Google Cloud 上のオープン データ レイクハウス
Google Cloud Japan Team
※この投稿は米国時間 2021 年 10 月 29 日に、Google Cloud blog に投稿されたものの抄訳です。
10 年以上にわたり、テクノロジー業界では、組織が求める多様性、ボリューム、レイテンシ、耐障害性、そして多様なデータアクセスの要件に対応しつつ、膨大なデータを保存、分析するための最適な方法を模索してきました。
これに対し、従来実装されてきたアーキテクチャは保存と分析を別個に行う、サイロ化されたものでした。データ ウェアハウスは、主に BI やレポートに使用される構造化された集計データを保存するために使用され、データレイクは、主に ML ワークロードに使用される非構造化データおよび半構造化データを大量に保存するために使用されます。この方法では、複雑な ETL パイプラインを必要とする大規模なデータの移動、処理、および重複がしばしば発生しました。このアーキテクチャの運用と管理は困難で、コストもかかり、アジリティも低下していました。組織がクラウドに移行する際には、こうしたサイロを解消したいと考えています。
これらの問題を解決するために、 データ レイクハウスという新しいアーキテクチャが登場しました。このアーキテクチャはデータレイクとデータ ウェアハウスの利点を組み合わせたものです。このアーキテクチャでは、Spark などさまざまな処理エンジンからアクセスできるオープン フォーマットで低コストのストレージが実現すると同時に、強力な管理機能と最適化機能も提供されます。
Google Cloud は、お客様に選択肢を提供することを信条としています。オープンソース技術のみでデータ レイクハウスを構築したい組織は、Google Cloud Storage(GCS)が提供する低コストのオブジェクト ストレージを使用することができます。データの保存にあたっては Parquet のようなオープン(OSS)フォーマットを、処理エンジンには Spark などが利用可能で、Delta、Iceberg、Hudi のようなフレームワークを Dataproc を通じて使用することで、トランザクション処理も実現できます。このオープンソース ベースのソリューションはまだ進化中であるため、構成、チューニング、スケーリングに多くの労力を必要とします。
Google は、クラウド ネイティブで、スケーラブルかつセキュリティに優れたデータレイク ソリューションを Google Cloud で提供し、幅広い選択肢と優れた相互運用性をお客様にお届けしています。Google のクラウド ネイティブ アーキテクチャは、組織におけるコスト削減と効率向上を実現します。 Google Cloud のソリューションは以下をベースにしています。
ストレージ: Google Cloud Storage による低コストのオブジェクト ストレージと、BigQuery による高度に最適化された分析用ストレージを選択可能。
コンピューティング: ワークロードごとに異なるエンジンを提供するサーバーレス コンピューティング。
BigQuery は、サーバーレスのクラウド データ ウェアハウスでペタバイト級のデータの分析を可能にする ANSI SQL 互換のエンジンを提供。
Dataprocは Hadoop と Spark のマネージド サービスで、さまざまなオープンソース フレームワークの使用を可能にする。
サーバーレス Sparkは、お客様からマネージド サービスにワークロードを送信可能で、ジョブ実行をサービス側で行う。
Vertex AI は大規模な ML モデルを、限られたコーディングで構築可能な統合 MLOps プラットフォーム。
さらに、Databricks、Starburst、Elastic などのパートナーのプロダクトをさまざまなワークロードに使用できる。
管理: Dataplex は、Google Cloud Storage(オブジェクト ストレージ)と BigQuery(高度に最適化された分析用ストレージ)のデータを横断する、メタデータ主導のデータ管理ファブリックを実現。組織は、Dataplex を使用して、レイクハウスでデータの作成、管理、保護、整理、分析をすることが可能。
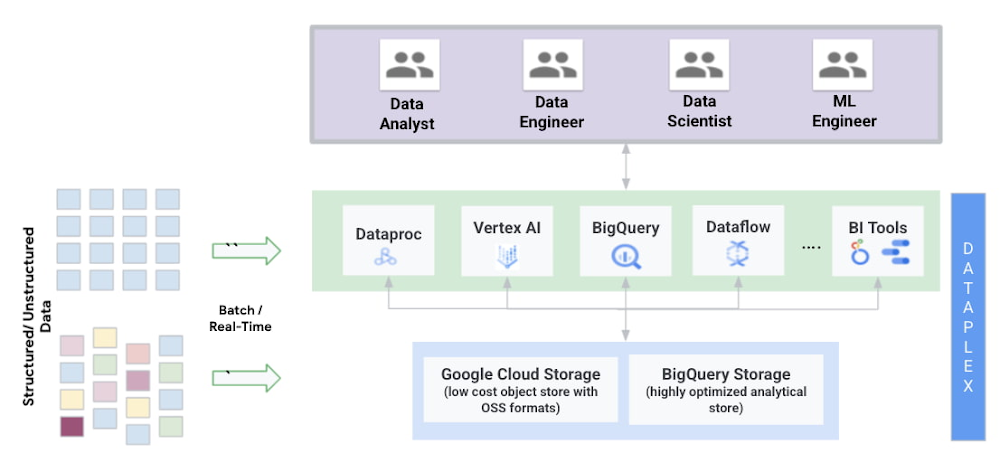
ここではデータ レイクハウス アーキテクチャの主な特徴と、お客様がどのようにして GCP 上で大規模な構築を行っているかを詳しく見ていきましょう。
選択可能なストレージ
Google Cloud では、オープンなプラットフォームを提供することを基本方針としています。お客様には、Google Cloud Storage の低コストなオブジェクト ストレージにデータを保存するか、高度に最適化された分析用ストレージや GCP で利用可能なその他のストレージ オプションを選択していただきたいと考えています。構造化データは BigQuery Storage に保存することをおすすめします。BigQuery Storage はストリーミング API も提供しており、組織は大量のデータをリアルタイムで取り込み、分析できます。非構造化データは Google Cloud Storage に保存することをおすすめします。一方、構造化データであっても、Parquet や ORC などの OSS 形式のものにアクセスする必要がある場合には、Google Cloud Storage に保存することができます。
Google Cloud では、BigQuery Storage API として知られるデータレイク Storage API の構築に投資し、BigQuery と GCS の両方のストレージ層で構造化データ向けの一貫した機能を提供しています。この API により、ユーザーは Spark や Flink などの任意のオープンソース エンジンから BigQuery ストレージや GCS にアクセスできるようになります。Storage API では、BigQuery や GCS のストレージ内のデータにきめ細かなアクセス制御を行うことができます(近日公開予定)。
サーバーレス コンピューティング
データ レイクハウスは、データのサイロを解消し、データを一元化することで、組織全体のさまざまなユースケースを促進します。データから最大限の価値を得られるよう、Google Cloud では組織がワークロードやペルソナに応じて最適化された異なる実行エンジンを、同じデータ層で実行することが可能になっています。これが可能なのは、Google Cloud 上でコンピューティングとストレージを完全に分離しているからです。 SQL、Python、または GUI ベースの方法など、ユーザーのデータアクセス レベルに合わせて対応することで、技術的なスキルの制限を受けることなく、あらゆるジョブにデータを活用できます。データ サイエンティストは、従来の SQL ベースのツールや BI タイプのツールを使わずに仕事をすることがあります。BigQuery には Storage API があるので、AI ノートブックや Dataproc 上で動作する Spark、Spark サーバーレスなどのツールを簡単にワークフローに組み込むことができます。ここでのパラダイム シフトは、データを移動させるのではなく、データにコンピューティングをもたらすことをサポートするデータ レイクハウス アーキテクチャです。サーバーレス Spark と BigQuery があれば、データ エンジニアはコードやロジックにすべての時間を費やすことができます。クラスタの管理やインフラストラクチャの調整は必要ありません。SQL や PySpark のジョブを選択したインターフェースから送信すると、ジョブのニーズに合わせて処理側が自動スケーリングされます。
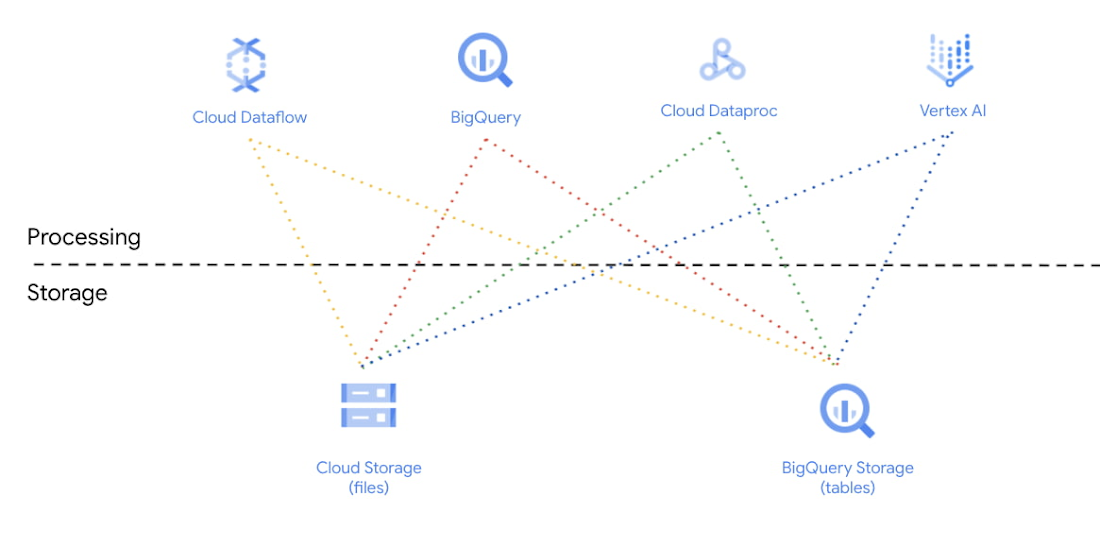
BigQuery ではサーバーレス アーキテクチャが採用されており、使い慣れた SQL インターフェースを使った大規模な分析が可能になっています。組織は BigQuery SQL を活用して、ペタバイト規模のデータセットで分析を行うことができます。さらに、BigQuery ML は、SQL 実務担当者が既存の SQL ツールやスキルを使ってモデルを構築することを可能にし、機械学習をより多くの人が利用できるようにします。慣れ親しんだ言語を使い、データの移動をなくすことでお客様の開発スピードが上がる好例と言えるでしょう。
Dataproc は Google Cloud のマネージド Hadoop です。レイクハウスのストレージである BigQuery や GCS から直接データを読み込んで計算を実行し、書き戻すことができます。実質的には、ユーザーのニーズやスキルに応じて、どこにどのようにデータを保存するか、どのように処理するかを自由に選択できるようになっています。Dataproc を使用すると、組織は Spark、Flink、Presto、Hive などの主要な OSS エンジンを活用できます。
Vertex AI は、企業が人工知能(AI)モデルのデプロイとメンテナンスを加速できるマネージド機械学習(ML)プラットフォームです。Vertex AI は、BigQuery Storage および GCS とネイティブに統合し、構造化データと非構造化データの両方を処理します。これにより、データ サイエンティストや ML エンジニアの専門知識レベルを問わず、機械学習オペレーション(MLOps)を導入することができるようになります。その結果、開発ライフサイクル全体を通して ML プロジェクトを効率的に構築し、管理できます。
インテリジェントなデータ マネジメントとガバナンス
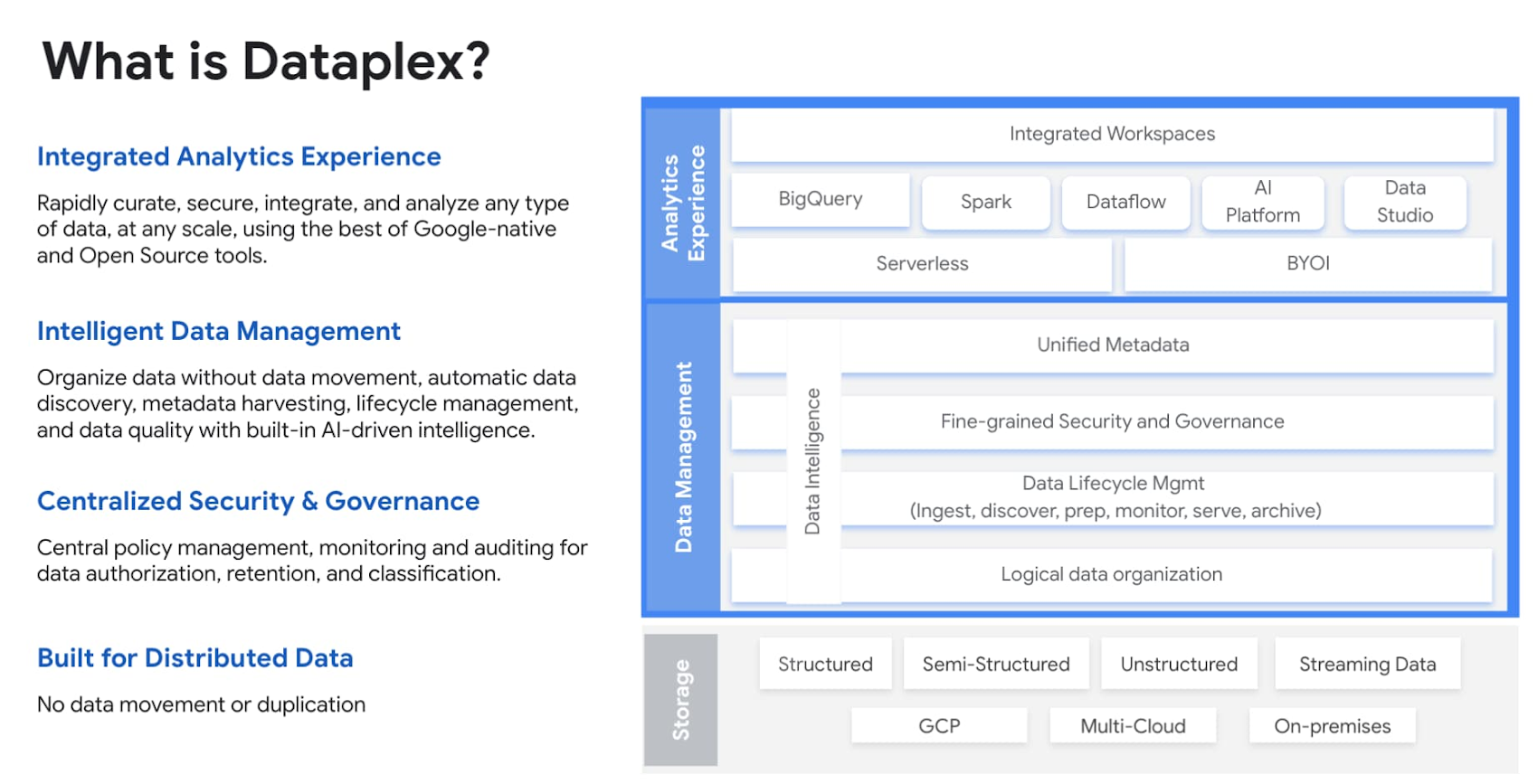
データ レイクハウスは、信頼できる単一の情報源にデータを保管してデータのコピーの作成を最小限にとどめる役割を果たします。また、セキュリティとガバナンスの一貫性はあらゆるレイクハウスにとって要となります。Google Cloud のインテリジェントなデータ ファブリック サービスである Dataplex は、GCS および BigQuery 上に構築されたさまざまなレイクハウス ストレージ層にデータ ガバナンスおよびセキュリティ機能を提供します。Dataplex は、基礎となるデータに関連するメタデータを使用して、データアセットをレイクやデータゾーンに論理的に整理します。この論理的な組織は、BigQuery と GCS に格納されたデータにまたがることができます。
Dataplex は、データスタック全体の上位に位置し、ガバナンスとデータ管理を統合します。統合されたデータ ファブリックが提供されることで、企業は統合された分析エクスペリエンスとともに、大規模なデータのキュレート、セキュリティ強化、管理をインテリジェントに行うことができます。Dataplex は異なるシステム間でのデータの検出とスキーマ推定を自動的に行い、メタデータをテーブルやファイルセットとしてメタストアに自動登録することでこれを補完します。Dataplex に組み込まれたデータ分類とデータ品質チェックにより、お客様は信頼できるデータにアクセスできます。
データの共有: 進化したデータレイクの主な利点の一つは、異なるチームや異なるペルソナが タイムリーに組織全体でデータを共有できることです。これを実現し、組織の壁を破るために、Google は Analytics Hubと呼ばれる BigQuery 上のレイヤを提供しています。Analytics Hub には、限定公開データ エクスチェンジを作成する機能があり、エクスチェンジの管理者(データ キュレーター)は、エクスチェンジ内のデータを社内およびビジネス パートナーやバイヤーなどの社外の特定の個人やグループに公開し、登録する権限を与えます(組織の内外を問いません)。
オープンかつ高い柔軟性
進化し続けるデータ アーキテクチャとエコシステムの世界では、データ管理、ガバナンス、スケーラビリティ、さらには機械学習を可能にする一連のツールの提供が増えています。
デジタル トランスフォーメーションと進化が期待される中、組織はしばしば、洗練されたソリューションにかなりの量の機能が付加されていることに気づきます。しかし、最終的な目標は、基盤となるインフラストラクチャを簡素化し、チームが本来の責任に集中できるようにすることです。データ エンジニアは元データを組織にとってより有用なものにし、データ サイエンティストはデータを探索して予測モデルを作成し、ビジネス ユーザーがそれぞれのドメインで正しい判断を下せるようにします。
Google Cloud は、オープン性、選択肢、シンプルさを重視したアプローチをとり、企業のデータ運用の中核をなす 2 つの要素であるデータレイクとデータ ウェアハウスを統合したデータ エコシステムを実現する、プラネットスケールの分析プラットフォームを提供しています。
データ レイクハウスは、このようなアーキテクチャの取り組みの集大成です。Google Cloud はお客様の組織でデータ レイクハウスを実現するために、お客様と協力できることを楽しみにしています。レイクハウスに関するより興味深い知見については、こちらのホワイトペーパー全文をご覧ください。
- データ アナリティクス プラクティス リード Dr. Firat Tekiner
- スマート アナリティクスおよび AI 担当ソリューション マネージャー Susan Pierce



