Google Kubernetes Engine の GPU 共有によりニュートリノを探索する

Google Cloud Japan Team
※この投稿は米国時間 2022 年 7 月 20 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 今回は、南極でのギガトン規模の IceCube ニュートリノ観測所によるニュートリノの検出に Google Kubernetes Engines の GPU 共有がどのように役立っているか、サンディエゴ スーパーコンピュータ センター(SDSC)およびウィスコンシン大学マディソン校からお話を伺いました。
IceCube ニュートリノ観測所は南極にある検出器で、ニュートリノと呼ばれる質量がほぼゼロの素粒子を探索するために設置されました。ニュートリノは高エネルギーの宇宙のメッセンジャーで、超新星爆発、ガンマ線バースト、さらにブラックホールや中性子星などの激変的宇宙現象に関する情報を提供してくれます。IceCube は、収集したニュートリノに関するセンサーデータに科学的なコンピュータ シミュレーションを実行して、検出した宇宙事象の方角を特定するとともに解像度を向上させます。
IceCube シミュレーション ワークフローで計算が最も複雑な部分は光子の伝播コード(レイトレーシング)です。このコードを NVIDIA GPU で実行すると大きなメリットがあります。このアプリケーションは本質的に高スループットで、各光子のシミュレーションは独立して実行されます。南極のコアデータ取得システムを除く IceCube のほとんどの計算ニーズについては、世界中に散らばるさまざまな研究機関のコンピューティング リソースが利用されています。そしてそのほとんどで、統合基盤として Open Science Grid(OSG)インフラストラクチャが使用されています。
GPU リソースは、科学的リソースのプロバイダ コミュニティでは比較的不足しています。2021 年における OSG のインフラストラクチャの CPU コア時間は 1800M でしたが、GPU 時間はわずか 6M でした。そのため、利用可能なリソースプールをクラウド リソースで拡大することが強く望まれています。
最近、SDSC チームは OSG インフラストラクチャを拡張しました。これにより、Kubernetes マネージド リソースを効果的に使用して、Pacific Research Platform(PRP)における IceCube のコンピューティング ワークロードを補完しています。このサービスは、IceCube のバッチシステムのキューの深さに基づき水平 Pilot Pod 自動スケーリングを実行することにより、完全に自律した形で動的プロビジョニングを管理します。
オンプレミス システムと異なり、Google Cloud には弾力性(オンデマンド スケーリング)や高い費用対効果(従量課金制)というメリットがあります。私たちのコミュニティは、このようなメリットをもたらしてくれる柔軟なプラットフォームを必要としていました。そして、自動プロビジョニング、自動スケーリング、動的スケジューリング、オーケストレートされたメンテナンス、Job API、フォールト トレランスに対応し、さらには同じクラスタ内で最大 15,000 ノード(クラスタあたり)の多様なマシンタイプ(CPU と GPU、オンデマンドと Spot など)の連携もサポートされる Google Kubernetes Engine(GKE)が私たちのニーズに非常にマッチしていることがわかりました。
IceCube のレイトレーシング シミュレーションは GKE GPU でのコンピューティングに大きく助けられている一方で、コードの GPU 部分へのデータのフィードはまだ CPU コンピューティングに依存しています。そして、GPU は CPU 以上の速さで高速化しています。NVIDIA V100、A100 GPU の登場により、IceCube のコードは現在、多くの構成で CPU の制約を受けるようになりました。IceCube の複数のアプリケーション間で大きな GPU を共有すると IceCube レイトレーシング シミュレーションは再び GPU の制約を受けるようになり、同じハードウェアから得られるシミュレーション結果が大幅に増大しました。GKE はシンプルな GPU 時間共有とより高度な A100 マルチインスタンス GPU(MIG)パーティショニングの両方をネイティブにサポートしているため、IceCube(そして OSG 全体)にとってとても扱いやすいです。
Google Cloud の弾力性を活用するため、GKE コンピューティング リソースのプロビジョニングとプロビジョニング解除では GKE 水平ノード自動スケーリングを全面的に利用しました。開始できないワーカー Pod があると、設定した最大値まで GKE ノードがオートスケーラーによってプロビジョニングされました。GKE ノードの未使用時は、オートスケーラーでプロビジョニングが解除され、コストが削減されました。
パフォーマンス結果
GKE のおかげで非常にシンプルに Google Cloud GPU リソースを使用できました。オンプレミスの PRP Kubernetes クラスタでそれまで使用していた設定をそのまま使用して、新しいクラスタを指定するだけでした。
初期設定が済むと、IceCube は Google Cloud リソースを効率的に使用できるようになりました。自動スケーリングの制限を設定する以外、SDSC チームが自らの手で介入することはありませんでした。SDSC チームが IceCube などのために行ってきた他のクラウド アクティビティはプロビジョニングされたリソースの積極的管理が必要でした。それに比べると非常に喜ばしい変化です。
自動スケーリング
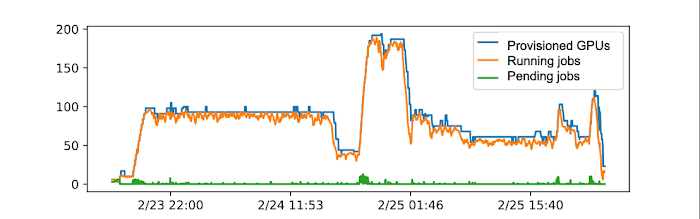
GKE 自動スケーリングによるクラウド リソースの自律的プロビジョニングとプロビジョニング解除は期待通りに機能し、図 1 に示すように IceCube ユーザーの需要にほぼ追随できました。特に GPU 共有と連動した GKE のパフォーマンスに感銘を受けました。図に示したテストランでは、GPU あたり 7 個の A100 MIG パーティションを使用しました。
NVIDIA GPU 共有
NVIDIA A100、V100、T4 Tensor Core GPU によるフル GPU と共有 GPU の Kubernetes ノードの両方をプロビジョニングしました。しかし、すべてのプロビジョニングされたリソースがジョブの必須要件を満たしていたため、それらを IceCube ジョブで使い分けることはありませんでした。
GPU 共有のメリットは選択したワークフローにおける CPU と GPU の比率に応じて異なると想定し、テストの間、極値からワークフローを 1 つずつピックアップしました。IceCube ユーザーは、(簡単に説明すると)光子のターゲット サイズをなんらかの因数で大きくすることで、一部の問題で GPU ベースのレイトレーシング コンピューティングを高速化できます。たとえば、oversize=1 に設定すると、シミュレーションの精度が最も高くなり、oversize=4 に設定すると速度が最も速くなります。コンピューティングを高速化すると当然のことながら、CPU 対 GPU 比が高くなります。
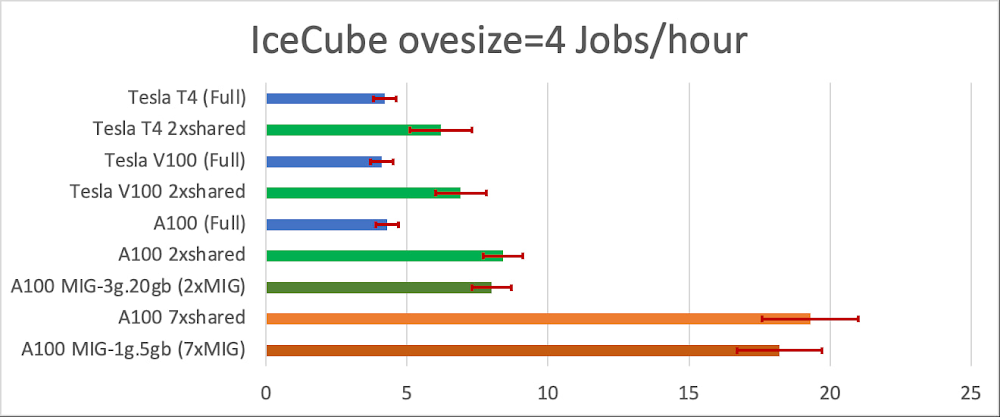
最高速の oversize=4 のワークロードが GPU 共有のメリットを最も受けました。図 2 で示すように、IceCube oversize=4 のジョブの場合、NVIDIA T4 よりも高速な GPU を使いこなすことができません。ローエンドの T4 GPU でさえも、共有するとジョブのスループットが約 40% 上昇します。A100 GPU の場合、GPU 共有によりスループットが 4.5 倍になります。これは非常に大きな変化です。注目したいのは、MIG と「シンプルな」GPU 共有はそれぞれスループットの相当の向上が見られますが、MIG は分離が他より非常に強いことです。これはマルチユーザーの設定では非常に重要です。
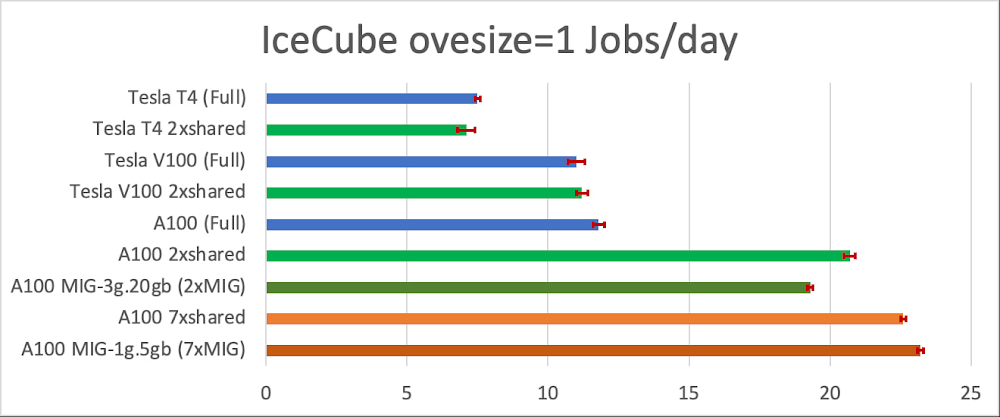
要件のさらに厳しい oversize=1 ワークロードでは GPU がより適切に使用されるため、古い T4 および V100 GPU ではジョブのスループットに改善は見られませんでした。一方、A100 GPU は全体として使用されるにはまだ強力すぎて、図 3 に示すように、GPU 共有によりスループットがほぼ 2 倍に向上しています。
当然のことながら、GPU 共有では 1 つのジョブで完了までかかる実測時間が長くなります。しかし、これは IceCube にとっては制約とはなりません。IceCube の主要な目的は数千もの独立したジョブの出力を生成することであり、期待されるタイムラインは分単位ではなく日単位で測定されます。そのため、ジョブのスループットと費用対効果がコンピューティングのレイテンシよりはるかに重要となります。
最後に、使用したリソースのほとんどが Spot VM 上でプロビジョニングされたことをお話ししておくべきでしょう。これにより、オンデマンドの VM に比べて大幅に費用を抑えられました。GKE はあらゆるプリエンプションを適切に処理したため、非常に高い費用対効果でオペレーションを実現できました。
学習した内容
ワークロードがすでに Kubernetes に対応していたこともあり、GKE での GPU 共有は非常にシンプルであることがわかりました。ユーザー視点では、使い慣れたオンプレミスの Kubernetes クラスタとの違いは実質的には感じられませんでした。
GPU 共有のメリットは選択したワークロードに明らかに依存しますが、少なくとも IceCube において最新の GPU(NVIDIA A100 など)を使用する場合は必須と考えられます。また、IceCube のジョブの大部分はローエンドの T4 GPU でも GPU 共有のメリットを得られます。
GPU 共有の方法については、迷わず MIG パーティショニングを選びます。時間共有の GPU 共有に比べると柔軟性がやや劣りますが、MIG の強力な分離特性により、マルチワークロードの設定管理の予測性がはるかに高くなります。そのうえで、「シンプルな」GPU 共有も許容できる結果となり、MIG サポートのない GPU では特に効果的でした。
まとめると、GKE での GPU 共有は非常に素晴らしいものでした。Kubernetes での GPU 共有によって得られたメリットは目を見張るものであり、可能な限り利用したいと考えています。
GKE での GPU 共有に関する詳細は、こちらのユーザーガイドをご覧ください。

- サンディエゴ スーパーコンピュータ センター、科学的ソフトウェア主任開発者兼研究者 Igor Sfiligoi 氏
