ステートフル アプリケーションの GKE ボリューム アタッチメントを最大で 80% 改善させた手法
Sneha Aradhey
Software Engineer
Brad Farr
Software Engineer
※この投稿は米国時間 2025 年 2 月 5 日に、Google Cloud blog に投稿されたものの抄訳です。
最近、Google Kubernetes Engine(GKE)でステートフル ワークロードを実行する際、クラスタのアップグレードの実行速度が各段に改善されたと感じませんでしたか。それは思い込みではありません。Google は最近、GKE および Google Compute Engine に機能強化を加え、Persistent Disk(PD)のアタッチおよび切断の速度を大幅に改善しました。これはつまり、レイテンシが低減し、ユーザー ワークロードや永続ストレージとの通信において、恩恵がもたらされることを意味します。この恩恵はクラスタをアップグレードする際に最も顕著に現れます。これまでは、ディスクを新しい VM へと移行する際に、大量のアタッチと切断のリクエストが発生することによりプロセスが遅延するという特徴がありました。
この問題の背景とそれに対する Google のソリューションについては、以下をお読みください。
Kubernetes ストレージと GKE CSI ドライバ
これまでは、ほとんどのアプリケーションが Kubernetes 上のコンテナで実行されており、ワークロード(およびそのストレージ)のライフサイクルは、その基盤となる仮想マシン(VM)と連動していました。そのため、ワークロードの新しい VM への移行は、エラーが発生しやすい、時間のかかる処理となっていました。VM を廃止して、ディスクの切断と新しい VM への再アタッチを手動で行い、ディスクパスの再マウントを行い、アプリケーションを再起動する必要があったのです。ディスクが VM から切断されたり新しい VM にアタッチされることはめったになく、あったとしてもその多くは、起動やシャットダウンのときや、トラフィック ボリュームが低いときだけでした。そのため、Kubernetes を、ステートフル IO バウンド アプリケーションを実行する場所として推奨することが難しくなっていました。求められていたのは、ストレージ中心のソリューションでした。
Google Cloud では、このソリューションは Google Compute Engine Persistent Disk(GCE PD)Container Storage Interface(CSI)ストレージ プラグインという形で実装されていました。CSI ドライバは GKE 内の基盤となるコンポーネントであり、これを用いて GKE クラスタ内の Compute Engine PD のライフサイクルを管理します。これにより、Kubernetes ワークロードのシームレスなストレージ アクセスが可能となり、プロビジョニング、アタッチ、切断、ファイルシステムの修正などのオペレーションが容易になります。その結果、ワークロードを GKE ノードをまたいでシームレスに動かせるようになるため、アップグレード、スケーリング、移行が可能になります。
ただし、1 つ問題があります。GKE は、ワークロードを柔軟に配置でき、また大規模にスケーリングすることができます。ノードは数百単位の Pod を受け入れることが可能であり、ワークロードで複数の永続ボリュームを利用することもできます。これは、追跡、管理、調整を必要とする VM に、数十から数百単位の PD がアタッチされることにつながります。ノードのアップグレードでは、ワークロードの可用性を維持し、クラスタのアップグレードの遅延を抑制するには、ワークロード Pod を再起動して PD を新しいノードに移行するために必要となる時間を短縮する必要があります。これにより、VM 向けに設計された既存のシステムと比較して桁違いに多い数のアタッチ / 切断オペレーションが発生することがあり、これが固有の問題となっています。
GKE 上のステートフル アプリケーションの規模は指数関数的に増大しているため、そのような大規模なオペレーションを効率的に処理できる CSI ドライバの設計が必要でした。Google はこれに対処するために、基盤となるアーキテクチャを再度見直して、PD のアタッチと切断のプロセスを最適化し、ダウンタイムを最小限に抑え、ワークロードの移行をよりスムーズなものにする必要がありました。そこで Google は次のことを行いました。
キューに入れられたボリュームのアタッチのオペレーションの統合
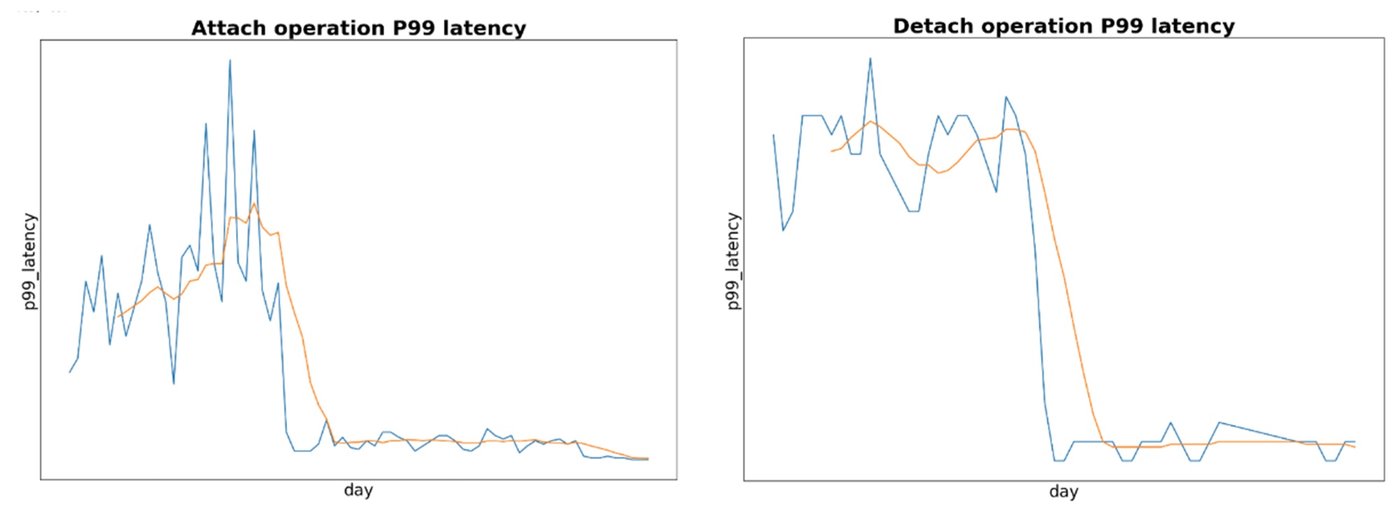
すでに説明したように、大量の PD ボリューム(最大 128)がアタッチされた GKE ノードで、ソフトウェアのアップグレード中に、シリアル化されたボリュームの切断とアタッチのオペレーションを原因とした大幅なレイテンシが発生していました。例として、64 の PD ボリュームがアタッチされたノードを考えてみましょう。今回の最適化が導入される前、CSI ドライバは、すべてのディスクをオリジナルのノードから切断する 64 のリクエストをまず発行して、その後すべてのディスクをアップグレードされたノードにアタッチする 64 のリクエストを発行していました。ただし、Compute Engine で同時に許可されるリクエストのキューの数は最大 32 であり、残りのオペレーションの処理は順番に実行されていました。キューに入れることを許可されなかったリクエストについては、容量が利用可能になるまで CSI ドライバによって再試行を実行する必要がありました。もし、128 ある切断とアタッチのオペレーションでそれぞれ 5 秒かかる場合、ノードのアップグレードで 10 分以上のレイテンシが発生することになります。今回の新しい最適化によって、このレイテンシはわずか 1 分強程度にまで低減されます。
Google にとって重要だったのは、クライアントを中断することなく、透明性のある形でこの最適化を導入することでした。CSI ドライバは、アタッチおよび切断のオペレーションの追跡と再試行を、ボリューム単位のレベルで実行します。ただ、CSI ドライバは一括処理を想定して設計されているわけではないため、OSS コミュニティの仕様を単純に更新することはできませんでした。Google のソリューションは、代わりに透明性のあるオペレーション統合を Compute Engine に導入するというものでした。これにより、Compute Engine コントロールで受信されるアタッチと切断のリクエストを単一のワークフローに統合し、オペレーション単位のエラー処理とロールバックも同時に維持することができます。
この新しく導入された Compute Engine のオペレーション統合によって、切断とアタッチのオペレーションが透過的な形で同時に実行されるようになります。また、キューの容量が増えたことで、ノードあたり最大 128 の保留中リクエストが許可されるようになっています。CSI ドライバは引き続きこれまでと同じように機能します。個々の切断およびアタッチのリクエストの管理について変更を加えることなく Compute Engine の最適化のメリットを享受でき、キューに入れられたオペレーションが適宜統合されるようになります。最初に実行する切断とアタッチのオペレーションが完了するまでに、Compute Engine がノード ボリューム アタッチメントの最終的な状態を計算し、ダウンストリーム システムとの調整を開始します。64 のボリュームを同時にアタッチするオペレーションでは、この統合によって、即座に実行される最初のアタッチメント以外の残りの 63 のオペレーションが統合され、最初のオペレーションの完了後すぐに実行するためのキューに入れられるようになります。その結果として、GKE のエンドツーエンドのレイテンシは劇的に改善されます。これらの改善の最も素晴らしい点は、お客様側の対応がまったくいらないことであり、お客様は以下の恩恵を自動的に得られるようになります。
- ワークロードのアタッチの p99 レイテンシを ~80% 改善
- ワークロードの切断の P99 レイテンシを ~60% 改善
このカスタム ソリューションでは、ワークフロー実行のための階層化アプローチが導入されています。これにより、コアのビジネス ロジック ワークフローを監視する 2 つの追加のワークフローが導入され、実際のボリュームのアタッチおよび切断の実行から受信されるリクエストが分離されます。
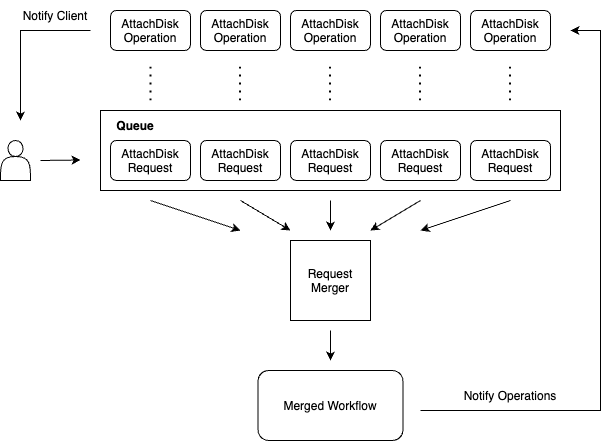
Compute Engine API がディスクをアタッチするリクエストを受け取った際、1 つではなく最大で 3 つのワークフローが作成されるようになりました。
-
1 つ目のワークフローは、attachDisk オペレーションに直接バインドされますが、これが実際に実行を担うわけではありません。そうではなく、このワークフローは単に完了をポーリングして、ユーザー向けオペレーションで観察されたエラーを設定します。
-
作成される 2 つ目のワークフローは、保留中の attachDisk または detachDisk オペレーションに対応するウォッチドッグのようなものであると考えてください。ウォッチドッグ フローの数は、Compute Engine インスタンス リソースごとにひとつだけです。このフローは、すべての保留中オペレーションが完了とマークされると終了します。また、ウォッチドッグ フローが存在しない場合にのみ、ディスクのアタッチ / 切断を行う最初のリクエストの一部としてオンデマンドで作成されます。
-
最後に、ウォッチドッグのフローで、実際の attachDisk/detachDisk プロセスを実行する 3 つ目のワークフローの存在が確認されます。このビジネス ロジック ワークフローが、それぞれの個別の attachDisk あるいは detachDisk オペレーションが成功したか、失敗したかをオペレーション ポーリング ワークフローに直接通知します。
また、受信される attachDisk/detachDisk リクエストが、ターゲットの Compute Engine インスタンス エンティティと同じデータベース行内でキューに直接入れられることはありません。これは、最適な HTTP レイテンシを実現し、データベースの競合を最小限に抑えるためのものです。そうではなく、リクエスト データがインスタンス エンティティのサブリソース行として作成され、ウォッチドッグ フローによってモニタリングされます。これらは、先入れ先出し(FIFO)の順番で選択され実行されます(GKE の場合)。
これで、ディスクの大規模なアタッチおよび切断オペレーションのための、新しい改善された手法の完成です。ユーザーは、大規模なステートフル アプリケーションを、GKE クラスタ上でシームレスに実行できるようになります。GKE 上でのステートフル アプリケーションのデプロイについて詳しくは、こちらのリソースをご覧ください。
- ソフトウェア エンジニア Sneha Aradhey
- ソフトウェア エンジニア Brad Farr

