コンテキスト アウェアなコード生成: 検索拡張と Vertex AI の Codey API
Google Cloud Japan Team
※この投稿は米国時間 2024 年 2 月 14 日に、Google Cloud blog に投稿されたものの抄訳です。
検索拡張生成(RAG)とは外部のデータや情報を利用して大規模言語モデル(LLM)の精度を向上させる方法です。本ブログ投稿では、Vertex AI の Codey API を使用し、コード補完およびコード生成用の Google Cloud AI モデルの出力精度を RAG を使用して向上させる方法を紹介します。Codey API はコード生成モデルのスイートであり、ソフトウェア開発者によるコーディング タスクの迅速化に役立ちます。Codey API には以下の 3 種類があり、開発者の生産性向上を支援します。
- コード補完: 現在のコンテキストに基づいてコードの候補が即時に示されるため、コーディングをシームレスで効率的に行えます。この API は IDE やエディターなどのアプリケーションに統合できるように設計されており、コードを記述する際にコードのオートコンプリートの候補を低レイテンシで提供します。
- コード生成: 必要なコードを自然言語で説明することにより、関数やクラスなどのコード スニペットを数秒で生成します。この API は、多数のコードを早急に記述する必要があるときや、着手の糸口が必要なときに役立ちます。IDE、エディター、CI / CD ワークフローを含むその他のアプリケーションに統合できます。
- コードチャット: ソフトウェア開発のライフサイクル全体を通じて、コーディングに関する支援を得られます。たとえば、厄介な問題をデバッグしたり、洞察に満ちた提案や回答で知識の幅を広げたりできます。このチャット API はマルチターン チャットが可能で、チャット アシスタントとして IDE やエディターへの統合が可能です。また、バッチ ワークフローでも使用できます。
これらのモデルには、ソース引用や有害性のチェックなどの責任ある AI 機能を統合することもできます。この機能では、Google が設定した責任ある AI ガイドラインに基づき、引用やコードのブロックを自動的に行います。
Codey API は、汎用コードの生成にとどまらず、はるかに多くのことを実現できます。組織の特定のスタイルに合わせてコード出力を調整し、組織のガイドラインに基づいてプライベート コード リポジトリへ安全にアクセスできます。これらのモデルはカスタマイズ可能であるため、確立されたコーディング基準や慣行を遵守したコードを生成できる一方で、コード生成タスクにあたってはカスタム エンドポイントと専有のコードベースを活用できます。
このようなレベルでのカスタマイズを実現するためには、企業のコードベースなどの特定のデータセットを使用してモデルをチューニングする方法があります。また別の方法として、RAG を活用して外部のナレッジソースをコード生成プロセスへと組み込む方法もあります。ここでは後者について、以下で詳しく説明します。
RAG とは
従来の LLM の範囲はその内部のナレッジベースに限られています。これにより、レスポンスが無関係なものやコンテキストに沿わないものになる場合もあります。この問題に対処するため、RAG は外部検索システムを LLM に統合します。これにより、関連性のある情報をその場で取得し利用できるようになります。
この技法によって LLM は外部の信頼できるソースから情報を検索し、関連性のあるコンテキストを用いて入力を拡張して、より情報量のある正確なレスポンスを生成できるようになります。一例として、コード生成モデルが RAG を使用して既存のコード リポジトリから関連性のある情報を取得し、これを使用して正確なコードやドキュメントを作成したり、コードエラーを修正したりすることもできます。
RAG の仕組みとは
RAG の実装には、ユーザーのクエリに基づいて関連性のあるドキュメントを提供できる堅牢な検索システムが必要です。
RAG システムがコード生成に役立つ仕組みを、以下に簡単に示します。
- 検索メカニズムが関連性のある情報をデータソースから取得します。この情報にはコード、テキスト、その他のデータタイプが使用できます。
- 生成メカニズム(お使いのコード生成 LLM)が、検索された情報を使用して出力を生成します。
- こうして、入力クエリや質問に対してより高い関連性を有するコードが生成されます。
RAG は多様なアプローチが可能ですが、最も一般的な RAG のパターンは、ソース情報のチャンクからエンべディングを生成し、Vertex AI のベクトル検索などのベクトル データベース内でこれらをチャンクのインデックスとするというものです。
以下の図は、Codey API でのコード生成における RAG パターンの概要を示したものです。
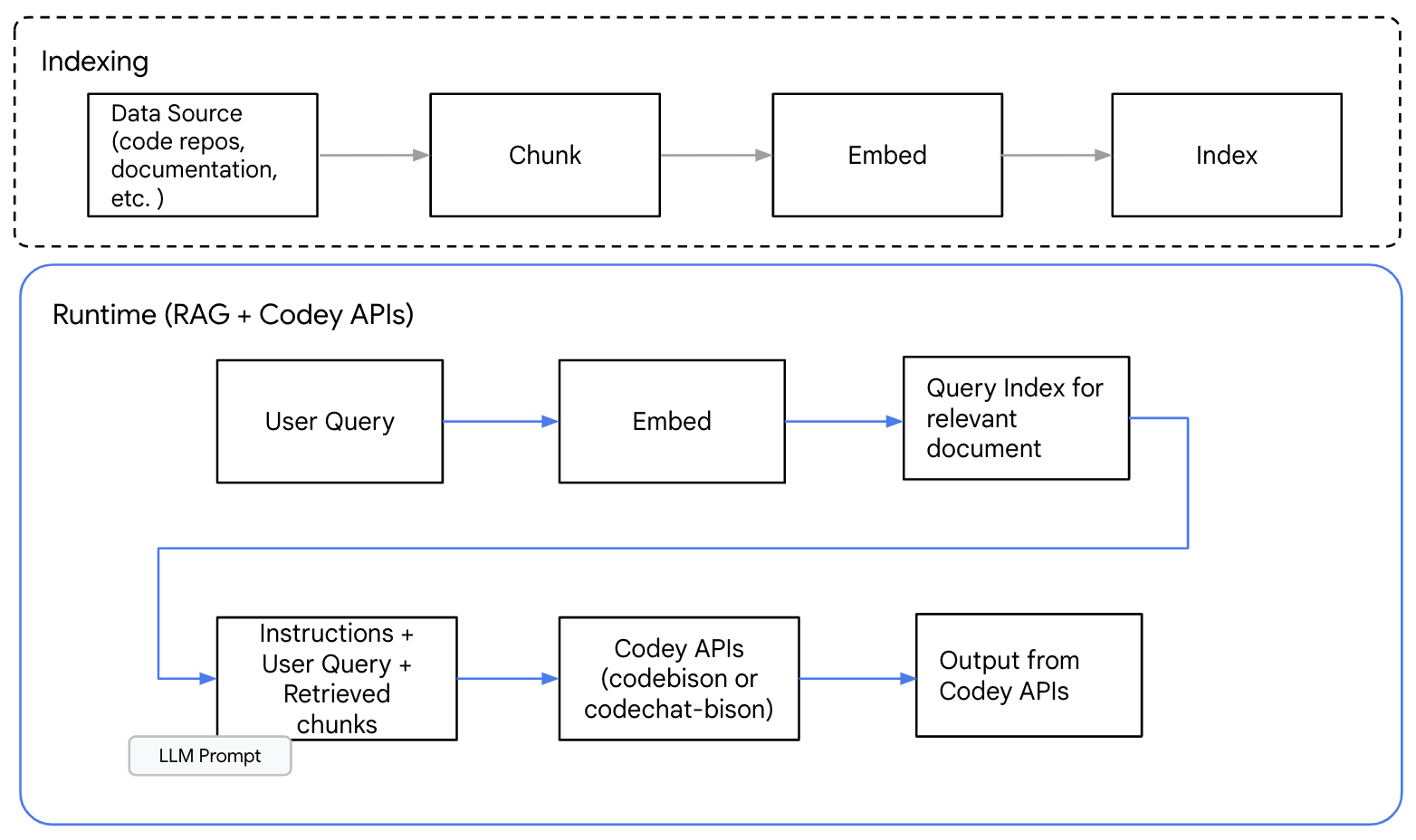
図 1: コード生成における RAG パターンの情報の流れの概要
最初のステップは、ソース情報の識別です。コード生成では API 定義、コード リポジトリ、ドキュメントなどが該当するでしょう。次に、分割スキームを決定する必要があります。情報を分割することで、クエリ処理に必要な関連性のあるコンテンツのみを選択し提供できます。
RAG の使用にあたっては、テキスト生成のために必要なコンテキスト情報を保持する分割アプローチが最適です。コード分割のメソッドは、関数、クラス、モジュールの境界など、自然な境界を尊重した分割メソッドを選択することをおすすめします。句や文の途中など、無作為に分割する技法は、コンテキストを分断し出力の質を低下させる恐れがあります。
情報ソースから情報のチャンクを作成したのち、エンベディングを生成して、ベクトル データベース内でこれをインデックスとすることができます。クエリを受け取ると、クエリのための新たなエンベディングが生成され、これを使用して関連性のある情報チャンクを検索します。
そして、プロンプト、ユーザーの質問、関連性のある情報チャンクが Codey API へ送られ、レスポンスが生成されます。
Codey API による RAG の使用
RAG について理解したところで、Vertex AI の Codey モデルでコード生成が行われる仕組みを見ていきます。
このデモンストレーションでは、Google Cloud の生成 AI の GitHub リポジトリにあるサンプルコードと Jupyter ノートブックをデータソースとして使用しました。リポジトリ全体をクロールし、Jupyter ノートブックをすべてリストアップしました。その後、これらのノートブックを分析し、コードの要素を抽出しました。この要素が分割され、ベクトル データベース内でインデックス付けされました。これらの手順については、こちらのノートブック内で詳しく説明しています。
以下の例は、プロンプトに対し、RAG による外部コンテキストの追加を使用せずに生成されたレスポンスです。
プロンプト: 「VertexAI text-bison モデル向けの langchain.llms インターフェースを使用して、プロンプトを受け取り予測する Python 関数を作ってください。」
RAG を使用しない場合のレスポンス:
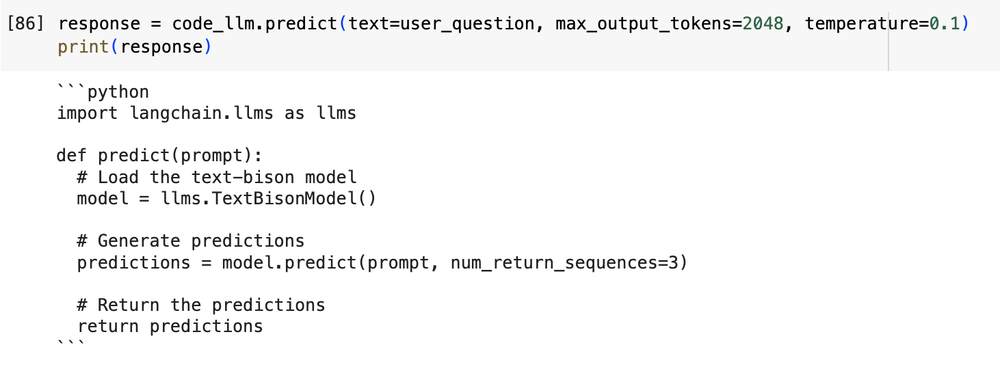
図 2: 外部コンテキストを使用しない場合のモデルからのレスポンス
上の例では、この LLM は Langchain ライブラリについての事前の知識を持ちません。レスポンスは一見もっともらしく、一貫性があるようですが、これはハルシネーションです。実際は、生成されたコードはこの text-bison モデルを正確にインスタンス化しておらず、Predict 関数を呼び出していません。
次に、RAG を使用して同じプロンプトを与えてみます。
RAG を使用した場合の出力:
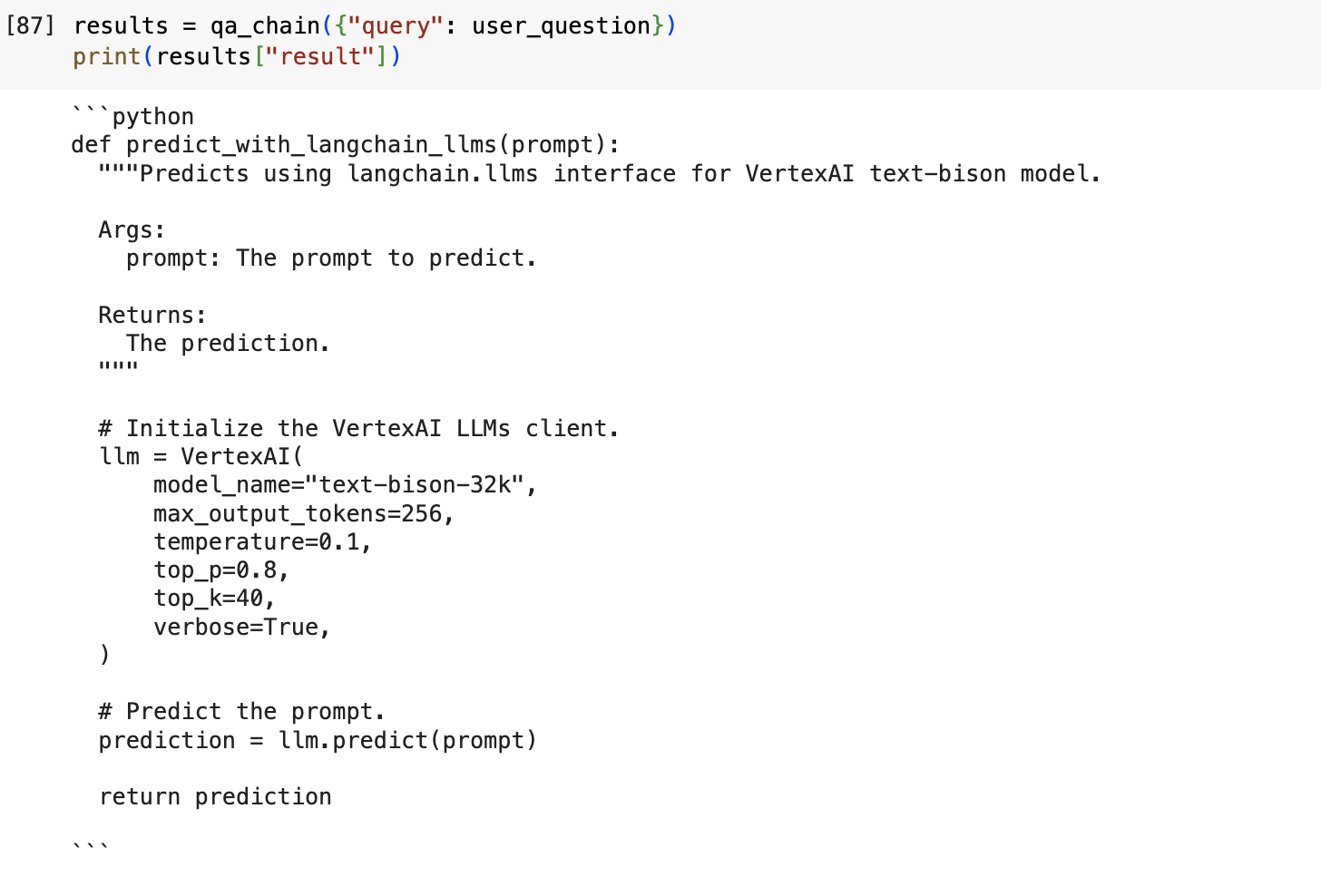
図 3: 検索拡張生成(RAG)を使用した場合の出力
RAG により、Codey は Google Cloud GitHub リポジトリからコードを動的に注入することができました。そして、Vertex AI text-bison モデルから Langchain API への呼び出しを行うことができる構文を正確に用いたコードを出力できました。
RAG の一般的なユースケースおよび RAG の限界
RAG は LLM によるコード生成やテキスト生成の精度向上に役立つものですが、その一方で、完璧なソリューションではないことを考慮することが重要です。場合によっては、RAG が不正確な結果や紛らわしい結果を生成するケースもあります。その理由は、RAG が使用するナレッジベースや外部ソースが不正確あるいは最新のものでない場合があること、あるいは LLM がナレッジベースから取得した情報を正確に解釈できない場合があることです。
この点を踏まえ、Codey API での RAG の使用は、以下に当てはまる場合におすすめします。
- モデルが、サポートされた言語の範囲内でコードのバリエーションを生成できる場合。たとえば、RAG を使用して別のコーディング スタイルを探索したり、特定の SQL のバリエーションにコードを適合させたりするなど。
- コード生成に使用したソースに対して透明性を確保し引用をする必要がある場合。
- 使用するモデルが、コードの鮮度が確保できる最新のコードベースを用いて分析および学習ができる場合。
- ユーザーが多様なコーディング パターンや微妙な差異について深く理解しており、既存のコードモデルを使用して、より優れたコード補完やターゲット関数の生成を行う場合。
RAG はファインチューニングの代わりになるのか
RAG と、教師ありチューニングは、コードモデルのパフォーマンス向上を目的とした別々の技法です。互いに補完的なアプローチであり、それぞれに独自の強みと弱みがあるため、併用することもできます。
たとえば、まず先に教師ありチューニングを用いて、特定のドメインやタスクにおいて Codey モデル(code-bison)をチューニングしてから、次に RAG を用いて、大規模データベースの情報によりモデルのナレッジを拡張できます。モデルをファインチューニングする方法について詳しくは、こちらのガイダンスをご覧ください。
RAG 使用の限界
RAG は LLM によるコード生成やテキスト生成の精度向上や情報量増加に役立つものですが、その一方で、完璧なソリューションではないことを考慮することが重要です。
場合によっては、RAG が不正確な結果や紛らわしい結果を生成するケースもあります。その理由は、RAG が使用するナレッジベースや外部ソースが不正確あるいは最新のものでない場合があること、あるいは LLM がナレッジベースから取得した情報を正確に解釈できない場合があることです。
使ってみる
Codey の使用を開始するには、Vertex AI の無料トライアルにご登録ください。Vertex AI アカウントを作成すると、Codey インスタンスを作成し、コードモデル API の使用を開始できます。
ベクトル データベースが必要な場合は、優れたパフォーマンス、価格、業界トップクラスの機能を備えた ベクトル検索 をご検討ください。コード スニペットを使用せず、非構造化または構造化(テーブル)ドキュメントの RAG 検索をご希望の場合は、Vertex AI Search でプロセス全体が容易になります。
-Vertex AI、プロダクト マネージャー Parashar Shah
-エンタープライズ AI / ML カスタマー エンジニア Harkanwal Bedi



