Dataproc の新しいテーブル形式を使ってみる
Google Cloud Japan Team
※この投稿は米国時間 2020 年 1 月 4 日に、Google Cloud blog に投稿されたものの抄訳です。
Google Cloud は常に、企業がデータソースを接続し、業務で集めたビッグデータを最大限に活用できるようにするための支援策を模索しています。Dataproc は、Apache Hive、Apache Spark を含む多数の Apache Hadoop エコシステム ソフトウェアをクラウドで実行するためのフルマネージド サービスです。テーブル形式のプロジェクトである Delta Lake と Apache Iceberg(Incubating)を、Cloud Dataproc(バージョン 1.5 プレビュー)で利用できるようになりました。すぐに Spark や Presto でご利用いただけます。Apache Hudi は Dataproc 1.3 でもご利用になれます。
これらのテーブル形式なら、次を必要とするワークロードで Dataproc を活用できます。
ACID トランザクション
データ バージョニング(別名: タイムトラベル)
スキーマ適用
スキーマの進化など
このブログでは、いくつかの例を示しながら、テーブル形式とは何か、テーブル形式が役立つ理由、Dataproc での使用方法について説明します。
テーブル形式の利点
ACID トランザクションは、ビジネス オペレーションにとって非常に重要な機能です。データ ウェアハウスでは、ユーザーが共通のデータセットに基づいてレポートを生成するということがごく一般的に行われています。レポートの作成中、同じテーブルセットに対して他のアプリケーションやユーザーが書き込みを行う可能性があります。Hadoop 分散ファイル システム(HDFS)とオブジェクト ストアは、ファイル システムのように設計されているため、トランザクション サポートを提供していません。分散処理環境にトランザクションを実装することは困難です。たとえば、通常の実装ではストレージ システムへのアクセスロックを検討する必要がありますが、その場合は全体的なスループット パフォーマンスが低下します。Apache Iceberg や Delta Lake などのテーブル形式は、トランザクションのセマンティクスとルールをファイル形式自体に push することにより、ACID の要件を効率的に解決します。
テーブル形式のもう 1 つの利点は、データ バージョニングです。つまり、データのスナップショットが履歴から取得できるようになります。データ履歴の検索のほか、特定の時刻や履歴のバージョンのデータにロールバックすることもできます。ミスや不正なデータがある場合は、データシステムのデバッグや保守も一段と簡単になります。
テーブル形式について
大半のビッグデータ プラットフォームは、データをファイルやオブジェクトとして基盤となるストレージ システムに保存します。保存されるファイルには、データのテーブルを表す特定の構造とアクセス プロトコルが含まれます(Parquet ファイル形式などがその例です)。サイズが大きいテーブルは複数のファイルに分割されます。こうすることで、単一のファイルやオブジェクトのストレージ システムに指定された制限よりも大きいテーブルを使用できます。また、データ値に基づいて不要なファイルをフィルタ(パーティショニング)することもできます。一度に複数の書き込みも可能です。これらのファイルをテーブルに整理する方法が、テーブル形式と呼ばれます。
Google Cloud のテーブル形式
最新のデータ ウェアハウスに最新のデータレイクが統合され始めたことにより、以前はデータ ウェアハウス用に予約されていた機能をデータレイクが提供するようになりました。
ビッグデータ処理パイプラインを構築する一般的なシナリオは、非構造化データ(ログファイル、データベース バックアップ、クリックストリームなど)を、データ アナリストやデータ サイエンティストが使用できるテーブルに構造化することです。これまでは、Apache Sqoop などのツールを使用して、ビッグデータ処理の結果をデータ ウェアハウスやリレーショナル データベース システム(RDBMS)にエクスポートし、データを解釈しやすくする必要がありました。しかし、Spark や Presto のようなツールが機能と導入の両方の面で拡大したため、同じデータを扱うユーザー層は、従来のデータ ウェアハウスや SQL に特化したインターフェースよりも、こうしたデータレイク ツールが提供する機能を好むようになりました。一方で、データがビジネスに不可欠であることに変わりはないため、ACID トランザクションやスキーマの進化といったストレージの理想は、実現には程遠い状態にあります。
Google Cloud では、BigQuery ストレージでこれらの問題とニーズを解決します。たとえば、Spark で BigQuery ストレージにアクセスする際には、Spark-BigQuery コネクタをご利用になれます。BigQuery ストレージは、Google のエンジニアリング チームがメンテナンスと運用のオーバーヘッドに対応するためのフルマネージド サービスです。
BigQuery ストレージに加えて、Cloud Storage をご利用の Dataproc のお客様は、いくつかの基本的なウェアハウジングのユースケースの解決に、テーブルに似た同様の機能を採用しています。たとえば、Cloud Storage はオブジェクト レベルでの一貫性が非常に高く、Hadoop 対応の Cloud Storage Connector バージョン 2.0 以降は、Cloud Storage に Hadoop ファイル システムシェル(hadoop fs コマンド)と他の HCFS API インターフェース経由で実行される、ディレクトリ変更操作への協調的ロック機能をサポートしています。
しかしながら、オープンソース コミュニティにおいては、Delta Lake と Apache Iceberg(Incubating)の 2 つは、機能面で従来のデータ ウェアハウスに近いソリューションと位置付けられています。Apache Hudi(Incubating)は、増分データにも対応するもう 1 つのソリューションです。これらのファイル形式のご利用にはある程度の操作が伴いますが、オープンソースのファイル形式を使用すると、柔軟性とポータビリティが大幅に向上します。
OSS ビッグデータのテーブル形式のスタート ポイント: Apache Hive
ファイルをテーブルとして整理する直感的な方法は、ディレクトリ構造を使用することです。たとえば、ディレクトリはテーブルを表します。それぞれのサブディレクトリには、パーティション値に基づく名前を付けることができます。各サブディレクトリには、他のサブパーティションやデータファイルが含まれます。これが Apache Hive がデータを管理する基本的な方法です。
Hive に関連する個別のコンポーネントである Hive メタストアは、このテーブルとパーティションの情報を追跡します。しかし、Hive データ ウェアハウスのデータサイズの増加と、クラウドへの移行に伴って、テーブル形式に対する Hive のアプローチには限界があることが表面化してきました。いくつかの例を挙げてみましょう。
Hive でのデータ検索には一覧表示が必要ですが、オブジェクト ストアに対する操作の負荷が高くなります。
Hive データ ストレージの構造は、オブジェクト ストア構造のベスト プラクティスとは相反するものです。このベスト プラクティスでは、ホットスポットを回避するためにデータを均等に分散します。
書き込み中のテーブルを読み取ると、誤った結果になる可能性があります。
HDFS でパーティションを直接追加または削除すると、アトミック性とテーブル統計が壊され、誤った結果が出てしまう可能性があります。
効率的なクエリを作成するには、テーブルの物理レイアウト(パーティション列)を知っている必要があります。レイアウトを変更すると、ユーザークエリが中断されます。
既存のテーブル形式が抱える制限を解決するために、オープンソース コミュニティがテーブル形式を考案しました。Google Cloud でこのテーブル形式を実行する方法を見てみましょう。
Google Cloud での Apache Iceberg の実行
Apache Iceberg は、巨大な分析データセット向けのオープンなテーブル形式です。Iceberg は、高性能な形式を使用して SQL テーブルのように機能するテーブルを Presto と Spark に追加します。上記の新機能に加えて、Iceberg では隠しパーティションも追加されました。パーティション列と実際のパーティション値の関係を定義することで、テーブルのパーティションを抽象化します。したがって、テーブルのパーティションを変更しても、ユーザーのクエリが中断されることはありません。
列統計やその他の指標に基づく高度なフィルタ、ファイルの一覧表示と名前変更の回避、分離と同時書き込みなど、一連の最適化機能も提供されます。
Iceberg は Dataproc との相性がよく、最新バージョンのスナップショットへのポインタを使用し、バージョンの切り替え時にアトミック性を保証するメカニズムを必要とします。Iceberg でのテーブルの追跡には 2 つのオプションがあります。
Hive カタログ - Hive カタログと Hive メタストアを使用してテーブルを追跡します
Hadoop テーブル - Cloud Storage のポインタを維持することでテーブルを追跡します
Hive カタログ テーブルは Hive メタストアを活用して、ポインタの切り替え時にアトミック性を確保します。Hadoop テーブルは、アトミックな名前変更操作を提供する HDFS などのファイル システムを活用しています。
Cloud Dataproc で使用する場合、Iceberg は Cloud SQL データベースを基盤とする Hive メタストアを利用できます。
Spark での Iceberg の使用
まず、最新のイメージ バージョン 1.5 で Cloud Dataproc クラスタを作成します。クラスタが作成されたら、そのクラスタに SSH で接続し、Apache Spark を実行します。
これで、Hive カタログを使用して Cloud Storage に Iceberg テーブルを作成できるようになります。まず、spark-shell を起動し、Cloud Storage バケットを使用してデータを保存します。
Hive カタログを使用してテーブルを作成し、データを書き込みます。
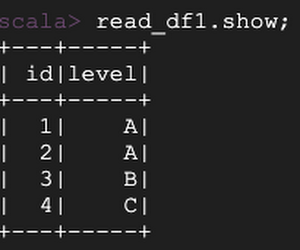
次に、「count」という名前の別の列を追加して、テーブル スキーマを変更します。
さらにデータを追加して、スキーマの進化がどのように処理されるかを見てみましょう。
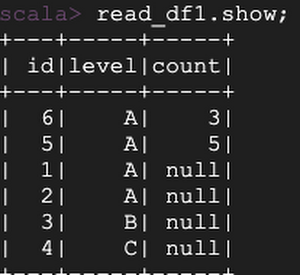
テーブルの履歴を確認できます。

有効なスナップショット、マニフェスト ファイル、データファイルを調べることもできます。
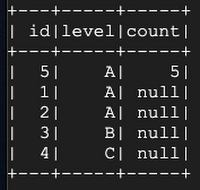
誤って id = 6 の値を持つ行を追加してしまったため、タイムトラベルを使用してテーブルの正しいバージョンを表示したい、というケースを考えてみましょう。
Google Cloud での Delta Lake の実行
Delta Lake は、RDBMS のような機能を Spark に実装することに焦点を当てています。ACID トランザクション、タイムトラベル、スキーマの進化などの機能のほか、データを削除、更新、アップサート(更新または挿入)する機能も提供します。
Delta Lake は、ストレージ システムに Parquet 形式でデータファイルを書き込みます。テーブルは、パスを使用するか、Hive メタストアを使用して登録できます。メタデータ側では Iceberg と同様に、ストレージ システム上のファイルのテーブル メタデータを管理します。Delta Lake は、トランザクション ログ メカニズムを使用して、システムに信頼できる唯一の情報源があることを確認し、アトミック性を実装します。
Delta Lake は、DELETE などのユーザー操作を、ファイルの追加やメタデータの更新などのいくつかのアクションに分割します。その後、これらのアクションを commit として順番にトランザクション ログに書き込みます。commit ごとに、テーブル ディレクトリの下の _delta_log サブディレクトリの下に JSON ファイルが作成されます。
Cloud Storage の使用
クラウドで実行している場合、Delta Lake はトランザクション ログをオブジェクト ストアに保存します。commit のアトミック性を確保するには、トランザクション ログへの書き込みがアトミックである必要があります。Delta Lake はその実現にストレージ システムを活用します。そのため、ストレージにはいくつかの特性が求められます。
ファイルのアトミックな可視性: このストアを介して書き込まれたファイルは、アトミックに可視化する必要があります。言い換えれば、部分ファイルを生成すべきではありません。
相互排除: 最終宛先でファイルを作成(または名前を変更)できる書き込みは 1 つだけです。
整合性の高い一覧表示: ファイルがディレクトリに書き込まれると、そのディレクトリは以降のすべての一覧表示でそのファイルを返す必要があります。
他のクラウド プロバイダの一部のオブジェクト ストアでは、整合性の高い一覧表示を提供しないため、データ損失につながる可能性があります。そのため Delta Lake では、オブジェクト ストアのトランザクション ログに書き込むことができる Spark セッションを一度に 1 つのみに制限する場合があります。同じ理由で複数の書き込みを許可しないため、Delta Lake の同時実行とスループットがさらに制限されます。
Cloud Storage を使用すると、トランザクション ログへの複数の書き込みが可能で整合性が保証されるため、Delta Lake を最大限に活用できます。
Delta Lake はデフォルトで HDFS をトランザクション ログ ストアとして使用します。gs://<bucket-name>/<your-table> の形式を使用してテーブルが Cloud Storage の場所を参照するようにすれば、Cloud Storage を使ってトランザクション ログを簡単に保存できます。
Spark での Delta Lake の使用
まず、最新のイメージ バージョン 1.5 で Dataproc クラスタを作成します。クラスタが作成されたら、そのクラスタに SSH で接続し、Apache Spark を実行します。
これで、Cloud Storage に Delta Lake テーブルを作成できるようになります。まず、spark-shell を起動し、Cloud Storage バケットを使用してデータを保存します。
Cloud Storage に Delta Lake テーブルを作成してみましょう。
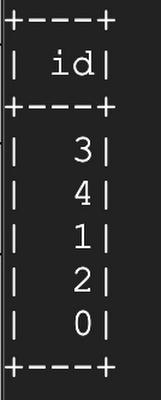
次に、元のデータを上書きします。その後、タイムトラベルを使用して以前のバージョンを確認します。

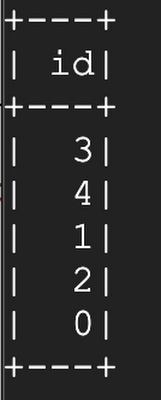
テーブル履歴を調べます。
更新します。
古いスナップショットを削除します。
Google Cloud での Apache Hudi の実行
Scala 2.12 のサポートや Avro ライブラリのアップグレードなどの未解決の問題があるため、現時点では Dataproc バージョン 1.3 でのみ Hudi を実行できます。次の手順で Apache Hudi の利用を開始できます。Spark シェルが起動したら、Hudi のクイックスタート チュートリアルを使用します。クイックスタートの例では、ファイル システムを使用していますが、次のコードから開始すれば、ファイル システムが Cloud Storage を使用するように指定できます。
ご不明な点がございましたら、いつでも Dataproc チームにお問い合わせください。
-By Roderick Yao, Strategic Cloud Engineer, Google Cloud and Christopher Crosbie, Product Manager, Google Cloud
このブログをレビューしていただいた Apache Iceberg の開発担当者、Ryan Blue 氏に感謝いたします。


