Google Cloud での画像生成パイプライン最適化: 実践ガイド

Gopala Dhar
AI Engineering Lead, Google Cloud Consulting
Kartik Chaudhary
Lead AI/ML Engineer, Google Cloud Consulting
※この投稿は米国時間 2025 年 2 月 22 日に、Google Cloud blog に投稿されたものの抄訳です。
Stable Diffusion や Flux などの生成 AI 拡散モデルは、生成するビジュアルの品質が高く、さまざまな分野のクリエイターにとって心強い画像生成ツールとなります。しかし、高度なパイプラインによる高品質な画像の生成には多大なコンピューティング能力が求められるため、費用がかさみ、結果を得るまでの時間にも影響します。これは GPU や TPU などの強力なハードウェアを使用しても変わりません。
主な課題は、画像の品質を損なうことなく、費用とレイテンシを最小限に抑えるようパイプライン全体を最適化することです。実際のアプリケーションで画像生成の可能性を最大限に引き出すためには、この絶妙なバランスが不可欠です。たとえば、モデルサイズを縮小して画像生成費用を削減する前に、基盤となるインフラストラクチャとソフトウェアを最適化して、モデルの最高のパフォーマンスを確保することを優先します。
Google Cloud コンサルティングは、お客様がこうした複雑な状況を乗り切れるよう支援してきました。最適化された画像生成パイプラインの重要性を理解しています。この投稿では、効率性と費用対効果の両方を実現して優れたユーザー エクスペリエンスを提供するための 3 つの実証済みの戦略をご紹介します。
最適化のための包括的なアプローチ
ハードウェアからコード、アーキテクチャ全体に至るまで、パイプラインのあらゆる側面に対応する包括的な最適化戦略を策定することをおすすめします。Google Cloud では、TPU や GPU などのハードウェアと、Pytorch などのソフトウェアやフレームワークを組み合わせたコンポーズ可能なスーパーコンピューティング アーキテクチャである AI Hypercomputer でこの問題に対処しています。主な取り組み分野は次のとおりです。
1. ハードウェアの最適化: リソース運用効率の最大化
画像生成パイプラインでは、デプロイに GPU か TPU が必要になることが多く、ハードウェアの使用率を最適化することで費用を大幅に削減できます。GPU を部分的に割り当てることはできないため、特にワークロードのスケーリング時には未使用率が高くなりやすく、効率の低下と運用コストの増加につながります。この問題に対処するために、Google Kubernetes Engine(GKE)には、リソース効率を向上させるための GPU 共有戦略がいくつか用意されています。また、NVIDIA H100 80 GB GPU を搭載した A3 High VM はサイズが小さいため、効率的にスケーリングして費用を調節しやすい VM です。
GKE の主要な GPU 共有戦略には、次のようなものがあります。
-
マルチインスタンス GPU: この戦略では、GKE で 1 つの GPU を最大 7 つのスライスに分割することで、ワークロード間でハードウェアを分離します。各 GPU スライスには独自のリソース(コンピューティング、メモリ、帯域幅)があり、1 つのコンテナに個別に割り当てることができます。この戦略は、復元力と予測可能なパフォーマンスが求められる推論ワークロードに活用できます。実装する前に、このアプローチの制限事項を文書で確認してください。留意すべきは、GKE のマルチインスタンス GPU で現在サポートされている GPU タイプは、NVIDIA A100 GPU(40 GB と 80 GB)と NVIDIA H100 GPU(80 GB)であるということです。
-
GPU タイム シェアリング: GPU タイム シェアリングでは、プロセス間の高速なコンテキストの切り替えを使用して、複数のコンテナが GPU の全容量にアクセスできます。これは、NVIDIA GPU の命令レベルのプリエンプションによって可能になります。このアプローチは、バースト型のインタラクティブなワークロードや、完全な分離が不要なテストやプロトタイピングにより適しています。GPU タイム シェアリングを使えば、GPU のアイドル時間が短縮され、GPU の費用と使用率を最適化できます。ただし、コンテキストの切り替えにより、個々のワークロードにレイテンシのオーバーヘッドが生じる可能性があります。
- NVIDIA Multi-Process Service(MPS): NVIDIA MPS は CUDA API のバージョンの一つであり、複数のプロセス / コンテナを同じ物理 GPU 上で干渉を受けずに同時に実行できます。このアプローチでは、単一の GPU で小規模から中規模の複数のバッチ処理ワークロードを実行し、スループットとハードウェアの使用効率を最大化できます。MPS を実装する際は、MPS を使用するワークロードがメモリ保護とエラーの封じ込めに関する制限を許容できることを確認する必要があります。
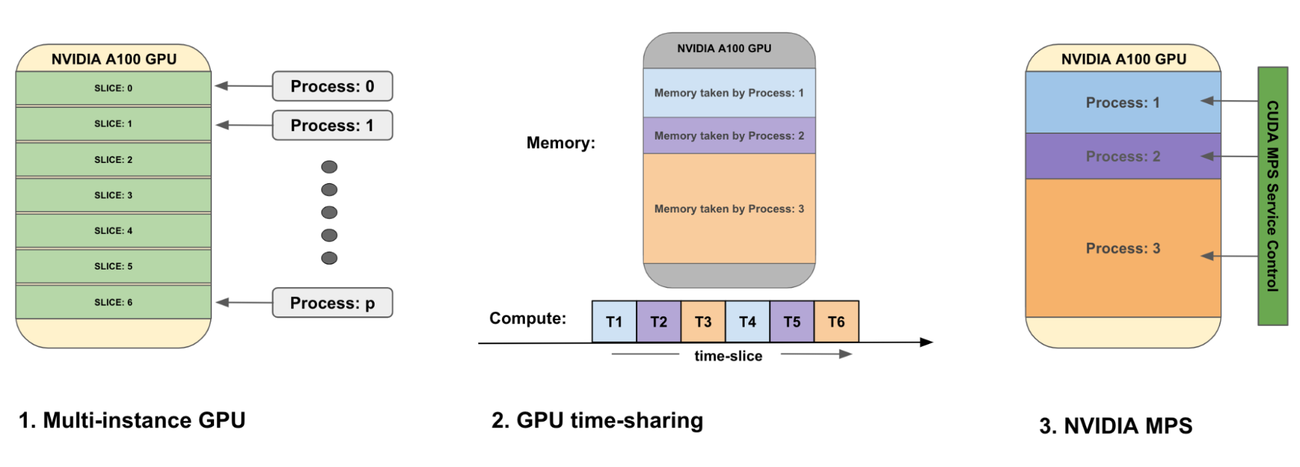
GPU 共有戦略の例を示すイラスト
2. 推論コードの最適化: 有効性を高めるためのファインチューニング
PyTorch でネイティブに記述されたパイプラインについては、その実行時間を最適化して短縮する方法がいくつかあります。
一つの方法は、PyTorch のコンパイル メソッドを使用することです。これにより、PyTorch コードを最適化されたカーネルに JIT(Just-in-time)コンパイルして実行を高速化できます。特にデコーダ ステップのフォワードパスの実行に有効です。基盤となるハードウェアに応じて、NVIDIA TensorRT、OpenVINO、IPEX などのさまざまなバックエンド コンピュータを使用したり、トレーニング時に特定のコンパイラ バックエンドを使用したりすることもできます。同様の JIT コンパイル機能は、JAX などの他のフレームワークでも利用できます。
コードのレイテンシを改善するもう一つの方法は、Flash Attention を有効にすることです。torch.backends.cuda.enable_flash_sdp 属性を有効にすると、PyTorch コードは Flash Attention をネイティブに実行し、特定のコンピューティングを高速化します。入力に基づく Flash が最適でない場合、別のアテンション機構が自動的に選択されます。
レイテンシを低減するには、GPU と CPU の間でのデータ転送を最小限に抑える必要もあります。テンソルの読み込みや、テンソルと Python の float の比較などのオペレーションでは、データ移動に伴うオーバーヘッドが非常に大きくなります。テンソルを浮動小数点値と比較するたびに CPU に転送する必要があり、レイテンシが発生します。GPU へのテンソルの読み込みとオフロードは、画像生成パイプライン全体で 1 回だけにとどめるのが理想です。これは、複数のモデルを利用する画像生成パイプラインでは特に重要です。こうしたパイプラインでは、実行される各モデルでレイテンシが連鎖的に発生するからです。PyTorch Profiler などのツールは、モデルの使用時間とメモリ使用量をモニタリングするのに役立ちます。
3. 推論パイプラインの最適化: ワークフローの合理化
コードを最適化すると、パイプライン内の個々のモジュールを高速化できますが、全体像をとらえることが重要です。マルチステップの画像生成パイプラインの多くは、複数のモデル(サンプラー、デコーダ、画像エンベディング モデル、テキスト エンベディング モデルなど)を次々にカスケードして最終的な画像を生成します。多くの場合、1 つの GPU が接続された単一のコンテナで実行されます。
拡散ベースのパイプラインでは、デコーダなどのモデルはコンピューティングの複雑さが大幅に増すため、実行に時間がかかります。一般的に高速なエンベディング モデルと比較すると特に顕著です。つまり、特定のモデルが生成パイプラインのボトルネックとなる可能性があるということです。GPU 使用率を最適化し、このボトルネックを軽減するには、マルチスレッド キューベースのアプローチを採用して、タスクのスケジューリングと実行を効率化することを検討してください。このアプローチにより、同じ GPU 上で異なるパイプライン ステージを並列実行できるため、複数のリクエストを同時に処理できます。ワーカー スレッド間でタスクを効率的に分散することで、GPU のアイドル時間を最小限に抑え、リソースの運用効率を最大化できるため、最終的にスループットが向上します。
また、プロセス全体で同じ GPU 上にテンソルを保持することで、CPU から GPU への(およびその逆の)データ転送のオーバーヘッドを削減できるので、さらなる効率向上と費用削減も見込めます。

2 つの同時リクエストに対するスタック パイプラインとマルチスレッド パイプラインの処理時間の比較
最後に
画像生成パイプラインの最適化は多面的なプロセスですが、その見返りは大きいものです。ハードウェアの最適化によるリソース運用効率の最大化、コードの最適化による実行速度の向上、パイプラインの最適化によるスループットの改善などを含めた包括的なアプローチを採用することで、パフォーマンスを大幅に強化して費用を削減するとともに、優れたユーザー エクスペリエンスを実現できます。お客様との取り組みにおいて、これらの最適化戦略を実装することで、画像の品質を損なうことなく大幅な費用削減につながることが一貫して確認されています。
準備ができたら
Google Cloud コンサルティングは、お客様が高性能な AI ソリューションを構築してデプロイできるよう支援しています。画像生成パイプラインの最適化をご検討中の方は、今すぐ Google Cloud コンサルティングにご連絡ください。AI イニシアチブの可能性を最大限に引き出すお手伝いをいたします。
重要なテストの段階で貴重なサポートとガイダンスを提供してくれた Akhil Sakarwal、Ashish Tendulkar、Abhijat Gupta、Suraj Kanojia に感謝します。
- Google Cloud、AI エンジニアリング リード Gopala Dhar
- Google Cloud コンサルティング、リード AI / ML エンジニア Kartik Chaudhary



