New release of Cloud Storage Connector for Hadoop: Improving performance, throughput and more
Igor Dvorzhak
Software Engineer
Sameer Farooqui
Cloud Data Engineer
We're pleased to announce a new version of the Cloud Storage Connector for Hadoop (also known as GCS Connector), which makes it even easier to substitute your Hadoop Distributed File System (HDFS) with Cloud Storage. This new release can give you increased throughput efficiency for columnar file formats such as Parquet and ORC, isolation for Cloud Storage directory modifications, and overall big data workload performance improvements, like lower latency, increased parallelization, and intelligent defaults.
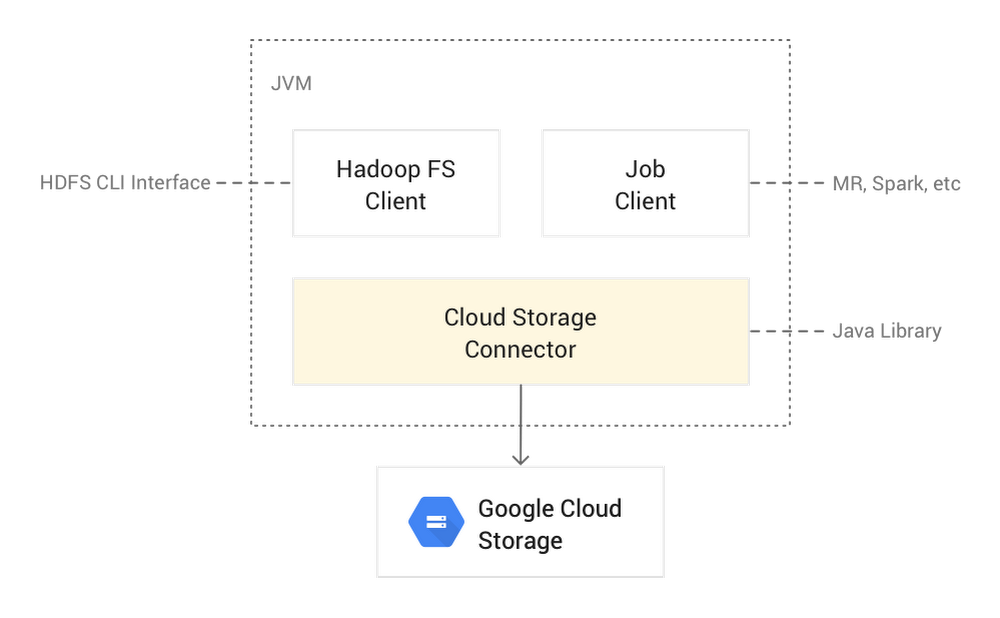
The Cloud Storage Connector is an open source Java client library that runs in Hadoop JVMs (like data nodes, mappers, reducers, Spark executors, and more) and allows your workloads to access Cloud Storage. The connector lets your big data open source software [such as Hadoop and Spark jobs, or the Hadoop Compatible File System (HCFS) CLI] read/write data directly to Cloud Storage, instead of to HDFS. Storing data in Cloud Storage has several benefits over HDFS:
Significant cost reduction as compared to a long-running HDFS cluster with three replicas on persistent disks;
Separation of storage from compute, allowing you to grow each layer independently;
Persisting the storage even after Hadoop clusters are terminated;
Sharing Cloud Storage buckets between ephemeral Hadoop clusters;
No storage administration overhead, like managing upgrades and high availability for HDFS.
The Cloud Storage Connector’s source code is completely open source and is supported by Google Cloud Platform (GCP). The connector comes pre-configured in Cloud Dataproc, GCP’s managed Hadoop and Spark offering. However, it is also easily installed and fully supported for use in other Hadoop distributions such as MapR, Cloudera, and Hortonworks. This makes it easy to migrate on-prem HDFS data to the cloud or burst workloads to GCP.
The open source aspect of the Cloud Storage Connector allowed Twitter’s engineering team to closely collaborate with us on the design, implementation, and productionizing of the fadvise and cooperative locking features at petabyte scale.
Cloud Storage Connector architecture
Here’s a look at what the Cloud Storage Connector architecture looks like:
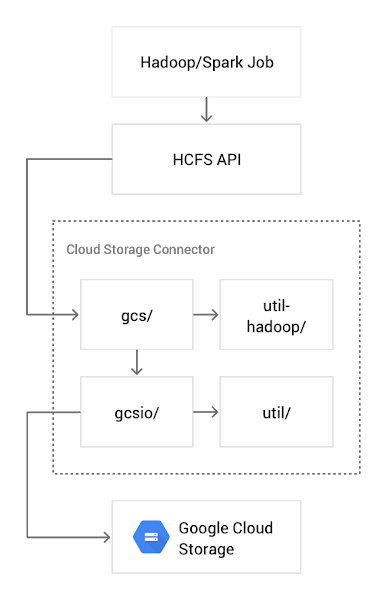
Cloud Storage Connector is an open source Apache 2.0 implementation of an HCFS interface for Cloud Storage. Architecturally, it is composed of four major components:
gcs—implementation of the Hadoop Distributed File System and input/output channels
util-hadoop—common (authentication, authorization) Hadoop-related functionality shared with other Hadoop connectors
gcsio—high-level abstraction of Cloud Storage JSON API
util—utility functions (error handling, HTTP transport configuration, etc.) used by gcs and gcsio components
In the following sections, we highlight a few of the major features in this new release of Cloud Storage Connector. For a full list of settings and how to use them, check out the newly published Configuration Properties and gcs-core-default.xml settings pages.
Here are the key new features of the Cloud Storage Connector:
Improved performance for Parquet and ORC columnar formats
As part of Twitter’s migration of Hadoop to Google Cloud, in mid-2018 Twitter started testing big data SQL queries against columnar files in Cloud Storage at massive scale, against a 20+ PB dataset. Since the Cloud Storage Connector is open source, Twitter prototyped the use of range requests to read only the columns required by the query engine, which increased read efficiency. We incorporated that work into a more generalized fadvise feature.
In previous versions of the Cloud Storage Connector, reads were optimized for MapReduce-style workloads, where all data in a file was processed sequentially. However, modern columnar file formats such as Parquet or ORC are designed to support predicate pushdown, allowing the big data engine to intelligently read only the chunks of the file (columns) that are needed to process the query. The Cloud Storage Connector now fully supports predicate pushdown, and only reads the bytes requested by the compute layer. This is done by introducing a technique known as fadvise.
You may already be familiar with the fadvise feature in Linux. Fadvise allows applications to provide a hint to the Linux kernel with the intended I/O access pattern, indicating how it intends to read a file, whether for sequential scans or random seeks. This lets the kernel choose appropriate read-ahead and caching techniques to increase throughput or reduce latency.
The new fadvise feature in Cloud Storage Connector implements a similar functionality and automatically detects (in default auto mode) whether the current big data application’s I/O access pattern is sequential or random.
In the default auto mode, fadvise starts by assuming a sequential read pattern, but then switches to random mode upon detection of a backward seek or long forward seek. These seeks are performed by the position() method call and can change the current channel position backward or forward. Any backward seek triggers the mode change to random; however, a forward seek needs to be greater than 8 MB (configurable via fs.gs.inputstream.inplace.seek.limit). The read pattern transition (from sequential to random) in fadvise’s auto mode is stateless and gets reset for each new file read session.
Fadvise can be configured via the gcs-core-default.xml file with the fs.gs.inputstream.fadvise parameter:
AUTO (default), also called adaptive range reads—In this mode, the connector starts in SEQUENTIAL mode, but switches to RANDOM as soon as the first backward or forward read is detected that’s greater than
fs.gs.inputstream.inplace.seek.limitbytes (8 MiB by default).RANDOM—The connector will send bounded range requests to Cloud Storage; Cloud Storage read-ahead will be disabled.
SEQUENTIAL—The connector will send a single, unbounded streaming request to Cloud Storage to read an object from a specified position sequentially.
In most use cases, the default setting of AUTO should be sufficient. It dynamically adjusts the mode for each file read. However, you can hard-set the mode.
Ideal use cases for fadvise in RANDOM mode include:
SQL (Spark SQL, Presto, Hive, etc.) queries into columnar file formats (Parquet, ORC, etc.) in Cloud Storage
Random lookups by a database system (HBase, Cassandra, etc.) to storage files (HFile, SSTables) in Cloud Storage
Ideal use cases for fadvise in SEQUENTIAL mode include:
Traditional MapReduce jobs that scan entire files sequentially
DistCp file transfers
Cooperative locking: Isolation for Cloud Storage directory modifications
Another major addition to Cloud Storage Connector is cooperative locking, which isolates directory modification operations performed through the Hadoop file system shell (hadoop fs command) and other HCFS API interfaces to Cloud Storage.
Although Cloud Storage is strongly consistent at the object level, it does not natively support directory semantics. For example, what should happen if two users issue conflicting commands (delete vs. rename) to the same directory? In HDFS, such directory operations are atomic and consistent. So Joep Rottinghuis, leading the @TwitterHadoop team, worked with us to implement cooperative locking in Cloud Storage Connector. This feature prevents data inconsistencies during conflicting directory operations to Cloud Storage, facilitates recovery of any failed directory operations, and simplifies operational migration from HDFS to Cloud Storage.
With cooperative locking, concurrent directory modifications that could interfere with each other, like a user deleting a directory while another user is trying to rename it, are safeguarded. Cooperative locking also supports recovery of failed directory modifications (where a JVM might have crashed mid-operation), via the FSCK command, which can resume or roll back the incomplete operation.
With this cooperative locking feature, you can now perform isolated directory modification operations, using the hadoop fs commands as you normally would to move or delete a folder:
To recover failed directory modification operations performed with enabled Cooperative Locking, use the included FSCK tool:
This command will recover (roll back or roll forward) all failed directory modification operations, based on the operation log.
The cooperative locking feature is intended to be used by human operators when modifying Cloud Storage directories through the hadoop fs interface. Since the underlying Cloud Storage system does not support locking, this feature should be used cautiously for use cases beyond directory modifications. (such as when a MapReduce or Spark job modifies a directory).
Cooperative locking is disabled by default. To enable it, either set fs.gs.cooperative.locking.enable Hadoop property to true in core-site.xml:
or specify it directly in your hadoop fs command:
How cooperative locking works
Here’s what a directory move with cooperative locking looks like:
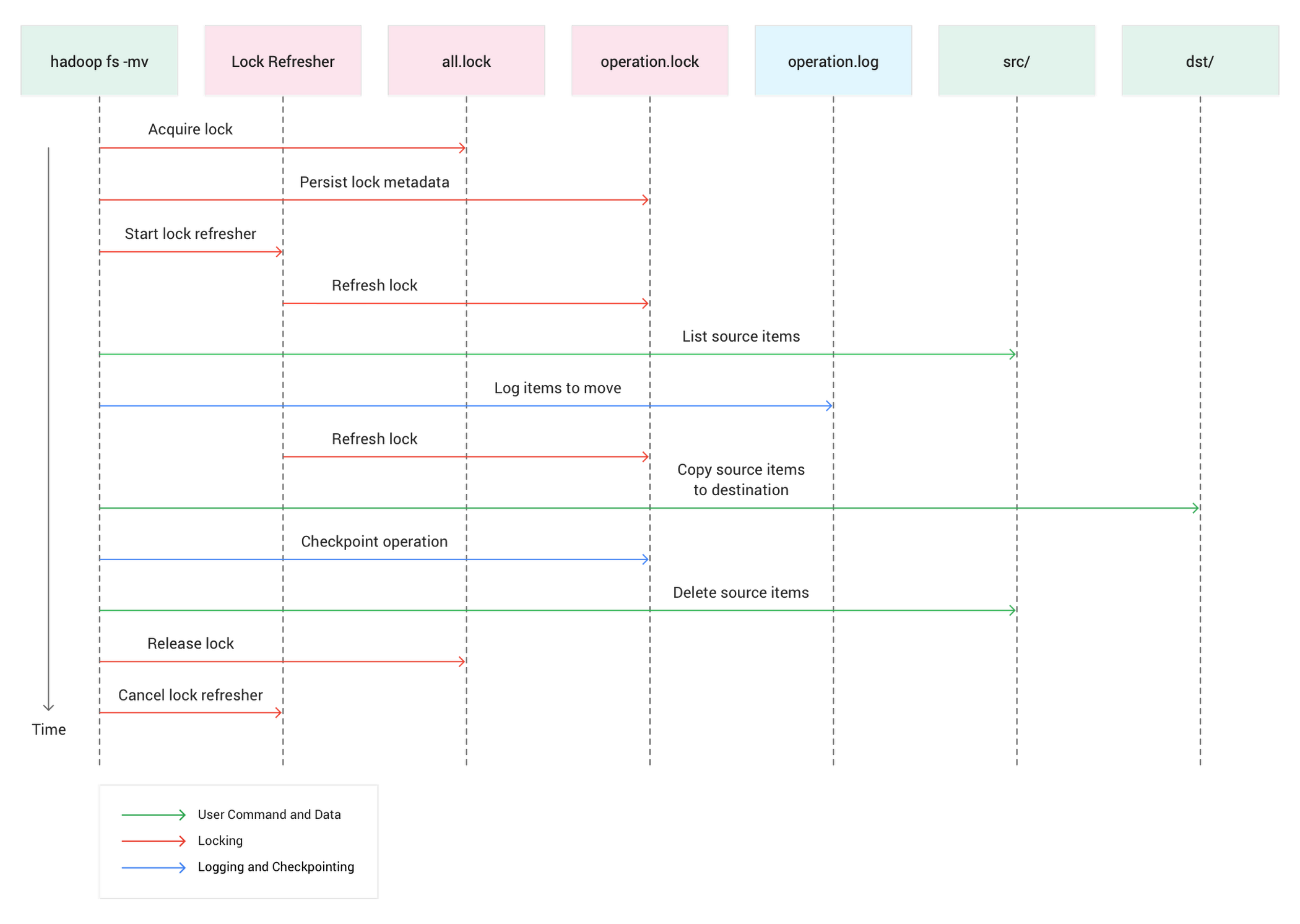
Cooperative Locking is implemented via atomic lock acquisition in the lock file (_lock/all.lock) using Cloud Storage preconditions. Before each directory modification operation, the Cloud Storage Connector atomically acquires a lock in this bucket-wide lock file.
Additional operational metadata is stored in *.lock and *.log files in the _lock directory at the root of the Cloud Storage bucket. Operational files (a list of files to modify) are stored in a per-operation *.log file and additional lock metadata in per-operation *.lock file. This per-operation lock file is used for lock renewal and checkpointing operation progress.
The acquired lock will automatically expire if it is not periodically renewed by the client. The timeout interval can be modified via the fs.gs.cooperative.locking.expiration.timeout.ms setting.
Cooperative locking supports isolation of directory modification operations only in the same Cloud Storage bucket, and does not support directory moves across buckets.
Note: Cooperative locking is a Cloud Storage Connector feature, and it is not implemented by gsutil, Object Lifecycle Management or applications directly using the Cloud Storage API.
General performance improvements to Cloud Storage Connector
In addition to the above features, there are many other performance improvements and optimizations in this Cloud Storage Connector release. For example:
Directory modification parallelization, in addition to using batch request, the Cloud Storage Connector executes Cloud Storage batches in parallel, reducing the rename time for a directory with 32,000 files from 15 minutes to 1 minute, 30 seconds.
Latency optimizations by decreasing the necessary Cloud Storage requests for high-level Hadoop file system operations.
Concurrent glob algorithms (regular and flat glob) execution to yield the best performance for all use cases (deep and broad file trees).
Repair implicit directories during delete and rename operations instead of list and glob operations, reducing latency of expensive list and glob operations, and eliminating the need for write permissions for read requests.
Cloud Storage read consistency to allow requests of the same Cloud Storage object version, preventing reading of different object versions and improving performance.
You can upgrade to the new version of Cloud Storage Connector using the connectors initialization action for existing Cloud Dataproc versions. It will become standard starting in Cloud Dataproc version 2.0.
Thanks to contributors to the design and development of the new release of Cloud Storage Connector, in no particular order: Joep Rottinghuis, Lohit Vijayarenu, Hao Luo and Yaliang Wang from the Twitter engineering team.

