Getting started with new table formats on Dataproc
Roderick Yao
Strategic Cloud Engineer, Google Cloud
Christopher Crosbie
Product Manager, Data Analytics
At Google Cloud, we’re always looking for ways to help you connect data sources and get the most out of the big data that your business gathers. Dataproc is a fully managed service for running Apache Hadoop ecosystem software such as Apache Hive, Apache Spark, and many more in the cloud. We’re announcing that table format projects Delta Lake and Apache Iceberg (Incubating) are now available in the latest version of Cloud Dataproc (version 1.5 Preview). You can start using them today with either Spark or Presto. Apache Hudi is also available on Dataproc 1.3.
With these table formats, you can now use Dataproc for workloads that need:
ACID transaction
Data versioning (a.k.a. time travel)
Schema enforcement
Schema evolution and more
In this blog, we will walk you through what table formats are, why they are useful, and how to use them on Dataproc with some examples.
Benefits of table formats
ACID transaction capability is very important to business operations. In the data warehouse, it is very common that users generate reports based on a common set of data. While building reports, there are other applications and users that might write to the same set of tables. Because Hadoop Distributed File System (HDFS) and object stores are designed to be like file systems, they are not providing transactional support. Implementing transactions in distributed processing environments is a challenging problem. For example, implementation typically has to consider locking access to the storage system, which comes at the cost of overall throughput performance. Table formats such as Apache Iceberg and Delta Lake solve these ACID requirements efficiently by pushing these transactional semantics and rules into the file formats themselves.
Another benefit of table formats is data versioning. This provides a snapshot of your data in history. You can look up data history and even roll back to the data at a certain time or version in history. It makes debugging and maintaining your data system much easier when there are mistakes or bad data.
Getting to know table formats
Most big data platforms store data as files or objects on the underlying storage systems. These files have certain structures and access protocols to represent a table of data (think of the Parquet file format, for example). As the size of these tables grow, they are divided up into multiple files. That allows tables that are bigger than the storage system limitations on a single file or object. This also allows you to filter unnecessary files based on data value (partitioning). And, you can have multiple writers at once. The way of organizing these files into tables is known as a table format.
Table formats on Google Cloud
As the modern data lake has started to merge with the modern data warehouse, the data lake has taken on responsibility for features previously reserved for the data warehouse.
A common scenario when building big data processing pipelines is to structure the unstructured data (log files, database backups, clickstream, etc.) into tables that can be used by the data analyst or data scientist. In the past, this often involved using a tool like Apache Sqoop to export the results of big data processing into a data warehouse or relational database system (RDBMS) to make it easier for data to be interpreted by the business. However, as tools like Spark and Presto have grown in terms of both features and adoption, the same data users now prefer the functionality offered by these data lake tools over the traditional data warehouse or SQL-only interface. However, because this data is necessary to the business, the storage expectations related to ACID transactions, schema evolution, etc. became a missing link.
In Google Cloud, BigQuery storage solves these problems and needs. You can access BigQuery storage with Spark using the Spark-BigQuery connector, and BigQuery storage is fully managed, with the maintenance and operations overhead taken care of by the Google engineering team.
In addition to BigQuery storage, Dataproc customers using Cloud Storage have had many of these same table-like features that solve for some of the basic warehousing use cases. For example, Cloud Storage is strongly consistent at the object level. And starting with version 2.0 of the Cloud Storage Connector for Hadoop, cooperative locking is supported for directory modification operations performed though the Hadoop file system shell (hadoop fs command) and other HCFS API interfaces to Cloud Storage.
However, in the open source community, Delta Lake and Apache Iceberg (Incubating) are two solutions that approximate traditional data warehouses in functionality. Apache Hudi (Incubating) is another solution to this problem that also provides a way to accommodate incremental data. While these file formats will involve some do-it-yourself operations, you can gain a lot of flexibility and portability using these open source file formats.
The start of table formats in OSS Big Data: Apache Hive
An intuitive way of organizing files as a table is using a directory structure. For example, a directory represents a table. Each of its subdirectories can be named based on partition values. Each of these subdirectories contains other subpartitions or data files. This is basically how Apache Hive manages data.
A component separate but related to Hive, the Hive Metastore keeps track of this table and partition information. However, as Hive data warehouses increased in data size and moved to the cloud, the Hive approach to table formats started to expose its limitations. To name just a few:
Hive requires a listing operation to find its data. It is expensive on object stores.
The structure of Hive data storage is against the best practices of object store structure, which prefers data evenly distributed to avoid hot-spotting.
Reading a table that is being written to can lead to the wrong result.
Adding and dropping partitions directly on HDFS breaks atomicity and table statistics, which could lead to wrong results.
Users have to know a table’s physical layout (partition columns) to write efficient queries. Changes to layout break user queries.
To solve the limitations of existing table formats, the open source community has come up with table formats. Let’s see how to run them on Google Cloud.
Running Apache Iceberg on Google Cloud
Apache Iceberg is an open table format for huge analytic datasets. Iceberg adds tables to Presto and Spark that use a high-performance format that works just like a SQL table. In addition to the new features listed above, Iceberg also added hidden partitioning. It abstracts the partitioning of a table by defining the relationship between the partition column and actual partition value. So changing table partitioning will not break user queries. Iceberg also provides a series of optimizations such as advanced filtering based on column statistics and other metrics, avoiding listing and renaming files, isolation and concurrent writing.
Iceberg works very well with Dataproc. Iceberg uses a pointer to the latest version of a snapshot and needs a mechanism to ensure the atomicity when switching versions. Iceberg provides two options to track tables:
Hive catalog—uses the Hive catalog and Hive Metastore to keep track of tables
Hadoop tables—tracks tables by maintaining a pointer on Cloud Storage
Hive catalog tables rely on Hive Metastore to provide atomicity when switching pointers. Hadoop tables rely on a file system such as HDFS that provides atomic renaming operation.
When using in Cloud Dataproc, Iceberg can utilize the Hive Metastore, which is backed by the Cloud SQL database.
Using Iceberg with Spark
To get started, create a Cloud Dataproc cluster with the newest 1.5 image. After the cluster is created, SSH to the cluster and run Apache Spark.
Now, you can get started by creating an Iceberg table on Cloud Storage using Hive Catalog. First, start spark-shell and tell it to use a Cloud Storage bucket to store data:
Use the Hive catalog to create a table and write some data:
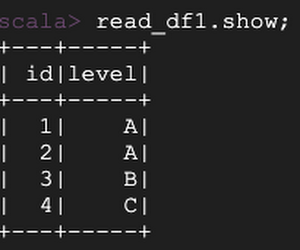
Now, change the table schema by adding another column named “count”:
Let’s add more data and see how it handles schema evolution:
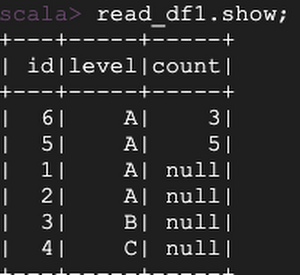
You can look at the table history:

You can also look into the valid snapshots, manifest files, and data files:
Let’s say we made a mistake by adding the row with value of id=6 and want to go back to see a correct version of the table using time travel:
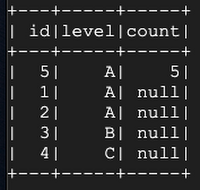
Running Delta Lake on Google Cloud
Delta Lake focuses on bringing RDBMS-like features to Spark. In addition to the features such as ACID transactions, time travel, and schema evolution, Delta Lake also provides the ability to delete, update, and upsert data.
Delta Lake writes data files in the Parquet format on the storage system. Tables can be registered either using path or using Hive Metastore. On the metadata side, similar to Iceberg, Delta Lake manages table metadata in files on the storage system. Delta Lake uses a transaction log mechanism to make sure that there is a single source of truth for the system and to implement atomicity.
Delta Lake breaks down user operations such as DELETE into a few actions such as add file or update metadata. Delta Lake then writes these actions into the transaction log in order as commits. Each commit will result in a JSON file under the _delta_log subdirectory under the table directory.
Working with Cloud Storage
Delta Lake stores transaction logs on object store when running on cloud. To ensure atomicity of the commit, writing to the transaction log needs to be atomic. Delta Lake relies on the storage system to provide that. In fact, it requires a few characteristics from storage:
Atomic visibility of files: Any file written through this store must be made visible atomically. In other words, this should not generate partial files.
Mutual exclusion: Only one writer must be able to create (or rename) a file at the final destination.
Consistent listing: Once a file has been written in a directory, all future listings for that directory must return that file.
Some object stores on other cloud providers do not provide a consistent listing, which could lead to data loss. So, in some cases Delta Lake only allows one single Spark session to write to the transaction log on the object store at a time. For the same reason, Delta Lake also disallows multiple writers, further limiting the concurrency and throughput of Delta Lake.
Cloud Storage allows multiple writers to the transaction log and guarantees consistency , allowing you to use Delta Lake to its full potential.
Delta Lake by default uses HDFS as the transaction log store. You can easily use Cloud Storage to store your transaction log by pointing your table to a location on Cloud Storage using the format of gs://<bucket-name>/<your-table>.
Use Delta Lake with Spark
To get started, create a Dataproc cluster with the newest 1.5 image. After the cluster is created, SSH to the cluster and run Apache Spark.
Now, you can get started by creating a Delta Lake table on Cloud Storage. First, start spark-shell and tell it to use a Cloud Storage bucket to store data:
Let’s create a Delta Lake table on Cloud Storage:
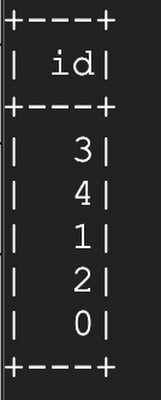
Next, overwrite the original data. Then, use time travel to see the earlier version:

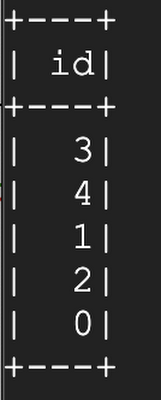
Inspect table history:
Update:
Vacuum/delete older snapshots:
Running Apache Hudi on Google Cloud
At the moment, Hudi can only run on Dataproc 1.3 version because of open issues like supporting Scala 2.12 and upgrading Avro library. You can get started with Apache Hudi using the following steps:After the Spark shell starts, use the quick start tutorial from Hudi. The example inside the quick start uses the file system. But you can simply point the file system to use Cloud Storage by starting with the following code:
Get in touch with the Dataproc team anytime.
Special thanks to Ryan Blue, who led the development of Apache Iceberg, for reviewing this blog.

