによって行われます。ユーザーはレプリケーションのセマンティクスを処理する必要はなく、通常どおりファイル システムを操作できます。基盤ドライバが読み取りと書き込みのシーケンスを処理します。
デフォルトでは、システムは完全レプリケーション モードで動作し、ディスクの読み取り / 書き込みリクエストは両方のレプリカに送信されます。
完全レプリケーション モードでは、次の処理が発生します。
- 書き込み時、書き込みリクエストは両方のレプリカへの書き込みを試行し、両方の書き込みが成功したことを確認します。
- 読み取り時、VM は両方のレプリカに読み取りリクエストを送信し、成功したレプリカからの結果を返します。読み取りリクエストがタイムアウトすると、別の読み取りリクエストが送信されます。
レプリカが処理に遅れ、読み取りまたは書き込みリクエストの完了の確認応答に失敗した場合、読み取り / 書き込みはレプリカに送信されなくなります。レプリケーションを続行する前に、レプリカの調整プロセスを実行して現在の状態に戻す必要があります。
次のステップ
- パフォーマンス要件を満たすようにディスクを構成する方法を確認する。
- 永続ディスクのスナップショットに関するベスト プラクティスを確認する。