Case study: in che modo Safari Books Online utilizza BigQuery per la Business Intelligence
Nota del redattore: questo articolo è stato scritto dall'autore ospite Daniel Peter. Daniel è Sr. Programmer Analyst presso Safari Books Online, un servizio di biblioteca online in abbonamento fondato da O'Reilly Media e Pearson Education. Safari Books Online utilizza BigQuery per risolvere alcune sfide fondamentali: creare dashboard aziendali dettagliate per individuare tendenze e gestire gli abusi, migliorare l'efficacia del team di vendita attraverso l'intelligence sulle vendite e consentire query ad hoc per rispondere a domande aziendali specifiche. Ha scelto BigQuery invece di altre tecnologie per la velocità di esecuzione delle query con un linguaggio familiare simile a SQL e per la mancanza di manutenzione.
Safari Libri Online ha una base clienti ampia e diversificata, che cerca e accede costantemente alla nostra raccolta di oltre 30.000 libri e video da una gamma sempre più ampia di computer e dispositivi mobili. Questo flusso di attività contiene informazioni approfondite che possiamo utilizzare per migliorare il nostro servizio e aumentare la redditività. Bloccati tra montagne di dati sull'utilizzo, ci sono tendenze come utenti principali, titoli più popolari e un punto di incontro per le richieste di vendita.
I nostri dati sull'utilizzo erano troppo grandi (nell'intervallo di miliardi di record) per eseguire query online integralmente con il nostro set di strumenti precedente. L'analisi poteva essere eseguita con strumenti di analisi dei dati web di terze parti come Omniture, ma questi strumenti non avevano la possibilità di eseguire query sui dati a livello di record ed esplorarli in tempo reale. Inoltre, non disponevano di un ottimo backend per sviluppare le visualizzazioni. Le query di tipo SQL dovevano essere eseguite su blocchi di dati più piccoli e richiedevano manodopera lenta. Non vedevamo l'ora che le query MySQL venissero completate e spesso dubitavamo della loro conclusione. Una volta raggiunti i timeout del client di database di 10 minuti, non potrai più eseguire analisi ad hoc. Rispondere a domande operative (ad esempio per individuare un abuso) può richiedere molto tempo, quindi la velocità è importante. Abbiamo giocato con Hadoop, ma la sua manutenzione richiedeva molte risorse, così abbiamo finito di metterlo in secondo piano per i progetti futuri.
Poi abbiamo scoperto Google BigQuery grazie a un video di Google I/O e abbiamo stabilito che sembrava perfetto per il nostro caso d'uso, quindi abbiamo deciso di provarlo. Continua a leggere per scoprire come siamo riusciti a ottenere rapidamente informazioni utili da dati altrimenti difficili da usare con BigQuery.
Trasferimento dei dati in BigQuery
Indipendentemente dalla piattaforma di database utilizzata, il passaggio ETL (Extract-Transform-Load) può essere una sfida a seconda delle origini dati. BigQuery non fa eccezione. Per semplificare questa operazione, Google ha un ottimo articolo sul caricamento di dati in BigQuery.
Questo diagramma mostra una panoramica del flusso di dati attraverso i server di destinazione e ETL che portano a BigQuery.
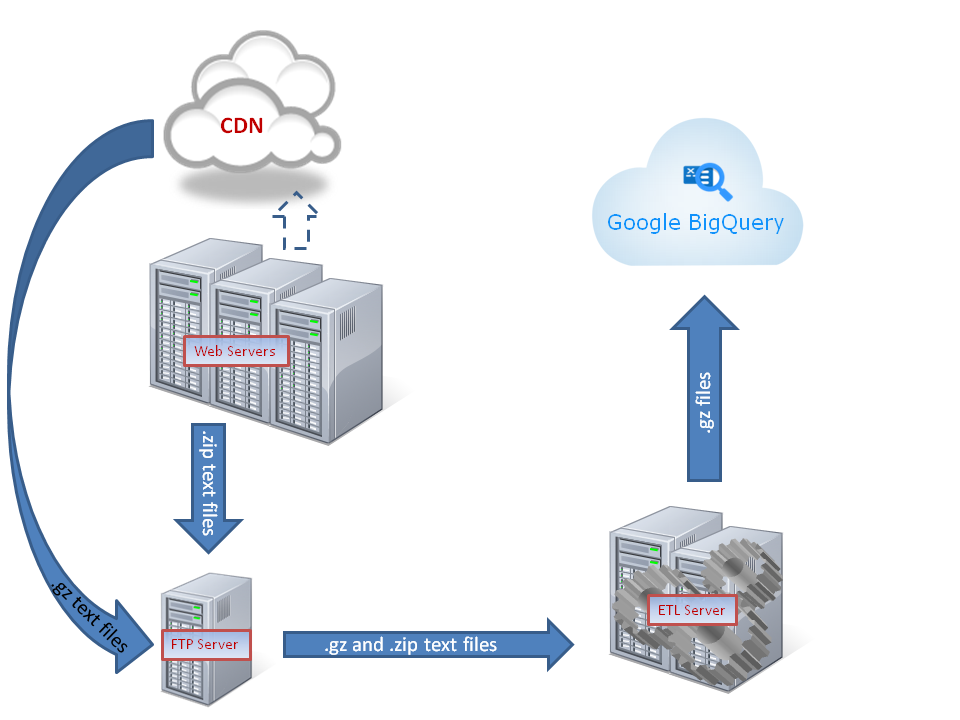
I nostri dati sull'utilizzo provengono dalla nostra rete CDN (Content Delivery Network) e dai log dei nostri server di applicazioni web. Questi dati sono stati pacchettizzati in blocchi in batch basati sul tempo copiati automaticamente in una "directory di destinazione". Era necessaria una trasformazione per essere caricati in BigQuery in un formato che consentisse il massimo dell'utilizzo.
Ecco i passaggi di base che abbiamo svolto:
Ottieni un elenco di tutti i file sorgente caricati in precedenza in BigQuery
È sufficiente chiamare lo strumento a riga di comando bq con il parametro format=json di uno script PHP:
bq --format=json query SELECT sourcefile FROM PageViews GROUP BY sourcefile
Abbiamo così ottenuto questo output JSON:
[{"sourcefile":"PageViews.201207122232.gz"},
{"sourcefile":"PageViews.201207111006.gz"},
{"sourcefile":"PageViews.201207121024.gz"}]
che possono essere facilmente spostati in un array utilizzando la funzione json_decode di PHP.
Convalida il nostro elenco di file di origine in attesa di essere caricati in BigQuery
Abbiamo ottenuto un elenco di tutti i file nella nostra directory di destinazione e abbiamo ricevuto il checksum con il comando linux md5sum. Abbiamo aspettato un po' di tempo, poi abbiamo recuperato l'elenco dei file con le somme md5. Tutti i file la cui somma md5 era stata modificata erano in fase di caricamento, pertanto li abbiamo rimossi dall'elenco per dare loro più tempo per il caricamento.
Abbiamo rimosso dall'elenco anche tutti i file che erano già stati caricati in BigQuery.
Abbiamo quindi controllato l'integrità dei nostri file con il comando gunzip -t di linux.
Trasforma i file
Trattiamo circa 40 file di testo compressi che hanno una dimensione di circa 60 MB ciascuno ogni 24 ore. L'esecuzione dell'ETL su questo volume di dati richiede un server di qualità. Abbiamo utilizzato una macchina Linux con 256 GB di RAM e 32 core, ma potresti cavartela con meno. Più è grande il server, meglio è, soprattutto durante il processo di sviluppo quando si esegue l'iterazione più e più volte. Per la produzione, e l'elaborazione solo dei dati incrementali, potresti fare lo scale down delle risorse. La cosa principale è che l'elaborazione del tempo di elaborazione di 1 ora di dati sull'utilizzo richiede meno di un'ora, altrimenti i dati in BigQuery non saranno mai aggiornati.
Il processo inizia con la decompressione dei file e l'analisi del testo riga per riga.
Una riga di esempio potrebbe avere il seguente aspetto:
50.0.113.6 - - [21/May/2012:06:12:51 +0000] "GET /techbus.safaribooksonline.com/9780596805395/how_python_runs_programs?reader=html HTTP/1.1" 504 417 "-" "Apple-PubSub/65.28" "-"
Volevamo escludere campi vuoti o non pertinenti, riformattare altri campi e suddividere i campi a più valori in modo da ottenere una tabella come questa:
| host | datetime | httpMethod | dominio | percorso | risorsa | stringa di query | stato | byte | useragent | file di origine |
|---|---|---|---|---|---|---|---|---|---|---|
| 50.0.113.6 | 21/05/2012 06:12:51 | GET | techbus.safaribooksonline.com | /9780596805395/ | how_python_runs_programs | reader=html | 504 | 417 | Apple-PubSub/65.28 | PageViews.201207122232.gz |
| STRINGA | STRINGA | STRINGA | STRINGA | STRINGA | STRINGA | STRINGA | INTERO | INTERO | STRINGA | STRINGA |
Questa funzione PHP ha funzionato bene per analizzare la voce del log web in un array:
str_getcsv($line, " ", '"', '\\');
Abbiamo eseguito un'elaborazione speciale su diversi campi:
- Abbiamo scelto di memorizzare la data/ora come stringa anziché come numero intero di timestamp (nota dell'editore: da quando BigQuery supporta il tipo TIMESTAMP). Abbiamo utilizzato PHP per recuperare le parti della data e le abbiamo riformattate nel seguente formato:
Y/m/d H:i:s, che può essere ordinato come testo. - Ha suddiviso la richiesta HTTP in dominio, percorso, risorsa e stringa di query utilizzando il comando
explodedi PHP e qualche altra logica. - Abbiamo aggiunto il nome del file di origine per poter rintracciare un record al suo file sorgente originale e impedirci di inserire qualsiasi file di origine più di una volta.
Abbiamo scritto ogni riga trasformata in un nuovo file, eseguendo l'escape dei caratteri speciali e delimitando i campi con una barra verticale |.
Quindi abbiamo compresso il file trasformato con il comando gzip -f -v di linux.
Copia i file in Google Cloud Storage
Copiare i file in Google Cloud Storage è un gioco da ragazzi grazie all'utilità della riga di comando gsutil. È letteralmente facile come copiare i file sulla tua macchina locale. Una volta installati, non dovevamo fare altro che iterare i nostri file trasformati e gsutil cp fino a Google:
foreach ($arrFiles as $file) {
echo 'Sending file to Google Cloud Storage: '.$file;
echo shell_exec('gsutil cp '.$file.' gs://data_warehouse/');
echo ' (COMPLETE).';
echo "\n";
}
Carica i file in BigQuery
Abbiamo creato questo file di schema:
[
{"type":"STRING","name":"host","mode":"NULLABLE"},
{"type":"STRING","name":"datetime","mode":"NULLABLE"},
{"type":"STRING","name":"httpMethod","mode":"NULLABLE"},
{"type":"STRING","name":"domain","mode":"NULLABLE"},
{"type":"STRING","name":"path","mode":"NULLABLE"},
{"type":"STRING","name":"resource","mode":"NULLABLE"},
{"type":"STRING","name":"querystring","mode":"NULLABLE"},
{"type":"INTEGER","name":"status","mode":"NULLABLE"},
{"type":"INTEGER","name":"bytes","mode":"NULLABLE"},
{"type":"STRING","name":"useragent","mode":"NULLABLE"},
{"type":"STRING","name":"sourcefile","mode":"NULLABLE"}
]
e l'ho salvato come schema.txt
È molto facile caricare i nostri file da Google Cloud Storage in BigQuery. Con lo strumento a riga di comando bq installato, abbiamo eseguito questo comando:
bq load --field_delimiter='|' --max_bad_records=99999999 dataset.tableName gs://data_warehouse/file1.gz, gs://data_warehouse/file2.gz, gs://file3.gz schema.txt
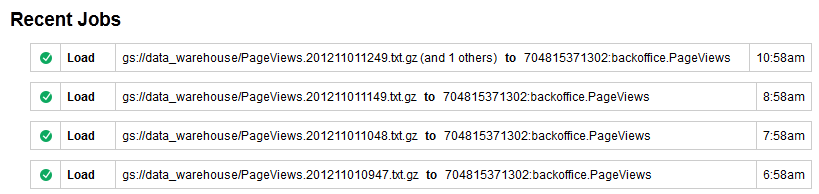
Un grande gruppo di file compressi con gzip viene importato in modo sorprendentemente rapido. Le operazioni di gzip e batch sono la soluzione migliore per noi, anche se Google consiglia file sorgente non compressi per ottenere le massime velocità di importazione possibili grazie alle operazioni di caricamento parallelizzate. In ogni caso, possiamo monitorare lo stato di questi job di caricamento tramite la "Cronologia dei job" dello strumento di navigazione BigQuery:
Utilizzare i dati in BigQuery
BigQuery si è dimostrata un'ottima piattaforma per i dati delle dashboard e offre la possibilità di visualizzare in dettaglio i dati delle dashboard grazie all'interfaccia utente basata su browser di BigQuery per le analisi ad hoc.
Ecco una dashboard utilizzata internamente dal nostro team operativo per monitorare gli utenti principali:

Se ci sono domande, puoi ottenere ulteriori informazioni su un utente, un titolo, un indirizzo IP eseguendo una query con lo strumento di navigazione di BigQuery.
Ecco una dashboard che utilizziamo internamente per tenere d'occhio i titoli più popolari di tendenza:

Anche in questo caso, BigQuery può rispondere a eventuali domande in questa dashboard.
I dati vengono inviati a queste dashboard da un job pianificato intermedio che viene eseguito tramite cron. Questo script esegue una query su BigQuery con lo strumento a riga di comando bq, ottiene il risultato in json, poi contatta alcuni altri servizi web per ottenere ulteriori informazioni che non sono archiviate in BigQuery, ad esempio i dati utente e le immagini in miniatura dei libri. Poi il tutto viene combinato e presentato nella dashboard. Questo è un buon modello, poiché non vorresti eseguire query su BigQuery ogni volta che la dashboard è stata caricata, poiché potrebbe diventare costosa. È meglio eseguire le attività più complesse analitiche con BigQuery, quindi archiviare i risultati in modo da avere uno stack LAMP economico per un consumo di massa. (Nota dell'editor: BigQuery ora dispone di memorizzazione delle query nella cache, che gestisce parte di questo processo automaticamente)
Intelligence di vendita
Un altro caso d'uso per cui BigQuery si è rivelato ideale è stato quello di analizzare i log web per trovare i lead che arrivavano nel nostro reparto vendite. Questo ci ha consentito di collegare un lead ad altri account del nostro sistema o di valutare il livello di interesse che qualcuno potrebbe avere nei nostri confronti in base al numero di libri in anteprima che avevano letto nell'ultimo mese sul nostro sito. Il lead viene creato nel nostro sistema CRM, quindi BigQuery cerca in modo asincrono nei nostri log nel seguente modo:
$query->setQuery("SELECT userid, COUNT(userid) AS countUserid FROM [backoffice.PageViews] WHERE remoteip='".$ip."' GROUP BY userid ORDER BY countUserid DESC LIMIT 20");
Il risultato viene restituito rapidamente e riportato al record dei lead, consentendo al nostro reparto vendite di acquisire informazioni e contattare il lead senza dover aspettare le informazioni.
Questo ci fornisce un riepilogo degli utenti (o richieste anonime) associate all'indirizzo IP del lead. Anche se gli indirizzi IP non sono identificatori perfetti, sono molto meglio di niente.
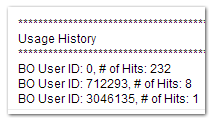
Puoi vedere che qualcuno dall'indirizzo IP di questo Lead ha visualizzato in modo anonimo (ID utente 0) 232 pagine dei nostri libri e alcuni altri utenti che hanno un account presso di noi sono già attivi su tale IP.
Anziché utilizzare l'interfaccia a riga di comando di BigQuery, questo caso d'uso era più adatto per OAuth da server a server con la libreria client delle API di Google per PHP. Questo ci ha permesso di creare un servizio web che combina dati provenienti da diverse fonti e restituisce i risultati al nostro CRM. Una di queste origini è BigQuery. Un'incredibile testimonianza della velocità di BigQuery è che non ho nemmeno dovuto implementare il servizio web in modo asincrono. Restituisce i risultati da BigQuery entro il periodo di timeout del servizio web richiesto dal CRM.
Ad hoc
Altri casi d'uso includono query ad hoc che non si basano sulle dashboard, ma su domande specifiche sull'attività.
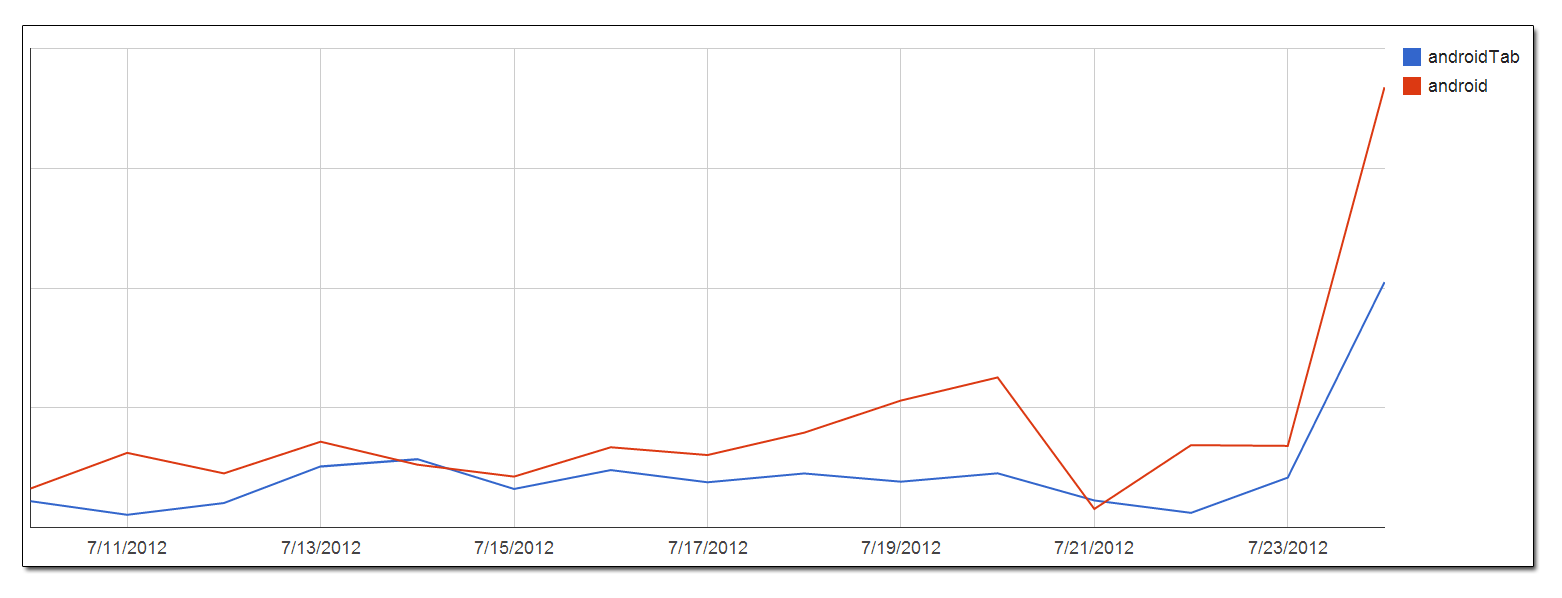
Quando abbiamo rilasciato le nostre app per Android, è stato facile eseguire una query sui nostri dati sull'utilizzo per vedere l'utilizzo di Android raggruppato per giorno. Nello strumento di navigazione di Google BigQuery, è stato facile esportare i risultati delle query come file CSV e caricarli in Fogli di lavoro Google per creare un grafico:
Ecco un esempio di come vengono esaminati i nostri utenti principali in base al numero di ricerche eseguite in una determinata ora del giorno:
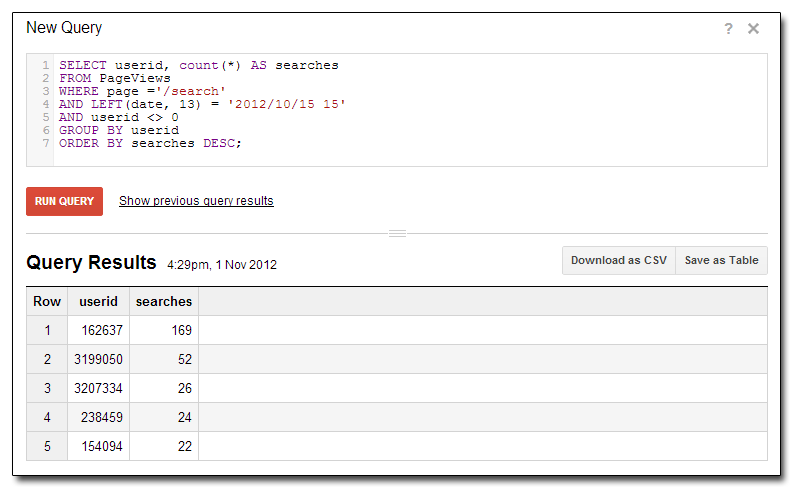
Non c'è davvero limite alle informazioni che puoi ottenere analizzando i tuoi dati. Da un punto di vista ad hoc, è possibile rispondere a qualsiasi domanda sui miliardi di righe di dati in pochi secondi grazie a una grande capacità di risposta. Ad esempio, puoi scoprire se quel traffico insolito sul tuo sito è un bot di spam del forum o un utente malintenzionato.
Come consigliato da Google, abbiamo suddiviso i nostri dati in anni:
Normalmente questo sarebbe un po' scomodo eseguire un'istruzione di unione tra le tabelle, ma BigQuery offre una buona scorciatoia per farlo:
SELECT page
FROM PageViews2006, PageViews2007, PageViews2008
WHERE page CONTAINS('google')
GROUP BY page
Affrontiamo gli anni fa di cui abbiamo bisogno per accedere alle nostre tabelle suddivise in base al tempo e le uniranno poiché abbiamo reso i nostri schemi uguali. Alla fine di ogni anno archiviamo la tabella "Attivi" e ne iniziamo una nuova. Questo è il migliore dei due mondi in quanto offre l'accessibilità di avere tutti i dati in un'unica tabella di grandi dimensioni, con la possibilità di separarli. Man mano che cresciamo, avrà senso suddividere ulteriormente i dati in incrementi mensili anziché annuali.
Riepilogo
Generare conoscenze significative a partire da enormi quantità di dati in modo tempestivo è una sfida da risolvere per Safari Books Online, come molte altre. Riuscire a seguire le tendenze in tempo reale, pur rimanendo al passo con i cambiamenti, invece di un mese dopo la notizia è molto importante. Questo porta a ridurre i problemi di abuso e a incrementare le entrate principali raccogliendo marketing intelligence sugli argomenti di tendenza e raccogliendo informazioni sui lead per chiudere le vendite in modo più efficace.
Futuro
Crediamo che stiamo solo dando un'occhiata a ciò che è possibile fare con BigQuery. Disporre i dati in una piattaforma interrogabile ad alte prestazioni è una risorsa enorme sia per i nostri progetti che abbiamo in programma sia per qualsiasi domanda ad hoc non pianificata.