生成 AI モデルを構築して評価したら、そのモデルを使用して、chatbot などのエージェントを構築できます。Gen AI Evaluation Service を使用すると、ユースケースのタスクや目標を完了するエージェントの能力を測定できます。
概要
エージェントを評価する方法は次のとおりです。
最終回答評価: エージェントの最終的な出力(エージェントが目標を達成したかどうか)を評価します。
軌跡評価: エージェントが最終回答に至るまでにたどったパス(ツール呼び出しの順序)を評価します。
Gen AI Evaluation Service を使用すると、1 つの Vertex AI SDK クエリでエージェントの実行をトリガーし、軌跡評価と最終回答評価の両方の指標を取得できます。
サポートされているエージェント
Gen AI Evaluation Service は、次のカテゴリのエージェントをサポートしています。
| サポートされているエージェント | 説明 |
|---|---|
| Agent Engine のテンプレートを使用して構築されたエージェント | Agent Engine(LangChain on Vertex AI)は、エージェントをデプロイして管理できるプラットフォームです。 Google Cloud |
| Agent Engine のカスタマイズ可能なテンプレートを使用して構築された LangChain エージェント | LangChain はオープンソース プラットフォームです。 |
| カスタム エージェント関数 | カスタム エージェント関数は、エージェントのプロンプトを受け取り、回答と軌跡を辞書で返す柔軟な関数です。 |
エージェント評価の指標を定義する
最終回答評価または軌跡評価の指標を定義します。
最終回答評価
最終回答評価は、モデル レスポンス評価と同じプロセスで行われます。詳細については、評価指標を定義するをご覧ください。
軌跡評価
次の指標は、期待される軌跡に従うモデルの能力を評価する際に役立ちます。
完全一致
予測軌跡が参照軌跡と完全に一致し、まったく同じツール呼び出しがまったく同じ順序で行われている場合、trajectory_exact_match 指標はスコア 1 を返します。それ以外の場合は 0 を返します。
指標の入力パラメータ
| 入力パラメータ | 説明 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用したツール呼び出しのリスト。 |
reference_trajectory |
エージェントがクエリを満たすうえで期待されるツールの使用。 |
出力スコア
| 値 | 説明 |
|---|---|
| 0 | 予測軌跡が参照軌跡と一致しません。 |
| 1 | 予測軌跡が参照軌跡と一致しています。 |
順序一致
余分なツール呼び出しが含まれているかを問わず、予測軌跡に参照軌跡のすべてのツール呼び出しが同じ順序で含まれている場合、trajectory_in_order_match 指標はスコア 1 を返します。それ以外の場合は 0 を返します。
指標の入力パラメータ
| 入力パラメータ | 説明 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用した予測軌跡。 |
reference_trajectory |
エージェントがクエリを満たすうえで期待される予測軌跡。 |
出力スコア
| 値 | 説明 |
|---|---|
| 0 | 予測軌跡のツール呼び出しが、参照軌跡の順序と一致していません。 |
| 1 | 予測軌跡が参照軌跡と一致しています。 |
順序を問わない一致
順序は問わず、余分なツール呼び出しが含まれているかも問わず、予測軌跡に参照軌跡のツール呼び出しがすべて含まれている場合、trajectory_any_order_match 指標はスコア 1 を返します。それ以外の場合は 0 を返します。
指標の入力パラメータ
| 入力パラメータ | 説明 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用したツール呼び出しのリスト。 |
reference_trajectory |
エージェントがクエリを満たすうえで期待されるツールの使用。 |
出力スコア
| 値 | 説明 |
|---|---|
| 0 | 参照軌跡のツール呼び出しのうち、予測軌跡に含まれていないものがあります。 |
| 1 | 予測軌跡が参照軌跡と一致しています。 |
適合率
trajectory_precision 指標は、予測軌跡のツール呼び出しのうち、参照軌跡に従って実際に関連性があるか正しいものの数を測定します。
適合率の計算では、まず、予測軌跡のアクションのうち、参照軌跡にも存在するアクションの数をカウントします。その数を予測軌跡のアクションの合計数で割ります。
指標の入力パラメータ
| 入力パラメータ | 説明 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用したツール呼び出しのリスト。 |
reference_trajectory |
エージェントがクエリを満たすうえで期待されるツールの使用。 |
出力スコア
| 値 | 説明 |
|---|---|
| [0,1] の範囲内の浮動小数点数 | スコアが高いほど、予測軌跡は正確です。 |
再現率
trajectory_recall 指標は、参照軌跡の重要なツール呼び出しのうち、予測軌跡で実際に捕捉された呼び出しの数を測定します。
再現率の計算では、まず、参照軌跡のアクションのうち、予測軌跡にも存在するアクションの数をカウントします。その数を参照軌跡のアクションの合計数で割ります。
指標の入力パラメータ
| 入力パラメータ | 説明 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用したツール呼び出しのリスト。 |
reference_trajectory |
エージェントがクエリを満たすうえで期待されるツールの使用。 |
出力スコア
| 値 | 説明 |
|---|---|
| [0,1] の範囲内の浮動小数点数 | スコアが高いほど、予測軌跡の再現率が高いことになります。 |
単一ツールの使用
trajectory_single_tool_use 指標は、指標仕様で指定された特定のツールが予測軌跡で使用されているかどうかを確認します。ツール呼び出しの順序やツールの使用回数はチェックされず、ツールが存在するかどうかのみがチェックされます。
指標の入力パラメータ
| 入力パラメータ | 説明 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用したツール呼び出しのリスト。 |
出力スコア
| 値 | 説明 |
|---|---|
| 0 | 指定のツールが存在しません。 |
| 1 | 指定のツールが存在します。 |
また、デフォルトでは、次の 2 つのエージェント パフォーマンス指標が評価結果に追加されます。EvalTask でこれらの指標を指定する必要はありません。
latency
エージェントが回答を返すまでに要した時間。
| 値 | 説明 |
|---|---|
| 浮動小数点数 | 秒単位で計算されます。 |
failure
エージェントの呼び出しがエラーになったか成功したかを示すブール値。
出力スコア
| 値 | 説明 |
|---|---|
| 1 | エラー |
| 0 | 有効な回答が返された |
エージェント評価用のデータセットを準備する
最終回答評価または軌跡評価用にデータセットを準備します。
最終回答評価のデータスキーマは、モデル レスポンス評価のスキーマと類似しています。
計算ベースの軌跡評価では、データセットに次の情報が含まれている必要があります。
| 入力タイプ | 入力フィールドの内容 |
|---|---|
predicted_trajectory |
エージェントが最終回答に到達するために使用したツール呼び出しのリスト。 |
reference_trajectory(trajectory_single_tool_use metric には不要) |
エージェントがクエリを満たすうえで期待されるツールの使用。 |
評価データセットの例
次の例は、軌跡評価用のデータセットを示しています。trajectory_single_tool_use を除くすべての指標で reference_trajectory が必要です。
reference_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_2",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_y"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
predicted_trajectory = [
# example 1
[
{
"tool_name": "set_device_info",
"tool_input": {
"device_id": "device_3",
"updates": {
"status": "OFF"
}
}
}
],
# example 2
[
{
"tool_name": "get_user_preferences",
"tool_input": {
"user_id": "user_z"
}
},
{
"tool_name": "set_temperature",
"tool_input": {
"location": "Living Room",
"temperature": 23
}
},
]
]
eval_dataset = pd.DataFrame({
"predicted_trajectory": predicted_trajectory,
"reference_trajectory": reference_trajectory,
})
評価データセットをインポートする
データセットは次の形式でインポートできます。
Cloud Storage に保存されている JSONL または CSV ファイル
BigQuery テーブル
Pandas DataFrame
Gen AI Evaluation Service には、エージェントの評価方法を示す目的で、サンプルの一般公開データセットが用意されています。次のコードは、Cloud Storage バケットからこの一般公開データセットをインポートする方法を示しています。
# dataset name to be imported
dataset = "on-device" # Alternatives: "customer-support", "content-creation"
# copy the tools and dataset file
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/tools.py .
!gcloud storage cp gs://cloud-ai-demo-datasets/agent-eval-datasets/{dataset}/eval_dataset.json .
# load the dataset examples
import json
eval_dataset = json.loads(open('eval_dataset.json').read())
# run the tools file
%run -i tools.py
ここで、dataset は次のいずれかの一般公開データセットです。
"on-device": スマートホーム デバイスを操作する Home のオンデバイス アシスタント向けのデータ。エージェントは、「寝室のエアコンを午後 11 時から午前 8 時までオンにし、それ以外の時間はオフに設定して」などのクエリに対応します。"customer-support": カスタマー サポート エージェント向けのデータ。エージェントは、「保留中の注文をキャンセルして、未解決のサポート チケットをエスカレーションできますか?」などのクエリに対応します。"content-creation": マーケティング コンテンツ作成エージェント向けのデータ。エージェントは、「キャンペーン X をソーシャル メディア サイト Y で 1 回限りのキャンペーンに変更し、予算を 50% 削減して 2024 年 12 月 25 日のみ実施するようにしてください」などのクエリに対応します。
エージェントの評価を実行する
軌跡評価または最終回答評価の評価を実行します。
エージェントの評価では、次のコードのように、回答評価の指標と軌跡評価の指標を組み合わせることができます。
single_tool_use_metric = TrajectorySingleToolUse(tool_name='tool_name')
eval_task = EvalTask(
dataset=EVAL_DATASET,
metrics=[
"rouge_l_sum",
"bleu",
custom_trajectory_eval_metric, # custom computation-based metric
"trajectory_exact_match",
"trajectory_precision",
single_tool_use_metric,
response_follows_trajectory_metric # llm-based metric
],
)
eval_result = eval_task.evaluate(
runnable=RUNNABLE,
)
指標のカスタマイズ
大規模言語モデルベースの指標は、テンプレート インターフェースを使用して、またはゼロから作成して、軌跡評価用にカスタマイズできます。詳細については、モデルベースの指標のセクションをご覧ください。テンプレート化された例を次に示します。
response_follows_trajectory_prompt_template = PointwiseMetricPromptTemplate(
criteria={
"Follows trajectory": (
"Evaluate whether the agent's response logically follows from the "
"sequence of actions it took. Consider these sub-points:\n"
" - Does the response reflect the information gathered during the trajectory?\n"
" - Is the response consistent with the goals and constraints of the task?\n"
" - Are there any unexpected or illogical jumps in reasoning?\n"
"Provide specific examples from the trajectory and response to support your evaluation."
)
},
rating_rubric={
"1": "Follows trajectory",
"0": "Does not follow trajectory",
},
input_variables=["prompt", "predicted_trajectory"],
)
response_follows_trajectory_metric = PointwiseMetric(
metric="response_follows_trajectory",
metric_prompt_template=response_follows_trajectory_prompt_template,
)
次のように、軌跡評価または回答評価に対してカスタムの計算ベースの指標を定義することもできます。
def essential_tools_present(instance, required_tools = ["tool1", "tool2"]):
trajectory = instance["predicted_trajectory"]
tools_present = [tool_used['tool_name'] for tool_used in trajectory]
if len(required_tools) == 0:
return {"essential_tools_present": 1}
score = 0
for tool in required_tools:
if tool in tools_present:
score += 1
return {
"essential_tools_present": score/len(required_tools),
}
custom_trajectory_eval_metric = CustomMetric(name="essential_tools_present", metric_function=essential_tools_present)
結果を表示して解釈する
軌跡評価または最終回答評価の場合、評価結果は次のように表示されます。
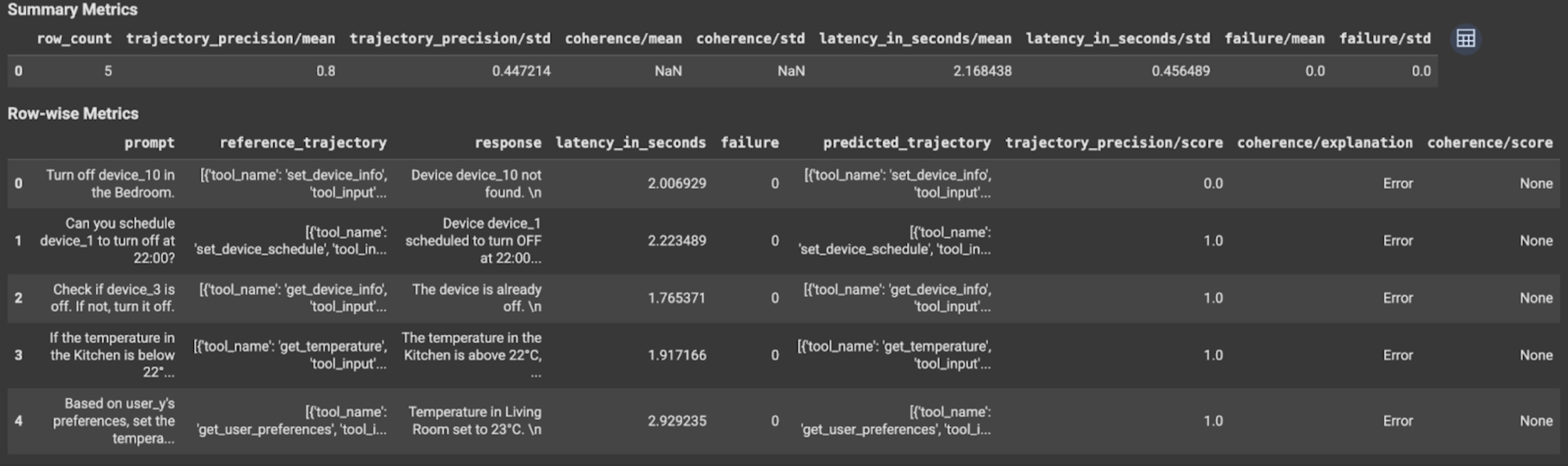
評価結果には次の情報が含まれます。
最終回答の指標
インスタンス レベルの結果
| 列 | 説明 |
|---|---|
| response | エージェントが生成した最終回答。 |
| latency_in_seconds | 回答の生成に要した時間。 |
| failure | 有効な回答が生成されたかどうかを示します。 |
| score | 指標仕様で指定された回答に対して計算されたスコア。 |
| explanation | 指標仕様で指定されたスコアの説明。 |
集計結果
| 列 | 説明 |
|---|---|
| mean | すべてのインスタンスの平均スコア。 |
| standard deviation | すべてのスコアの標準偏差。 |
軌跡の指標
インスタンス レベルの結果
| 列 | 説明 |
|---|---|
| predicted_trajectory | エージェントが最終回答に到達するために行ったツール呼び出しの順序。 |
| reference_trajectory | 期待されるツール呼び出しの順序。 |
| score | 予測軌跡と指標仕様で指定された参照軌跡に対して計算されたスコア。 |
| latency_in_seconds | 回答の生成に要した時間。 |
| failure | 有効な回答が生成されたかどうかを示します。 |
集計結果
| 列 | 説明 |
|---|---|
| mean | すべてのインスタンスの平均スコア。 |
| standard deviation | すべてのスコアの標準偏差。 |
Agent2Agent(A2A)プロトコル
マルチエージェント システムを構築する場合は、A2A プロトコルを確認することを強くおすすめします。A2A プロトコルは、基盤となるフレームワークに関係なく、AI エージェント間のシームレスな通信とコラボレーションを可能にするオープン スタンダードです。2025 年 6 月に Linux Foundation に寄贈されました Google Cloud 。A2A SDK を使用したり、サンプルを試したりするには、GitHub リポジトリをご覧ください。
次のステップ
次のエージェント評価ノートブックを試す。