Open data lakehouse on Google Cloud
Firat Tekiner
Product Management
Susan Pierce
Senior Product Manager
Try Google Cloud
Start building on Google Cloud with $300 in free credits and 20+ always free products.
Free trialFor more than a decade the technology industry has been searching for optimal ways to store and analyze vast amounts of data that can handle the variety, volume, latency, resilience, and varying data access requirements demanded by organizations.
Historically, organizations have implemented siloed and separate architectures, data warehouses used to store structured aggregate data primarily used for BI and reporting whereas data lakes, used to store unstructured and semi-structured data, in large volumes, primarily used for ML workloads. This approach often resulted in extensive data movement, processing, and duplication requiring complex ETL pipelines. Operationalizing and governing this architecture was challenging, costly and reduced agility. As organizations are moving to the cloud they want to break these silos.
To address some of these issues, a new architecture choice has emerged: the data lakehouse, which combines key benefits of data lakes and data warehouses. This architecture offers low-cost storage in an open format accessible by a variety of processing engines like Spark while also providing powerful management and optimization features.
At Google cloud we believe in providing choice to our customers. Organizations that want to build their data lakehouse using open source technologies only can easily do so by using low cost object storage provided by Google Cloud Storage, storing data in open formats like Parquet, with processing engines like Spark and use frameworks like Delta, Iceberg or Hudi through Dataproc to enable transactions. This open source based solution is still evolving and requires a lot of effort in configuration, tuning and scaling.
At Google Cloud, we provide a cloud native, highly scalable and secure, data lakehouse solution that delivers choice and interoperability to customers. Our cloud native architecture reduces cost and improves efficiency for organizations. Our solution is based on:
Storage: Providing choice of storage across low cost object storage in Google Cloud Storage or highly optimized analytical storage in BigQuery
Compute: Serverless compute that provide different engines for different workloads
BigQuery, our serverless cloud data warehouse provides ANSI SQL compatible engine that can enable analytics on petabytes of data.
Dataproc, our managed Hadoop and Spark service enables using various open source frameworks
Serverless Spark, allows customers to submit their workloads to a managed service and take care of the job execution.
Vertex AI, our unified MLOps platform enables building large scale ML models with very limited coding
Additionally you can use many of our partner products like Databricks, Starburst or Elastic for various workloads.
- Management: Dataplex enables a metadata-led data management fabric across data in Google Cloud Storage (object storage) and BigQuery (highly optimized analytical storage). Organizations can create, manage, secure, organize and analyze data in the lakehouse using Dataplex.
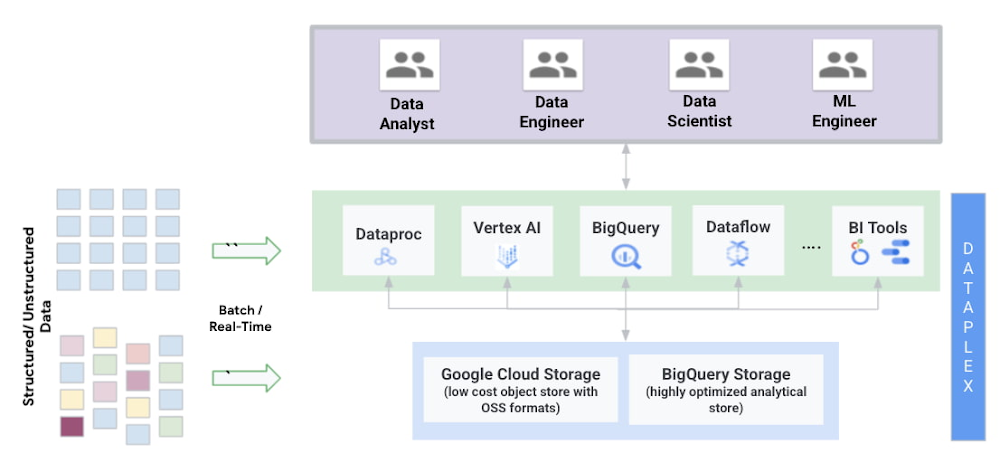
Let's take a closer look at some key characteristics of a data lakehouse architecture and how customers have been building this on GCP at scale.
Storage Optionality
At Google Cloud our core principle is delivering an open platform. We want to provide customers with a choice of storing their data in low cost object storage in Google Cloud Storage or highly optimized analytical storage or other storage options available on GCP. We recommend organizations store their structured data in BigQuery Storage. BigQuery Storage also provides a streaming API that enables organizations to ingest large amounts of data in real-time and analyze it. We recommend unstructured data to be stored in Google Cloud storage. In some cases where organizations need to access their structured data in OSS formats like Parquet or ORC they can store them on Google Cloud Storage.
At Google Cloud we have invested in building Data Lake Storage API also known as BigQuery Storage API to provide consistent capabilities for structured data across both BigQuery and GCS storage tiers. This API enables users to access BigQuery Storage and GCS through any open source engine like Spark, Flink etc. Storage API enables users to apply fine grained access control on data in BigQuery and GCS storage (coming soon).
Serverless Compute
The data lakehouse enables organizations to break data silos and centralize data, which facilitates various different types of use cases across organizations. To get maximum value from data, Google Cloud allows organizations to use different execution engines, optimized for different workloads and personas to run on top the same data tiers. This is made possible because of complete separation of compute and storage on Google Cloud. Meeting users at their level of data access including SQL, Python, or more GUI-based methods mean that technological skills do not limit their ability to use data for any job. Data scientists may be working outside traditional SQL-based or BI types of tools. Because BigQuery has the storage API, tools such as AI notebooks, Spark running on Dataproc, or Spark Serverless can easily be integrated into the workflow. The paradigm shift here is that the data lakehouse architecture supports bringing the compute to the data rather than moving the data around. With serverless Spark and BigQuery, data engineers can spend all their time on the code and logic. They do not need to manage clusters or tune infrastructure. They submit SQL or PySpark jobs from their interface of choice, and processing is auto-scaled to match the needs of the job.
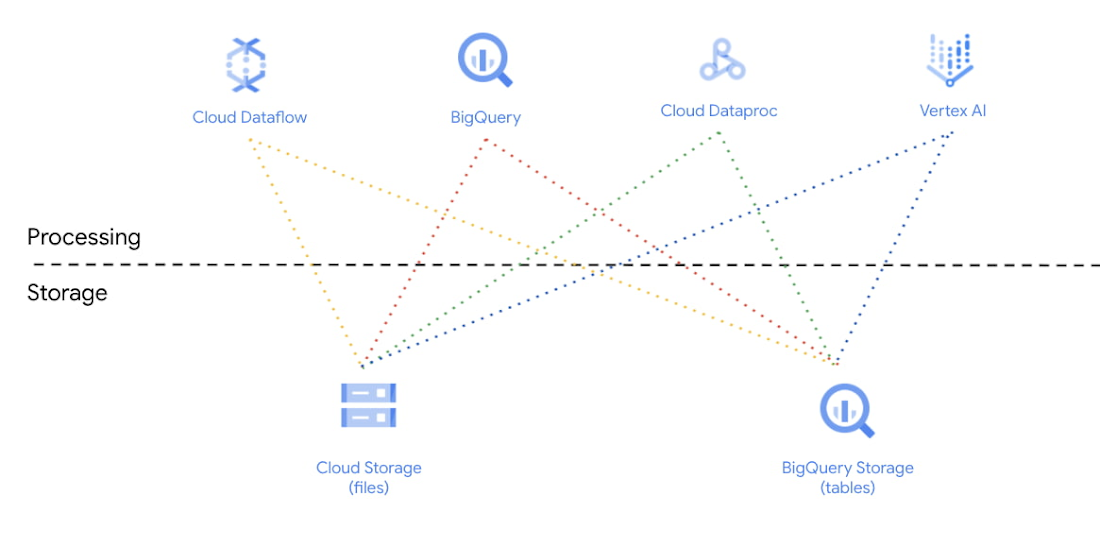
BigQuery leverages serverless architecture to enable organizations to run large scale analytics using a familiar SQL interface. Organizations can leverage BigQuery SQL to run analytics on petabyte scale data sets. In addition, BigQuery ML democratizes machine learning by letting SQL practitioners build models using existing SQL tools and skills. BigQuery ML is another example of how customers’ development speed can be increased by using familiar dialects and the need to move data.
Dataproc, Google Cloud’s managed Hadoop, can read the data directly from lakehouse storage; BigQuery or GCS and run its computations, and write it back. In effect, users are given freedom to choose where and how to store the data and how to process it depending on their needs and skills. Dataproc enables organizations to leverage all major OSS engines like Spark, Flink, Presto, Hive etc.
Vertex AI is a managed machine learning (ML) platform that allows companies to accelerate the deployment and maintenance of artificial intelligence (AI) models. Vertex AI natively integrates with BigQuery Storage and GCS to process both structured and unstructured data. It enables data scientists and ML engineers across all levels of expertise to implement Machine Learning Operations (MLOps) and thus efficiently build and manage ML projects throughout the entire development lifecycle.
Intelligent data management and governance
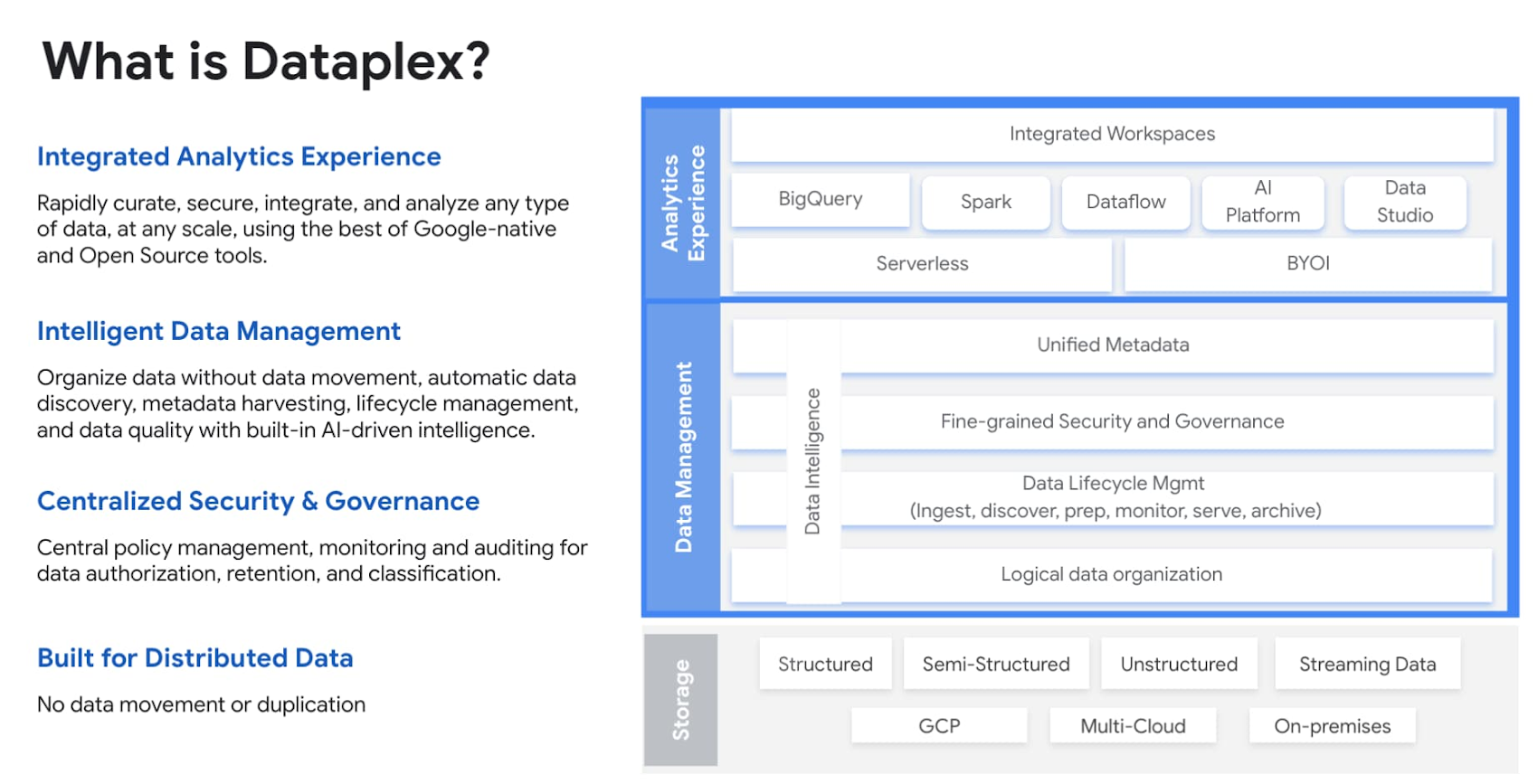
The data lakehouse works to store the data in a single-source-of-truth, making minimal copies of the data. Consistent security and governance is key to any lakehouse. Dataplex, our intelligent data fabric service, provides data governance and security capabilities across various lakehouse storage tiers built on GCS and BigQuery. Dataplex uses metadata associated with the underlying data to enable organizations to logically organize their data assets into lakes and data zones. This logical organization can span across data stored in BigQuery and GCS.
Dataplex sits on top of the entire data stack to unify governance and data management. It provides a unified data fabric that enables enterprises to intelligently curate,secure and govern data, at scale, with an integrated analytics experience. It provides automatic data discovery and schema inference across different systems and complements this with automatic registration of metadata as tables and filesets into metastores. With built-in data classification and data quality checks in Dataplex, customers have access to data they can trust.
Data sharing: is one of the key promises of evolved data lakes is that different teams and different personas can share the data across the organization in a timely manner. To make this a reality and break organizational barriers, Google offers a layer on top of BigQuery called Analytics Hub. Analytics Hub provides the ability to create private data exchanges, in which exchange administrators (a.k.a. data curators) give permissions to publish and subscribe to data in the exchange to specific individuals or groups both inside the company and externally to business partners or buyers. (within or outside of their organization).
Open and flexible
In the ever evolving world of data architectures and ecosystems, there are a growing suite of tools being offered to enable data management, governance, scalability, and even machine learning.
With promises of digital transformation and evolution, organizations often find themselves with sophisticated solutions that have a significant amount of bolted-on functionality. However, the ultimate goal should be to simplify the underlying infrastructure,and enable teams to focus on their core responsibilities: data engineers make raw data more useful to the organization, data scientists explore the data and produce predictive models so business users can make the right decision for their domains.
Google Cloud has taken an approach anchored on openness, choice and simplicity and offers a planet-scale analytics platform that brings together two of the core tenants of enterprise data operations, data lakes and data warehouses into a unified data ecosystem.
The data lakehouse is a culmination of this architectural effort and we look forward to working with you to enable it at your organization. For more interesting insights on lakehouse, you can read the full whitepaper here.

