RAG の本番環境への移行を Ray、LangChain、HuggingFace で加速
Julie Amundson
Senior Staff Software Engineer
Jason Soo Hoo
Software Engineering Manager
※この投稿は米国時間 2024 年 5 月 3 日に、Google Cloud blog に投稿されたものの抄訳です。
このたび、本番環境への移行プロセスを加速する、検索拡張生成(RAG)アプリケーション向けのクイックスタート ソリューションおよびリファレンス アーキテクチャをリリースしましたのでお知らせいたします。この投稿では、完全な RAG アプリケーションを Ray、LangChain、Hugging Face を使用して、Google Kubernetes Engine(GKE)、および Cloud SQL for PostgreSQL と pgvector にデプロイする方法について説明します。
RAG とは
RAG は、特定のアプリケーション向け大規模言語モデル(LLM)などの基盤モデルの出力を向上させることができます。RAG が実装された AI アプリを使用すると、トレーニングによって得られた知識のみを利用するのではなく、ユーザーのプロンプトに関連性が最も高い情報を外部のナレッジベースから取得し、その情報をプロンプトに追加してから生成モデルに送信できるようになります。このようなナレッジベースの形式には、ベクトル データベース、従来型の検索インデックス、リレーショナル データベースがあります。これらのナレッジベースにアクセスすると、たとえばカスタマー サービスの chatbot であればヘルプセンターの記事を確認したり、デジタル ショッピング アシスタントであれば商品カタログや購入者レビューを確認したり、AI による旅行代理店であればフライトやホテルの最新情報を提供したりできます。
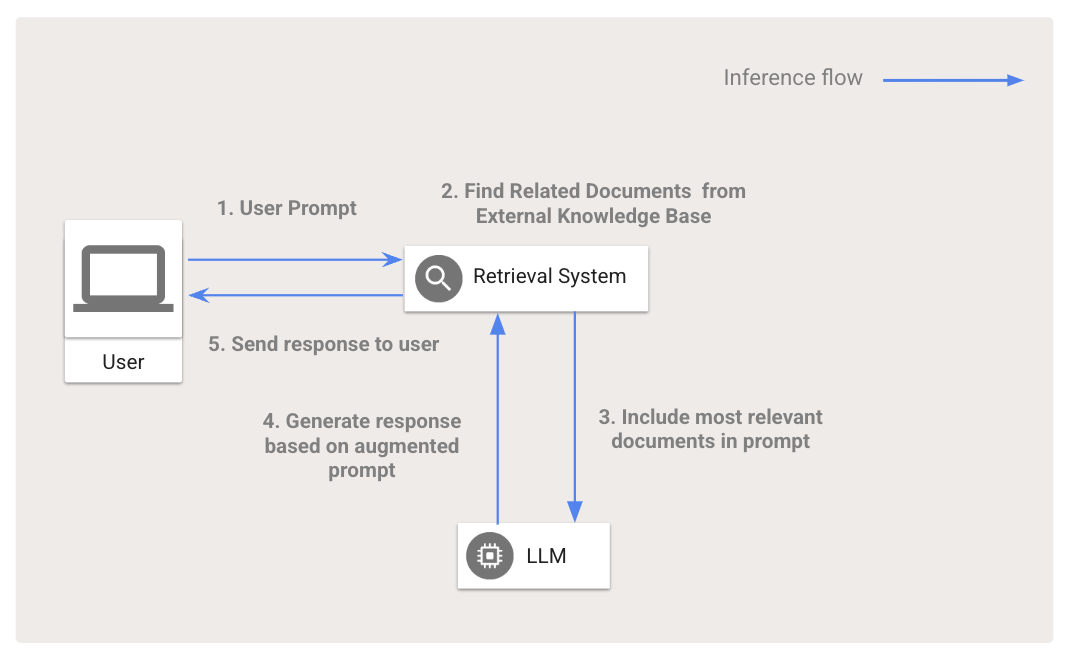
LLM が依存しているトレーニング データは常に最新であるとは限らないため、アプリケーションで扱われる分野の関連データが含まれない場合があります。LLM を再トレーニングまたはファインチューニングして分野固有の最新データを学習させる費用は高く、そのプロセスも複雑です。RAG を使用すると、LLM が最新データにアクセスできるようになるため、トレーニングやファインチューニングが不要になるだけでなく、LLM による事実に基づいた回答の生成がしやすくなるため、ハルシネーションが削減され、人が検証できるソース情報をアプリケーションから提供できるようになります。
RAG の仕組みについて詳しくは、コンテキスト アウェアなコード生成に関する Google のブログをご覧ください。
RAG 向けの AI インフラストラクチャ
生成 AI が普及する前は、一般的なアプリケーション アーキテクチャにデータベース、複数のマイクロサービス、フロントエンドが含まれていました。最も基本的な RAG アプリケーションを使用する場合でも、LLM への対応、処理、非構造化データの取得を可能にするための新しい要件が求められます。このような要件を満たすには、特に AI ワークロード向けに最適化されたインフラストラクチャが必要になります。
多くのお客様は、Vertex AI などのフルマネージド プラットフォーム経由で TPU や GPU などの AI インフラストラクチャにアクセスされています。一方で、オープンソース フレームワークおよびオープンモデルを活用しながら、GKE 上で独自のインフラストラクチャを管理されているお客様もいらっしゃいます。このブログ投稿は、後者のお客様向けです。
AI プラットフォームを最初から構築する場合、モデルの提供に使用するフレームワーク、推論で使用するマシンシェイプ、機密性の高いデータを保護する方法、費用とパフォーマンス要件を満たす方法、トラフィックの増加に合わせたスケーリング方法など、多くの重要な決定を下す必要があります。それぞれの決定項目には、急速に変化しつつある広大な生成 AI ツール環境を考えると、多くのトレードオフをともないます。
このような状況を受け、Google は GKE、Cloud SQL、およびオープンソース フレームワーク(Ray、LangChain、Hugging Face)上で RAG アプリケーションを構築するためのクイックスタート ソリューションおよびリファレンス アーキテクチャを開発しました。RAG のベスト プラクティスが最初から組み込まれたこのソリューションは、迅速に導入を開始して、本番環境への移行プロセスを加速させるのに役立ちます。
GKE および Cloud SQL 上で RAG を使用するメリット
GKE および Cloud SQL を使用すると、本番環境への移行プロセスを、以下のさまざまな方法で加速できます。
-
高速なデータ読み込み - Ray Data を使用すると、GKE の GCSFuse ドライバ経由で、Ray クラスタからデータにシームレスに並行してアクセスできます。エンべディングを効率的に Cloud SQL for PostgreSQL および pgvector に読み込むことで、低レイテンシでベクトル検索を大規模に実行できます。
-
高速なデプロイ - Ray、JupyterHub、および Hugging Face Text Generation Inference(TGI)を GKE クラスタに迅速にデプロイできます。
-
簡単なセキュリティ確保 - GKE で Kubernetes のセキュリティを簡単に確保できるほか、Sensitive Data Protection(SDP)を使用して、デリケートまたは有害なコンテンツを除外できます。また、Identity-Aware Proxy によって Google の標準認証を活用することで、ユーザーは LLM フロントエンドおよび Jupyter ノートブックにシームレスに接続できます。
-
費用の効率化および管理オーバーヘッドの削減 - GKE を使用すると、クラスタ管理が削減され、YAML 構成を介した Spot ノードなどの費用削減手段を簡単に利用できます。
-
スケーラビリティ - GKE は、トラフィックの増加に合わせて自動的にノードをプロビジョニングするため、スケールアップする手動の構成が不要になります。
GKE および Cloud SQL への RAG のデプロイ
Google のエンドツーエンドの RAG アプリケーションおよびリファレンス アーキテクチャは以下を提供します。
-
Google Cloud プロジェクト - GKE クラスタ、Cloud SQL for PostgreSQL、pgvector インスタンスなどの、RAG アプリケーションの実行に必要な前提条件をプロジェクトで構成します。
-
AI フレームワーク - Ray、JupyterHub、Hugging Face TGI を GKE にデプロイします。
-
RAG エンベディング パイプライン - エンベディングを作成して、Cloud SQL for PostgreSQL および pgvector インスタンスに格納します。
-
RAG chatbot アプリケーションの例 - ウェブベースの RAG chatbot を GKE にデプロイします。
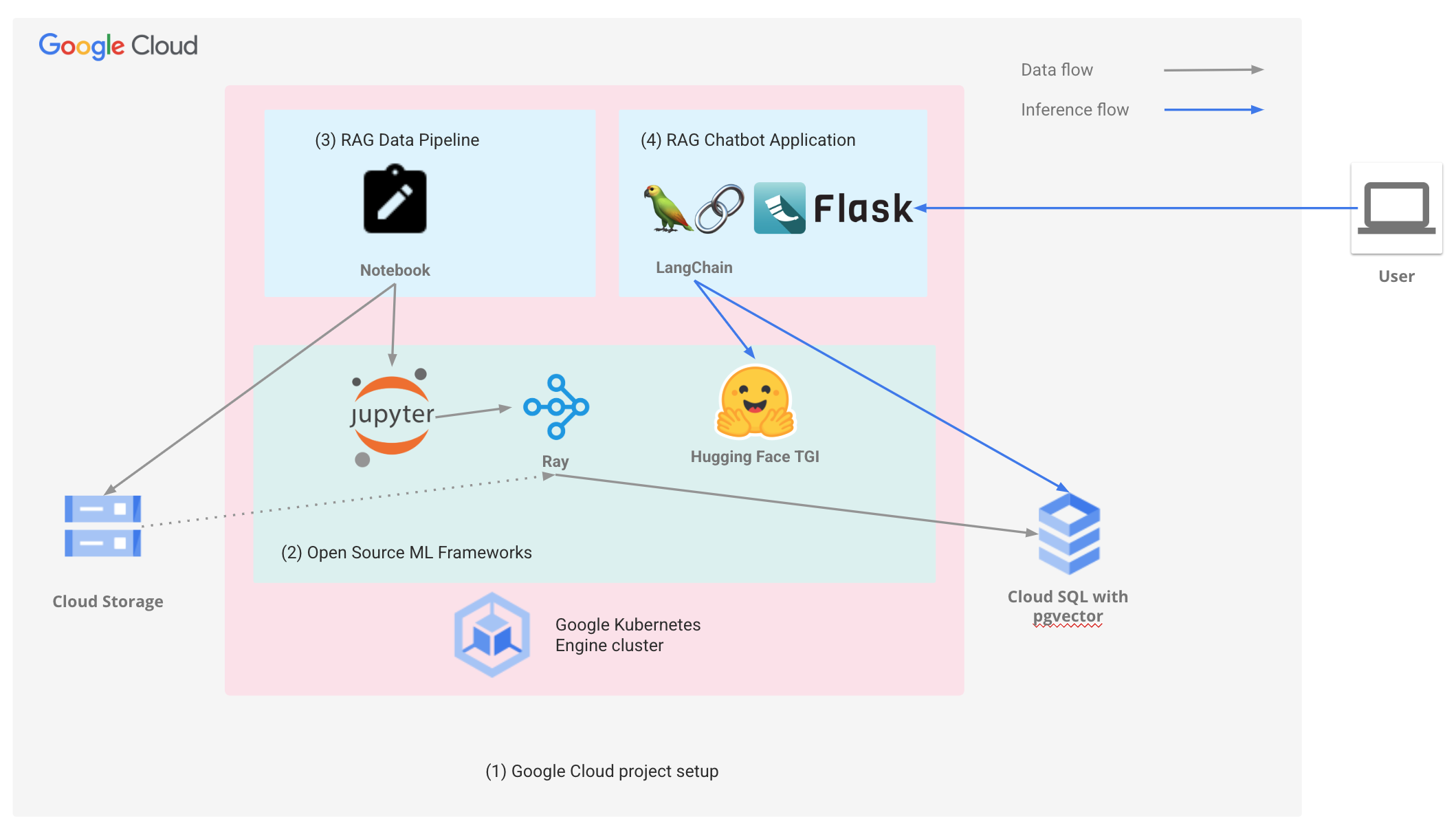
Chatbot アプリケーションの例では、ユーザーがオープンソースの LLM とやり取りできるウェブ インターフェースが提供されています。RAG データ パイプラインが pgvector を使用して Cloud SQL for PostgreSQL に読み込んだデータに基づいて、ユーザークエリに対してより包括的かつ有益な回答が生成されています。
Google の RAG ソリューションは、さらなる開発の基盤となるため、幅広いアプリケーションを構築するためのテクノロジーとして期待されています。RAG の機能を、GKE および Cloud SQL のスケーラビリティと柔軟性および Google Cloud のセキュリティ機能と組み合わせることで、デベロッパーは、複雑な作業に対応でき、貴重なインサイトを提供する、パワフルで汎用性のあるアプリケーションを構築できるようになります。
Google は、このソリューションをさらに進化させ、顧客データセットの追加、モデルの置き換え、データセットおよびベクトル データベースの新しいドキュメントでの更新などの機能を追加していく予定です。
詳しくは README、github の手順、RAG のリファレンス アーキテクチャをご覧ください。また、RAG に関するディスカッションを含む Google Cloud Next 2024 セッションも合わせてご覧ください。



