Cloud Composer 3 | Cloud Composer 2 | Cloud Composer 1
Cette page explique comment surveiller l'état et les performances de l'environnement Cloud Composer général à l'aide de métriques clés sur le tableau de bord de surveillance.
Introduction
Ce tutoriel se concentre sur les principales métriques de surveillance Cloud Composer qui peuvent fournir une bonne vue d'ensemble de l'état et des performances au niveau de l'environnement.
Cloud Composer propose plusieurs métriques qui décrivent l'état général de l'environnement. Les consignes de surveillance de ce tutoriel sont basées sur les métriques exposées dans le tableau de bord Monitoring de votre environnement Cloud Composer.
Dans ce tutoriel, vous découvrirez les métriques clés qui servent d'indicateurs principaux des problèmes liés aux performances et à l'état de votre environnement, ainsi que les consignes pour interpréter chaque métrique en actions correctives afin de maintenir l'environnement en bon état. Vous allez également configurer des règles d'alerte pour chaque métrique, exécuter l'exemple de DAG et utiliser ces métriques et alertes pour optimiser les performances de votre environnement.
Objectifs
Coûts
Ce tutoriel utilise les composants facturables suivants de Google Cloud :
- Cloud Composer (voir les coûts supplémentaires)
- Cloud Monitoring
Une fois que vous avez terminé ce tutoriel, évitez de continuer à payer des frais en supprimant les ressources que vous avez créées. Pour en savoir plus, consultez Effectuer un nettoyage.
Avant de commencer
Cette section décrit les actions à effectuer avant de commencer le tutoriel.
Créer et configurer un projet
Pour ce tutoriel, vous avez besoin d'un projet Google Cloud. Configurez le projet comme suit :
Dans la console Google Cloud , sélectionnez ou créez un projet :
Assurez-vous que la facturation est activée pour votre projet. Découvrez comment vérifier si la facturation est activée sur un projet.
Assurez-vous que l'utilisateur de votre projet Google Cloud dispose des rôles suivants pour créer les ressources nécessaires :
- Administrateur de l'environnement et des objets Storage
(
roles/composer.environmentAndStorageObjectAdmin) - Administrateur de Compute (
roles/compute.admin) - Éditeur Monitoring (
roles/monitoring.editor)
- Administrateur de l'environnement et des objets Storage
(
Activer les API pour votre projet.
Enable the Cloud Composer API.
Roles required to enable APIs
To enable APIs, you need the Service Usage Admin IAM
role (roles/serviceusage.serviceUsageAdmin), which
contains the serviceusage.services.enable permission. Learn how to grant
roles.
Créer votre environnement Cloud Composer
Créez un environnement Cloud Composer 2.
Dans le cadre de cette procédure, vous attribuez le rôle Extension de l'agent de service de l'API Cloud Composer v2 (roles/composer.ServiceAgentV2Ext) au compte de l'agent de service Composer. Cloud Composer utilise ce compte pour effectuer des opérations dans votre projet Google Cloud .
Explorer les métriques clés sur l'état et les performances au niveau de l'environnement
Ce tutoriel se concentre sur les métriques clés qui peuvent vous donner une bonne vue d'ensemble de l'état et des performances globales de votre environnement.
Le tableau de bord Monitoring de la consoleGoogle Cloud contient diverses métriques et divers graphiques qui permettent de surveiller les tendances dans votre environnement et d'identifier les problèmes liés aux composants Airflow et aux ressources Cloud Composer.
Chaque environnement Cloud Composer possède son propre tableau de bord Monitoring.
Familiarisez-vous avec les métriques clés ci-dessous et localisez chacune d'elles dans le tableau de bord "Surveillance" :
Dans la console Google Cloud , accédez à la page Environnements.
Dans la liste des environnements, cliquez sur le nom de votre environnement. La page Détails de l'environnement s'ouvre.
Accédez à l'onglet Surveillance.
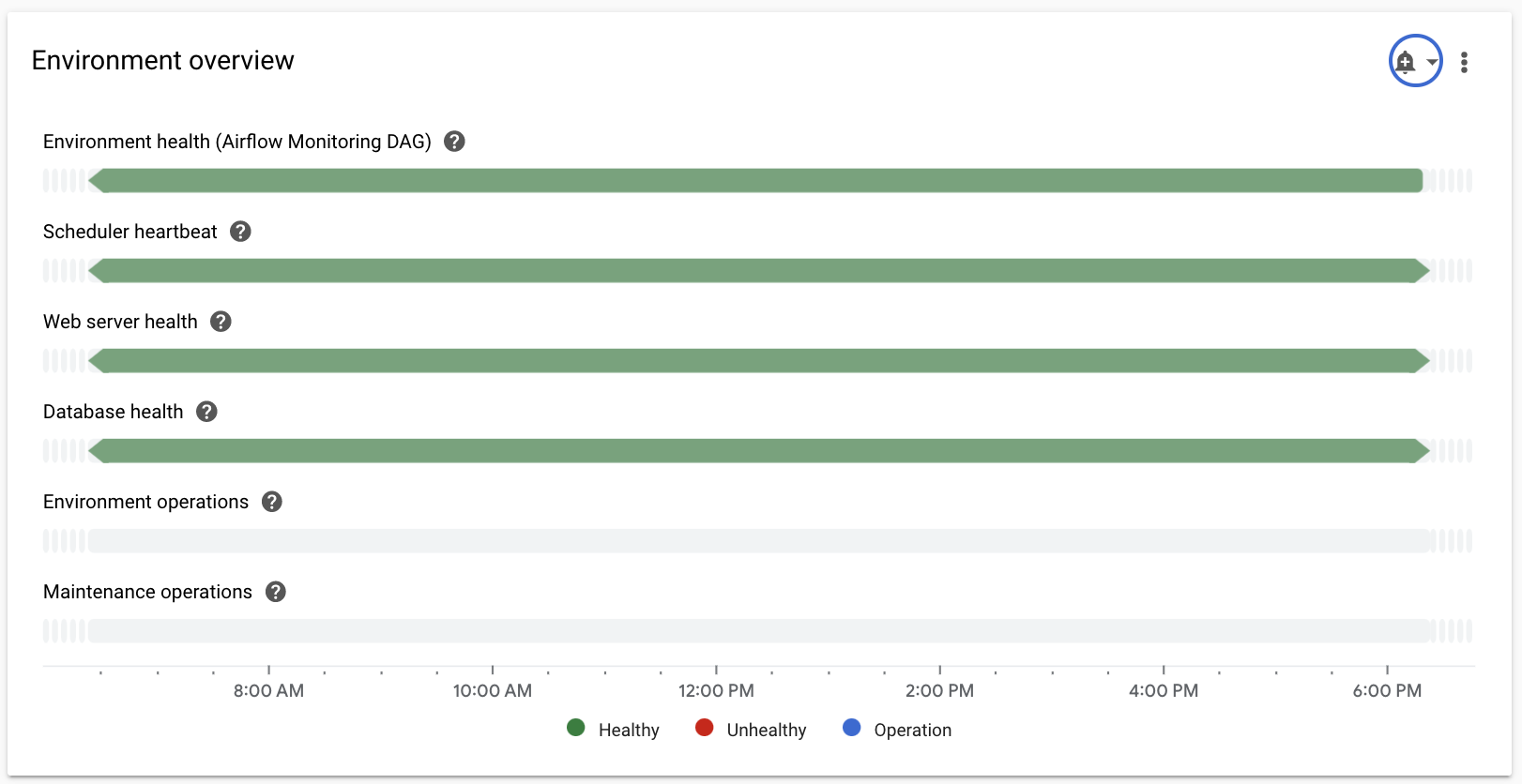
Sélectionnez la section Présentation, recherchez l'élément Présentation de l'environnement dans le tableau de bord, puis observez la métrique État de l'environnement (DAG de surveillance Airflow).
Cette chronologie indique l'état de l'environnement Cloud Composer. La couleur verte de la barre d'état de l'environnement indique que l'environnement est sain, tandis que la couleur rouge indique que l'environnement n'est pas sain.
Toutes les deux ou trois minutes, Cloud Composer exécute un DAG d'activité nommé
airflow_monitoring. Si l'exécution du DAG de liveness se termine correctement, l'état d'intégrité estTrue. Si l'exécution du DAG de vivacité échoue (par exemple, en raison de l'éviction d'un pod, de l'arrêt d'un processus externe ou d'une maintenance), l'état d'intégrité estFalse.
Sélectionnez la section Base de données SQL, recherchez l'élément État de la base de données dans le tableau de bord, puis observez la métrique État de la base de données.
Cette chronologie indique l'état de la connexion à l'instance Cloud SQL de votre environnement. La barre verte "État de la base de données" indique la connectivité, tandis que les échecs de connexion sont indiqués en rouge.
Le pod de surveillance Airflow pingue la base de données régulièrement et indique l'état d'intégrité
Truesi une connexion peut être établie ouFalsesi cela n'est pas possible.
Dans l'élément État de la base de données, observez les métriques Utilisation du processeur de la base de données et Utilisation de la mémoire de la base de données.
Le graphique "Utilisation du processeur de la base de données" indique l'utilisation des cœurs de processeur par les instances de base de données Cloud SQL de votre environnement par rapport à la limite totale de processeur de base de données disponible.
Le graphique "Utilisation de la mémoire de la base de données" indique l'utilisation de la mémoire par les instances de base de données Cloud SQL de votre environnement par rapport à la limite totale de mémoire disponible pour la base de données.
Sélectionnez la section Planificateurs, recherchez l'élément Signal de présence du planificateur dans le tableau de bord, puis observez la métrique Signal de présence du planificateur.
Cette chronologie indique l'état du programmateur Airflow. Recherchez des zones rouges pour identifier les problèmes liés au planificateur Airflow. Si votre environnement comporte plusieurs planificateurs, l'état de pulsation est "Bon" tant qu'au moins l'un des planificateurs répond.
Le planificateur est considéré comme non opérationnel si le dernier signal de présence a été reçu plus de 30 secondes (valeur par défaut) avant l'heure actuelle.
Sélectionnez la section Statistiques DAG, recherchez l'élément Tâches zombie supprimées dans le tableau de bord, puis observez la métrique Tâches zombie supprimées.
Ce graphique indique le nombre de tâches zombies supprimées pendant une courte période. Les tâches zombies sont souvent provoquées par l'arrêt externe des processus Airflow (par exemple, lorsqu'un processus de tâche est arrêté).
Le planificateur Airflow supprime régulièrement les tâches zombies, ce qui apparaît dans ce graphique.
Sélectionnez la section Nœuds de calcul, recherchez l'élément Redémarrages de conteneurs de nœuds de calcul dans le tableau de bord, puis observez la métrique Redémarrages de conteneurs de nœuds de calcul.
- Un graphique indique le nombre total de redémarrages pour les conteneurs de nœuds de calcul individuels. Un trop grand nombre de redémarrages de conteneurs peut affecter la disponibilité de votre service ou d'autres services en aval qui l'utilisent comme dépendance.
Découvrez les benchmarks et les mesures correctives possibles pour les métriques clés.
La liste suivante décrit les valeurs de référence qui peuvent indiquer des problèmes et fournit des mesures correctives que vous pouvez prendre pour résoudre ces problèmes.
État de l'environnement (DAG de surveillance Airflow)
Taux de réussite inférieur à 90 % sur une période de quatre heures
Les échecs peuvent entraîner des évictions de pods ou des arrêts de nœuds de calcul, car l'environnement est surchargé ou présente des dysfonctionnements. Les zones rouges de la chronologie de l'état de l'environnement correspondent généralement aux zones rouges des autres barres d'état des composants individuels de l'environnement. Identifiez la cause première en examinant d'autres métriques dans le tableau de bord "Monitoring".
État de la base de données
Taux de réussite inférieur à 95 % sur une période de quatre heures
Les échecs signifient qu'il existe des problèmes de connectivité à la base de données Airflow, qui peuvent être dus à un plantage ou à un temps d'arrêt de la base de données parce qu'elle est surchargée (par exemple, en raison d'une utilisation élevée du processeur ou de la mémoire, ou d'une latence plus élevée lors de la connexion à la base de données). Ces symptômes sont le plus souvent causés par des DAG sous-optimaux, par exemple lorsque les DAG utilisent de nombreuses variables d'environnement ou Airflow définies globalement. Identifiez la cause première en examinant les métriques d'utilisation des ressources de la base de données SQL. Vous pouvez également inspecter les journaux du planificateur pour détecter les erreurs liées à la connectivité de la base de données.
Utilisation du processeur et de la mémoire de la base de données
Utilisation moyenne du processeur ou de la mémoire supérieure à 80 % sur une période de 12 heures
La base de données est peut-être surchargée. Analysez la corrélation entre les exécutions de votre DAG et les pics d'utilisation du processeur ou de la mémoire de la base de données.
Vous pouvez réduire la charge de la base de données grâce à des DAG plus efficaces avec des requêtes et des connexions en cours d'exécution optimisées, ou en répartissant la charge plus uniformément dans le temps.
Vous pouvez également allouer plus de processeur ou de mémoire à la base de données. Les ressources de base de données sont contrôlées par la propriété de taille d'environnement de votre environnement, et l'environnement doit être mis à l'échelle à une taille plus grande.
Pulsation du programmeur
Taux de réussite inférieur à 90 % sur une période de quatre heures
Attribuez davantage de ressources au planificateur ou augmentez le nombre de planificateurs de 1 à 2 (recommandé).
Tâches zombie supprimées
Plus d'une tâche zombie par période de 24 heures
La raison la plus courante des tâches zombies est la pénurie de ressources de processeur ou de mémoire dans le cluster de votre environnement. Consultez les graphiques d'utilisation des ressources des nœuds de calcul et attribuez-leur davantage de ressources, ou augmentez le délai d'expiration des tâches zombies afin que le programmateur attende plus longtemps avant de considérer une tâche comme zombie.
Redémarrages de conteneurs de nœuds de calcul
Plus d'un redémarrage par période de 24 heures
La raison la plus courante est le manque de mémoire ou d'espace de stockage du nœud de calcul. Examinez la consommation de ressources des nœuds de calcul et allouez plus de mémoire ou d'espace de stockage à vos nœuds de calcul. Si le manque de ressources n'est pas la cause, consultez la section Dépannage des incidents de redémarrage des nœuds de calcul et utilisez les Requêtes de journalisation pour découvrir les raisons des redémarrages des nœuds de calcul.
Créer des canaux de notification
Suivez les instructions de la section Créer un canal de notification pour créer un canal de notification par e-mail.
Pour en savoir plus sur les canaux de notification, consultez Gérer les canaux de notification.
Créer des règles d'alerte
Créez des règles d'alerte basées sur les benchmarks fournis dans les sections précédentes de ce tutoriel pour surveiller en continu les valeurs des métriques et recevoir des notifications lorsque ces métriques ne respectent pas une condition.
Console
Vous pouvez configurer des alertes pour chaque métrique présentée dans le tableau de bord "Surveillance" en cliquant sur l'icône en forme de cloche située dans l'angle de l'élément correspondant :
Recherchez chaque métrique que vous souhaitez surveiller dans le tableau de bord Monitoring, puis cliquez sur l'icône en forme de cloche dans l'angle de l'élément de métrique. La page Créer une règle d'alerte s'ouvre.
Dans la section Transformer les données :
Configurez la section Dans chaque série temporelle comme décrit dans la configuration des règles d'alerte pour la métrique.
Cliquez sur Suivant, puis configurez la section Configurer le déclencheur d'alerte comme décrit dans la configuration des règles d'alerte pour la métrique.
Cliquez sur Suivant.
Configurez les notifications. Développez le menu Canaux de notification et sélectionnez le ou les canaux de notification que vous avez créés à l'étape précédente.
Cliquez sur OK.
Dans la section Nom de la règle d'alerte, remplissez le champ Nom de la règle d'alerte. Utilisez un nom descriptif pour chacune des métriques. Utilisez la valeur "Nommer la règle d'alerte" comme décrit dans la configuration des règles d'alerte pour la métrique.
Cliquez sur Suivant.
Examinez la règle d'alerte, puis cliquez sur Créer une règle.
Configurations des règles d'alerte pour la métrique "État de l'environnement (DAG de surveillance Airflow)"
- Nom de la métrique : Environnement Cloud Composer : sain
- API : composer.googleapis.com/environment/healthy
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformer les données > Dans chaque série temporelle :
- Période glissante : personnalisée
- Valeur personnalisée : 4
- Unités personnalisées : heure(s)
- Fenêtrage glissant : fraction (vrai)
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : en dessous du seuil
- Valeur du seuil : 90
- Nom de la condition : état de l'environnement
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte : "État de l'environnement Airflow".
Configurations des règles d'alerte pour les métriques d'état de la base de données
- Nom de la métrique : État de la base de données de l'environnement Cloud Composer
- API : composer.googleapis.com/environment/database_health
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformer les données > Dans chaque série temporelle :
- Période glissante : personnalisée
- Valeur personnalisée : 4
- Unités personnalisées : heure(s)
- Fenêtrage glissant : fraction (vrai)
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : en dessous du seuil
- Valeur du seuil : 95
- Nom de la condition : état de la base de données
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte : "État de la base de données Airflow".
Configurations de règles d'alerte pour la métrique "Utilisation du processeur de la base de données"
- Nom de la métrique : Utilisation du processeur de la base de données de l'environnement Cloud Composer
- API : composer.googleapis.com/environment/database/cpu/utilization
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformer les données > Dans chaque série temporelle :
- Période glissante : personnalisée
- Valeur personnalisée : 12
- Unités personnalisées : heure(s)
- Fenêtrage glissante : moyenne
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : au-dessus du seuil
- Valeur du seuil : 80
- Nom de la condition : condition d'utilisation du processeur de la base de données
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte : "Utilisation du processeur de la base de données Airflow".
Configurations des règles d'alerte pour la métrique "Utilisation de la mémoire de la base de données"
- Nom de la métrique : Utilisation de la mémoire de la base de données de l'environnement Cloud Composer
- API : composer.googleapis.com/environment/database/memory/utilization
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformer les données > Dans chaque série temporelle :
- Période glissante : personnalisée
- Valeur personnalisée : 12
- Unités personnalisées : heure(s)
- Fenêtrage glissante : moyenne
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : au-dessus du seuil
- Valeur du seuil : 80
- Nom de la condition : condition d'utilisation de la mémoire de la base de données
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte "Utilisation de la mémoire de la base de données Airflow".
Configurations des règles d'alerte pour la métrique "Pulsations du programmeur"
- Nom de la métrique : "Cloud Composer Environment - Scheduler Heartbeats"
- API : composer.googleapis.com/environment/scheduler_heartbeat_count
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformer les données > Dans chaque série temporelle :
- Période glissante : personnalisée
- Valeur personnalisée : 4
- Unités personnalisées : heure(s)
- Fenêtrage glissant : nombre
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : en dessous du seuil
Valeur du seuil : 216
- Vous pouvez obtenir ce nombre en exécutant une requête qui agrège la valeur
_scheduler_heartbeat_count_meandans l'éditeur de requêtes de l'explorateur de métriques.
- Vous pouvez obtenir ce nombre en exécutant une requête qui agrège la valeur
Nom de la condition : condition de pulsation du planificateur
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte : "Pulsation du programmeur Airflow".
Configurations des règles d'alerte pour la métrique "Tâches zombie supprimées"
- Nom de la métrique : Environnement Cloud Composer – Tâches zombie supprimées
- API : composer.googleapis.com/environment/zombie_task_killed_count
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION]Transformer les données > Dans chaque série temporelle :
- Période glissante : 1 jour
- Fenêtrage glissant : somme
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : au-dessus du seuil
- Valeur du seuil : 1
- Nom de la condition : condition des tâches zombies
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte : "Tâches zombies Airflow".
Configurations de règles d'alerte pour la métrique "Redémarrages de conteneurs de nœuds de calcul"
- Nom de la métrique : Nombre de redémarrages du conteneur Kubernetes
- API : kubernetes.io/container/restart_count
Filtres :
environment_name = [ENVIRONMENT_NAME] location = [CLUSTER_LOCATION] pod_name =~ airflow-worker-.*|airflow-k8s-worker-.* container_name =~ airflow-worker|base cluster_name = [CLUSTER_NAME]CLUSTER_NAMEcorrespond au nom du cluster de votre environnement, que vous trouverez sous Configuration de l'environnement > Ressources > Cluster GKE dans la console Google Cloud .Transformer les données > Dans chaque série temporelle :
- Période glissante : 1 jour
- Fenêtrage glissante : taux
Configurez un déclencheur d'alerte :
- Types de conditions : seuil
- Déclencheur d'alerte : À chaque infraction de série temporelle
- Position du seuil : au-dessus du seuil
- Valeur du seuil : 1
- Nom de la condition : condition de redémarrage des conteneurs de nœuds de calcul
Configurez les notifications et finalisez l'alerte :
- Nommez la règle d'alerte : "Redémarrages des nœuds de calcul Airflow".
Terraform
Exécutez un script Terraform qui crée un canal de notification par e-mail et importe des règles d'alerte pour les métriques clés fournies dans ce tutoriel en fonction de leurs benchmarks respectifs :
- Enregistrez l'exemple de fichier Terraform sur votre ordinateur local.
Remplacez les éléments suivants :
PROJECT_ID: ID de projet de votre projet. Par exemple,example-project.EMAIL_ADDRESS: adresse e-mail à laquelle envoyer une notification en cas de déclenchement d'une alerte.ENVIRONMENT_NAME: nom de votre environnement Cloud Composer. Exemple :example-composer-environmentCLUSTER_NAME: nom de votre cluster d'environnement, que vous trouverez sous Configuration de l'environnement > Ressources > Cluster GKE dans la console Google Cloud .
resource "google_monitoring_notification_channel" "basic" {
project = "PROJECT_ID"
display_name = "Test Notification Channel"
type = "email"
labels = {
email_address = "EMAIL_ADDRESS"
}
# force_delete = false
}
resource "google_monitoring_alert_policy" "environment_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Environment Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Environment health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/healthy\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.9
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "database_health_metric" {
project = "PROJECT_ID"
display_name = "Airflow Database Health"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database health condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database_health\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 0.95
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_FRACTION_TRUE"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_cpu_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database CPU Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database CPU usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/cpu/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_database_memory_usage" {
project = "PROJECT_ID"
display_name = "Airflow Database Memory Usage"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Database memory usage condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/database/memory/utilization\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 80
aggregations {
alignment_period = "43200s"
per_series_aligner = "ALIGN_MEAN"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_scheduler_heartbeat" {
project = "PROJECT_ID"
display_name = "Airflow Scheduler Heartbeat"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Scheduler heartbeat condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/scheduler_heartbeat_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_LT"
threshold_value = 216 // Threshold is 90% of the average for composer.googleapis.com/environment/scheduler_heartbeat_count metric in an idle environment
aggregations {
alignment_period = "14400s"
per_series_aligner = "ALIGN_COUNT"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_zombie_task" {
project = "PROJECT_ID"
display_name = "Airflow Zombie Tasks"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Zombie tasks condition"
condition_threshold {
filter = "resource.type = \"cloud_composer_environment\" AND metric.type=\"composer.googleapis.com/environment/zombie_task_killed_count\" AND resource.label.environment_name=\"ENVIRONMENT_NAME\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_SUM"
}
}
}
}
resource "google_monitoring_alert_policy" "alert_worker_restarts" {
project = "PROJECT_ID"
display_name = "Airflow Worker Restarts"
combiner = "OR"
notification_channels = [google_monitoring_notification_channel.basic.name] // To manually add a notification channel add it with the syntax "projects/[PROJECT_ID]/notificationChannels/[CHANNEL_ID]"
conditions {
display_name = "Worker container restarts condition"
condition_threshold {
filter = "resource.type = \"k8s_container\" AND (resource.labels.cluster_name = \"CLUSTER_NAME\" AND resource.labels.container_name = monitoring.regex.full_match(\"airflow-worker|base\") AND resource.labels.pod_name = monitoring.regex.full_match(\"airflow-worker-.*|airflow-k8s-worker-.*\")) AND metric.type = \"kubernetes.io/container/restart_count\""
duration = "60s"
comparison = "COMPARISON_GT"
threshold_value = 1
aggregations {
alignment_period = "86400s"
per_series_aligner = "ALIGN_RATE"
}
}
}
}
Tester les règles d'alerte
Cette section explique comment tester les règles d'alerte créées et interpréter les résultats.
Importer un exemple de DAG
L'exemple de DAG memory_consumption_dag.py fourni dans ce tutoriel imite une utilisation intensive de la mémoire des nœuds de calcul. Le DAG contient quatre tâches, chacune écrivant des données dans un exemple de chaîne, ce qui consomme 380 Mo de mémoire. L'exemple de DAG est programmé pour s'exécuter toutes les deux minutes et démarrera automatiquement une fois que vous l'aurez importé dans votre environnement Composer.
Importez l'exemple de DAG suivant dans l'environnement que vous avez créé lors des étapes précédentes :
from datetime import datetime
import sys
import time
from airflow import DAG
from airflow.operators.python import PythonOperator
def ram_function():
data = ""
start = time.time()
for i in range(38):
data += "a" * 10 * 1000**2
time.sleep(0.2)
print(f"{i}, {round(time.time() - start, 4)}, {sys.getsizeof(data) / (1000 ** 3)}")
print(f"Size={sys.getsizeof(data) / (1000 ** 3)}GB")
time.sleep(30 - (time.time() - start))
print(f"Complete in {round(time.time() - start, 2)} seconds!")
with DAG(
dag_id="memory_consumption_dag",
start_date=datetime(2023, 1, 1, 1, 1, 1),
schedule="1/2 * * * *",
catchup=False,
) as dag:
for i in range(4):
PythonOperator(
task_id=f"task_{i+1}",
python_callable=ram_function,
retries=0,
dag=dag,
)
Interpréter les alertes et les métriques dans Monitoring
Patientez environ 10 minutes après le début de l'exécution de l'exemple de DAG, puis évaluez les résultats du test :
Vérifiez votre boîte de réception pour vous assurer que vous avez reçu une notification deGoogle Cloud Alerting dont l'objet commence par
[ALERT]. Le contenu de ce message contient les détails de l'incident lié à la règle d'alerte.Cliquez sur le bouton Afficher l'incident dans la notification par e-mail. Vous êtes redirigé vers l'explorateur de métriques. Examinez les détails de l'incident d'alerte :

Figure 2. Détails de l'incident ayant généré une alerte (cliquez pour agrandir) Le graphique des métriques d'incidents indique que les métriques que vous avez créées ont dépassé le seuil de 1, ce qui signifie qu'Airflow a détecté et arrêté plus d'une tâche zombie.
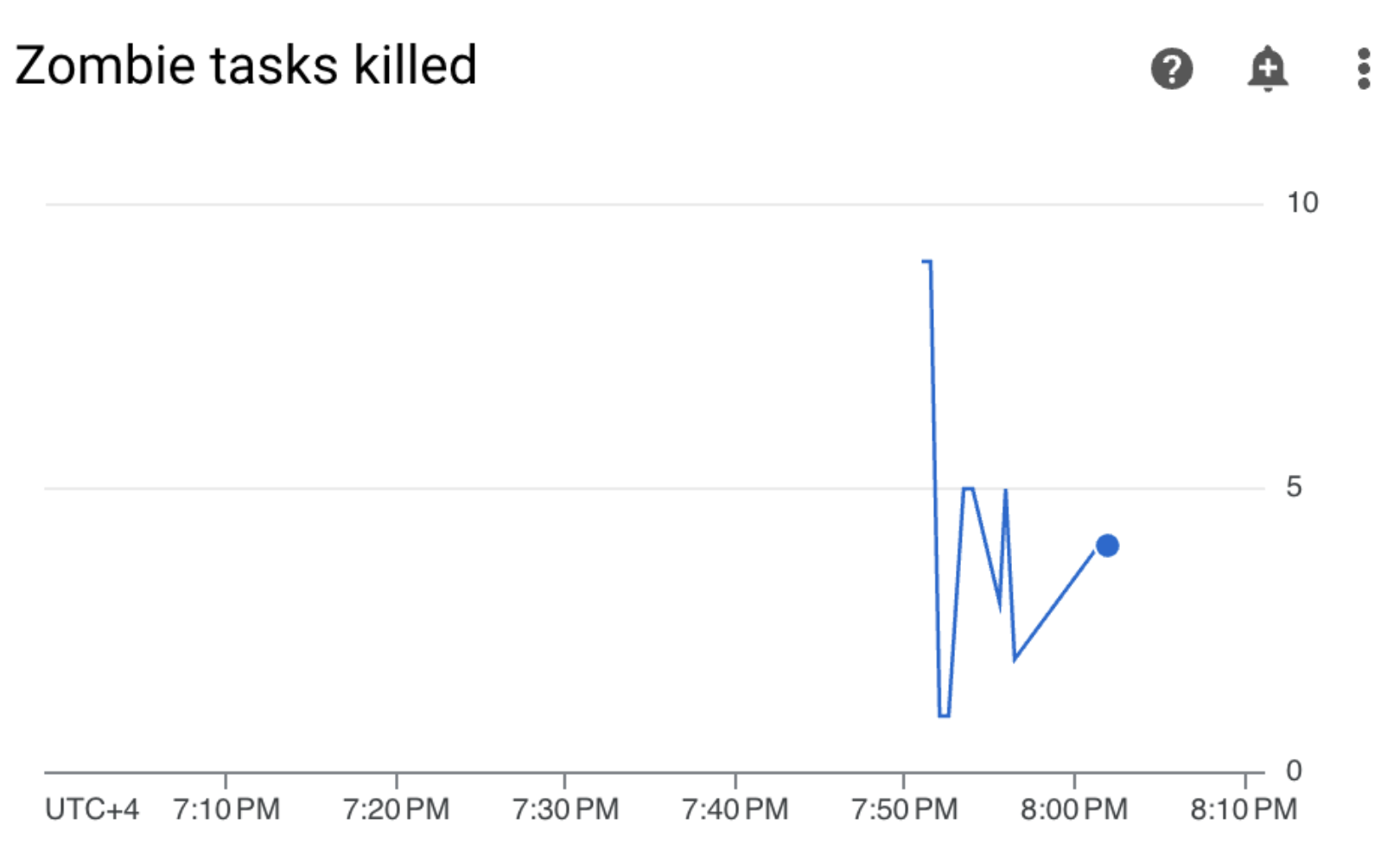
Dans votre environnement Cloud Composer, accédez à l'onglet Surveillance, ouvrez la section Statistiques DAG et recherchez le graphique Tâches zombies supprimées :

Figure 3. Graphique des tâches zombie (cliquez pour agrandir) Le graphique indique qu'Airflow a supprimé environ 20 tâches zombies au cours des 10 premières minutes d'exécution du DAG exemple.
Selon les benchmarks et les actions correctives, la raison la plus courante des tâches zombies est le manque de mémoire ou de processeur du nœud de calcul. Identifiez la cause racine des tâches zombies en analysant l'utilisation des ressources de vos workers.
Ouvrez la section "Nœuds de calcul" de votre tableau de bord Monitoring et examinez les métriques d'utilisation du processeur et de la mémoire des nœuds de calcul :
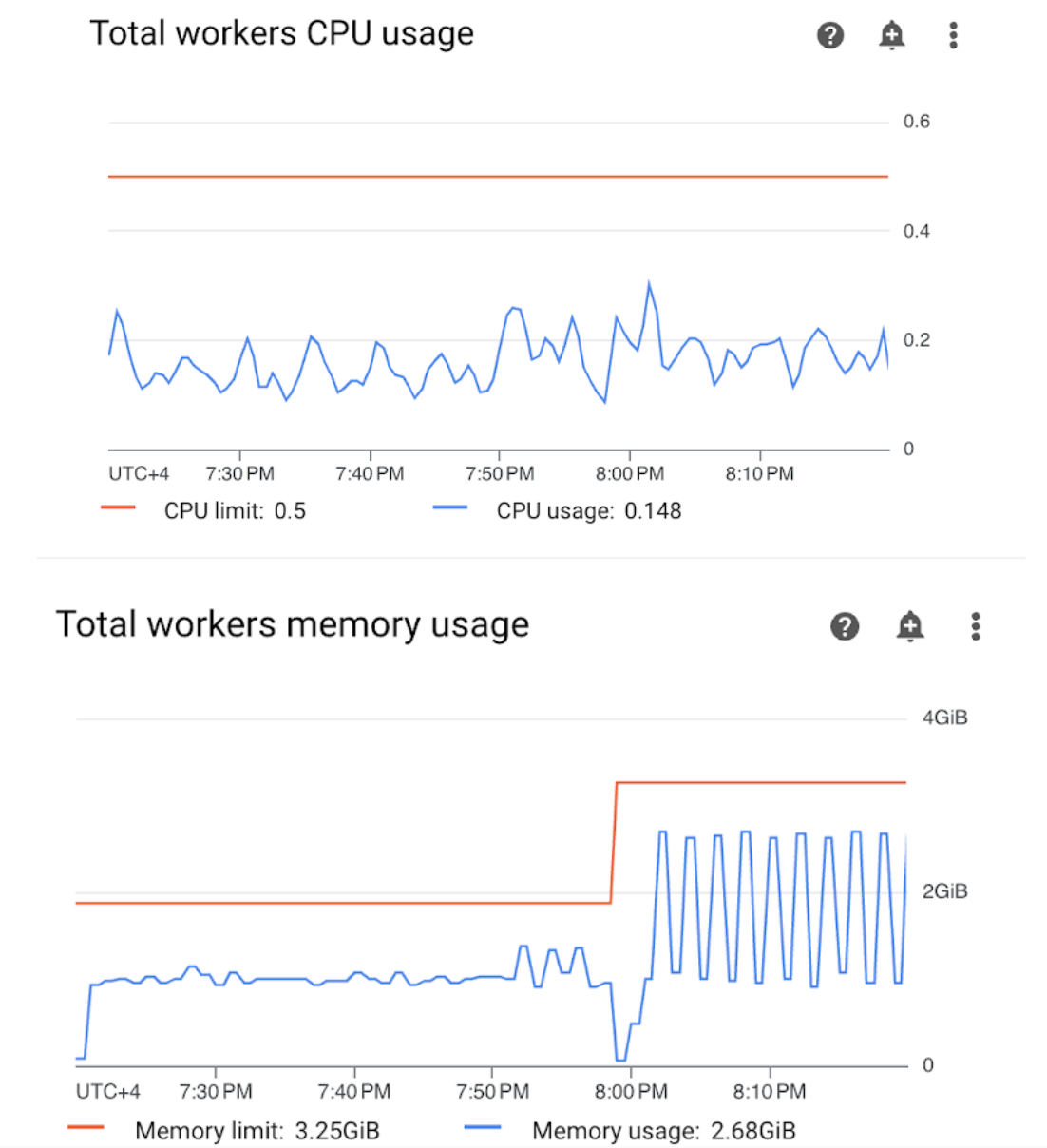
Figure 4 : Métriques sur l'utilisation du processeur et de la mémoire des nœuds de calcul (cliquez pour agrandir) Le graphique "Utilisation totale du processeur des nœuds de calcul" indique que l'utilisation du processeur des nœuds de calcul est toujours restée en dessous de 50 % de la limite totale disponible. Le processeur disponible est donc suffisant. Le graphique "Utilisation totale de la mémoire des nœuds de calcul" montre que l'exécution de l'exemple de DAG a entraîné l'atteinte de la limite de mémoire pouvant être allouée, qui équivaut à près de 75 % de la limite de mémoire totale indiquée dans le graphique (GKE réserve 25 % des quatre premiers Gio de mémoire et 100 Mio de mémoire supplémentaires sur chaque nœud pour gérer l'éviction des pods).
Vous pouvez en conclure que les nœuds de calcul manquent de ressources mémoire pour exécuter correctement l'exemple de DAG.
Optimiser votre environnement et évaluer ses performances
En fonction de l'analyse de l'utilisation des ressources des nœuds de calcul, vous devez allouer plus de mémoire à vos nœuds de calcul pour que toutes les tâches de votre DAG réussissent.
Dans votre environnement Composer, ouvrez l'onglet DAG, cliquez sur le nom de l'exemple de DAG (
memory_consumption_dag), puis sur Suspendre le DAG.Allouer de la mémoire supplémentaire aux nœuds de calcul :
Dans l'onglet "Configuration de l'environnement", recherchez la configuration Ressources > Charges de travail, puis cliquez sur Modifier.
Dans l'élément Nœud de calcul, augmentez la limite de mémoire. Dans ce tutoriel, utilisez 3,25 Go.
Enregistrez les modifications et attendez plusieurs minutes que le nœud de calcul redémarre.
Ouvrez l'onglet "DAG", cliquez sur le nom de l'exemple de DAG (
memory_consumption_dag), puis sur Réactiver le DAG.
Accédez à Monitoring et vérifiez qu'aucune nouvelle tâche zombie n'est apparue après la mise à jour des limites de ressources de vos workers :
Résumé
Dans ce tutoriel, vous avez découvert les principales métriques sur l'état et les performances au niveau de l'environnement, comment configurer des règles d'alerte pour chaque métrique et comment interpréter chaque métrique pour prendre des mesures correctives. Vous avez ensuite exécuté un exemple de DAG, identifié la cause première des problèmes d'état de l'environnement à l'aide des alertes et des graphiques de surveillance, et optimisé votre environnement en allouant plus de mémoire à vos nœuds de calcul. Toutefois, il est recommandé d'optimiser vos DAG pour réduire la consommation de ressources des nœuds de calcul en premier lieu, car il n'est pas possible d'augmenter les ressources au-delà d'un certain seuil.
Effectuer un nettoyage
Pour éviter que les ressources utilisées dans ce tutoriel ne soient facturées sur votre compte Google Cloud , supprimez le projet contenant les ressources, ou conservez le projet et supprimez les ressources individuelles.
Supprimer le projet
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Supprimer des ressources individuelles
Si vous envisagez d'explorer plusieurs tutoriels et guides de démarrage rapide, réutiliser des projets peut vous aider à ne pas dépasser les limites de quotas des projets.
Console
- Supprimez l'environnement Cloud Composer. Vous allez également supprimer le bucket de l'environnement au cours de cette procédure.
- Supprimez chacune des règles d'alerte que vous avez créées dans Cloud Monitoring.
Terraform
- Assurez-vous que votre script Terraform ne contient pas d'entrées pour les ressources qui sont toujours requises par votre projet. Par exemple, vous pouvez choisir de conserver certaines API activées et des autorisations IAM toujours attribuées (si vous avez ajouté de telles définitions à votre script Terraform).
- Exécutez
terraform destroy. - Supprimez manuellement le bucket de l'environnement. Cloud Composer ne le supprime pas automatiquement. Vous pouvez le faire depuis la console Google Cloud ou Google Cloud CLI.
Étapes suivantes
- Optimiser les environnements
- Faire évoluer des environnements
- Gérer les libellés d'environnement et répartir les coûts liés à l'environnement