GKE: バッチ プラットフォームの新拠点
Google Cloud Japan Team
※この投稿は米国時間 2023 年 10 月 31 日に、Google Cloud blog に投稿されたものの抄訳です。
本日の投稿は、Google Kubernetes Engine(GKE)がバッチ処理プラットフォームの構築に適している理由を管理者やアーキテクト向けに解説するシリーズの第 1 回目となります。
Kubernetes は、コンテナ化アプリケーションのデプロイおよび管理を行うための最先端のコンテナ オーケストレーション プラットフォームとして登場し、イノベーションの推進に貢献してきました。このプラットフォームは、マイクロサービスの実行だけでなく、バッチ ワークロードのオーケストレーションにも強力なフレームワークとして威力を発揮します。たとえば、データ処理のジョブをはじめ、ML モデルのトレーニング、科学シミュレーションの実行や、コンピューティングの負荷が高い各種タスクに利用できます。GKE は、基盤インフラストラクチャを抽象化するためのマネージド Kubernetes ソリューションであり、ユーザーが費用対効果に優れた方法でスピーディに価値創出できるようにします。
バッチ プラットフォームは、Kubernetes Job として定義されるバッチ ワークロードを受信した順番で処理します。その際、キューを適宜使用しながら、ビジネスケースのロジックを適用します。
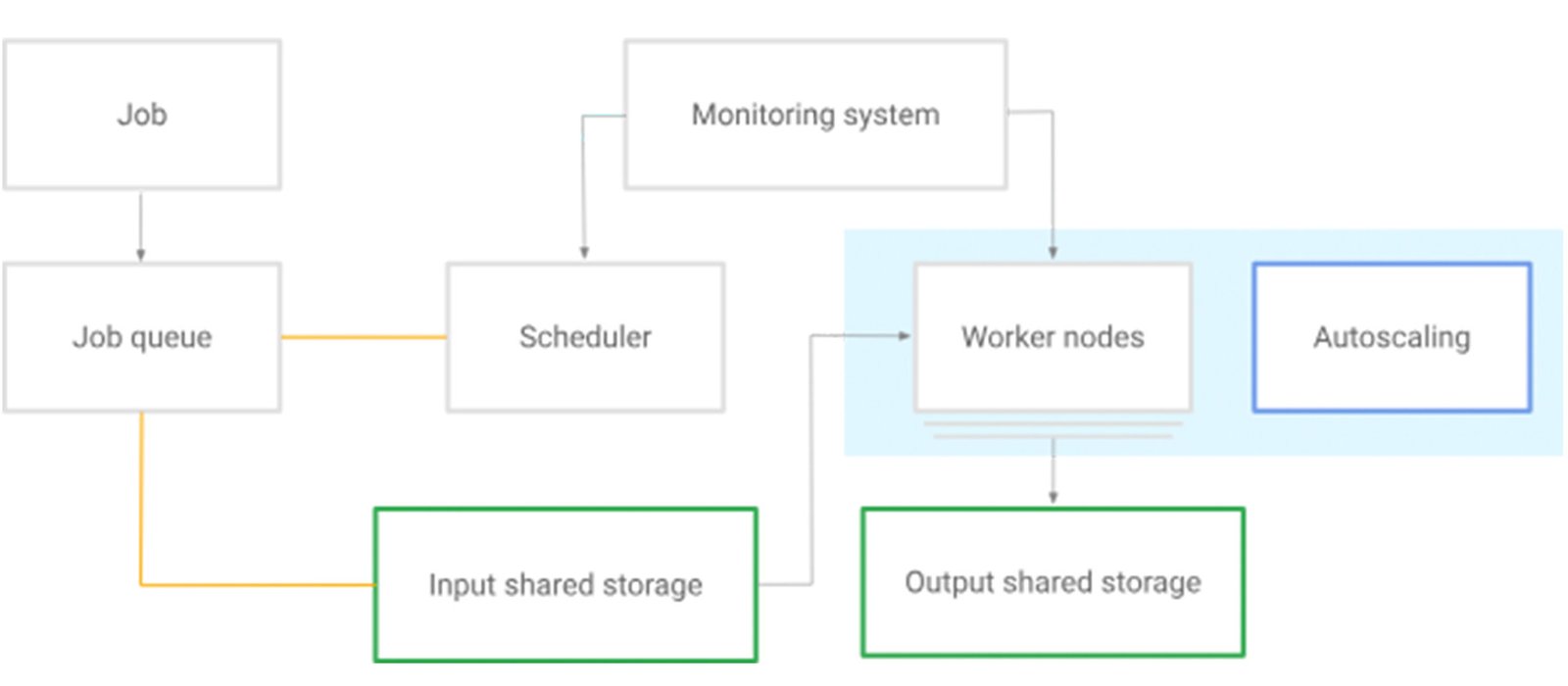
バッチ プラットフォームの主な Kubernetes リソースは、Job と Pod です。Job の管理には、Kubernetes Job API を使用します。Job は 1 つ以上の Pod を作成し、指定数の Pod が正常に終了するまで、これらの Pod の実行を試行し続けます。Pod が正常に完了すると、Job がそれをトラッキングします。正常な完了が指定数に達すると、Job(タスク)が完了したとみなされます。
GKE はマネージド Kubernetes ソリューションであり、複雑なインフラストラクチャおよびワークロード オーケストレーションを単純化します。では、GKE の機能と、バッチ プラットフォームの運用に適している点を詳しく見ていきましょう。
クラスタのアーキテクチャと利用可能なリソース
GKE 環境はノードで構成されます。ノードは Compute Engine 仮想マシン(VM)であり、グループ化されてクラスタを形成します。GKE を Autopilot モードで使用すると、クラスタの構成(ノード、スケーリング、セキュリティやその他の事前設定など)が自動管理されるため、お客様はワークロードに集中できます。Autopilot クラスタは、デフォルトで高可用性を備えています。
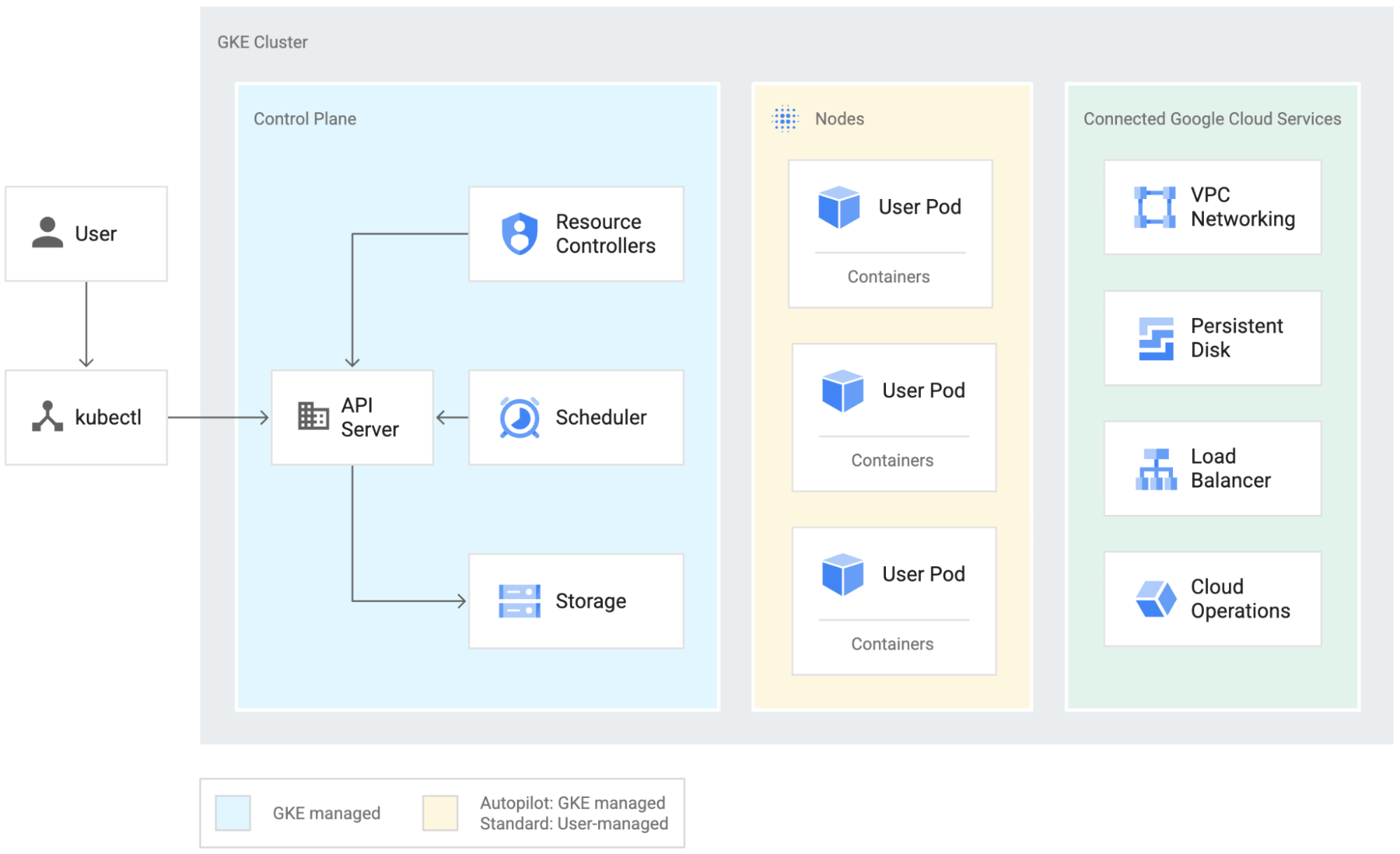
Google Cloud は、さまざまなワークロード向けに最適化した新しい VM シリーズやシェイプを継続的に追加しています。ご利用のワークロードで現在使用可能なオプションを確認するには、マシン ファミリーのリソースと比較ガイドをご覧ください。
スケーラビリティ
GKE は、マネージド プロバイダが現在提供しうる最大規模の Kubernetes クラスタをホストすることが可能です。多くのバッチ ユースケースにおいて鍵となるスケールは、クラスタにつき 15,000 ノードです(オープンソースの Kubernetes の場合は 5,000 ノード)。
たとえば、Bayer Crop Science のようなお客様は GKE のスケールを活用して 1 時間に約 150 億の遺伝子型を処理しているほか、PGS は GKE を使用して世界最大規模のスーパーコンピュータと同等のものを構築しました。GKE では、複数のノードプールを作成し、それぞれのノードプールに異なる VM のタイプ、シェイプやシリーズを使用して、さまざまな要件のワークロードを実行することが可能です。
マルチテナンシー
GKE のクラスタ マルチテナンシーは、多数の単一テナント クラスタを管理するのに代わる手段で、アクセス制御を目的としています。このモデルでは、「テナント」と呼ばれる複数のユーザーやワークロードによってマルチテナント クラスタが共有されます。これらのテナントは、名前空間によって分離可能です。つまり、個々のテナントおよびその Kubernetes リソースを、各自の名前空間に分けることができます。そのうえで、ポリシーを使って、テナントの強制分離や、API アクセスの制限、リソース使用量を制限する割り当ての設定、コンテナで実行できる処理の制限などを行えます。
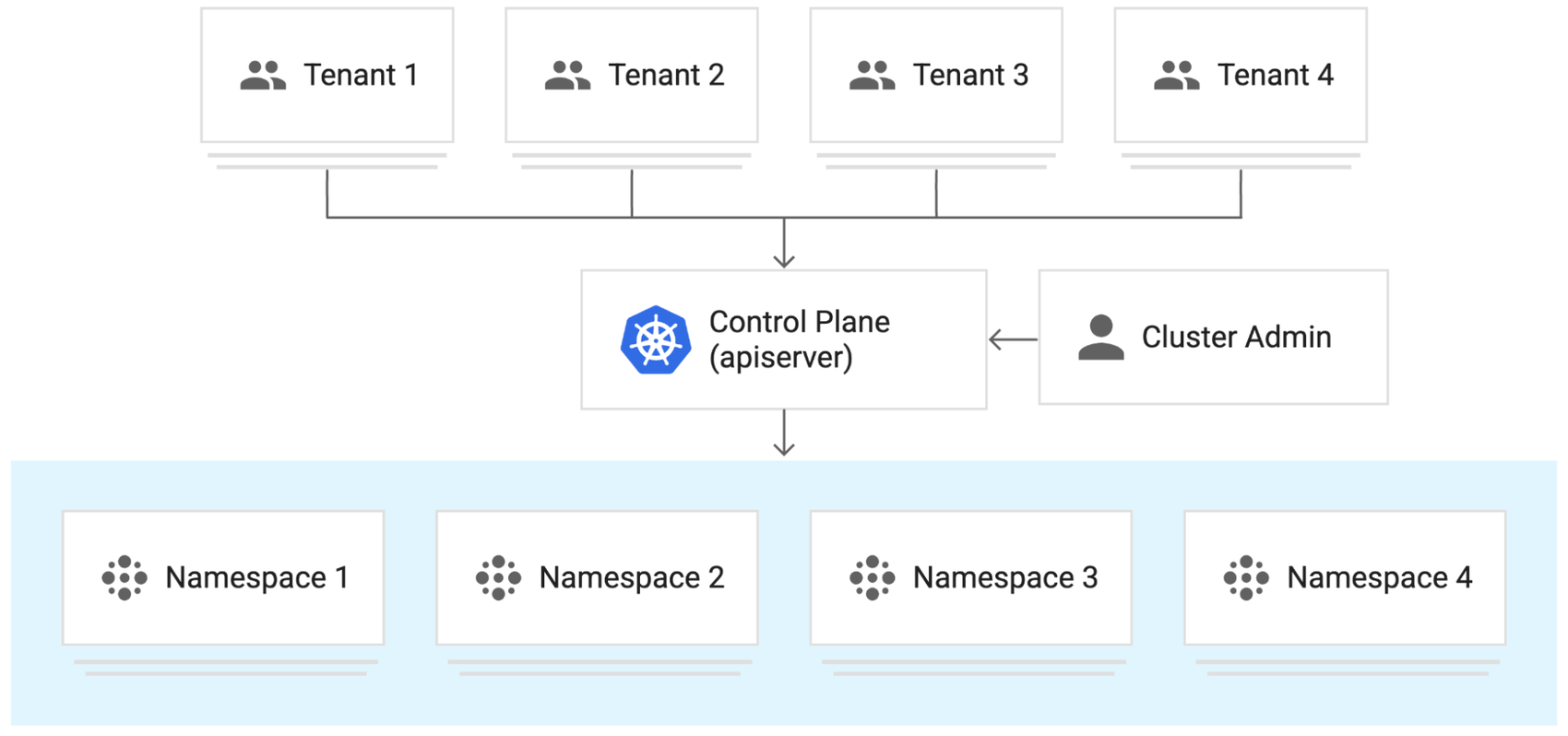
キューと「公平な共有」
管理者は、ワークロード送信元のテナント間で基盤クラスタのリソースを公平に共有するように、ポリシーを実装および構成できます。ここで、何をもって公平とするのかは、自由に定義できます。たとえば、ワークロードの最小要件に比例するリソース割り当て上限をテナントごとに割り当てるようにすれば、プラットフォーム上のすべてのテナントのワークロードにスペースを確保できます。または、利用可能なリソースがないときに受信したジョブはキューに追加して、受信した順番に処理するようにもできます。
Kueue は Kubernetes ネイティブのジョブ キューイング システムで、Kubernetes クラスタのバッチ処理、ハイ パフォーマンス コンピューティング、ML やこれらに類似する用途に使用できます。Kueue は、クラスタのリソースをテナント間で公平に共有するために、割り当ておよび各ジョブのリソース使用方法を管理します。たとえば、ジョブの待機や、開始登録(ポッドの作成)、プリエンプト(アクティブなポッドの削除)のタイミングを決定します。以下の図は、ユーザーがジョブを送信してから、Kueue がそのジョブを適切な nodeAffinity で登録するまでの流れや、Kubernetes がワークロードの処理をアクティベートする様子を示しています。
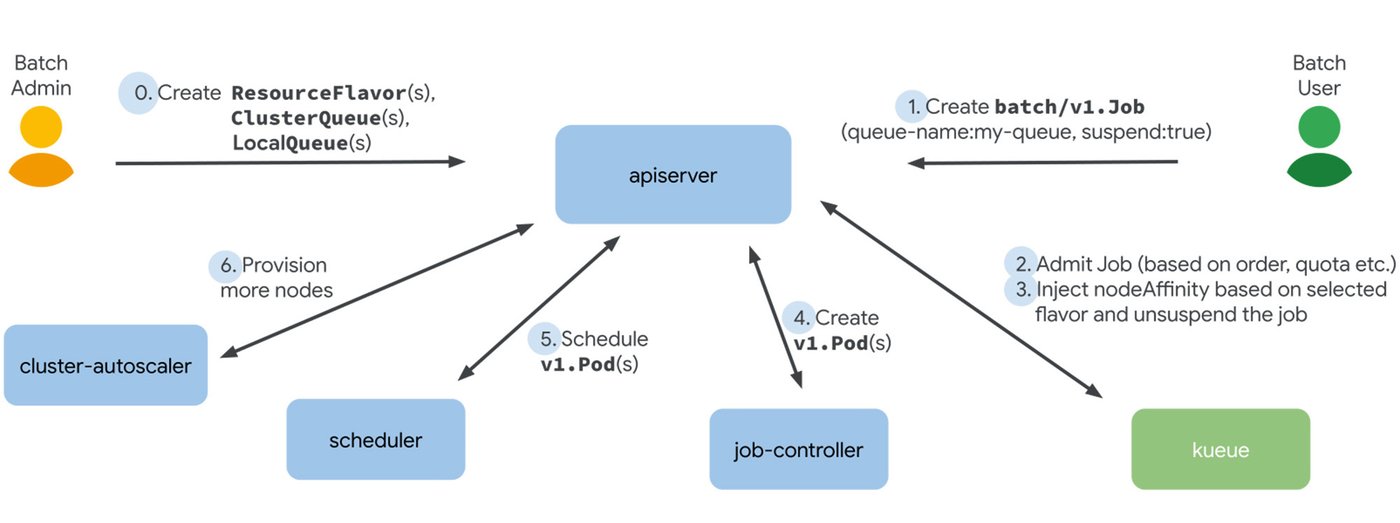
Kueue では、管理者によるバッチ処理動作の構成を支援するために、ClusterQueue などの概念を取り入れています。ClusterQueue は、CPU、メモリ、ハードウェア アクセラレータなどのリソースプールを制御するクラスタ スコープのオブジェクトで、コホートにグループ化できます。同じコホートに属する ClusterQueue は、未使用の割り当て量を互いに貸し借りでき、こうしたやりとりは ClusterQueue の BorrowingLimit を使って制御します。
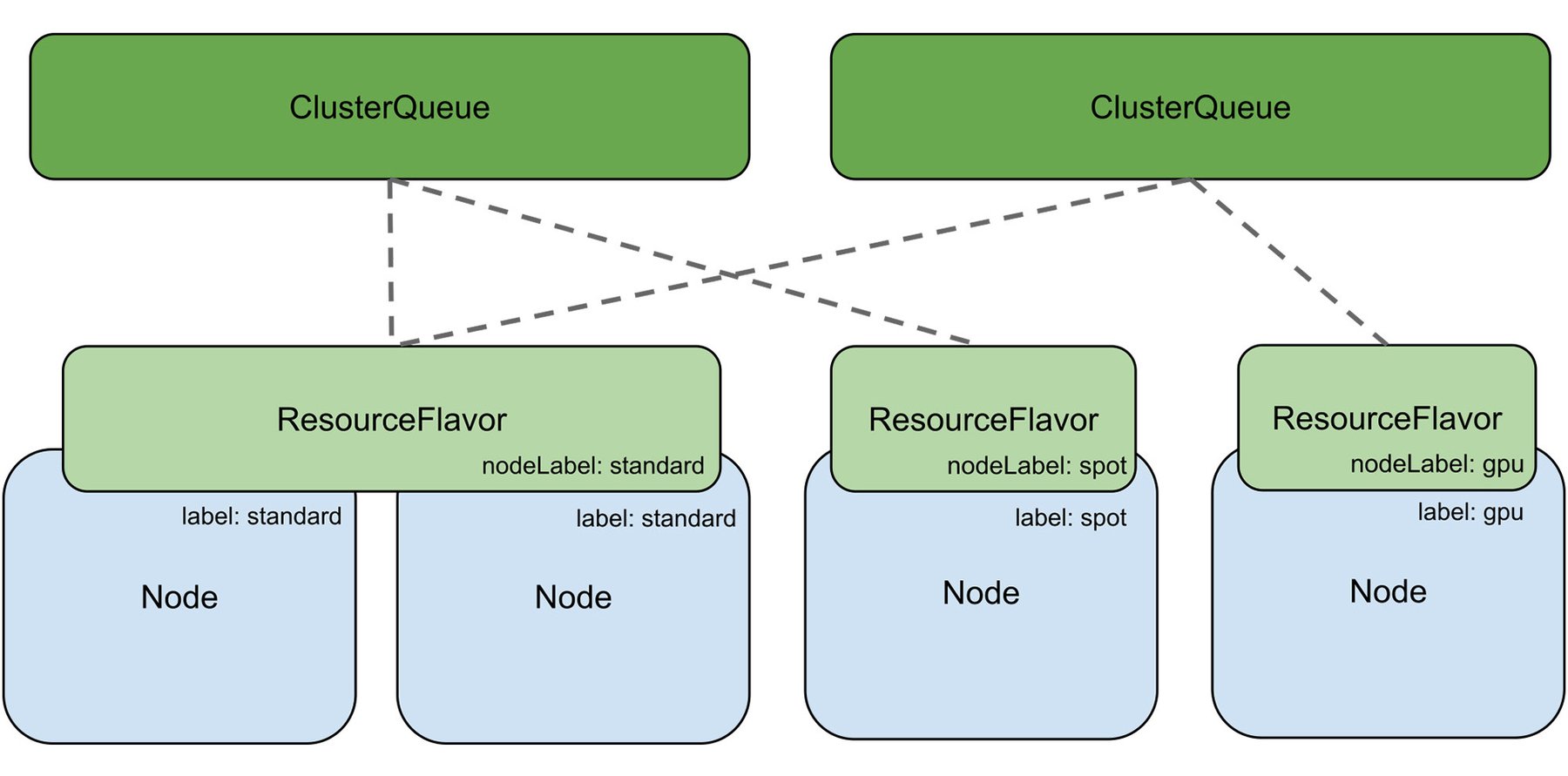
Kueue の ResourceFlavor はリソースのバリエーションを表すオブジェクトで、ラベルや taint を使ってクラスタノードに関連付けることができます。たとえば、1 つのクラスタ内に、CPU アーキテクチャ(x86、Arm など)やアクセラレータのブランドまたはモデル(Nvidia A100 や Nvidia T4 など)が異なるノードが混在しているとします。ResourceFlavor でこれらのリソースを表し、ClusterQueue でそれを参照しながら、リソースの割り当て上限を制御することが可能です。詳しくは、Kueue の概念をご覧ください。
ジョブ キューイング システムの実装方法や、GKE 上の異なる名前空間でワークロードのリソースや割り当て共有を構成する方法を学ぶには、こちらのチュートリアルをご覧ください。
信頼性の高いワークロードと費用最適化
コンピューティングおよびストレージ プラットフォームのリソースは、効率良く使用することが重要です。個々のバッチ処理の要件に応じてコンピューティング インスタンスのサイズを適正化して費用を削減しながら、パフォーマンスも犠牲になることのないよう、GKE のバッチ ワークロードでは Compute Engine 永続ディスクを使用できます。これは、耐久性の高いストレージを提供する永続ボリュームという仕組みによって実現されています。ワークロードのストレージやネットワーク構成などを最適化する方法について詳しくは、https://cloud.google.com/kubernetes-engine/docs/best-practices/batch-platform-on-gke#storage_performance_and_cost_efficiency をご覧ください。
オブザーバビリティ
GKE は Google Cloud のオペレーション スイートと統合されているため、GKE クラスタから Cloud Logging や Cloud Monitoring に送信するログや指標を制御できます。そのため、バッチユーザーは、ワークロード Pod から詳細な最新ログにアクセスしたり、Prometheus などのモニタリング システムを使ってワークロード固有の独自の指標を自由に書き込んだりできます。さらに、GKE は Managed Service for Prometheus もサポートしています。このサービスは、Google の世界規模の時系列データベースである Monarch を基盤としており、指標を簡単に収集できます。Prometheus サーバーのセットアップやメンテナンスの複雑さを回避するため、このマネージド収集を使用することをおすすめします。詳しくは、バッチ プラットフォームのモニタリングをご覧ください。
まとめ
GKE は、コンテナ化されたバッチ ワークロードの実行に最適なプラットフォームであり、高いスケーラビリティ、復元性、セキュリティ、費用対効果を実現します。組織の要件に応じて、人による操作が不要な Autopilot モードまたはきめ細かなカスタマイズが可能な Standard モードを選べます。Google Cloud サービスと密接に統合されているため、Compute Engine VM の全ファミリー、CPU、アクセラレータ アーキテクチャを利用できるのはもちろん、Kubernetes ネイティブのジョブ キューイング システム Kueue も使用できます。既存のバッチ ワークロードの新たな拠点として今すぐ GKE を導入して、大規模なコンピューティング プラットフォームの運用、マルチテナンシーの単純化、スケーリング、パフォーマンス、費用の最適化といったメリットをご活用ください。
バッチ プラットフォームの設計および実装方法について詳しくは、 GKE でバッチ ワークロードを実行するためのベスト プラクティス | Google Kubernetes Engine(GKE)をご覧ください。
ジョブ キューイング システムの実装方法や、GKE 上の異なる名前空間でワークロードのリソースや割り当て共有を構成する方法を学ぶには、こちらのチュートリアルをご覧ください。
ー Google Cloud、ソリューション アーキテクト Ali Zaidi
ー GKE プロダクト マネージャー Maciek Różacki



