Bayer Crop Science が 15,000 ノードの GKE クラスタを活用して未来に種をまく
Google Cloud Japan Team
※この投稿は米国時間 2020 年 6 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
編集者注: 本日の投稿では、GKE のクラスタあたり最大 15,000 ノードのサポートが幅広いユースケースにどのように役立つかを探ります。特に Bayer Crop Science がジェノタイピング ラボから取得した新しい情報の迅速な処理を支援する方法を見ていきます。
Google で構築するプロダクトの主要要件は、スケーラビリティです。Google Kubernetes Engine(GKE)を採用する企業が増えるにつれ、Google では GKE クラスタの限界を押し広げることに取り組んできました。具体的に言うと、それは最大 15,000 個のノードを備えたクラスタを実現するための取り組みです。これはクラウドベースの Kubernetes サービスでサポートされている最大数のノードです。その数は、オープンソースの Kubernetes でサポートされているノード数の 3 倍です。
このような大規模クラスタは、以下のようなさまざまなユースケースに役立ちます。
- 大規模なインターネット規模のサービスを実行している
- 管理するクラスタを少なくしてインフラストラクチャ管理を簡素化する必要がある
- バッチ処理 - 一時的にはるかに多くのリソースを使用することにより、データの処理に必要な時間を短縮する
- ゲームの起動中やオンラインの e コマース キャンペーン中など、リソース需要の急増に対応する新しいクラスタをプロビジョニングする代わりに、既存のクラスタのサイズを変更できるため、サービスの可用性とパフォーマンスを向上させることができます。
IT システムのスケーラビリティは単にサポートしているノードの数ではないと考えると、クラスタあたり 15,000 個のノードを持つことはさらに大きな意味を持ちます。スケーラブルなシステムは、大量のリソースを使用しながらも、その目的を果たすことができる必要があります。Kubernetes クラスタの場合、ノードの数は通常、クラスタとそのワークロードのサイズを表します。しかし、よく見てみると、状況ははるかに複雑です。
Kubernetes クラスタの規模は、クラスタのすべてのリソースで構成される多次元オブジェクトのようなものです。そして、スケーラビリティは、その立方体を拡張できる量を制限するエンベロープです。ポッドとコンテナの数、イベント スケジューリングの頻度、サービスと各サービスのエンドポイントの数などは、クラスタの規模として良い指標となります。また、コントロール プレーンが利用可能であり、ワークロードがタスクを実行できることも必要です。 大規模な運用が困難になるのは、これらの次元間に依存関係が存在することが要因です。詳細と例については、Kubernetes のスケーラビリティのしきい値 と GKE 固有のスケーラビリティ ガイドラインに関するこのドキュメントをご覧ください。
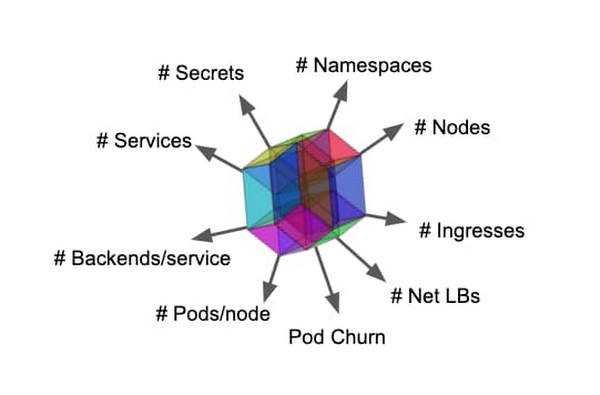
非常にスケーラブルなプラットフォームでの実行からメリットが得られるのは、ハイパースケール サービスのみではありません。小規模なサービスもメリットが得られます。環境のスケーラビリティの限界を押し広げることにより、コンフォート ゾーンを拡大し、インフラストラクチャの信頼性とパフォーマンスを損なうことなく、間違いを犯したり、非標準のデザイン パターンを使用したりする自由度が高まります。非常にスケーラブルなプラットフォームの実際の例として、今日は、Bayer Crop Science のチームにお話を伺い、同社が設計した最近のプロジェクトについて学びます。
15,000 個のノード規模で実行するための準備
GKE ユーザーが 1 つのクラスタで 5,000 個を超えるノードを必要とするワークロードを実行できるようにするために、設計パートナー グループに非公開の早期アクセス プログラムに参加してもらいました。
精密農業会社の Bayer Crop Science(BCS)は現在、GKE の最大のユーザーの 1 社であり、Google Cloud で最大級の GKE クラスタを備えています。具体的には、同社は GKE を使用して、研究開発パイプラインでどの種子の研究を進め、最終的にどの商品を農家に提供可能にするかを決定しています。これを行うには、正確かつ豊富な遺伝子型データが必要です。トウモロコシのカタログだけで 60,000 個の生殖質があるため、BCS は各種子個体群を個別にテストすることはできません。その代わりに、血統や祖先の遺伝子型の観察などの他のデータセットを使用して、各個体群で見込みのある遺伝子型を推測しています。このようにして、BCS のデータ サイエンティストは、「この種子は特定の害虫に耐性があるか?」などの質問に答えることができ、種子生産パイプラインを運営するために毎年必要な農地を削減しています。
昨年、BCS はオンプレミスの計算を GKE に移行しました。最大 5,000 個のノードのクラスタを利用することで、サイエンティストはその月に必要なデータの事前計算を、数日を要する単一の大規模なバッチジョブとして実行できるようになりました。以前は、サイエンティストは研究に必要な遺伝子型データを特別な方法で要求し、多くの場合、その結果を数日待つ必要がありました。詳細については、BCS の Jason Clark 氏による Next ‘19 のこのプレゼンテーションをご覧ください。
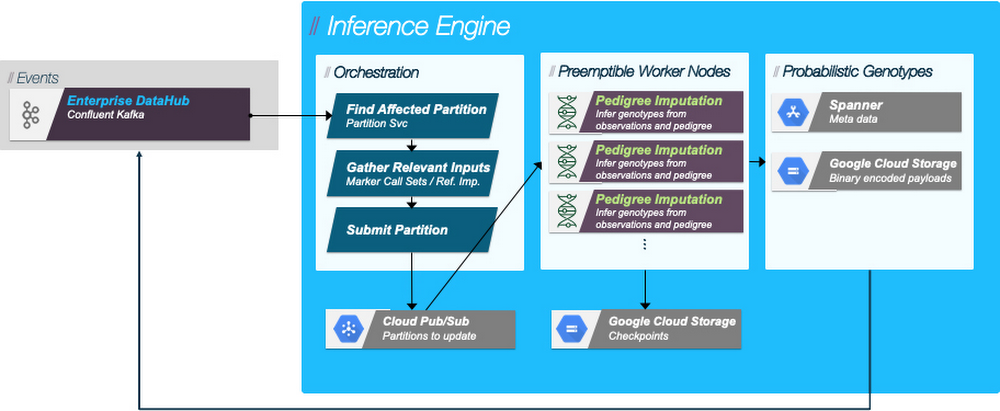
Bayer Crop Science インフラストラクチャ / アーキテクチャ
BCS は、ジェノタイピング ラボから届く新しい情報の迅速な処理を促進するために、イベント ドリブン アーキテクチャを実装しました。新しい遺伝子型観測のセットが品質管理を通過すると、それがサービスに書き込まれ、イベントが Cloud Pub/Sub トピックに公開されます。推論エンジンによってこのトピックがモニタリングされます。そして、受信イベントが推論許可の要件と一致する場合、ジョブ リクエストが作成され、別のトピックに配置されます。推論エンジン ワーカー ノードは、受信キューでのワークの深さを調べる HorizontalPodAutoscaler を使用して、利用可能な最大の Kubernetes クラスタにデプロイされます。ワーカーがトピックからジョブを選択すると、ジョブを最初にトリガーした遺伝子型観測を含む、必要なすべての入力がステージングされ、遺伝子型推論アルゴリズムが実行されます。結果はアクセスしやすいようにサービスに書き込まれ、遺伝子型推論トピックにイベントが発行されます。推論済みの遺伝子型に基づいた意思決定などの下流プロセスは、このイベント ストリームに関連付けられ、イベントを受信するとすぐに作業が開始されます。
準備と共同テスト
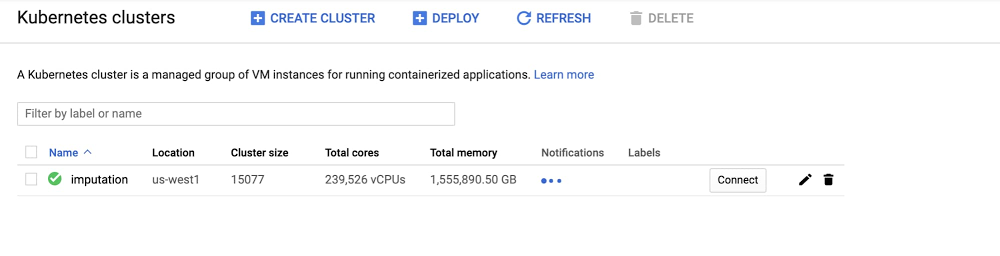
BCS の データ推測(別名: 補完)に使用される最大のクラスタは、最大 4,479 個のノード、94,798 個の CPU、455 TB の RAM を使用します。そして、その補完パイプラインは高度に並列化可能なバッチジョブであるため、15,000 個のノードのクラスタで実行するようにスケーリングすることは簡単でした。
共同テストでは、推論エンジンをホストするクラスタとその自動スケーリング機能を使用して、ワークロードのサイズと使用可能なリソースの量をオーバースケールしました。大型マシン(16 CPU highmem 104 GB RAM)で 0 から 15,000 個のノードにクラスタをスケールし、合計 240,000 CPU コアと 1.48 PiB の RAM を実現することを目指しました。
ここでリソースが低費用で提供されるようにするために、推論エンジン ワーカー ポッドをホストするクラスタでは、プリエンプティブル インスタンスのみを使用し、入力データをホストするサポート サービスと出力の処理は通常のインスタンスで実行しました。プリエンプティブル VM により、膨大な量の計算能力を獲得すると同時に、計算能力にかかる費用をほぼ 5 分の 1 に削減しています。
BCS は、15,000 個のノードを自由に使用することで、多くの時間を節約しています。1,000 CPU の古いオンプレミス環境では、1 時間あたりに処理できる遺伝子型の数は最大 62,500,000 個でした。最大 5,000 個のノード制限があるクラスタを使うと、これまでよりも 100 倍速く処理できます。そして、15,000 個のノード全体で 240,000 CPU を使用した場合、1 時間あたり最大約15,000,000,000 個の遺伝子型を処理できます。これにより、モデル リビジョンを作成してデータ バックログ全体をすばやく再処理したり、新しいデータセットに基づいて推論をすばやく追加したりできるため、データ サイエンティストはバッチジョブの完了を待たずに作業を続行できます。
大規模な実行から学んだ教訓
Google と BCS はともに 15,000 個のノードの単一クラスタ全体でワークロードを実行することから多くのことを学びました。
その 1 つは、クラスタとやりとりするコンポーネントのスケーリングが非常に重要であることです。GKE が高いスループットでデータを処理したため、私たちは Spanner を実行するインスタンスの数を増やすなど、システムの他のコンポーネントもスケールアップする必要がありました。
もう 1 つの重要なポイントは、プリエンプティブル VM を管理することです。プリエンプティブル VM は費用効率が非常に高いですが、実行できるのは最大 24 時間で、その時間内に排除されることがあります。プリエンプティブル VM を効果的に使用するために、BCS は 15 分ごとに Google Cloud Storage 環境をチェックしました。これにより、ジョブが完了する前にプリエンプトされた場合、ジョブ リクエストはキューに戻り、次に利用可能なワーカーによって取得されて続行されます。
イノベーションの種をまく
Bayer Crop Science が大量の遺伝子データを処理するには、オンデマンドで大量のインフラストラクチャが必要です。つまり、数千のノードでクラスタを実行できると、BCS は事前計算されたデータをすばやく配信できます。たとえば、2 週間でデータセット全体を再処理できます。最大 15,000 個のノードクラスタにより、その時間を 4 日間に短縮できます。これにより、アナリストは特定のバッチをオフラインで処理するように要求する必要がなくなります。BCS は、大規模なデータセットの仮説を非本番環境ですばやくテストすることの価値も実感しました。
そして、このコラボレーションのおかげで、すべての GKE ユーザーは、こうした機能にすぐにアクセスできるようになり、今年後半には広く利用可能になる 15,000 個のノードクラスタのサポートを受けられます。GKE チームからの今後のアップデートをご期待ください。また、8 月 25 日の NEXT OnAir のセッションにぜひご参加ください。このセッションでは、Google Cloud が Mesos と Aurora の多数のユーザーと協力して、GKE で同様のハイパースケール エクスペリエンスを提供する方法について説明します。
- Bayer Crop Science データ エンジニアリング リード Rob Long, Google Cloud プロダクト マネージャー Maciek Różacki
