L’Oréal、Tech Accelerator でエンドツーエンドの MLOps プラットフォームを構築

Moutia Khatiri
Tech Accelerators CTO, L’Oréal
Dr. Wafae Bakkali
Staff Generative AI Specialist, Blackbelt, Google
※この投稿は米国時間 2025 年 1 月 24 日に、Google Cloud blog に投稿されたものの抄訳です。
テクノロジーは、かつてないスピードと規模で私たちの生活や社会的な交流に変化をもたらし、新たな機会を生み出してきました。このような現実に適応するために、L'Oréal は、すべての人々が利用できる、パーソナライズされ、インクルーシブで、責任ある美を推進し、ビューティ テックのリーダーとしての地位を確立しました。この取り組みは、同社の「Beauty for Each, powered by Beauty Tech(ビューティ テックによる一人ひとりのための美)」というスローガンにも示されています。
このビューティ テックの融合は、拡張現実を使用した美容商品、スマート デバイス、強化されたマーケティング、オンラインおよびオフライン サービス、デジタル プラットフォームなど、情報通信技術、データ、AI によって実現されたものに顕著に表れています。L'Oréal は、美容体験を高め、美容の利用可能性とサステナビリティを高める革新的なソリューションの開発に取り組んでおり、それは、世界中の人々の多様なニーズや願望に応える未来を形作るものです。
世界最大級の化粧品メーカーである L’Oréal は、従業員向けのデジタル ソリューションの強化や、顧客へのパーソナライズされた体験の提供のために、長年にわたって AI を活用しています。このブログでは同社の Tech Accelerator が Google Cloud を使用して、スケーラブルでエンドツーエンドの MLOps プラットフォームを構築した方法を紹介します。このプラットフォームによって AI モデルのデプロイが加速され、迅速なイノベーションが可能になりました。
MLOps のビジョンと要件
AI イニシアチブを加速し、商品開発を最適化するために、L'Oréal Tech Accelerator では、再利用可能で安全かつユーザーフレンドリーな機械学習オペレーション(MLOps)プラットフォームを Google Cloud に構築することを目指しました。このプラットフォームの目的は以下のとおりです。
-
ワークフローを効率化し、コラボレーションを強化することで、チーム間の摩擦を減らし、製品化までの時間を短縮する。
-
セキュリティとベスト プラクティスを確保し、一貫性があり、明確に文書化されたプロセスを促進することで、エラーを最小限に抑える。
-
迅速な導入を実現するために、最小限のトレーニングで直感的に操作できるプラットフォームを構築する。
このアプローチにより、より一貫性のある効率的な開発環境が促進され、最終的には、商品の品質が向上し、進化するビジネス ニーズに対応するアジリティが高まります。
L'Oréal の MLOps プラットフォームの概要
Tech Accelerator の MLOps プラットフォームを理解するために、主要なコンポーネントを詳しく見ていきましょう。以下にプロセスの概要を示します。
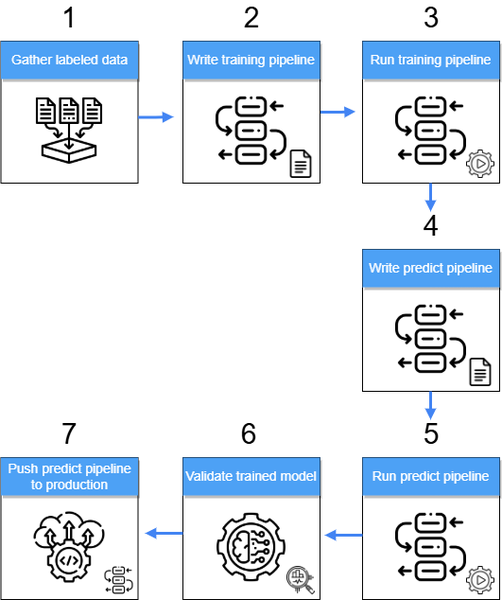
-
ラベル付きデータの準備: ラベル付きデータは、BigQuery、Google Cloud Storage、オンプレミス システム、データレイクなど、さまざまなソースから収集されます。データは ML モデルのトレーニングに備えて処理され、一元管理された場所(BigQuery、Google Cloud Storage など)に保存されます。
-
トレーニング パイプラインの開発: Kubeflow SDK を使用して、トレーニング パイプラインのフローとロジックを定義します。このパイプラインにより、ML モデルのトレーニング プロセスを自動化します。
-
トレーニング パイプラインの実行: トレーニング パイプラインが実行され、トレーニング済みモデルのアーティファクトが生成されます。このアーティファクトは、アクセスとデプロイを容易にするために Python ライブラリに埋め込まれた pickle ファイルとして保存されます。
-
予測パイプラインの開発: Kubeflow SDK を再度使用して、トレーニング済みモデルによって新しいデータに対する推論を生成する予測パイプラインを作成します。
-
予測パイプラインの実行: 予測パイプラインが実行され、BigQuery、Google Cloud Storage、データレイクに保存される推論が生成されます。
-
トレーニング済みモデルの検証: 予測パイプラインからの推論結果を使用して、トレーニング済みモデルのパフォーマンスを評価します。これには、F1 スコアや適合率などの主要な精度指標の計算が含まれます。
-
予測パイプラインを本番環境に push: ここまでのステップで、データ サイエンティストや ML エンジニアがパイプラインのすべてのコンポーネントを手動で開発、テスト、検証し、新しいモデル バージョン(複数可)を作成します。次のステップでは、新しいモデル バージョンを組み込んだ新しいバージョンの予測パイプラインを本番環境に push します。このデプロイでは、CI / CD パイプラインなどの開発におけるベスト プラクティスを活用します。
MLOps プラットフォームは、DevOps の原則を活用して、堅牢で効率的な開発ライフサイクルを保証します。これには、ML 開発プロセスを 4 つの異なる環境(例: Google Cloud プロジェクト)に分離することが含まれます。
-
DataOps 環境: この環境は、ラベル付きトレーニング データ、モデル アーティファクト、パイプライン コンポーネントなど、すべてのデータアセットを保存および管理するための中央リポジトリを提供します。これにより、ML ワークフロー全体でデータの整合性とアクセス性を確保します。さらに、この環境では、トレーニング パイプラインが実行されてモデルの新しいバージョンが作成されます。
-
開発環境: 新しいバージョンの予測パイプラインをテストするための専用スペースであり、複数のモデルをオーケストレートできます。この環境では、計算速度、データの整合性、エンドツーエンドの統合、その他のパフォーマンス要素を評価できます。
-
ステージング環境: この環境は本番環境の設定を反映しており、ビジネス上の期待や要件の厳密なテストと検証が可能です。実際のデータに極めて近いステージング データを使用することで、予測パイプラインにおけるビジネス上の潜在的な問題を早期に特定し、対処できます。
-
本番環境: 検証済みの予測パイプラインと新しいバージョンのモデルがデプロイされるライブ環境です。L'Oréal Tech Accelerator のアプリケーションとサービス用にリアルタイム予測とバッチ予測を生成し、エンドユーザーに価値を提供します。
この構造化されたアプローチでは、環境が明確に分離されているため、効率的なコラボレーションが促進され、リスクが最小限に抑えられるうえ、開発環境から本番環境へのスムーズな移行が保証されます。最終的には、AI を活用した高品質な美容体験を L'Oréal Tech Accelerator で提供できるようになります。効率をさらに最適化し費用を削減するために、トレーニング パイプラインは DataOps 環境内で 1 回のみ実行されることに注意してください。結果として得られるトレーニング済みモデルは、他の環境にもデプロイされます。これにより、各環境でモデルを再トレーニングする必要がなくなり、大幅な費用削減(最大 1/3)を実現できます。
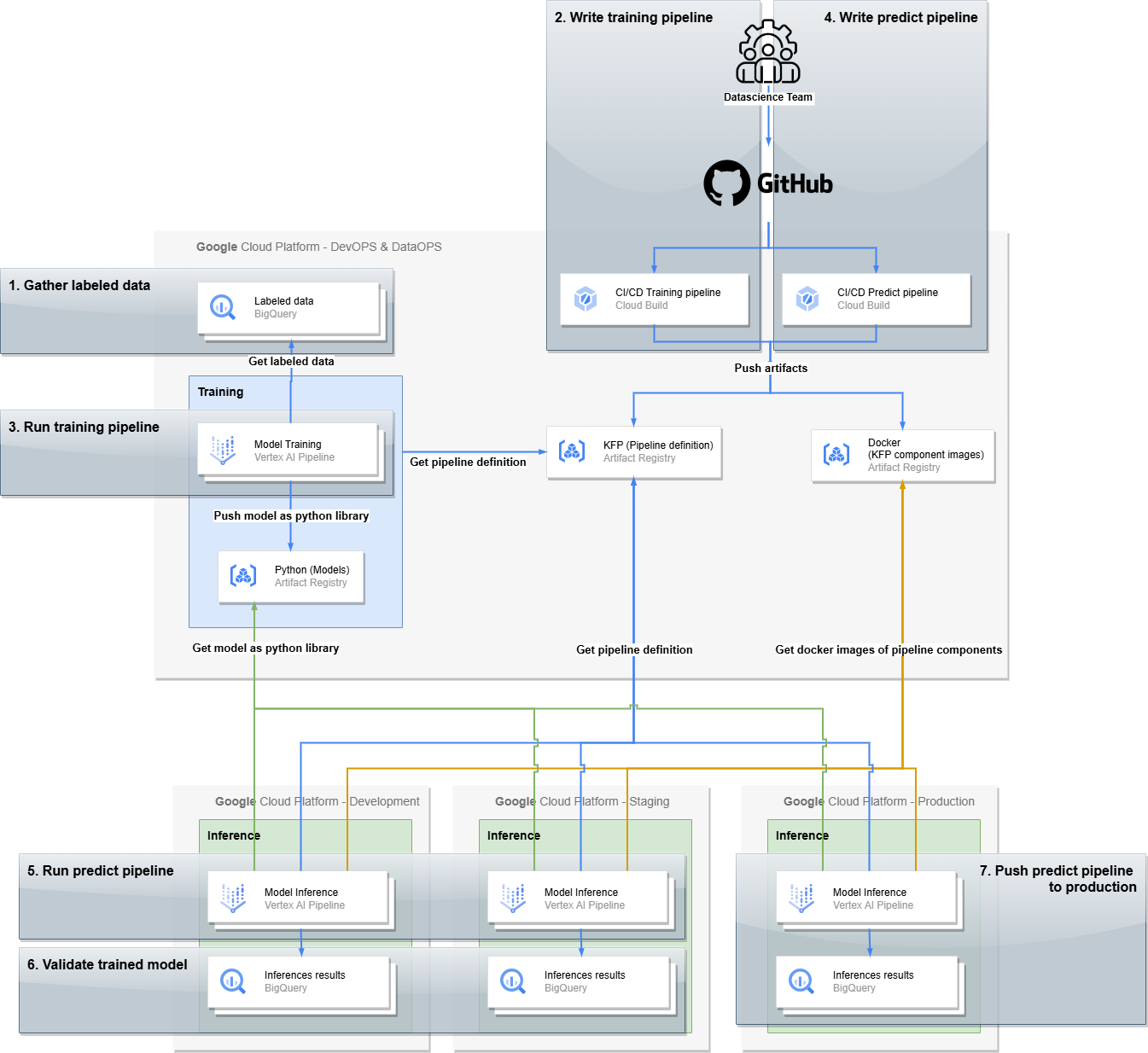
上の図は、複数の環境と必要なインフラストラクチャの関係を示したものです。重要なポイントを以下に挙げます。
-
モデル トレーニング パイプラインは、トレーニング済みモデルを埋め込んだ Python パッケージを出力します。
-
CI / CD パイプラインは、Kubeflow Pipelines(KFP)パイプライン定義と、そのコンポーネントに関連する Docker イメージを出力します。
-
新しいモデルを作成するための「Training(トレーニング)」と、予測を生成するための「Inference(推論)」という 2 つの運用上の構成要素があります。
MLOps プラットフォームの主要コンポーネントの詳細
プラットフォームの運用の中核となるのが KFP です。その役割を理解するために、Vertex パイプラインとは何かを定義します。
「パイプラインとは、コンポーネントを組み合わせてコンピューティングの有向非巡回グラフ(DAG)を形成するワークフローの定義です。実行時には、各コンポーネントの実行は単一のコンテナの実行に対応し、ML アーティファクトが作成される場合があります。パイプラインには制御フローが含まれる場合もあります。」— Kubeflow のドキュメント
このセクションでは、2 つの主要な運用上の構成要素である「トレーニング」と「推論」を、L'Oréal Tech Accelerator がどのように構築および管理するかに焦点を当てます。
トレーニング パイプライン
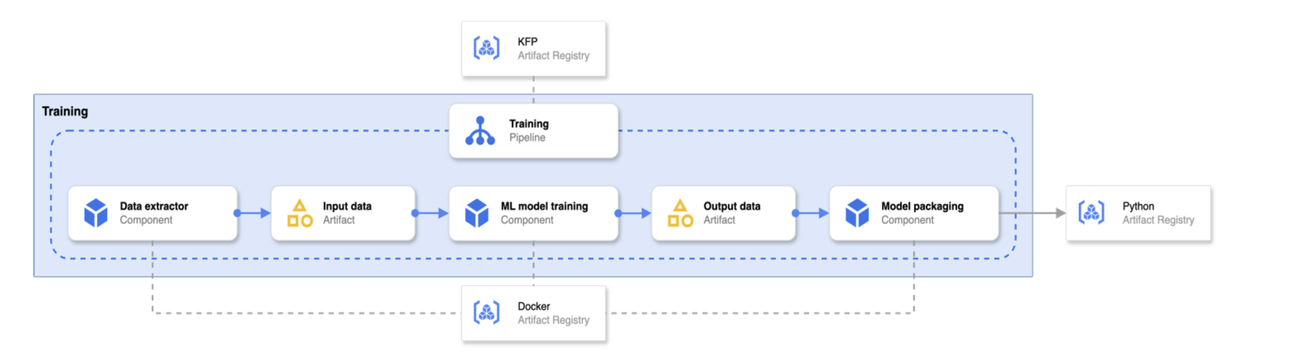
トレーニング パイプラインのアーキテクチャは、効率性と再現性を考慮して設計されています。その仕組みをご紹介します。
-
パイプラインの定義とコンポーネント: パイプラインの定義は KFP アーティファクト レジストリから取得され、個々のパイプライン ステップを実行するコンテナ イメージは Docker アーティファクト レジストリから取得されます。これらのアーティファクトは CI / CD パイプラインによって作成および管理され、バージョン管理と一貫性が確保されます(「L'Oréal の MLOps プラットフォームの概要」を参照)。
-
モデルのトレーニングとパッケージ化: 新しいトレーニング パイプラインの実行が完了すると、新しいトレーニング済みモデルは Python ライブラリにパッケージ化されるため、デプロイや統合が容易になります。
-
Model Registry: このパッケージ化されたモデルは、Python アーティファクト レジストリに push され、トレーニング済みモデルの中央リポジトリが作成されます。これにより、モデルのバージョン管理、共有、デプロイが異なる環境でも容易になります。
推論パイプライン
推論パイプラインは、トレーニング パイプラインと同様のアーキテクチャを採用しており、モデルのデプロイにおける一貫性と効率性を確保します。その仕組みをご紹介します。
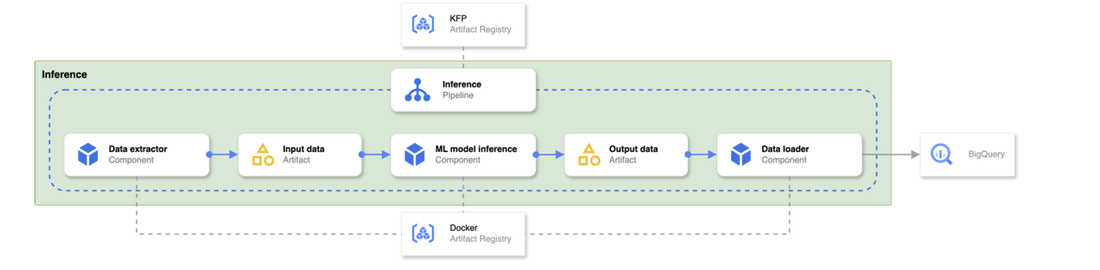
-
パイプラインの定義とコンポーネント: KFP を使用して定義された推論パイプラインの定義は、アーティファクト レジストリから取得されます。同様に、パイプラインに必要なコンポーネントを含む Docker イメージは、別のアーティファクト レジストリから取得されます。
-
CI / CD インテグレーション: これらのパイプライン定義と Docker イメージは、CI / CD パイプラインによって作成およびデプロイされます。推論パイプラインは常に最新の状態に保たれ、最新の検証済みコンポーネントが使用されます。
モジュール性と依存性の課題
従来の ML パイプラインでは、多くの場合、その定義を単一の共有コードベースに依存していました。これにより、複数のチームがパイプラインの開発に協力や貢献をする必要がある場合に、問題が生じる可能性があります。このようなチームがすべて同じコードベースで作業すると、以下のような理由で摩擦が生じ、開発プロセスに遅れが生じる可能性があります。
-
マージの競合: 複数のチームが同じファイルを同時に編集する場合に発生します。
-
インテグレーションの課題: 別々のチームによって開発された異なるコンポーネントをシームレスに連携する必要があります。
-
バージョン管理の複雑さ: 複数のバージョンのパイプラインの管理や更新が必要です。
デプロイのボトルネック: 異なるチームが変更を加える必要がある場合、デプロイの調整が必要です。
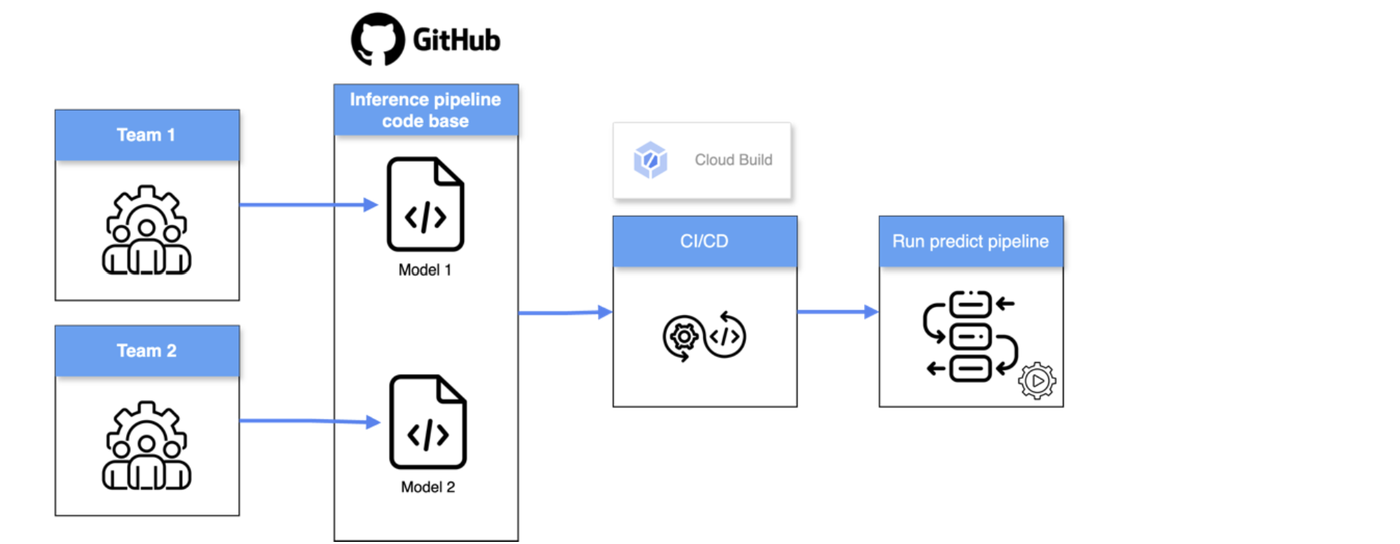
たとえば、2 つのチームが同じコードベース内の別々のモデル(Model 1、Model 2)で作業している場合(上図を参照)、一方のモデルのパイプラインが失敗すると、もう一方のモデルの推論パイプラインの実行が妨げられる可能性があります。これにより、システム全体に影響を及ぼす単一障害点が生じます。
この問題に対処するには、パイプライン開発において、よりモジュール化され、独立したアプローチが必要です。それにより、個々のチームが他のチームに影響を与えることなく、それぞれのコンポーネントに取り組めるようにします。
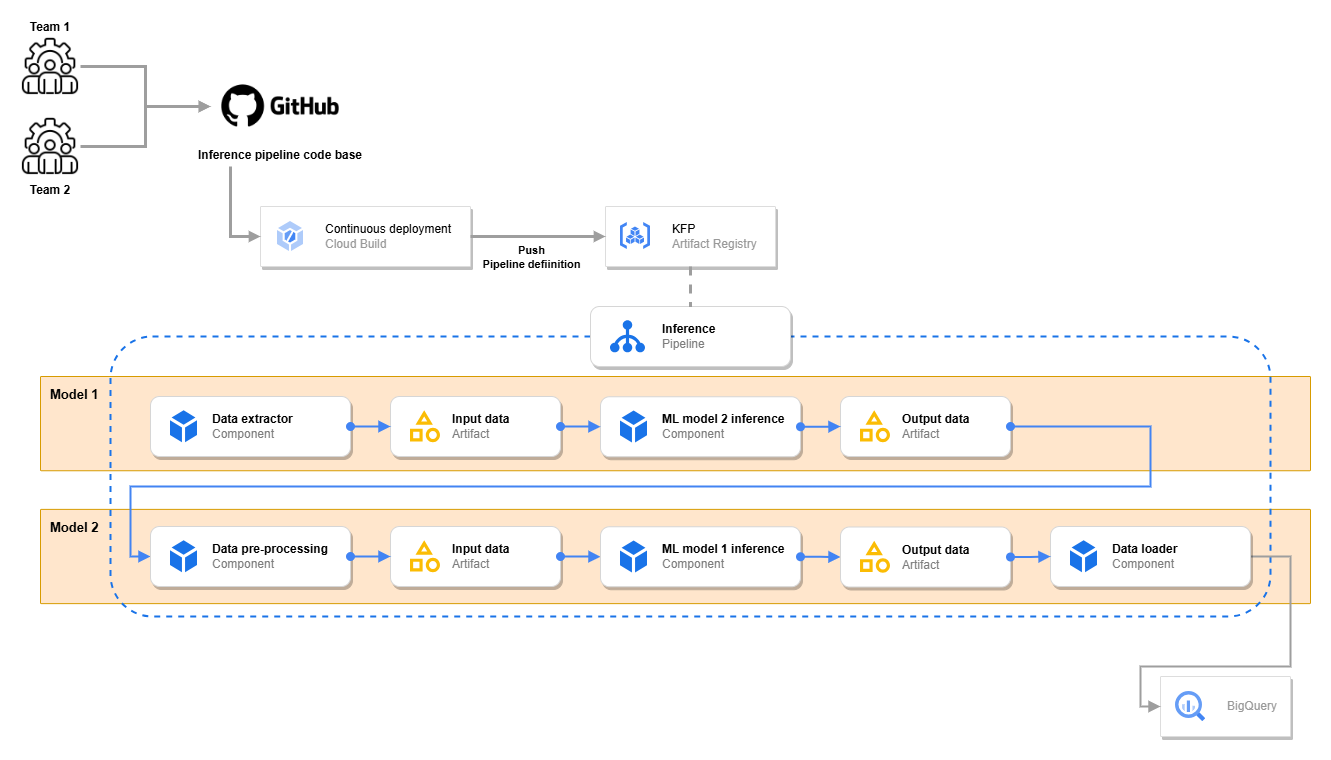
上の図は、先に説明した例と問題に対する ML パイプライン定義とインフラストラクチャを示したものです。
解決策
L’Oréal Tech Accelerator のソリューションでは、KFP アーティファクト レジストリを使用して、パイプライン開発にモジュール式のアプローチを採用しています。これにより、それぞれが独自のコードベースと CI / CD パイプラインを備えた独立したサブ パイプラインを作成できます。この分離により、以下のような大きなメリットがもたらされます。
-
独立した開発: 各チームは、互いの進捗やデプロイに干渉されることなく、サブ パイプラインで自律的に作業できます。これにより、チーム間の摩擦が軽減され、開発サイクルが加速されます。
-
テストとバージョニングの分離: 各サブ パイプラインは個別にテストおよびバージョニングを行えるため、あるコンポーネントの変更が他のコンポーネントに誤って影響を与えることがなくなります。
アジリティの向上: このモジュール性により、システム全体に影響を与えることなく、各チームがサブ パイプラインを迅速に適応および更新できます。
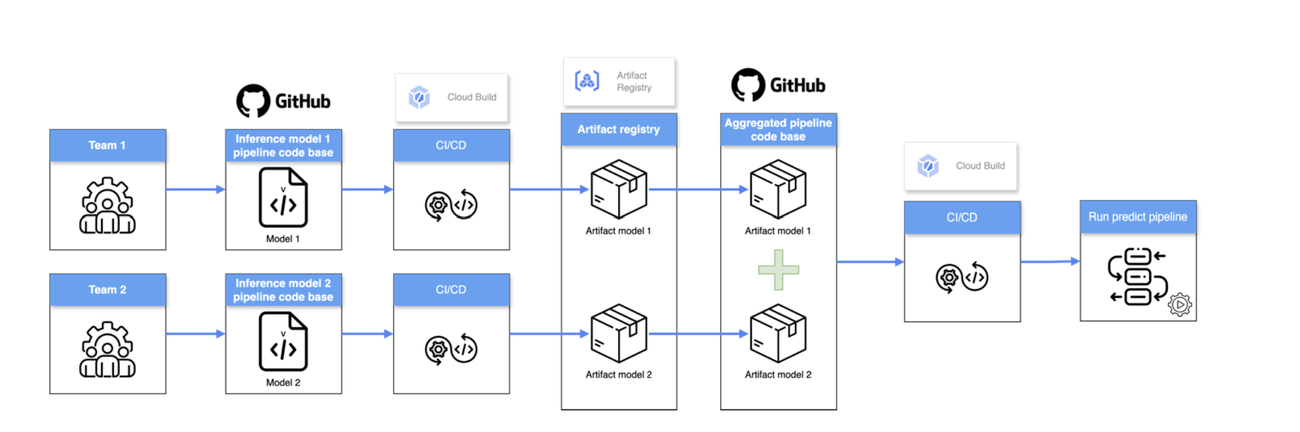
上記に加えて、L'Oréal Tech Accelerator では、オーケストレーターとして機能する追加のコードベースを導入しています。このオーケストレーターは、各サブ パイプラインの出力アーティファクトを構成要素として使用し、個々のサブ パイプラインを一貫したワークフローに統合します。このアプローチは、独立した開発のメリットと統合パイプラインのパワーを組み合わせたものです。
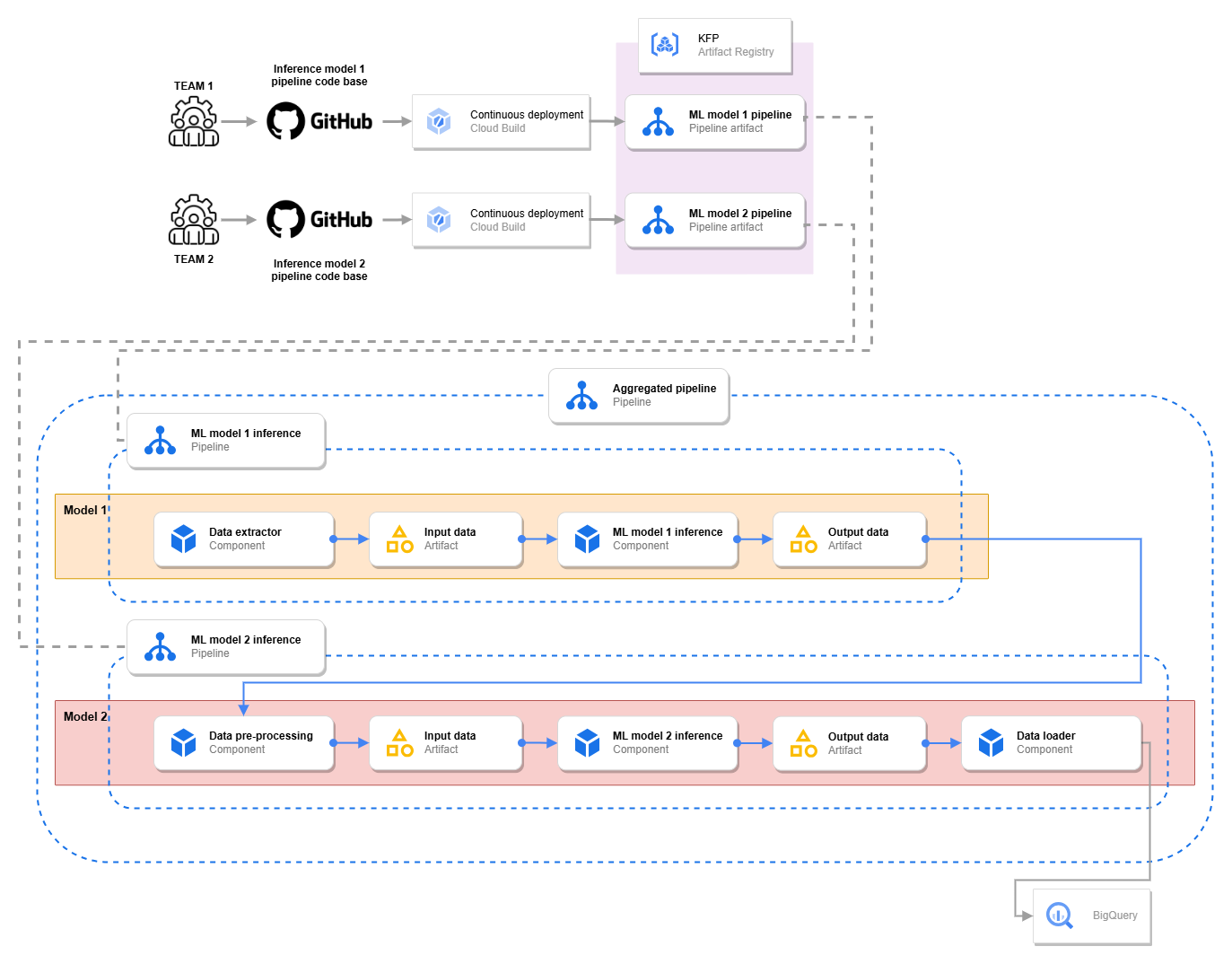
上の図は、このソリューションの ML パイプライン定義とインフラストラクチャを示したものです。
例: 集約パイプラインのコード スニペット
以下のコード スニペットは、集約モジュールの使いやすさを示したもので、異なるチームによる複数の予測パイプラインとモデルを組み合わせる例です。このオーケストレーション レイヤにより、個々のコンポーネントを統一されたワークフローにシームレスに統合できます。
まとめ、次のステップ
Google Cloud に構築した L'Oréal のモジュール式 MLOps プラットフォームにより、AI 開発プロセスの効率性とアジリティが大幅に向上しました。各チームがそれぞれの ML モデルで独立して作業できるようになったほか、L'Oréal Tech Accelerator によって開発の加速とコラボレーションの改善が実現し、システムの品質と信頼性も向上しました。
現在のプラットフォームはすでに大きなメリットをもたらしていますが、引き続き最適化を進めています。
特に重点を置いているのは、Docker イメージのサイズを増加させ、パイプラインの速度を低下させる可能性がある、大規模なモデル アーティファクトの課題への対応です。この問題を軽減するために、L'Oréal Tech Accelerator では、オンデマンド モデルのダウンロードや API 駆動型の推論などのソリューションを模索しており、ビューティ テックのイノベーションの最前線に立ち続けることを目指しています。
今回の執筆にあたり、Kerebel Paul-Sirawit 氏(L’Oréal、DevOps & Cloud Lead)、Sokratis Kartakis 博士(Google、生成 AI ブラックベルト)、Christophe Dubos(Google、プリンシパル アーキテクト)からご支援をいただきました。心から感謝の意を表したいと思います。冒頭画像クレジット: Ben Hassett / Myrtille Revemont / Helena Rubinstein pour L’Oréal
-L’Oréal、Tech Accelerator 最高技術責任者 Moutia Khatiri 氏



