Vertex AI Gen AI Evaluation Service でのエージェント評価のご紹介
Irina Sigler
Product Manager, Cloud AI
Ivan Nardini
Developer Relations Engineer
※この投稿は米国時間 2025 年 1 月 25 日に、Google Cloud blog に投稿されたものの抄訳です。
次世代の信頼できる AI を構築するには、包括的なエージェント評価が不可欠です。単に出力を確認するだけでは不十分で、エージェントがとったアクションの「理由」、つまり推論、意思決定プロセス、解決策に到達するまでの道筋を理解する必要があります。
そこでこのたび、Vertex AI Gen AI Evaluation Service の公開プレビュー版をリリースしました。この新機能は、デベロッパーが AI エージェントを厳密に評価し、理解できるようサポートします。この機能には、さまざまなフレームワークで構築されたエージェント向けに特別に設計された強力な評価指標のセットが含まれており、評価プロセスを合理化するためのネイティブなエージェント推論を行うことができます。
この投稿では、評価指標がどのように機能するかを探り、これをエージェントに適用する方法の例をご紹介します。
Vertex AI Gen AI Evaluation Service を使用してエージェントを評価する
評価指標には、最終回答と軌跡評価という 2 種類のカテゴリがあります。
最終回答では、「エージェントが目標を達成しているか?」というシンプルな質問をします。特定のニーズに応じて最終回答のカスタム基準を定義し、成功を測定できます。たとえば、小売 chatbot が適切なトーンとスタイルを使用して、正確な商品情報を提供するかどうかや、調査エージェントが調査結果を効果的に要約するかどうかを評価できます。
さらに、背後にあるエージェントの意思決定プロセスを分析するための軌跡評価を行うこともできます。軌跡評価は、エージェントの推論を理解し、潜在的な間違いや非効率性を特定し、最終的にパフォーマンスを改善するために非常に重要です。そのために、以下の 6 つの軌跡評価指標が用意されています。
1. 完全一致: AI エージェントに、理想的な解決策を完全に反映した一連のアクション(「軌跡」)を生成することを要求します。
2. 順序一致: エージェントの軌跡は、必要なアクションを正しい順序ですべて含んでいる必要がありますが、余分で不必要なステップも含まれる可能性があります。たとえば、レシピどおりに料理するものの、途中でさらにスパイスを加えるようなものです。
3. 順序を問わない一致: この指標はさらに柔軟で、エージェントの軌跡が、順序に関係なく、必要なアクションをすべて含むかどうかだけが確認されます。これは、どのようなルートを通るかにかかわらず目的地に到達するようなものです。
4. 適合率: この指標はエージェントのアクションの正確さに焦点を当てます。予測された軌跡のアクションのうち、参照軌跡にも存在するアクションの割合を計算します。適合率が高ければ、エージェントが大抵は適切なアクションをとっていることを意味します。
5. リコール: この指標は、エージェントが重要なアクションをすべて捕捉できているかを測定します。参照軌跡のアクションのうち、予測された軌跡にも存在するアクションの割合を計算します。リコールが高ければ、エージェントが重要なステップをとり損なった可能性は低いことを意味します。
6. 単一ツールの使用: この指標は、エージェントの軌跡内に特定のアクションが存在するかどうかを確認します。エージェントが特定のツールや機能を利用することを学んだかどうかを評価するのに役立ちます。
互換性と柔軟性の両立
Vertex AI Gen AI Evaluation Service はさまざまなエージェント アーキテクチャに対応しています。
今回のリリースにより、Vertex AI 上のエージェント アプリケーションのマネージド ランタイムである Reasoning Engine(LangChain on Vertex AI)で構築されたエージェントを評価できるようになります。また、LangChain、LangGraph、CrewAI などのオープンソース フレームワークで構築されたエージェントにも対応しており、今後、新しい Google Cloud サービスによるエージェントの構築にも対応する予定です。
最大限の柔軟性を得るには、プロンプトを処理して回答を返すカスタム関数を使用してエージェントを評価します。評価をより簡単に行うために、ネイティブ エージェント推論を使用して、Vertex AI Experiments ですべての結果を自動的に記録することもできます。
エージェント評価の実例
次のような LangGraph カスタマー サポート エージェントがあり、エージェントが生成する回答と、その回答を生成するためにとられた一連のアクション(「軌跡」)の両方を評価しようとしているとします。
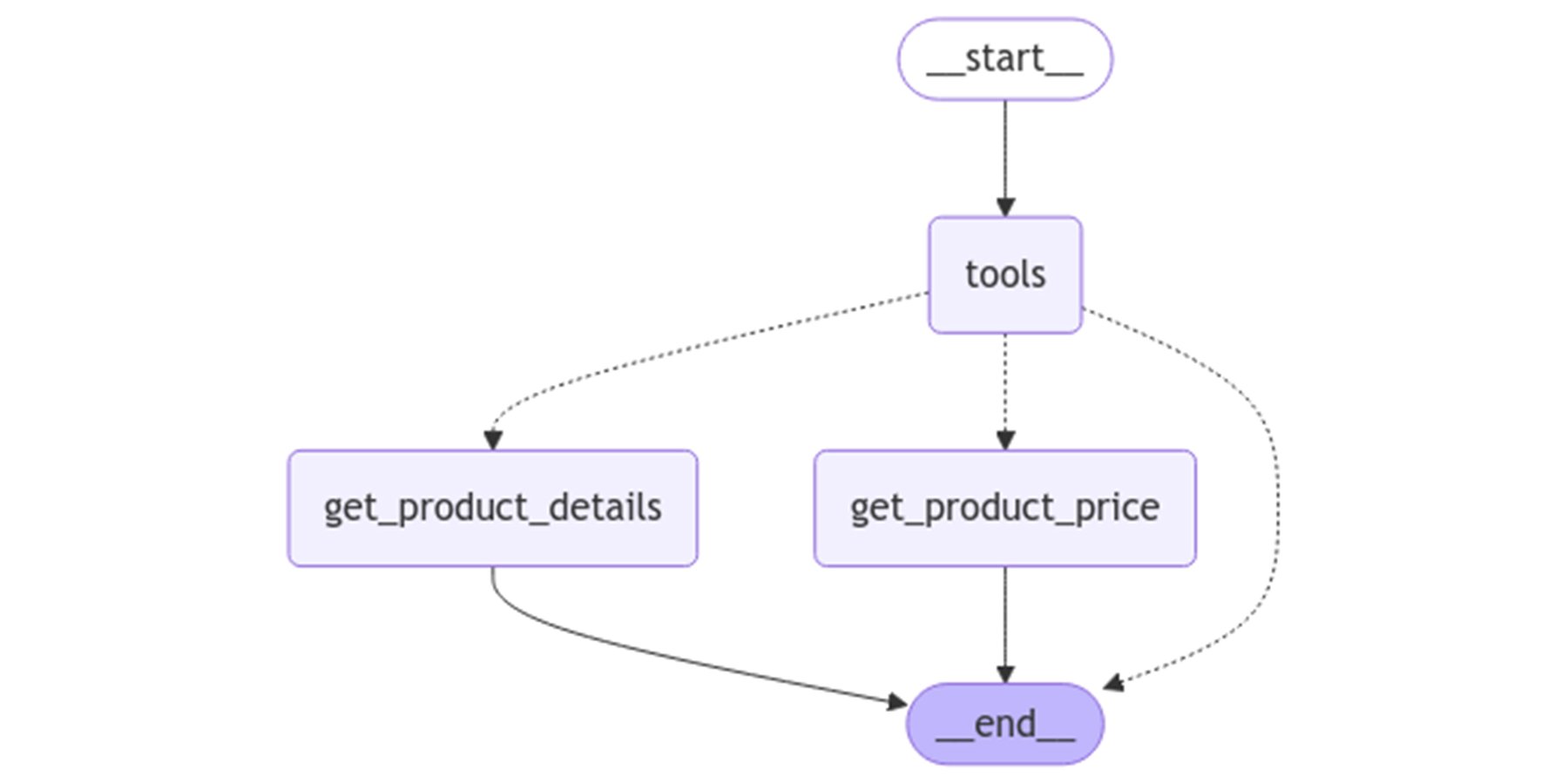
Vertex AI Gen AI Evaluation Service を使用してエージェントを評価するには、まず評価データセットを準備します。このデータセットには以下の要素が含まれていることが理想的です。
-
ユーザー プロンプト: ユーザーがエージェントに提供する入力。
-
参照軌跡: エージェントが正しい回答を提供するためにとるべき一連のアクション。
-
生成された軌跡: ユーザー プロンプトに対する回答を生成するためにエージェントが実際にとった一連のアクション。
-
回答: エージェントの一連のアクションに基づいて生成された回答。
以下は評価データセットのサンプルです。

評価データセットを収集したら、エージェントの評価に使用する指標を定義します。指標の一覧とその解釈については、生成 AI エージェントを評価するを参照してください。定義できる指標の一部を以下に示します。
response_follows_trajectory_metric は、エージェントを評価するために定義できるカスタム指標です。
標準的なテキスト生成指標(「一貫性」など)は、主にテキスト構造に焦点を当てるため、環境と対話する AI エージェントを評価する際には十分ではない可能性があります。エージェントの回答は、環境内での有効性に基づいて評価されるべきです。Vertex AI Gen AI Evaluation Service を使用すると、response_follows_trajectory_metric などのカスタム指標を定義して、エージェントの回答がツールの選択から論理的に続いているかどうかを評価できます。このような指標の詳細については、公式ノートブックを参照してください。
評価データセットと指標を定義できたら、Vertex AI で最初のエージェント評価ジョブを実行します。以下のコードサンプルをご覧ください。
評価を行うには、定義済みのデータセットと指標を使用して EvalTask を開始します。次に、evaluate メソッドを使用して評価ジョブを実行します。Vertex AI Gen AI Evaluation Service は、Vertex AI のマネージド テスト追跡サービスである Vertex AI Experiments 内で実行されるテストとして、生成された評価を追跡します。評価の結果は、ノートブックと Vertex AI Experiments UI の両方で確認できます。Colab Enterprise を使用している場合は、以下のように Experiment サイドパネルでも結果を確認できます。
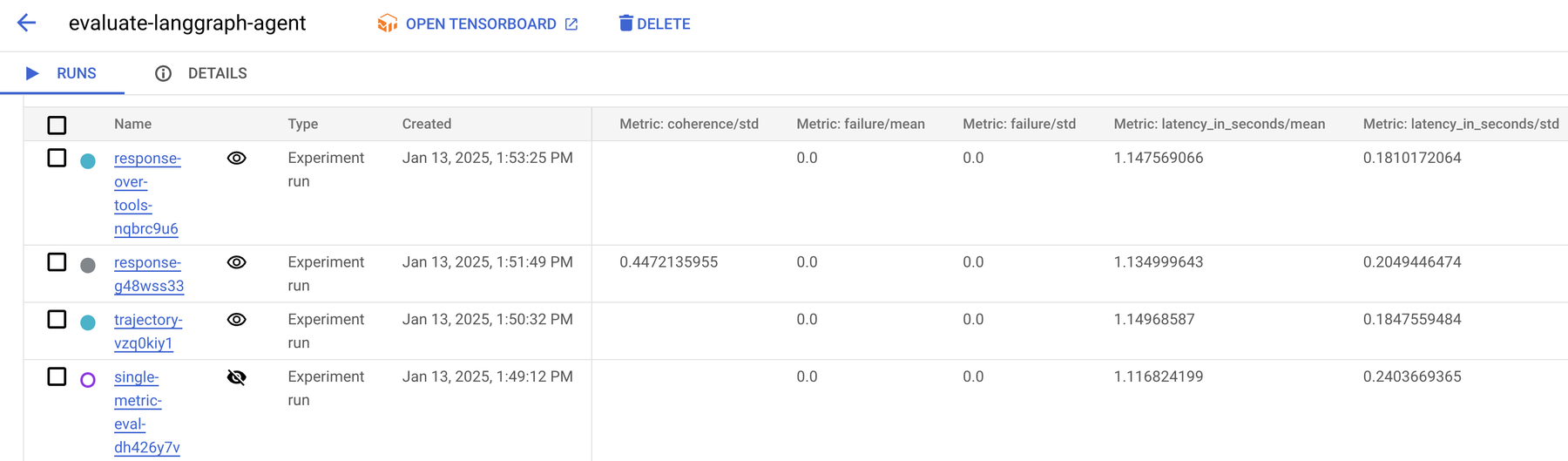
Vertex AI Gen AI Evaluation Service では、サマリーと指標のテーブルが提供されるので、エージェントのパフォーマンスに関する詳細な分析情報を確認できます。これには、個々のユーザー入力、軌跡の結果、要求されたすべての指標にわたるすべてのユーザー入力と軌跡のペアの集計結果が含まれます。
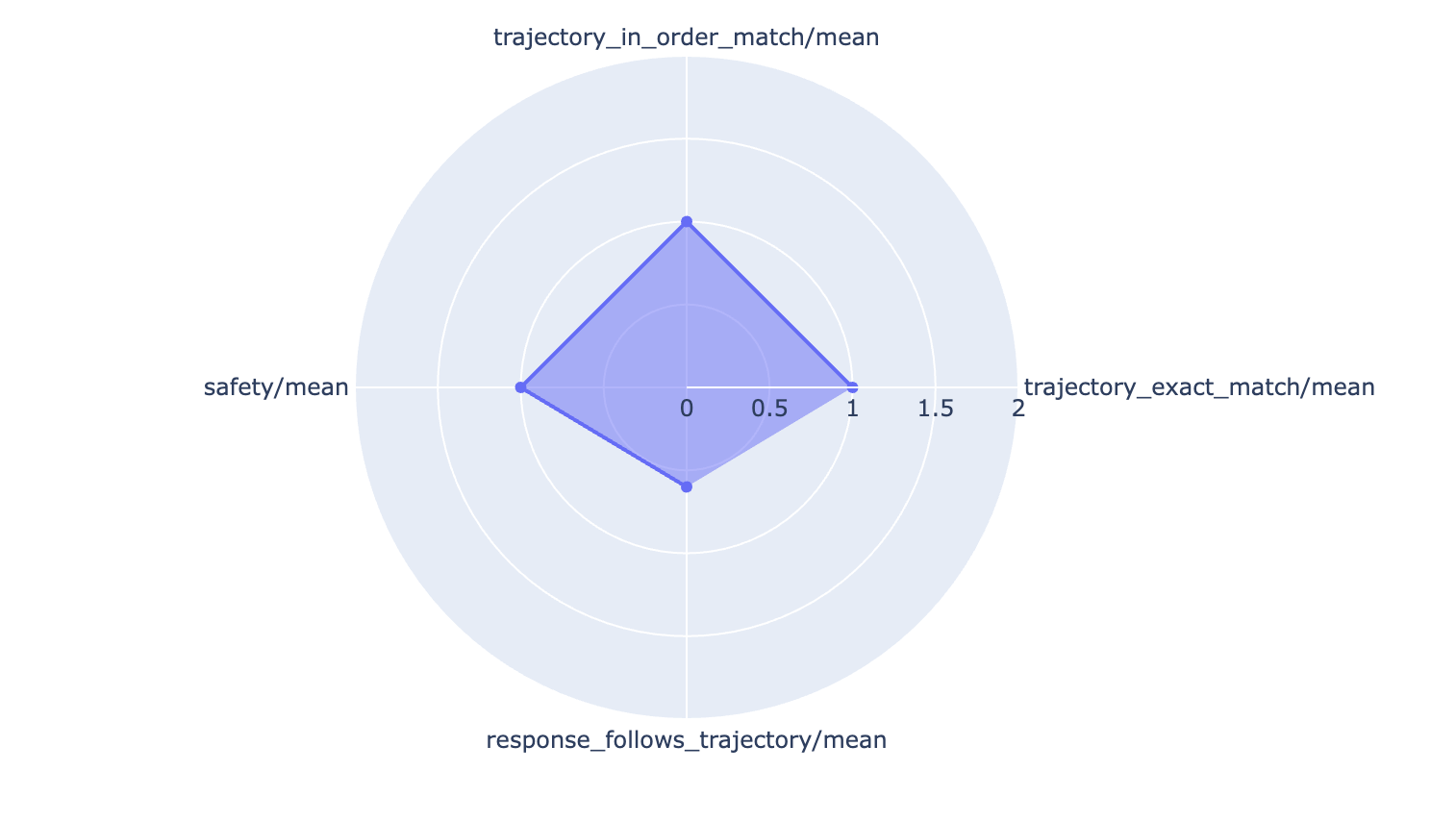
これらのきめ細かな評価結果にアクセスすることで、以下のような棒グラフやレーダー チャートなどで、エージェントのパフォーマンスをわかりやすく可視化できます。
使ってみる
Vertex AI Gen AI Evaluation Service の公開プレビュー版を活用して、エージェント アプリケーションの可能性を最大限に引き出しましょう。



