Google Cloud VMware Engine のデータソースで BigQuery を使う
Google Cloud Japan Team
※この投稿は米国時間 2021 年 12 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
このブログ記事は、オンプレミスのデータソースを Google Cloud VMware Engine に移行したお客様で、Google Cloud が提供するデータおよび分析サービスを利用したいと考えている方を対象としています。お客様が Google Cloud を選ぶ目的の一つは、ご自身のデータセットに Google Cloud 分析を活用することです。お客様が IT の意思決定者、あるいはデータ アーキテクトである場合、Google 分析を使ってデータのパワーを迅速に利用したいとお考えでしょうか。このブログ記事では、データセットに対する高度な分析や機械学習が可能な BigQuery を使ったデータへのアクセス方法をご説明します。
理由
データの使用と分析は、テクノロジーの最前線にあります。大量のデータとリソースプールが日々管理され、使用されています。こういった状況に対応するため、Google Cloud は既存のデータベースの管理と理解を支援しています。その際、費用をかけてソース マテリアルやデータのロケーションを再設計する必要はありません。このブログ記事では、データベースを再設計することなしに、既存データを使って Google Cloud データおよび分析サービスへアクセスする方法をご紹介します。データソースが Google Cloud VMware Engine にあると、Google の可用性に優れたフォールト トレラントのインフラストラクチャを活用して、データ パイプラインのパフォーマンスを向上させることができます。これらのソリューションは、BigQuery を利用したクラウド ネイティブ分析により、データセットから価値を抽出するまでの時間を短縮することを目的としています。
Google Cloud VMware Engine を介して移行を実施するこのソリューションは、データ オペレーションのあらゆる面でメリットを提供します。データベース管理者(DBA)や仮想インフラストラクチャ / クラウドの管理者は、オンプレミスに類似の使い慣れた環境をクラウド上でも利用できます。オンプレミスのインフラストラクチャ チームは、使い慣れたツールセットを利用して、データ サイエンティスト チーム、AI チーム、機械学習(ML)チームを実現できます。これらのチームは、オンプレミスのデータに対して、Google Cloud の AI / ML / データ分析機能を利用できるようになります。
例えば、プロダクトのクロスセルの機会を模索している場合、最初のステップは、プロダクト全体にわたってプロダクトの使用状況と請求データセットが分析できるようにつながっているかを確認することです。DBA チームがデータセットを特定し、インフラストラクチャ チームがこれらのソースへのアクセスを可能にします。次に、アプリケーション チームはこのデータを BigQuery に複製し、BigQuery ML レコメンデーションなどのアプローチを用いて、クロスセルの機会を引き出します。別のユースケースの例としては、オペレーションの使用量の増加予測や成長計画があります。販売データが BigQuery に複製されると、データセットでの高度な時系列予測のアプローチが利用可能になります。
含まれる内容
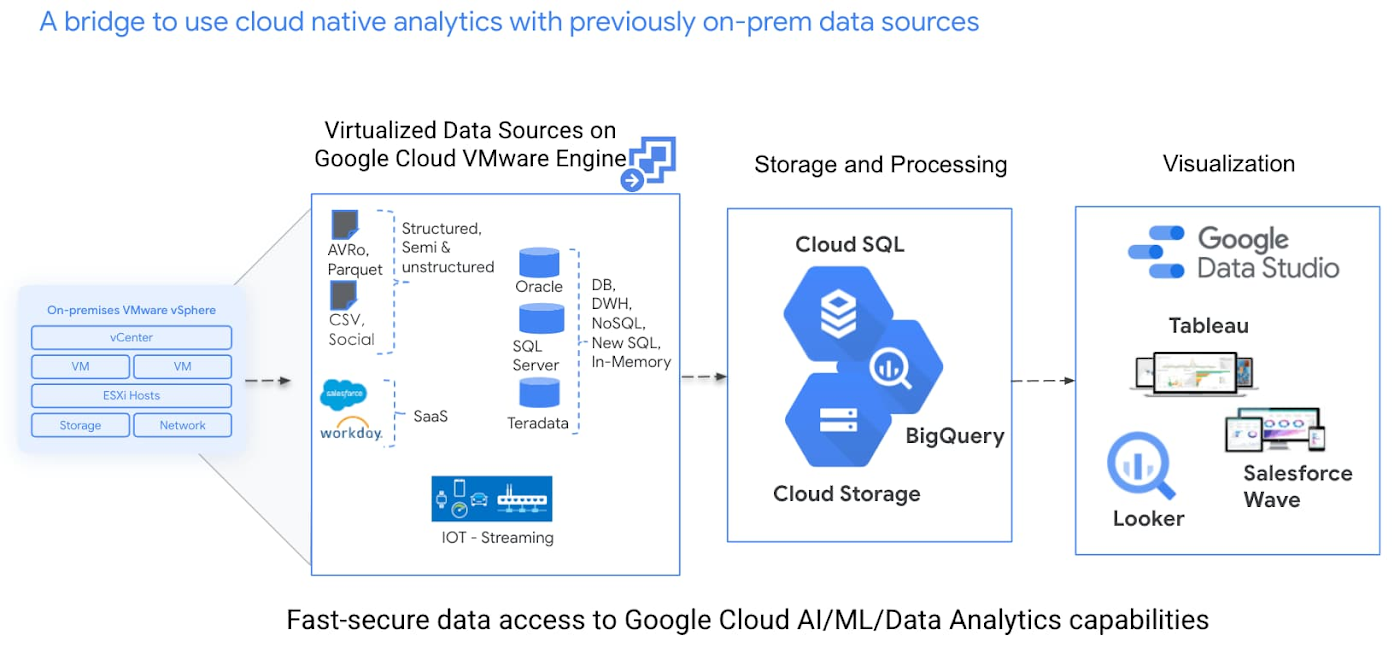
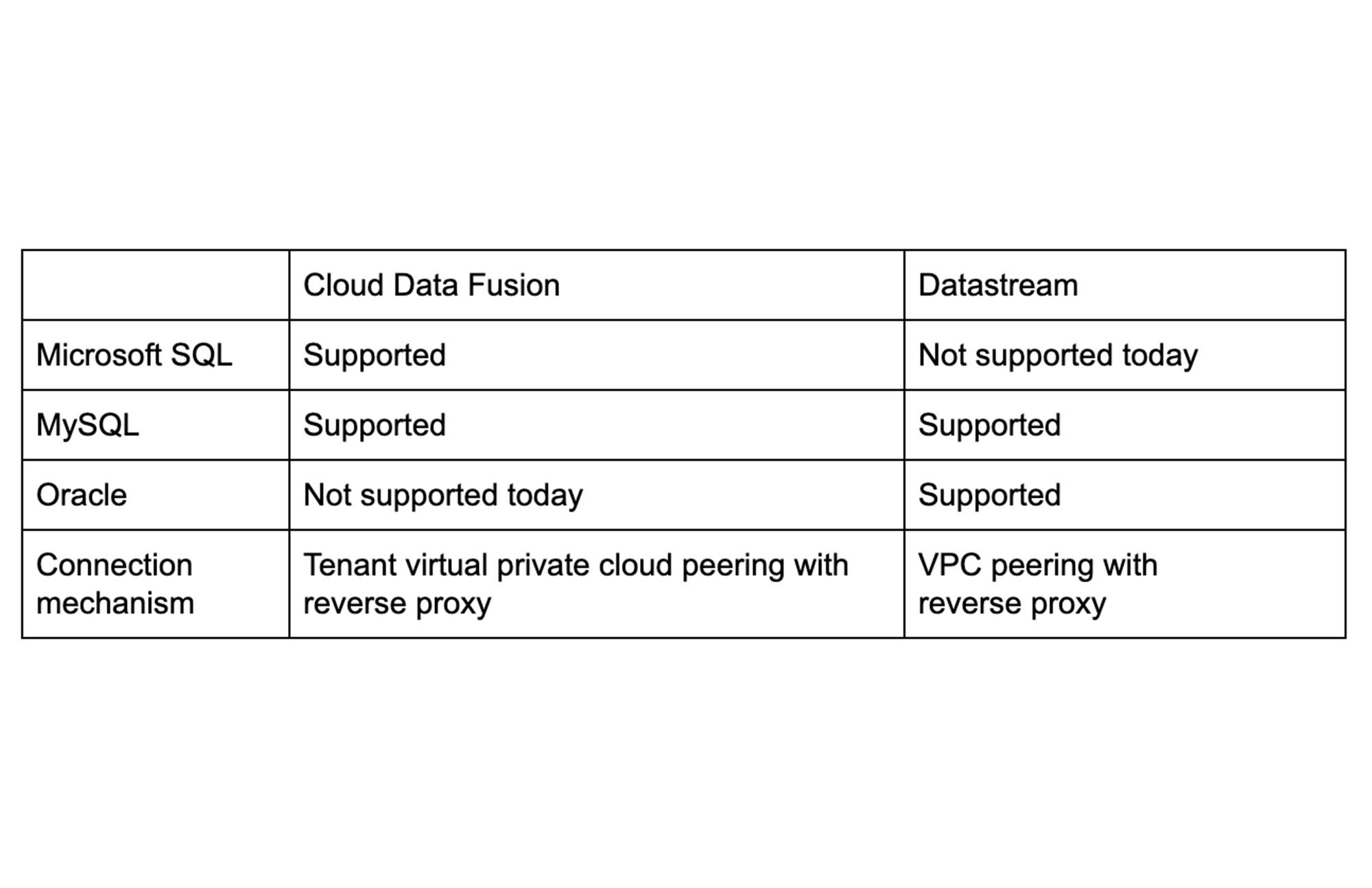
リレーショナル データセットを BigQuery 内に非公開かつ安全に複製するために、Google Cloud Data Fusion や Google Cloud Datastream を利用する方法をご紹介します。Datafusion は、さまざまな種類のデータ パイプラインをサポートする ETL ツールです。Datastream は、変更データ キャプチャとレプリケーションのためのサービスです。この両方のサービスを利用すると、データは常に Google Cloud のプロジェクトの中に存在し、内部 IP を使ってデータにアクセスできます。ここではリアルタイム レプリケーションに焦点を当て、BigQuery 内で SQL Server、MySQL、Oracle などのオペレーショナル データストアから継続的にデータにアクセスできるようにします。
データソースからクラウドへのデータ移行や、ETL(抽出 / 変換 / 読み込み)によるデータ ウェアハウスへのデータ パイプラインの維持には、非常に時間がかかります。別のアプローチとしては、ELT(抽出 / 読み込み / 変換)があります。ELT アプローチでは、ターゲット システム(BigQuery など)にデータを読み込んでから変換が行われます。ELT プロセスは、従来の ETL プロセスよりも簡単に実行でき、データの読み込みも速いため、よく利用されています。
データセットが Google Cloud に存在することで、データチームは高速かつ低レイテンシの Google Cloud ネットワーク上で Cloud Data Fusion や Datastream を利用して、VMware インフラストラクチャから Google Cloud ネイティブ ストレージ バケットや BigQuery など Google Cloud のさまざまな宛先にデータを複製、移動できます。
わかりやすくするために、ここではすべてのサービスが同じプロジェクト内で使用されていると仮定します。また、Google Cloud の VMware Engine から、オンプレミスから、または他の Virtual Private Cloud(VPC)からデータを移行する際の料金への影響についても説明します。
Cloud Data Fusion:
Cloud Data Fusion は、ETL / ELT データ パイプラインをコードフリーでデプロイできる、マウス操作だけの視覚的インターフェースを提供しますCloud Data Fusion には、テーブルを BigQuery に複製するためのレプリケーション アクセラレータも用意されています。
Cloud Data Fusion は、独自の VPC を持つテナント プロジェクトを内部で設定し、Cloud Data Fusion のリソースを管理します。Cloud Data Fusion を使って Google Cloud VMware Engine 内のデータソースにアクセスするには、メイン VPC 上でリバース プロキシを使用します。これについては以下の画像で説明します。
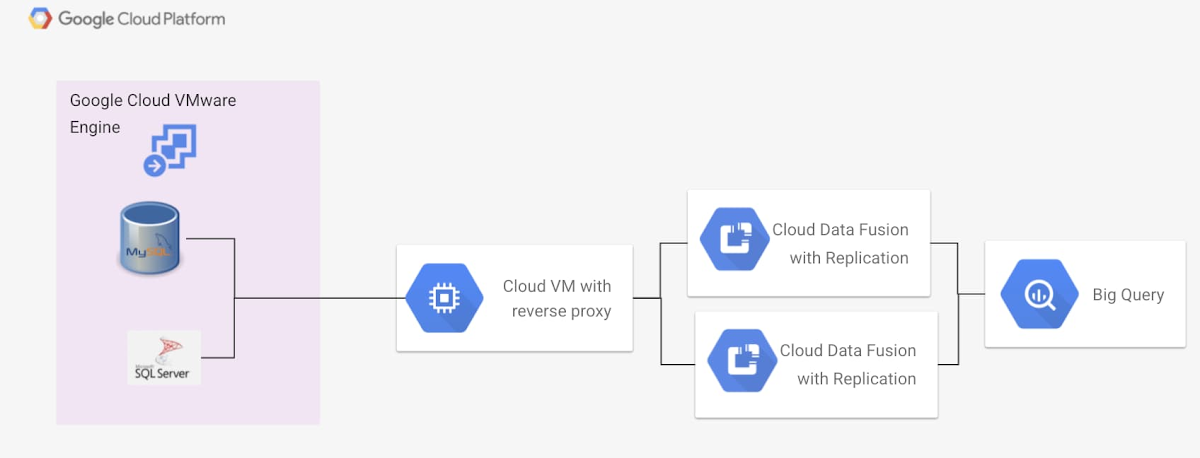
このシナリオでは、プロジェクト内の Google Cloud VMware Engine インスタンス上でデータ ワークロードを実行しています。Google Cloud VMware Engine 環境には、Google Cloud VMware Engine でピアリングされたプロジェクト レベルの VPC を介してアクセスします。プロジェクト レベルの VPC 上の Google Compute Engine インスタンスは、Google Cloud VMware Engine インスタンスに直接アクセスできないサービスに対して、Google Cloud VMware Engine データベースへのリバース プロキシを公開します。Cloud Data Fusion インスタンスは、メイン VPC へのプライベート IP アクセスとネットワーク ピアリングが可能で、リバース プロキシ インスタンスを介してデータにアクセスできます。Cloud Data Fusion に内部 IP アクセスとネットワーク ピアリングを設定するプロセスについては、こちらのドキュメントをご覧ください。
ピアリングが完了したら、Cloud Data Fusion の Java Database Connectivity コネクタを使って、レプリケーションや高度な ETL オペレーションのためにデータベースにアクセスします。変更データ キャプチャを有効にするには、Google Cloud VMware Engine 内のデータベースを有効にして、データベースへの変更をトラックおよびキャプチャする必要があります。このプロセス全体の設定とレプリケーションについては、MySQL と SQL Server のドキュメントで説明しています。
Google Cloud Datastream
Datastream は、サーバーレスの変更データ キャプチャとレプリケーション サービスです。Google Cloud VMware Engine 上の Oracle、MySQL データベースから、低レイテンシのストリーミング データにアクセスできます。この方法では、データフローのパイプラインをより柔軟に管理できます。このソリューションは一般提供前であり、一部の地域でのみ提供されています。
また、このオプションでは、Google Compute Engine インスタンス内にリバース プロキシを構成する必要があります。このリバース プロキシは、Google Cloud VMware Engine 内のデータソースにアクセスするために使用されます。このオプションについて詳しくは、こちらのドキュメントをご覧ください。
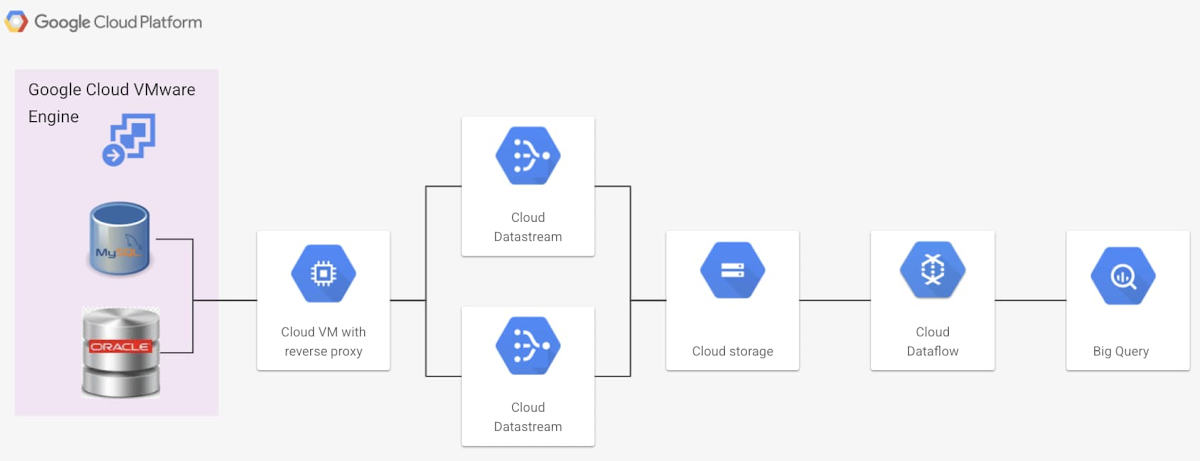
Datastream を使用するための詳しい設定方法は、入門ガイドをご参照ください。レプリケーションを有効にするには、Datastream に構成されたストリームが必要です。このストリームは、データベースのデータにアクセスし、データをクラウド ストレージのシンクにパイプします。Datastream は、リバース プロキシを使用してデータにアクセスしますが、これはお客様の VPC 上で公開されている必要があります。データを BigQuery にパイプするために、Dataflow 内であらかじめ構成された Datastream to BigQuery テンプレートを使用します。
ご利用方法
最初のステップは、Google Cloud VMware Engine にワークロードを移行することです。クラウド管理者やアーキテクトがこれを推進するのが一般的です。移行フェーズで特定されていない場合、次のステップは、Google Cloud VMware Engine でホストされている仮想マシン上に存在するデータベースを特定し、BigQuery を使用して既存のレポートを再作成することです。ほとんどの組織では、このプロセスに複数のペルソナが関わってきます。例えば、データソースに関する情報はデータ アーキテクトが、コストやパフォーマンスへの影響に関する分析情報はソリューション アーキテクトが、ネットワーク インターフェースに関する情報はインフラストラクチャからの入力が、それぞれ最適な情報源となるでしょう。以下のステップは、こうした動きを可能にするために考えられるアプローチです。
Google Cloud VMware Engine に移行された仮想マシン上に存在する、レポートに使用されるデータセットを特定します。
データベースの種類とパイプラインの要件(価格と性能のトレードオフと使いやすさ)に基づいて、適切なパイプライン(Datastream または Data Fusion)を選択します。
データ パイプラインに基づいて、適切なリージョンを選択します。同一リージョン内では、下り(外向き)データの料金は発生しません。
Google Cloud VMware Engine データセットへのリバース プロキシを設定します。
必要とされるレプリケーションのパフォーマンスに基づいて、パフォーマンス パラメータでレプリケーション サービスを設定します。
データセットのビジネス要件に基づいた分析と可視化を有効にします。
結論
Google Cloud VMware Engine サービスは、既存のデータセットを使用したデータおよび分析の可視化を、迅速かつ容易に実現します。これにより、時間のかかるデータベースの再構築をすることなく、VMware 上の既存のインフラストラクチャ オペレーション態勢を活用してクラウド分析を実現できます。これらのアプローチにより、Google Cloud 上の専用ハードウェアのパフォーマンス メリットを活用し、世界最先端のデータ機能に接続できます。
謝辞
このブログへのご意見をいただいた Manoj Sharma 氏と Sai Gopalan 氏に感謝いたします。
Google Cloud プロダクト マネージャー Nitish Murthy
VMware-aaS グローバル リード ソリューション マネージャー Wade Holmes