How to connect Cloudera’s CDH to Cloud Storage
Roderick Yao
Strategic Cloud Engineer, Google Cloud
If you are running CDH, Cloudera’s distribution of Hadoop, we aim to provide you with first-class integration on Google Cloud so you can run a CDH cluster with Cloud Storage integration.
In this post, we’ll help you get started deploying the Cloud Storage connector for your CDH clusters. The methods and steps we discuss here will apply to both on-premise clusters and cloud-based clusters. Keep in mind that the Cloud Storage connector uses Java, so you’ll want to make sure that the appropriate Java 8 packages are installed on your CDH cluster. Java 8 should come pre-configured as your default Java Development Kit.
[Check out this post if you’re deciding how and when to use Cloud Storage over the Hadoop Distributed File System (HDFS).]
Here’s how to get started:
Distribute using the Cloudera parcel
If you’re running a large Hadoop cluster or more than one cluster, it can be hard to deploy libraries and configure Hadoop services to use those libraries without making mistakes. Fortunately, Cloudera Manager provides a way to install packages with parcels. A parcel is a binary distribution format that consists of a gzipped (compressed) tar archive file with metadata.
We recommend using the CDH parcel to install the Cloud Storage connector. There are some big advantages of using a parcel instead of manual deployment and configuration to deploy the Cloud Storage connector on your Hadoop cluster:
Self-contained distribution: All related libraries, scripts and metadata are packaged into a single parcel file. You can host it at an internal location that is accessible to the cluster or even upload it directly to the Cloudera Manager node.
No need for sudo access or root: The parcel is not deployed under /usr or any of the system directories. Cloudera Manager will deploy it through agents, which eliminates the need to use sudo access users or root user to deploy.
Create your own Cloud Storage connector parcel
To create the parcel for your clusters, download and use this script. You can do this on any machine with access to the internet.
This script will execute the following actions:
Download Cloud Storage connector to a local drive
Package the connector Java Archive (JAR) file into a parcel
Place the parcel under the Cloudera Manager’s parcel repo directory
If you’re connecting an on-premise CDH cluster or cluster on a cloud provider other than Google Cloud Platform (GCP), follow the instructions from this page to create a service account and download its JSON key file.
Create the Cloud Storage parcel
Next, you’ll want to run the script to create the parcel file and checksum file and let Cloudera Manager find it with the following steps:
1. Place the service account JSON key file and the create_parcel.sh script under the same directory. Make sure that there are no other files under this directory.
2. Run the script, which will look something like this: $ ./create_parcel.sh -f <parcel_name> -v <version> -o <os_distro_suffix>
- parcel_name is the name of the parcel in a single string format without any spaces or special characters. (i.e.,, gcsconnector)
- version is the version of the parcel in the format x.x.x (ex: 1.0.0)
- os_distro_suffix: Like the naming conventions of RPM or deb, parcels need to be named in a similar way. A full list of possible distribution suffixes can be found here.
- d is a flag you can use to deploy the parcel to the Cloudera Manager parcel repo folder. It’s optional; if not provided, the parcel file will be created in the same directory where the script ran.
Distribute and activate the parcel
Once you’ve created the Cloud Storage parcel, Cloudera Manager has to recognize the parcel and install it on the cluster.
The script you ran generated a .parcel file and a .parcel.sha checksum file. Put these two files on the Cloudera Manager node under directory /opt/cloudera/parcel-repo. If you already host Cloudera parcels somewhere, you can just place these files there and add an entry in the manifest.json file.
On the Cloudera Manager interface, go to Hosts -> Parcels and click Check for New Parcels to refresh the list to load any new parcels. The Cloud Storage connector parcel should show up like this:
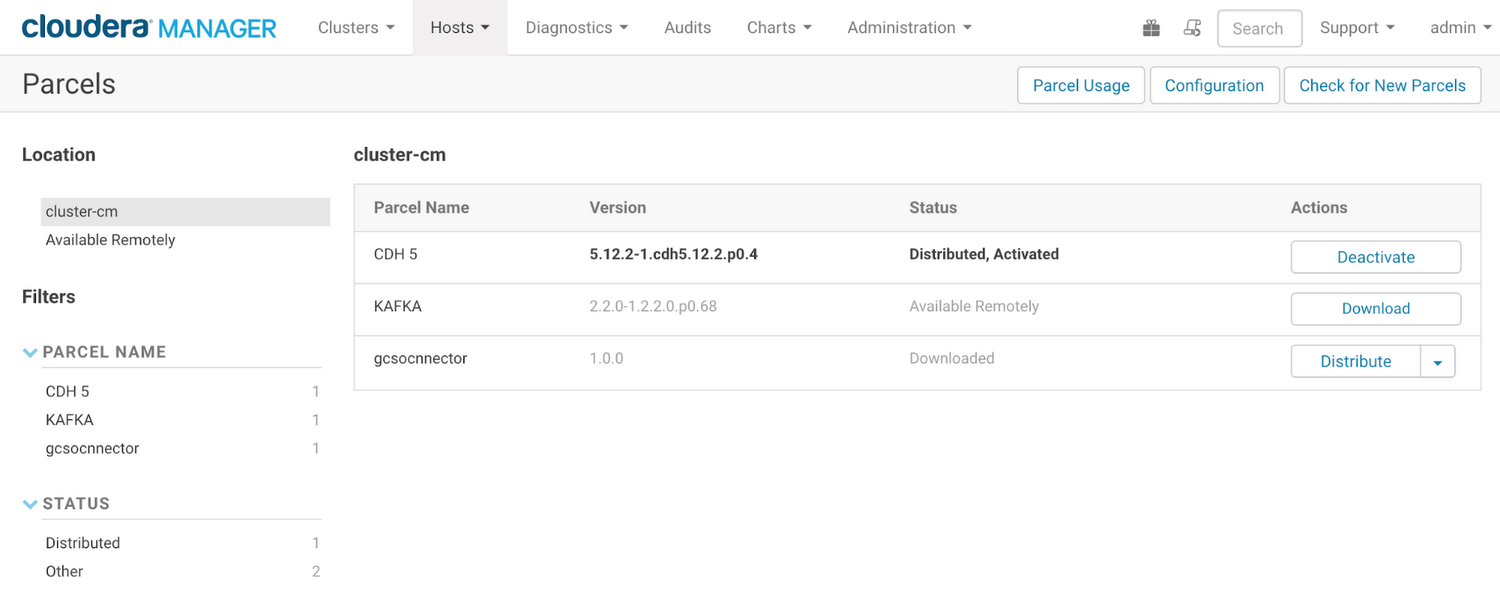
3. On the Actions column of the new parcel, click Distribute. Cloudera Manager will start distributing the Cloud Storage connector.
4. JAR file to every node in the cluster.
When distribution is finished, click Activate to enable the parcel.
Configure CDH clusters to use the Cloud Storage connector
After the Cloud Storage connector is distributed on the cluster, you’ll need to do a few additional configuration steps to let the cluster use the connector. These steps will be different depending on whether you’re using HDFS or Spark for your Hadoop jobs.
Configuration for the HDFS service
1. From the Cloudera Manager UI, click HDFS service > Configurations. In the search bar, type core-site.xml. In the box titled “Cluster-wide Advanced Configuration Snippet (Safety Valve) for core-site.xml,” add the following properties:
2. Click Save configurations > Restart required services.
3. Export Hadoop classpath to point to the Cloud Storage connector JAR file, as shown here:
4. Run the “hdfs dfs - ls” command pointing to the bucket the service account has access to:
Configuration for the Spark service
In order to let Spark recognize the Cloud Storage path, you have to let Spark load the connector JAR. Here is how to configure it:
1. From the Cloudera Manager home page, go to Spark > Configuration > Spark Service Advanced Configuration Snippet (Safety Valve) for spark-conf/spark-env.sh. Add the configuration according to the Cloud Storage connector JAR path.
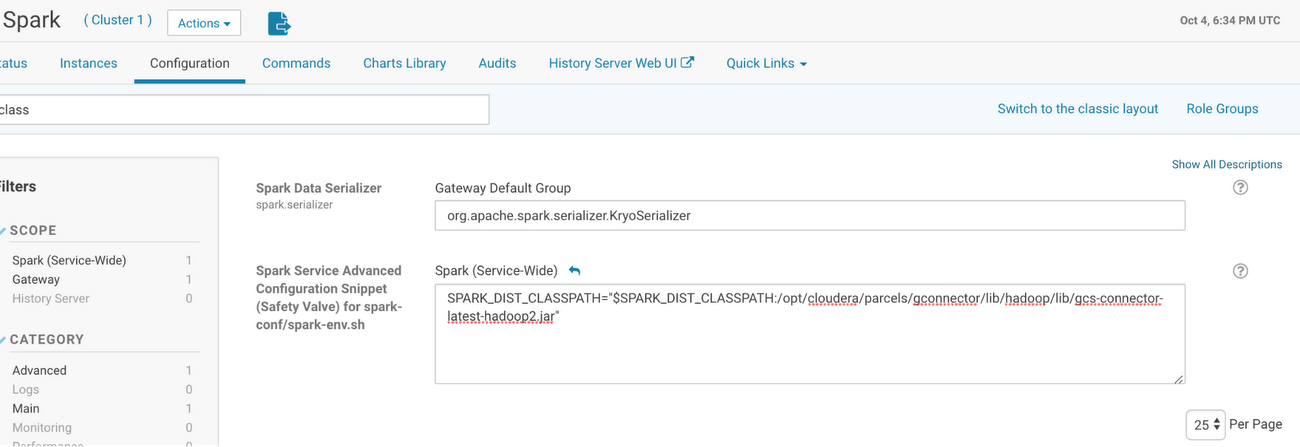
2. Next, use Cloudera Manager to deploy the configuration and restart the service if necessary.
3. Open Spark shell to validate that you can access Cloud Storage using Spark.
Configuration for the Hive service
If you also need to store Hive table data in Cloud Storage, configure Hive to load the connector JAR file with the following steps:
1. From Cloudera Manager home page, go to Hive Service > Configuration, search “Hive Auxiliary JARs Directory” and enter the path to the Cloud Storage connector JAR, as shown here:
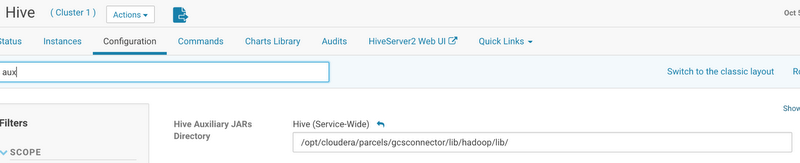
2. Validate if the JAR is being accepted by accessing the Hive CLI. Note that the IP address and the result may be different here from your screen:

That’s it! You’ve now connected Cloudera’s CDH to Google Cloud Storage, so you can store and access your data on Cloud Storage with high performance and scalability. Learn more here about running these workloads on Google Cloud.


