Guia de soluções: backup do Google Cloud e DR para Oracle na solução Bare Metal
Informações gerais
Para fornecer resiliência aos databases Oracle em um ambiente da Solução Bare Metal, você precisa ter uma estratégia clara de backups de database e recuperação de desastres. Para ajudar você com esse requisito, a equipe de arquitetos de soluções doGoogle Cloud realizou testes abrangentes do serviço de backup e DR do Google Cloud e compilou as descobertas neste guia. Como resultado, mostraremos as melhores maneiras de implantar, configurar e otimizar suas opções de backup e recuperação para databases Oracle em um ambiente da Solução Bare Metal usando o serviço Backup e DR. Também vamos compartilhar alguns números de desempenho dos nossos resultados de testes para que você tenha uma referência de comparação com seu próprio ambiente. Este guia é útil para administradores de backup, doGoogle Cloud ou de Oracle DBA.
Contexto
Em junho de 2022, a equipe de arquitetos de soluções iniciou uma demonstração de prova de conceito (PoC) de Google Cloud Backup e DR para um cliente empresarial. Para atender aos critérios de sucesso, precisávamos dar suporte à recuperação do database da Oracle de 50 TB e restaurar o database em até 24 horas.
Essa meta apresentou vários desafios, mas a maioria das pessoas envolvidas na PoC acreditava que poderíamos alcançar esse resultado e que deveríamos prosseguir com a PoC. Sentimos que havia um risco relativamente baixo porque os dados de testes anteriores da equipe de engenharia de backup e DR mostravam que era possível alcançar esses resultados. Também compartilhamos os resultados do teste com o cliente para que ele se sinta confortável em prosseguir com a PoC.
Durante a PoC, aprendemos a configurar vários elementos juntos com êxito (Oracle, Google Cloud Backup e DR, armazenamento e links de extensão regionais) em um ambiente da Solução Bare Metal. Ao seguir as práticas recomendadas que aprendemos, é possível gerar bons resultados.
"Sua milhagem pode variar" é uma boa maneira de pensar nos resultados gerais deste documento. Nossa meta é compartilhar um pouco de conhecimento sobre o que aprendemos, o que você deve observar, o que precisa evitar e áreas de investigação se não está conseguindo o desempenho ou os resultados desejados. Esperamos que este guia ajude você a gerar confiança com as soluções propostas e que seus requisitos possam ser atendidos.
Arquitetura
A Figura 1 mostra uma visão simplificada da infraestrutura que você precisa criar ao implantar o Backup e DR para proteger os databases Oracle em execução em um ambiente da Solução Bare Metal.
Figura 1: componentes para usar o Backup e DR com databases Oracle em um ambiente de Solução Bare Metal

Como você pode ver no diagrama, esta solução requer os seguintes componentes:
- Extensão regional da Solução Bare Metal: permite executar bancos de dados Oracle em um data center de terceiros ao lado de um data center do Google Cloud e usar as licenças de software atuais no local.
- Projeto de serviço de backup e DR: permite hospedar o dispositivo de backup/recuperação e fazer backup da Solução Bare Metal e das cargas de trabalho do Google Cloud nos buckets do Cloud Storage.
- Projeto de serviço do Compute: fornece um local para executar as VMs do Compute Engine.
- Serviço de backup e DR: oferece o console de gerenciamento de backup e DR que permite manter os backups e a recuperação de desastres.
- Projeto host: permite criar sub-redes regionais em uma VPC compartilhada que pode conectar a extensão regional da Solução Bare Metal ao serviço de backup e DR, ao dispositivo de backup/recuperação, aos buckets do Cloud Storage e às VMs do Compute Engine.
Instalar o Google Cloud Backup e DR
A solução de backup e DR exige, no mínimo, os dois componentes principais a seguir para que a solução funcione:
- Console de gerenciamento de DR e backup: um endpoint UI e API HTML 5 que permite criar e gerenciar backups no console doGoogle Cloud .
- Dispositivo de backup/recuperação: este dispositivo funciona como o trabalhador da tarefa para executar backups e ativa e restaura tarefas de tipo.
OGoogle Cloud gerencia o console de gerenciamento de backup e DR. Você precisa implantar o console de gerenciamento em um projeto de produtor de serviço (lado do gerenciamento doGoogle Cloud ) e implantar o dispositivo de backup/recuperação em um projeto de consumidor de serviço (lado do cliente). Para mais informações sobre o Backup e DR, consulte Configurar e planejar uma implantação de backup e DR. Para ver a definição de um produtor e um consumidor de serviço, consulte o glossário do Google Cloud.
Antes de começar
Para instalar o serviço de backup e recuperação de desastres do Google Cloud , conclua as etapas de configuração a seguir antes de iniciar a implantação:
- Ative uma conexão de acesso a serviços privados. Estabeleça essa conexão antes de iniciar a
instalação. Mesmo que você já tenha uma sub-rede de acesso a serviços privados
configurada, ela precisa ter, no mínimo, uma sub-rede
/23. Por exemplo, se você já configurou uma sub-rede/24para a conexão de acesso a serviços privados, recomendamos adicionar uma sub-rede/23. Melhor ainda, você pode adicionar uma sub-rede/20para garantir que possa adicionar mais serviços posteriormente. - Configure o Cloud DNS para que ele possa ser acessado na rede VPC em que você implanta o dispositivo de backup/recuperação. Isso garante a resolução adequada de googleapis.com (via pesquisa privada ou pública).
- Configure rotas de rede e regras de firewall padrão para permitir o tráfego de saída
para
*.googleapis.com(via IPs públicos) ouprivate.googleapis.com(199.36.153.8/30) na porta TCP 443 ou uma saída explícita para0.0.0.0/0. Novamente, é necessário configurar as rotas e o firewall na rede VPC em que você instalará o dispositivo de backup/recuperação. Também recomendamos usar o Acesso privado do Google como uma opção preferencial. Consulte Configurar o Acesso privado do Google para mais informações. - Ativar as APIs a seguir no projeto do consumo:
- API Compute Engine
- API Cloud Key Management Service (KMS)
- API Cloud Resource Manager (para projetos de host e de serviço, se estiverem em uso)
- API Identity and Access Management
- API Workflows
- API Cloud Logging
- Se você tiver ativado alguma políticas da organização, configure o seguinte:
constraints/cloudkms.allowedProtectionLevelsincluemSOFTWAREouALL.
- Configure as seguintes regras de firewall:
- Entrada do appliance de backup/recuperação na VPC do Compute Engine para o host (agente) do Linux na porta TCP-5106.
- Se você usar um disco de backup baseado em bloco com iSCSI, saia do host Linux (agente) na Solução Bare Metal para o dispositivo de backup/recuperação na VPC do Compute Engine na porta TCP-3260.
- Se você usa um disco de backup baseado em NFS ou dNFS, saia do host Linux (agente)
na Solução Bare Metal para o dispositivo de backup/recuperação na
VPC do Compute Engine nas seguintes portas:
- TCP/UDP-111 (rpcbind)
- TCP/UDP-756 (status)
- TCP/UDP-2049 (nfs)
- TCP/UDP-4001 (mountd)
- TCP/UDP-4045 (nlockmgr)
- Configure o Google Cloud DNS para resolver nomes de host e domínios da Solução Bare Metal. Assim, você garante que a resolução de nomes seja consistente nos servidores da Solução Bare Metal, VMs e recursos baseados no Compute Engine, como o serviço de backup e DR.
Instalar o console de gerenciamento de backup e DR
- Ative a API Backup and DR Service, se ela ainda não estiver ativada.
No console Google Cloud , use o menu de navegação para acessar a seção Operações e selecione Backup e DR:
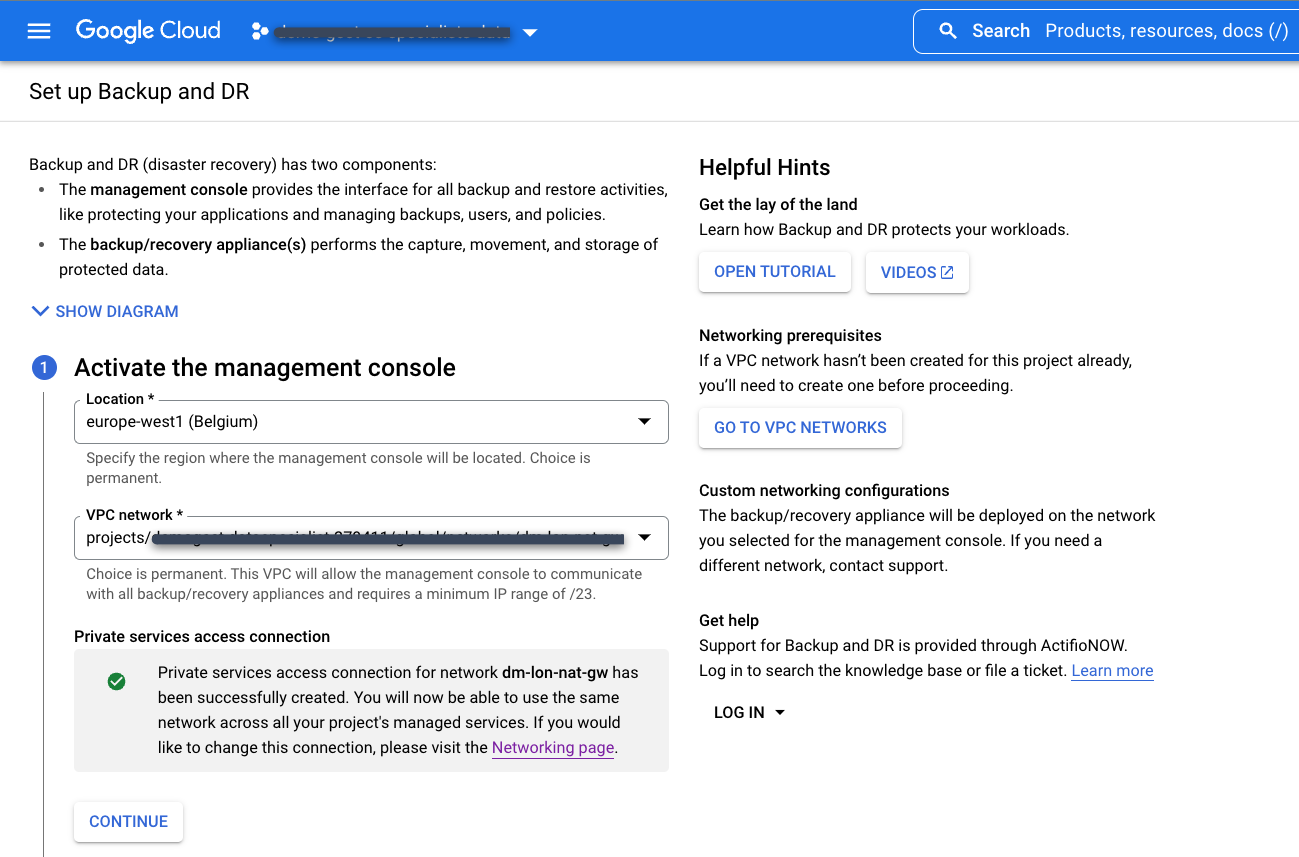
Selecione a conexão de acesso a serviços particulares que você criou anteriormente.
Escolha o local do console de gerenciamento de backup e DR. Essa é a região em que você implanta a interface do usuário do console de gerenciamento de backup e DR em um projeto de produtor de serviço. Google Cloud é proprietário e mantém os recursos do console de gerenciamento.
Escolha a rede VPC no projeto de consumidor do serviço que você quer conectar ao serviço de backup e DR. Esse é normalmente um projeto host ou de VPC compartilhada.
Depois de esperar até uma hora, você vai ver a tela a seguir quando a implantação for concluída.
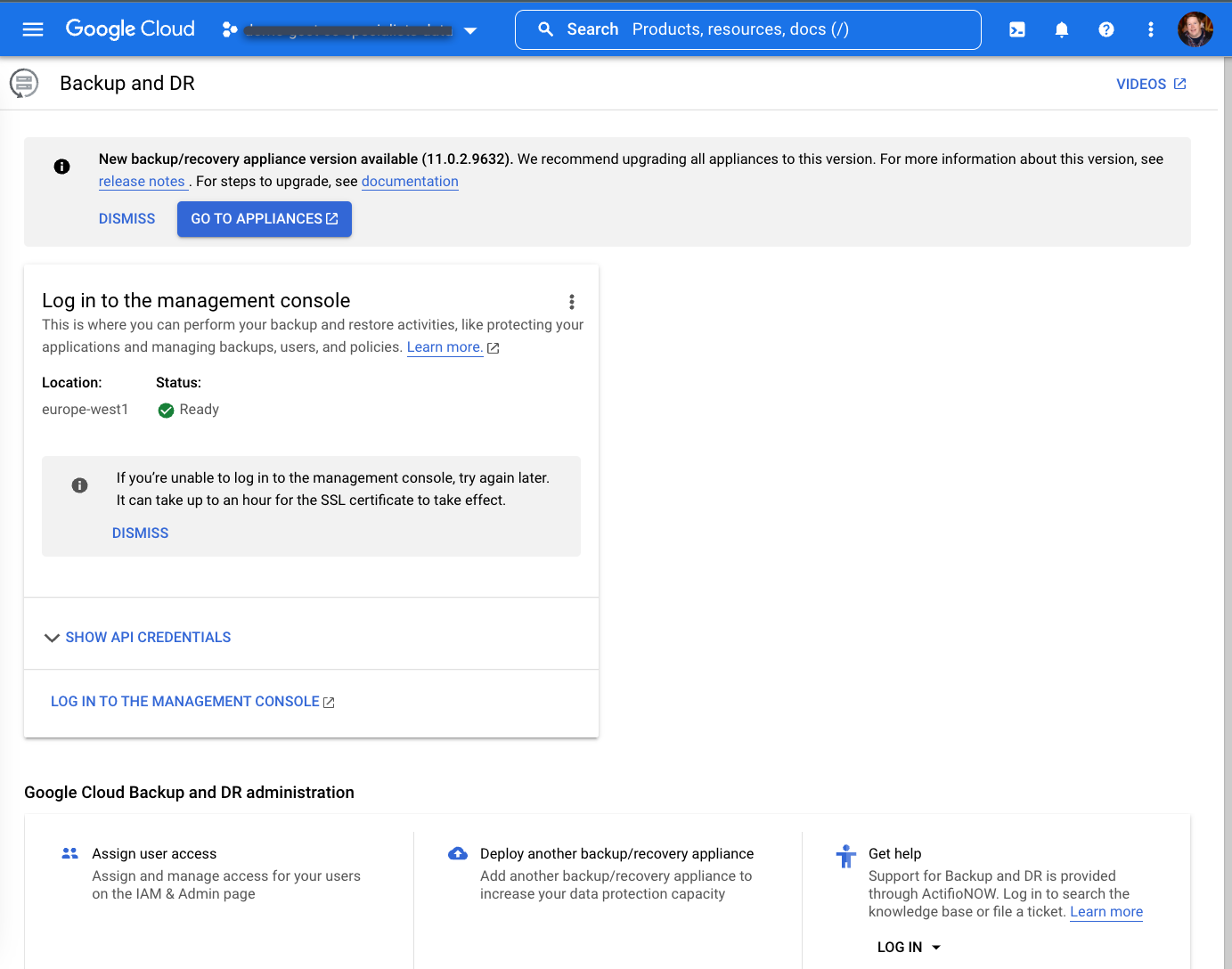
Instalar o appliance de backup/recuperação
Na página Backup e DR, clique em Fazer login no Console de gerenciamento:
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Na página principal do console de gerenciamento de backup e DR, acesse a página Appliances:
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Digite o nome do appliance de backup/recuperação. O Google Cloud adiciona automaticamente outros números aleatórios no final do nome quando a implantação é iniciada.
Escolha o projeto do consumidor em que você quer instalar o dispositivo de backup/recuperação.
Escolha sua região, zona e sub-rede preferidas.
Selecione um tipo de armazenamento. Recomendamos escolher Disco permanente padrão para PoCs e Disco permanente SSD para um ambiente de produção.
Clique no botão Iniciar instalação. O processo leva cerca de uma hora para implantar o console de gerenciamento de backup e DR e o primeiro dispositivo de backup/recuperação.
É possível adicionar outros dispositivos de backup/recuperação em outras regiões ou zonas após a conclusão do processo de instalação inicial.
Configurar o Google Cloud Backup e DR
Nesta seção, você vai aprender as etapas necessárias para configurar o serviço de backup e DR e proteger suas cargas de trabalho.
Configurar uma conta de serviço
A partir da versão 11.0.2 (lançamento de dezembro de 2022 do Backup e DR), é possível usar uma única conta de serviço para executar o dispositivo de backup/recuperação para acessar buckets do Cloud Storage e proteger as máquinas virtuais (VMs) do Compute Engine (não abordadas neste documento).
Papéis da conta de serviço
Google Cloud O Backup e DR usa o Google Cloud Identity and Access Management (IAM) para autorização e autenticação de contas de usuário e de serviço. É possível usar papéis predefinidos para ativar uma variedade de recursos de backup. As duas mais importantes são as seguintes:
- Operador de backup e DR do Cloud Storage: atribua esse papel às conta de serviço usadas por um dispositivo de backup/recuperação que se conecta aos bucket do Cloud Storage. A função permite a criação de buckets do Cloud Storage para backups de snapshots do Compute Engine e o acesso a buckets com dados de backup atuais baseados em agente para restaurar cargas de trabalho.
- Operador de backup e DR do Compute Engine: atribua esse papel às conta de serviço usadas por um dispositivo de backup/recuperação para criar snapshots do Persistent Disk para máquinas virtuais do Compute Engine. Além de criar snapshots, esse papel permite que a conta de serviço restaure VMs no mesmo projeto de origem ou em projetos alternativos.
É possível encontrar sua conta de serviço visualizando a VM do Compute Engine que executa o dispositivo de backup/recuperação no projeto de consumidor/serviço e observando o valor da conta de serviço listado na seção de API e gerenciamento de identidade.
Para fornecer as permissões apropriadas aos seus dispositivos de backup/recuperação, acesse a página Identity and Access Management e conceda os seguintes papéis do IAM à conta de serviço do dispositivo de backup/recuperação.
- Operador de Backup e DR do Cloud Storage
- Operador de DR e backup do Compute Engine (opcional)
Configurar pools de armazenamento
Os pools armazenam dados em locais físicos. Use o Persistent Disk para os dados mais recentes (1 a 14 dias) e o Cloud Storage para retenção em longo prazo (dias, semanas, meses e anos).
Cloud Storage
Crie um bucket padrão regional ou multirregional no local em que você precisa armazenar os dados de backup.
Siga estas instruções para criar um bucket do Cloud Storage:
- Na página de buckets do Cloud Storage, nomeie o bucket.
- Selecione seu local de armazenamento.
- Escolha uma classe de armazenamento: padrão, nearline ou coldline.
- Se você escolher o armazenamento nearline ou coldline, defina o modo Controle de acesso como Refinado. Para o armazenamento padrão, aceite o modo de controle de acesso padrão de Uniforme.
Por fim, não configure outras opções de proteção de dados e clique em Criar.
Em seguida, adicione esse bucket ao appliance de backup/recuperação. Acesse o console de gerenciamento de backup e DR.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/
Selecione o item de menu Gerenciar > Pools de armazenamento.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#pools
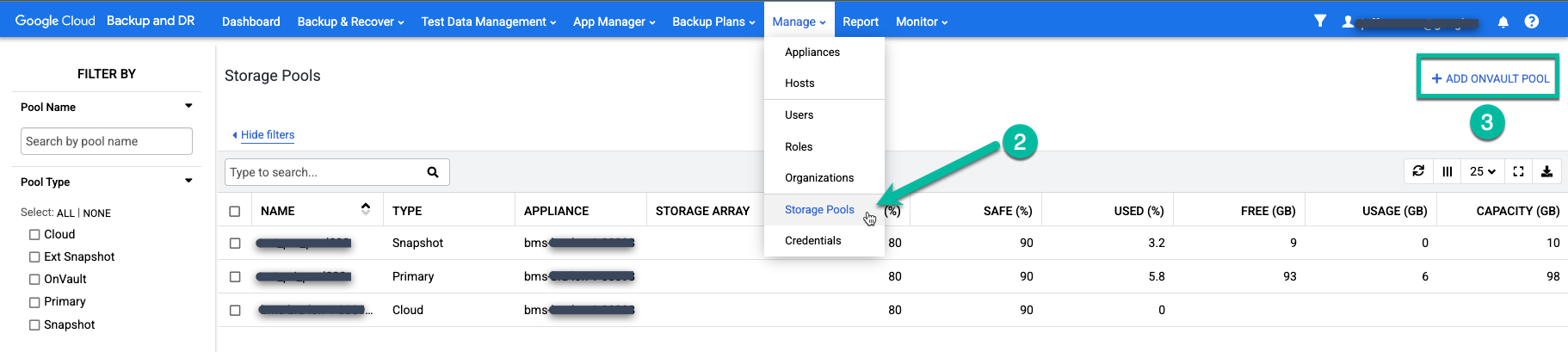
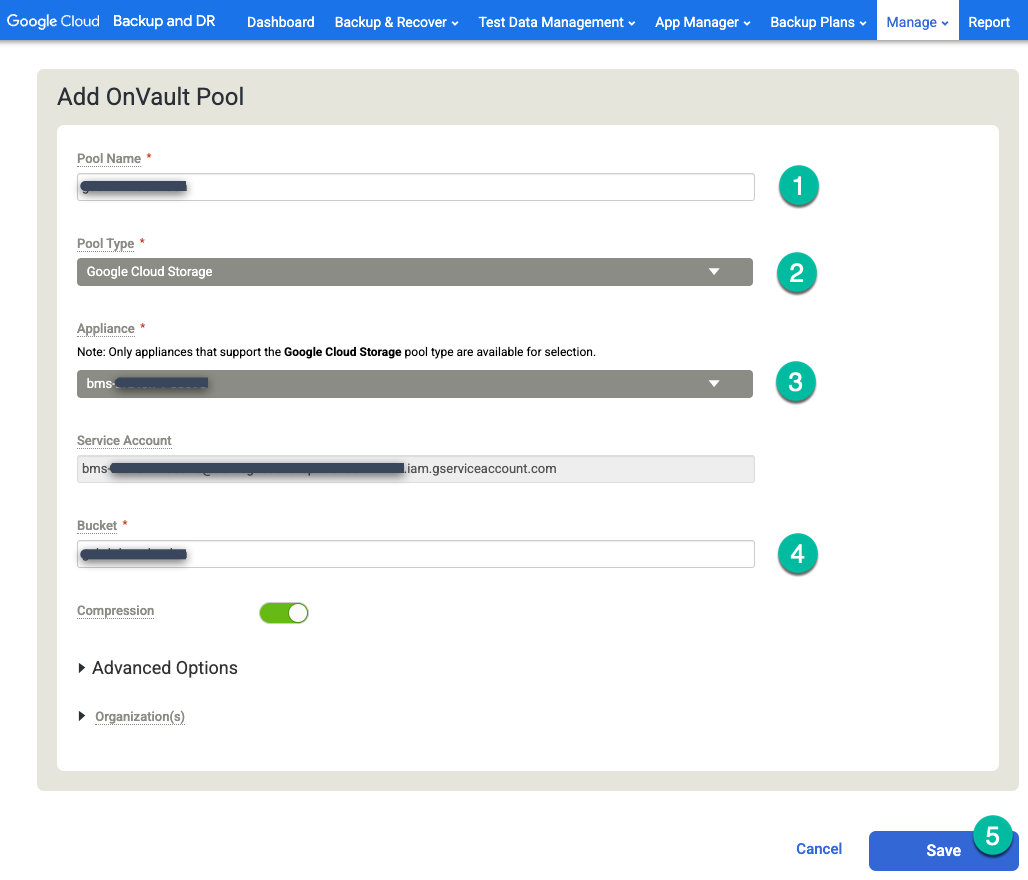
Clique na opção do lado direito + Adicionar OnVault Pool.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#addonvaultpool
- Digite um nome para o Nome do pool.
- Escolha Cloud Storage para o Tipo de pool.
- Selecione o dispositivo que você quer anexar ao bucket do Cloud Storage.
- Digite o nome do bucket do Cloud Storage.
Clique em Save.
Pools de snapshots de disco permanente
Se você implantou o appliance de backup/recuperação com opções padrão ou SSD, o pool de snapshots de Persistent Disk será de 4 TB por padrão. Se os bancos de dados ou sistemas de arquivos de origem exigirem um pool maior, edite as configurações do dispositivo de backup/recuperação implantado, adicione um novo Persistent Disk e crie um pool personalizado ou configure outro pool padrão.
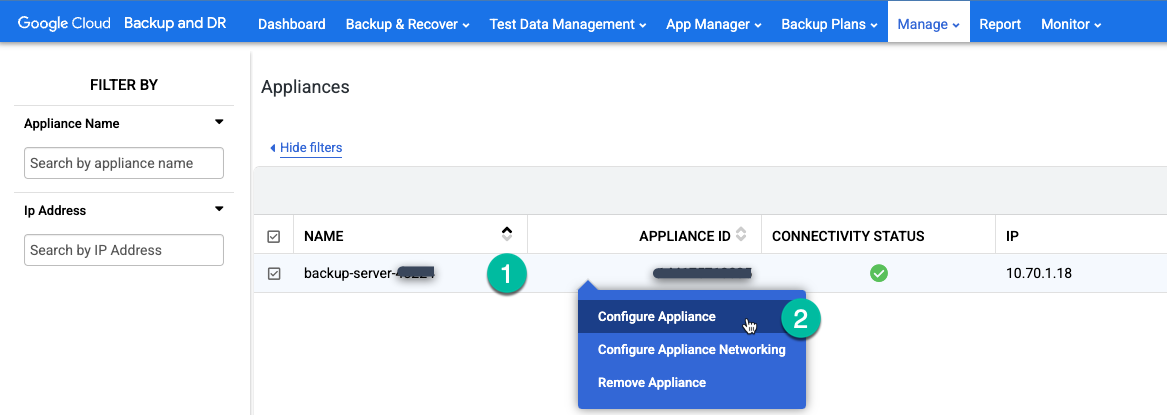
Acesse a página Gerenciar > Eletrodomésticos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
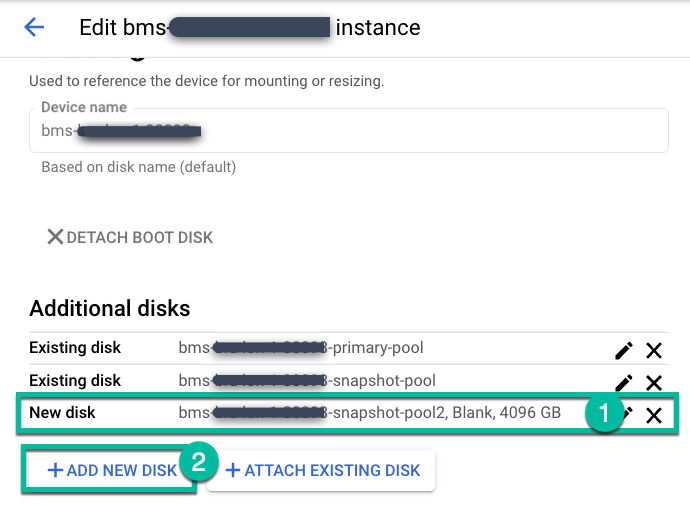
Edite a instância do servidor de backup e clique em +Adicionar novo disco.
- Dê um nome ao disco.
- Selecione um tipo de disco Em branco.
- Escolha "Padrão", "Equilibrada" ou "SSD", dependendo das suas necessidades.
- Digite o tamanho do disco necessário.
Clique em Save.
Acesse a página Gerenciar > Eletrodomésticos no console de gerenciamento de backup e DR.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Clique com o botão direito do mouse no nome do appliance e selecione Configurar appliance no menu.
É possível adicionar o disco ao pool de snapshots atual (expansão) ou criar um novo pool. No entanto, não misture tipos de Persistent Disk no mesmo pool. Se estiver se expandindo, clique no ícone superior direito para o pool que você quer expandir.
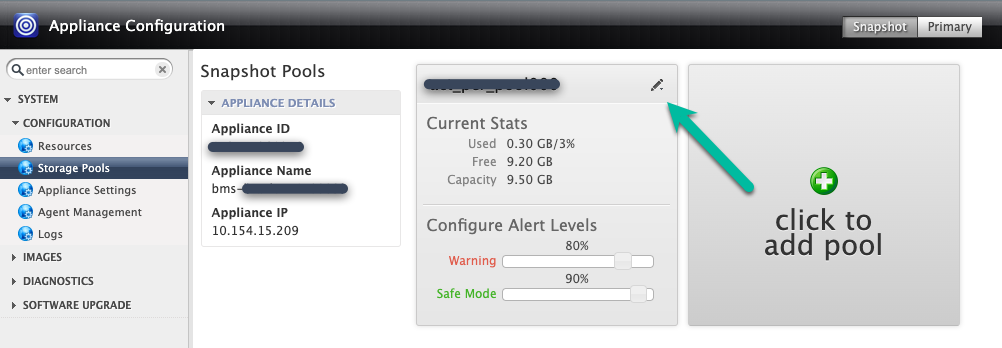
Neste exemplo, você cria um novo pool com a opção Clique para adicionar pool. Depois de clicar nesse botão, aguarde 20 segundos para que a próxima página seja aberta.
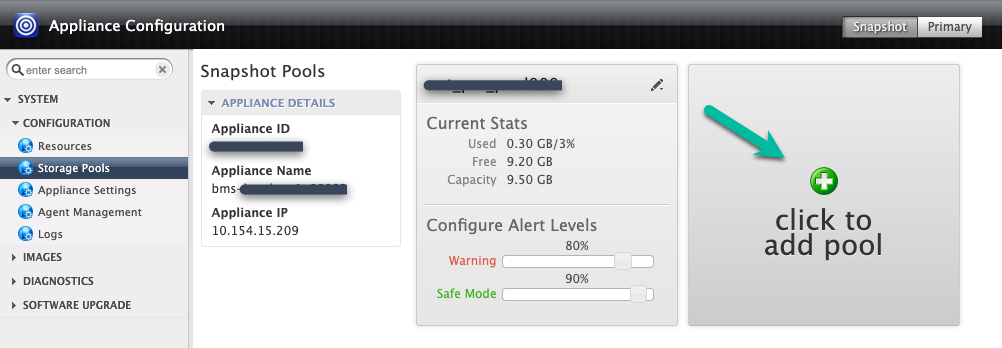
Nesta etapa, configure o novo pool.
- Dê um nome ao pool e clique no ícone + verde para adicionar o disco ao pool.
- Clique em Enviar.
- Para continuar, digite PROCEED em maiúsculas quando solicitado.
Clique em Confirmar.
Agora o pool será expandido ou criado com o disco permanente.
Configurar planos de backup
Os planos de backup permitem que você configure dois elementos principais para fazer backup de qualquer banco de dados, VM ou sistema de arquivos. Os planos de backup incorporam perfis e modelos.
- Os perfis permitem definir quando fazer o backup de algo e por quanto tempo os dados de backup devem ser retidos.
- Os modelos fornecem um item de configuração que permite decidir qual dispositivo de backup/recuperação e pool de armazenamento (Persistent Disk, Cloud Storage etc.) será usado para a tarefa de backup.
criar um perfil
No console de gerenciamento de backup e DR, acesse a página Planos de backup > Perfis.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#manageprofiles
Dois perfis já serão criados. É possível usar um perfil para snapshots de VM do Compute Engine, editar o outro e usá-lo para backups da Solução Bare Metal. É possível ter vários perfis, o que é útil se você estiver fazendo backup de muitos bancos de dados que exigem diferentes níveis de disco para backup. Por exemplo, é possível criar um pool para SSD (desempenho maior) e um para discos permanentes padrão (desempenho padrão). Para cada perfil, é possível escolher um pool de snapshots diferente.
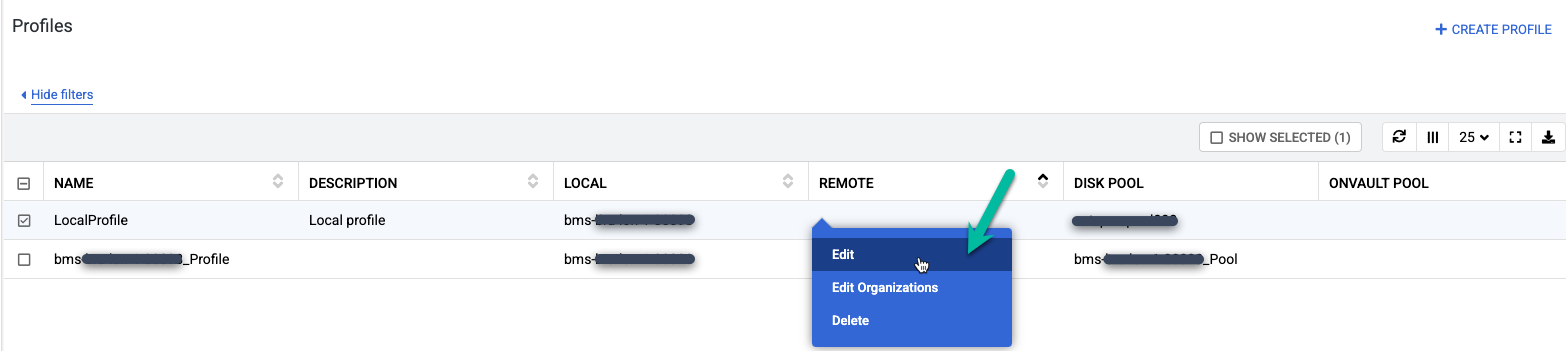
Clique com o botão direito do mouse no perfil padrão chamado LocalProfile e selecione Editar.
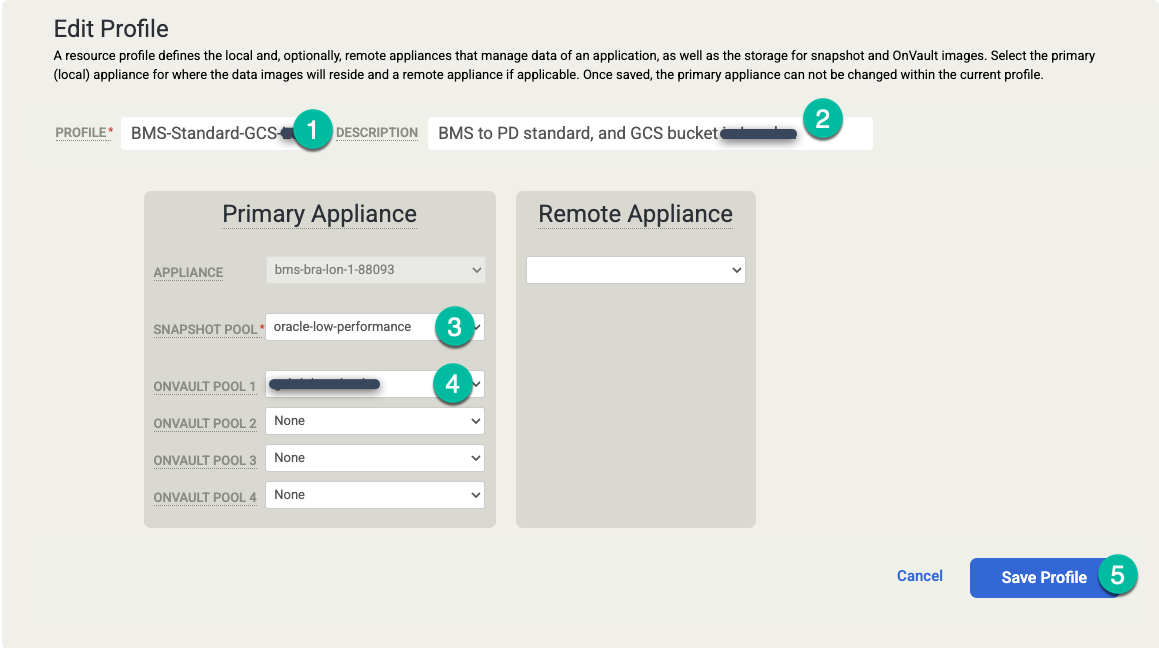
Faça as mudanças a seguir:
- Atualize as configurações de Perfis com um nome e uma descrição de perfil mais significativos. É possível especificar o nível de disco a ser usado, onde os bucket do Cloud Storage estão localizados ou outras informações que explicam a finalidade desse perfil.
- Altere o pool de snapshots para o novo pool expandido ou criado anteriormente.
- Selecione um pool do OnVault (bucket do Cloud Storage) para esse perfil.
Clique em Salvar perfil.
Criar um modelo
No console de gerenciamento de backup e DR, acesse o menu Planos de backup > Modelos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#managetemplates
Clique em +Criar modelo.
- Dê um nome ao modelo.
- Selecione Sim em Permitir modificações de configurações de política.
- Adicione uma descrição deste modelo.
Clique em Salvar modelo.
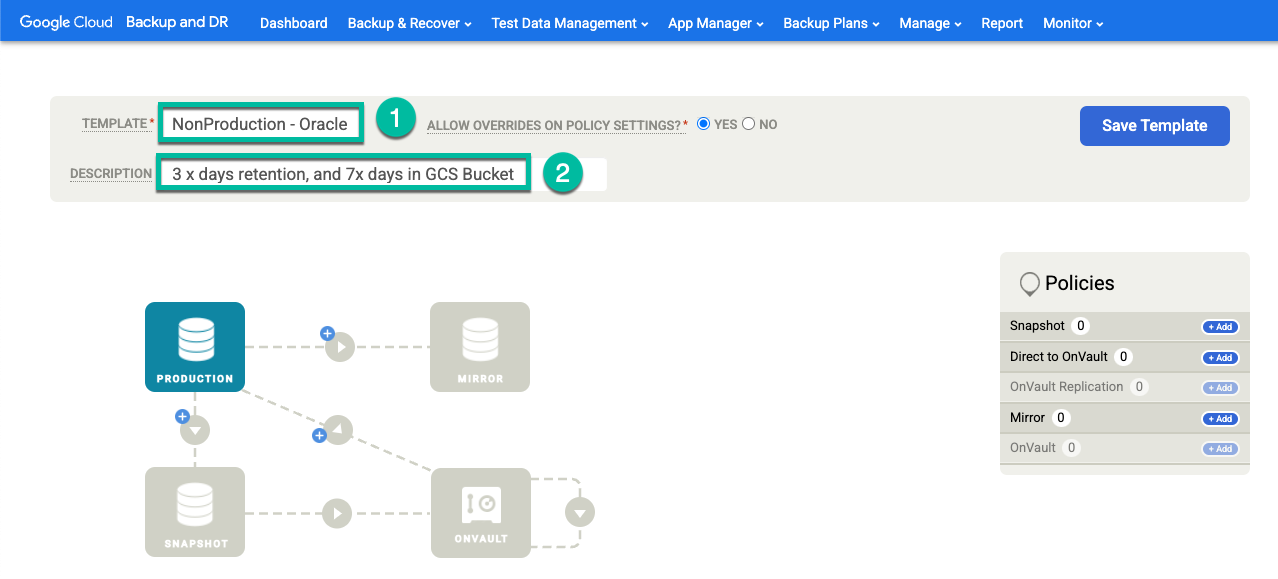
No seu modelo, configure o seguinte:
- Na seção Políticas à direita, clique em +Adicionar.
- Forneça um nome para a política.
- Marque a caixa de seleção dos dias em que a política será executada ou deixe o padrão como Todos os dias.
- Edite a janela dos jobs que você quer executar nesse período.
- Selecione um horário de retenção.
Clique em Configurações avançadas da política.
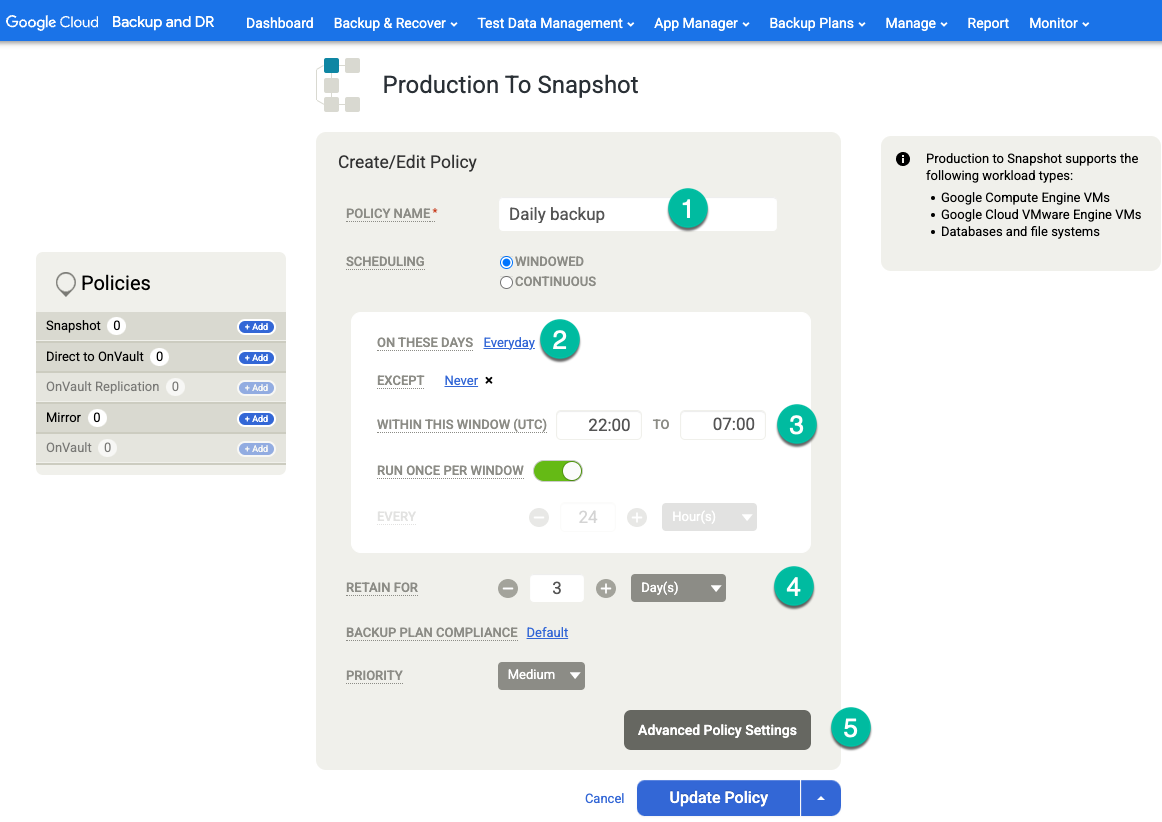
Para fazer backups de registros arquivados com frequência regular (por exemplo, a cada 15 minutos) e replicar os registros para o Cloud Storage, ative as seguintes configurações de política:
- Defina Truncate/Purge Log after Backup como Truncate se você quiser.
- Defina Enable Database Log Backup como Yes se quiser.
- Defina RPO (Minutes) como o intervalo de backup do registro do arquivo.
- Defina Período de retenção do backup de registros (em dias) como o período de armazenamento desejado.
- Defina Replicate Logs (Use Streamsnap Technology) como No.
- Defina Send Logs to OnVault Pool como Yes se você quiser enviar registros para o bucket do Cloud Storage. Caso contrário, selecione Não.
Clique em Salvar alterações.
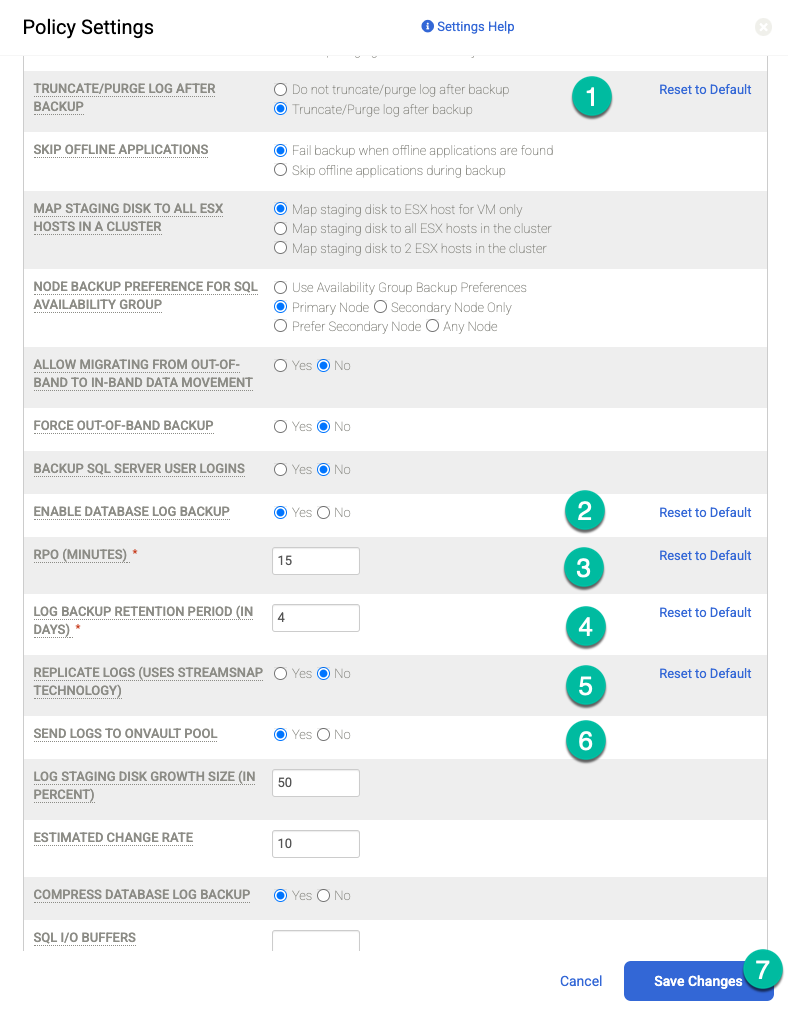
Clique em Fazer update da política para salvar as mudanças.
Para OnVault à direita, execute as seguintes ações:
- Clique em +Add.
- Adicione o nome da política.
- Defina a Retenção em dias, semanas, meses ou anos.
Clique em Atualizar política.
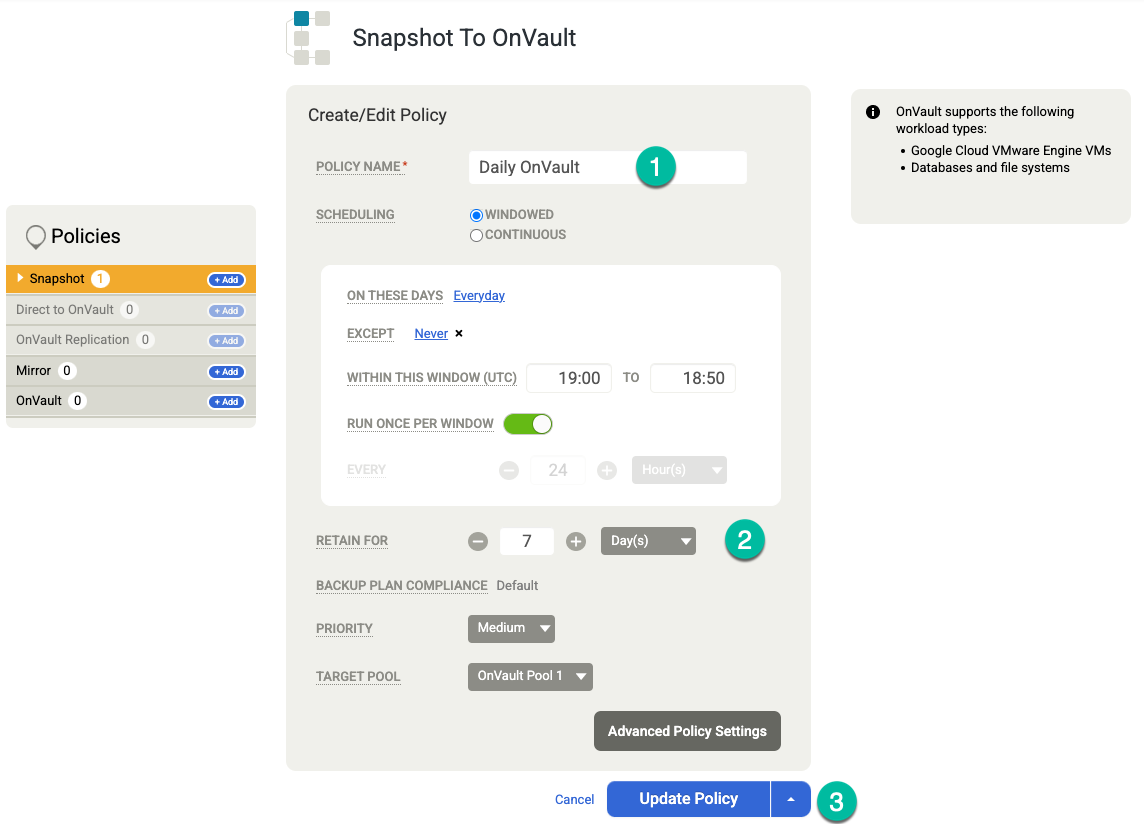
(Opcional) Se você precisar adicionar mais opções de retenção, crie mais políticas para retenção semanal, mensal e anual. Para adicionar outra política de retenção, siga estas etapas:
- Em OnVault à direita, clique em +Adicionar.
- Adicione um nome de política.
- Altere o valor para Nestes dias para o dia em que você quer acionar esse job.
- Defina a Retenção em Dias, Semanas, Meses ou Anos.
Clique em Atualizar política.
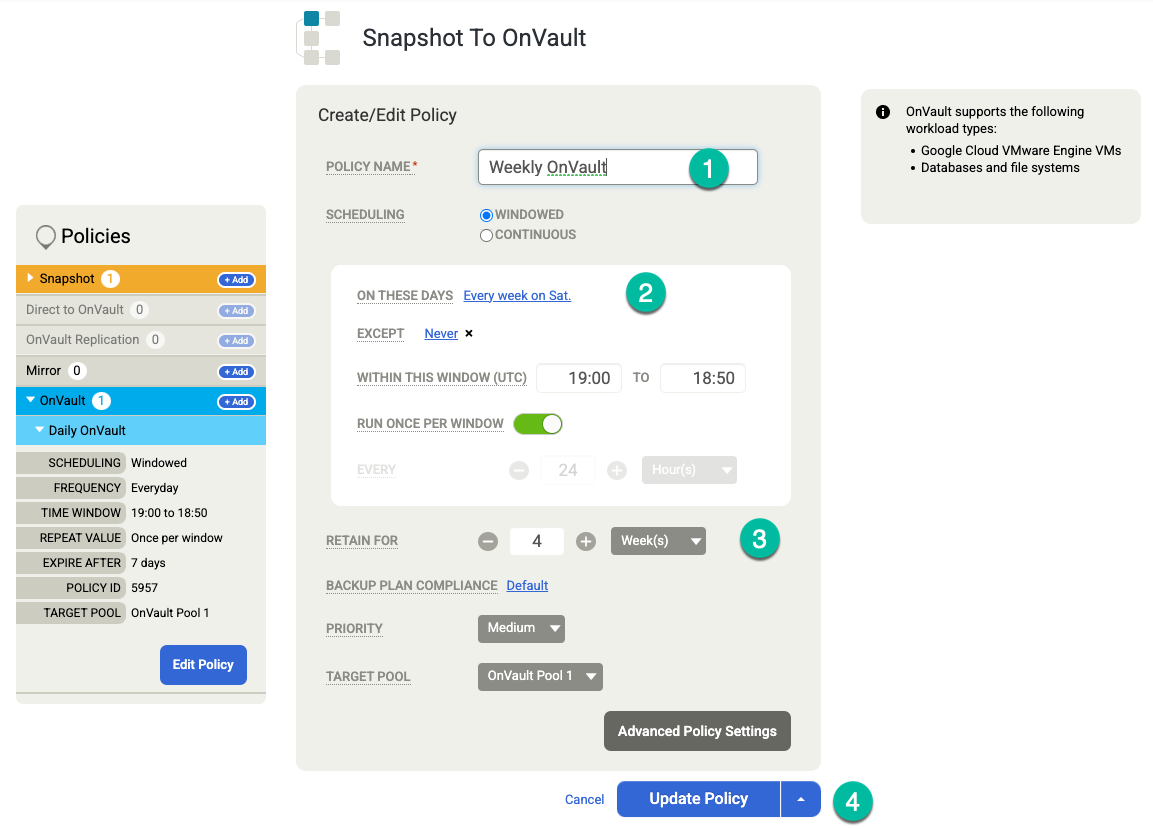
Clique em Salvar modelo. No exemplo a seguir, você verá uma política de snapshot que mantém backups por três dias no nível do Persistent Disk, sete dias para jobs do Vault e um total de quatro semanas. O backup semanal funciona nas noites de sábado.
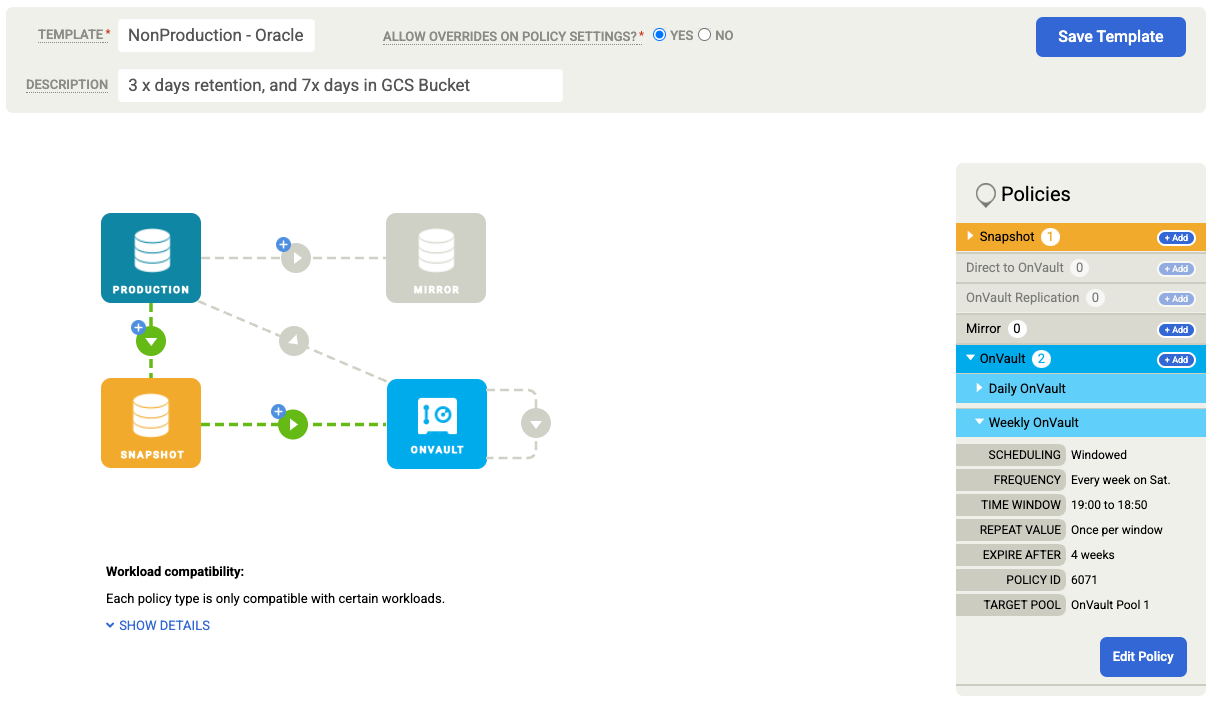
Fazer backup de um database Oracle
A arquitetura de DR e backup do Google Cloud oferece backup Oracle consistente e incremental para Google Cloud, além de recuperação instantânea e clonagem para databases Oracle de vários terabytes.
Google Cloud O Backup e DR usa as seguintes APIs da Oracle:
- API de cópia de imagens RMAN: uma cópia de imagem de um arquivo de dados é muito mais rápida de restaurar porque a estrutura física do arquivo de dados já existe. A diretiva do Recovery Manager (RMAN) BACKUP AS COPY cria cópias de imagem para todos os arquivos de dados de todo o banco de dados e mantém o formato do arquivo de dados.
- API ASM e CRS: use a API Auto Storage Management (ASM) e a API Cluster Ready Services (CRS) para gerenciar o grupo de discos de backup do ASM.
- API de backup de registros RMAN: essa API gera registros de backup, faz backup deles em um disco de preparo e os limpa do local do arquivo de produção.
Configurar os hosts da Oracle
As etapas para configurar os hosts da Oracle incluem instalar o agente, adicionar os hosts ao Backup e DR, configurar os hosts e descobrir os databases da Oracle. Depois que tudo estiver pronto, será possível fazer backups do database Oracle para backup e DR.
Instalar o agente de backup
A instalação do agente de backup e DR é relativamente simples. Você só precisa instalar o agente na primeira vez em que usar o host e, em seguida, os upgrades subsequentes poderão ser feitos na interface do usuário de backup e DR no console do Google Cloud . Você precisa estar conectado como um usuário root ou em uma sessão autenticada do sudo para executar uma instalação do agente. Não é necessário reiniciar o host para concluir a instalação.
Faça o download do agente de backup na interface do usuário ou na página Gerenciar > Eletrodomésticos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#clusters
Clique com o botão direito do mouse no nome do appliance de backup/recuperação e selecione Configurar o appliance. Uma nova janela do navegador será aberta.
Clique no ícone do Linux 64 bits para fazer o download do agente de backup no computador que hospeda a sessão do navegador. Use scp (cópia segura) para mover o arquivo do agente transferido por download para os hosts da Oracle para instalação.
Como alternativa, é possível armazenar o agente de backup em um bucket do Cloud Storage, ativar downloads e usar os comandos
wgetoucurlpara fazer o download do agente diretamente para os hosts do Linux.curl -o agent-Linux-latestversion.rpm https://storage.googleapis.com/backup-agent-images/connector-Linux-11.0.2.9595.rpm
Use o comando
rpm -ivhpara instalar o agente de backup.É muito importante copiar a chave secreta gerada automaticamente. Usando o console de gerenciamento de backup e DR, você precisa adicionar a chave secreta aos metadados do host.
A saída deste comando é semelhante a:
[oracle@host `~]# sudo rpm -ivh agent-Linux-latestversion.rpm Verifying... ################################# [100%] Preparing... ################################# [100%] Updating / installing… 1:udsagent-11.0.2-9595 ################################# [100%] Created symlink /etc/systemd/system/multi-user.target.wants/udsagent.service → /usr/lib/systemd/system/udsagent.service. Action Required: -- Add this host to Backup and DR management console to backup/recover workloads from/to this host. You can do this by navigating to Manage->Hosts->Add Host on your management console. -- A secret key is required to complete this process. Please use b010502a8f383cae5a076d4ac9e868777657cebd0000000063abee83 (valid for 2 hrs) to register this host. -- A new secret key can be generated later by running: '/opt/act/bin/udsagent secret --reset --restart
Se você usar o comando
iptables, abra as portas do firewall do agente de backup (TCP 5106) e dos serviços da Oracle (TCP 1521):sudo iptables -A INPUT -p tcp --dport 5106 -j ACCEPT sudo iptables -A INPUT -p tcp --dport 1521 -j ACCEPT sudo firewall-cmd --permanent --add-port=5106/tcp sudo firewall-cmd --permanent --add-port=1521/tcp sudo firewall-cmd --reload
Adicionar hosts a backup e DR
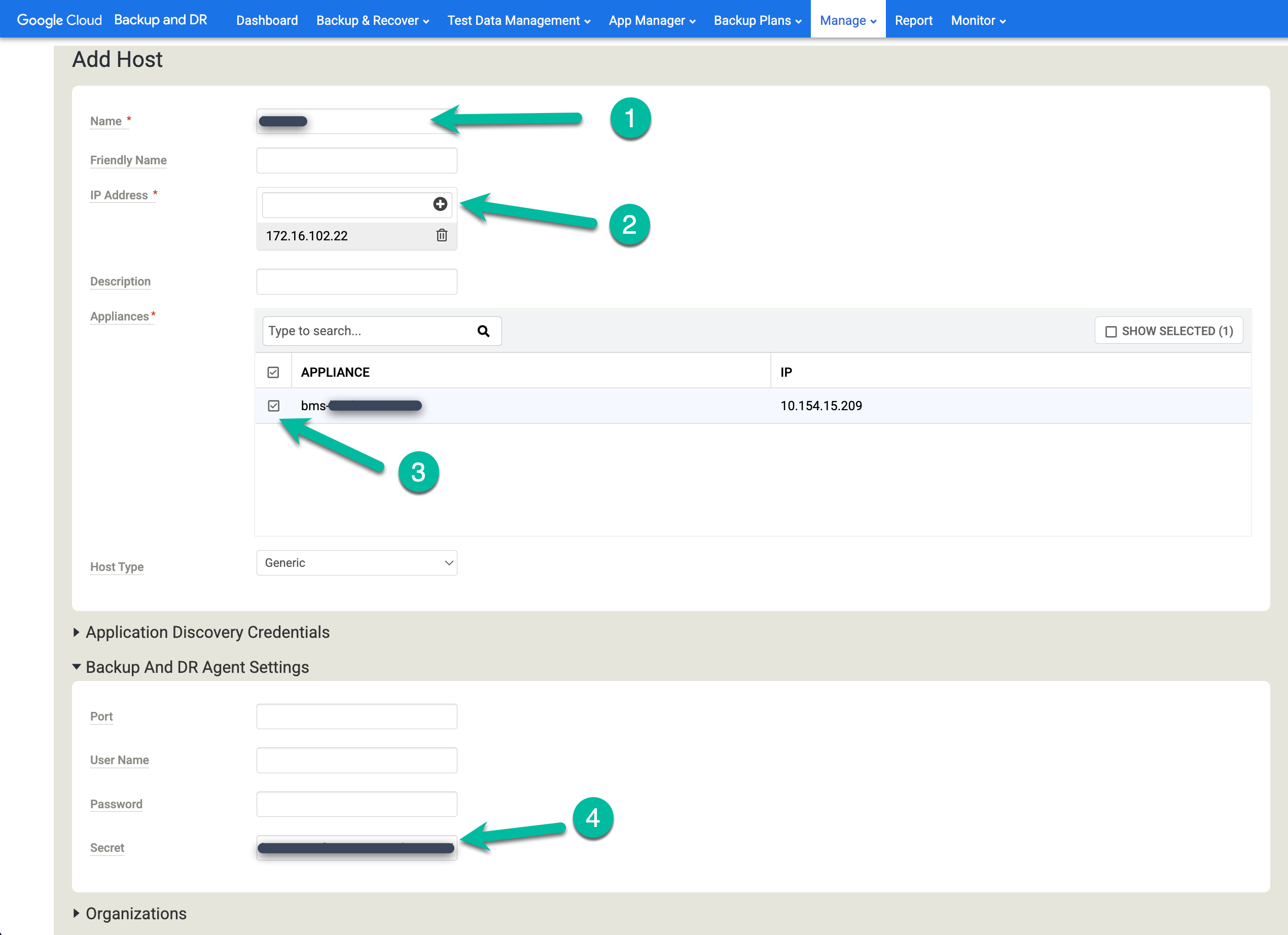
No console de gerenciamento de backup e DR, acesse Manage > Hosts.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
- Clique em +Adicionar host.
- Adicione o nome do host.
- Adicione um endereço IP para o host e clique no botão + para confirmar a configuração.
- Clique nos appliances em que você quer adicionar o host.
- Cole a chave secreta. Execute essa tarefa menos de duas horas depois de instalar o agente de backup e de gerar a chave secreta.
Clique em Adicionar para salvar o host.
Se você receber um erro ou uma mensagem de Sucesso parcial, tente as seguintes soluções alternativas:
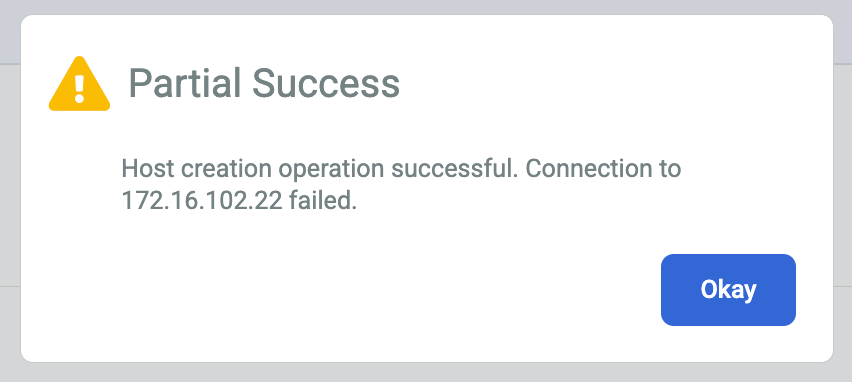
A chave secreta da criptografia do agente de backup pode ter expirado. Se você não adicionou a chave secreta ao host em duas horas após a criação. É possível gerar uma nova chave secreta no host Linux usando a seguinte sintaxe de linha de comando:
/opt/act/bin/udsagent secret --reset --restart
O firewall que permite a comunicação entre o appliance de backup/recuperação e o agente instalado no host pode não estar configurado corretamente. Siga as etapas para abrir as portas do firewall do agente de backup e dos serviços da Oracle.
A configuração do Network Time Protocol (ntp) para seus hosts do Linux pode estar configurada incorretamente. Verifique se as configurações de NTP estão corretas.
Ao corrigir o problema, o Status do certificado mudará de N/D para Válido.

Configurar os hosts
No console de gerenciamento de backup e DR, acesse Manage > Hosts.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#hosts
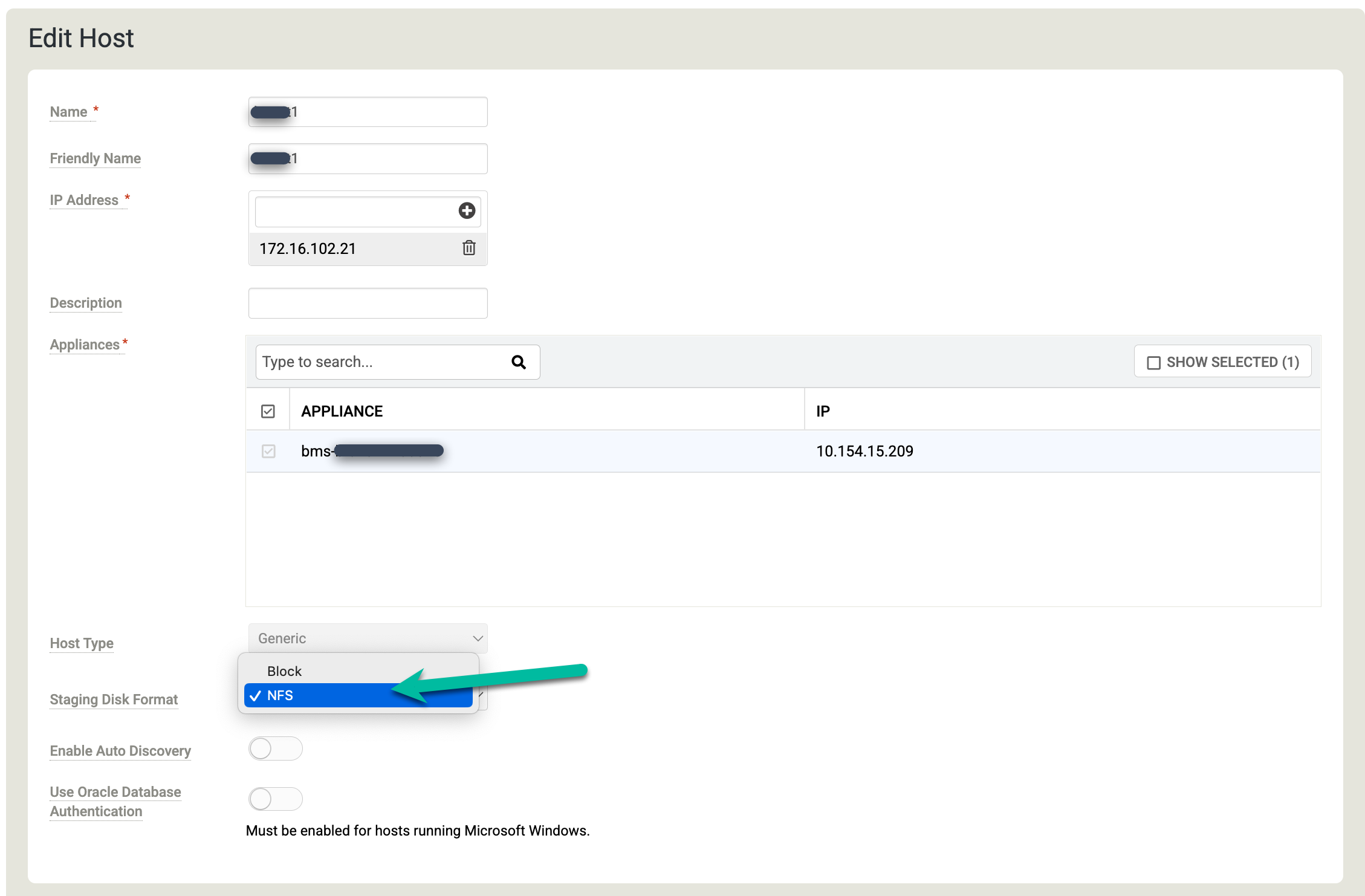
Clique com o botão direito do mouse no host do Linux em que você quer fazer backup dos databases Oracle e selecione Editar.
Clique em Como preparar o formato do disco e selecione NFS.
Role para baixo até a seção Aplicativos descobertos e clique em Descobrir aplicativos para iniciar o processo de descoberta do appliance para o agente.
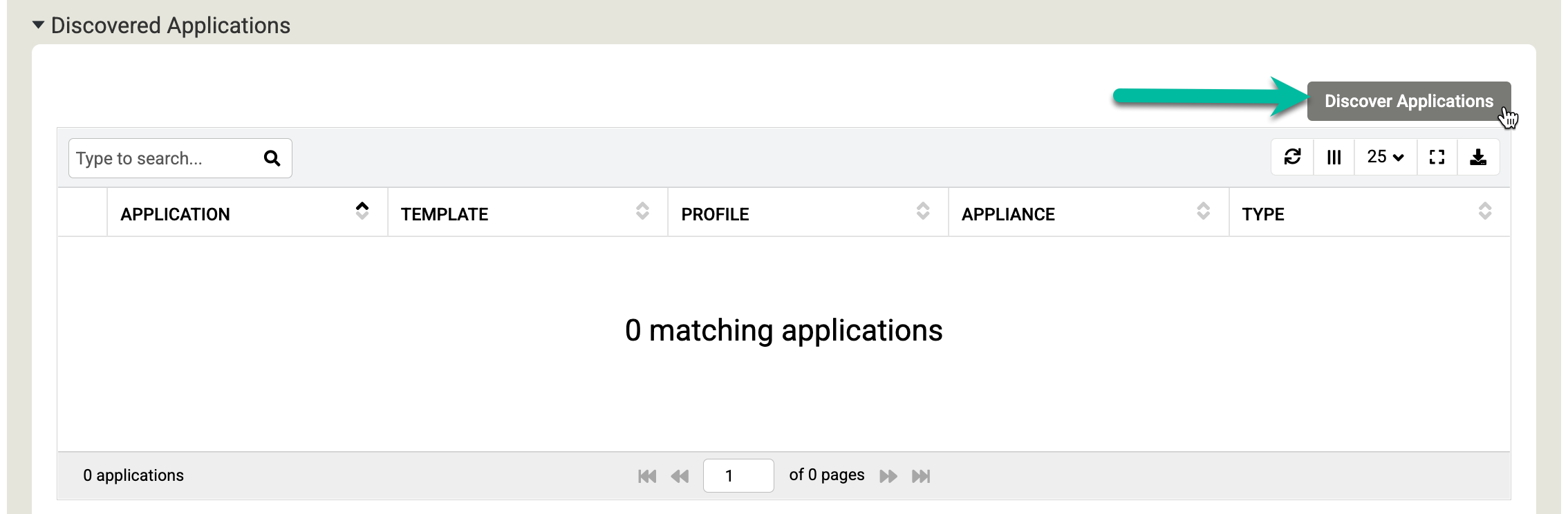
Clique em Discover para iniciar o processo. O processo de descoberta leva até 5 minutos. Quando concluídos, os sistemas de arquivos descobertos e os databases Oracle aparecem na janela de aplicativos.
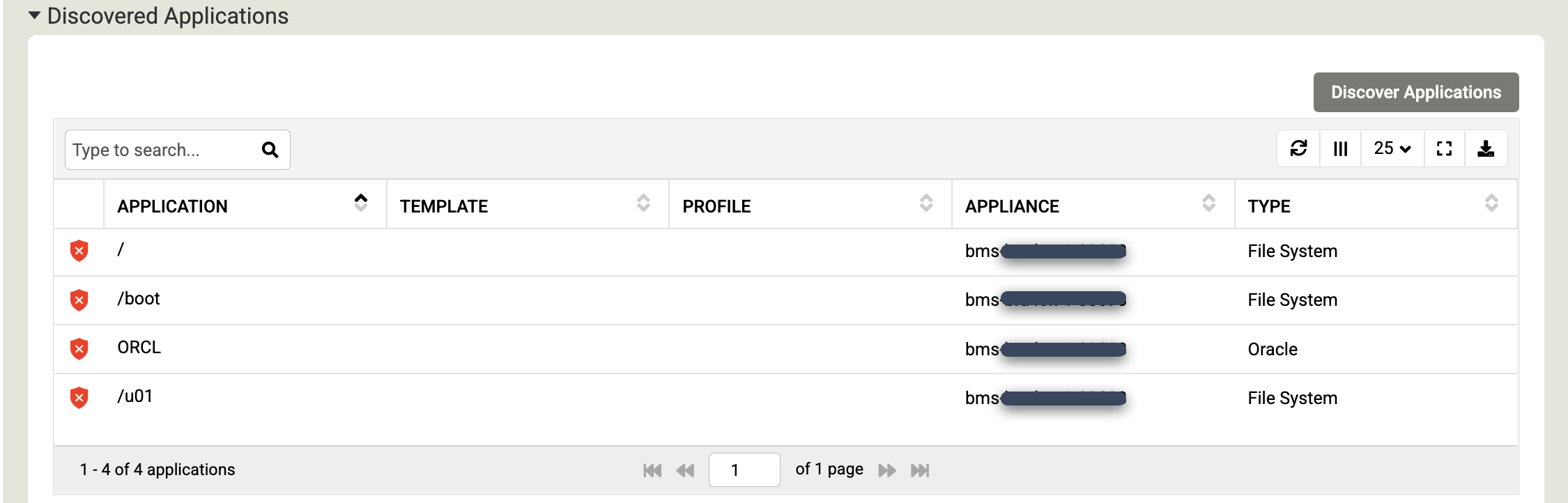
Clique em Salvar para atualizar as alterações nos hosts.
Preparar o host Linux
Ao instalar pacotes de utilitários iSCSI ou NFS no seu host baseado no SO Linux, é possível mapear um disco de preparo para um dispositivo que grava os dados de backup. Use os comandos a seguir para instalar os utilitários iSCSI e NFS. Embora seja possível usar um ou ambos os conjuntos de utilitários, esta etapa garante que você tenha o que precisa quando precisa.
Para instalar os utilitários iSCSI, execute o seguinte comando:
sudo yum install -y iscsi-initiator-utils
Para instalar os utilitários NFS, execute o seguinte comando:
sudo yum install -y nfs-utils
Preparar o database Oracle
Este guia pressupõe que você já tenha uma instância e um banco de dados Oracle configurados. Google Cloud O Backup e DR é compatível com a proteção de bancos de dados em execução em sistemas de arquivos, ASM, clusters de aplicativos reais (RAC) e muitas outras configurações. Para mais informações, consulte Backup e DR para databases Oracle.
Você precisa configurar alguns itens antes de iniciar o job de backup. Algumas dessas tarefas são opcionais, mas recomendamos as seguintes configurações para um desempenho ideal:
- Use SSH para se conectar ao host Linux e faça login como o usuário Oracle com privilégios su.
Defina o ambiente Oracle como sua instância específica:
. oraenv ORACLE_SID = [ORCL] ? The Oracle base remains unchanged with value /u01/app/oracle
Conecte-se ao SQL*Plus com a conta
sysdba:sqlplus / as sysdba
Use os seguintes comandos para ativar o modo ARCHIVELOG. A saída deste comando é semelhante a:
SQL> shutdown Database closed. Database dismounted. ORACLE instance shut down. SQL> startup mount ORACLE instance started. Total System Global Area 2415918600 bytes Fixed Size 9137672 bytes Variable Size 637534208 bytes Database Buffers 1761607680 bytes Redo Buffers 7639040 bytes Database mounted. SQL> alter database archivelog; Database altered. SQL> alter database open; Database altered. SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination /u01/app/oracle/product/19c/dbhome_1/dbs/arch Oldest online log sequence 20 Next log sequence to archive 22 Current log sequence 22 SQL> alter pluggable database ORCLPDB save state; Pluggable database altered.
Configure o NFS direto para o host Linux:
cd $ORACLE_HOME/rdbms/lib make -f [ins_rdbms.mk](http://ins_rdbms.mk/) dnfs_on
Configure o acompanhamento de alterações em blocos. Primeiro, verifique se ele está ativado ou desativado. O exemplo a seguir mostra o acompanhamento de alterações em blocos como desativado:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ DISABLED
SQL> alter database enable block change tracking using file +ASM_DISK_GROUP_NAME/DATABASE_NAME/DBNAME.bct; Database altered.
Emita o seguinte comando ao usar um sistema de arquivos:
SQL> alter database enable block change tracking using file '$ORACLE_HOME/dbs/DBNAME.bct';; Database altered.
Verifique se o rastreamento de alterações de bloqueio está ativado:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Proteger um database Oracle
No console de gerenciamento de backup e DR, acesse a página Gerenciador de apps > Aplicativos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Clique com o botão direito do mouse no nome do database Oracle que você quer proteger e selecione Gerenciar plano de backup no menu.
Selecione o modelo e o perfil que você quer usar e clique em Aplicar plano de backup.
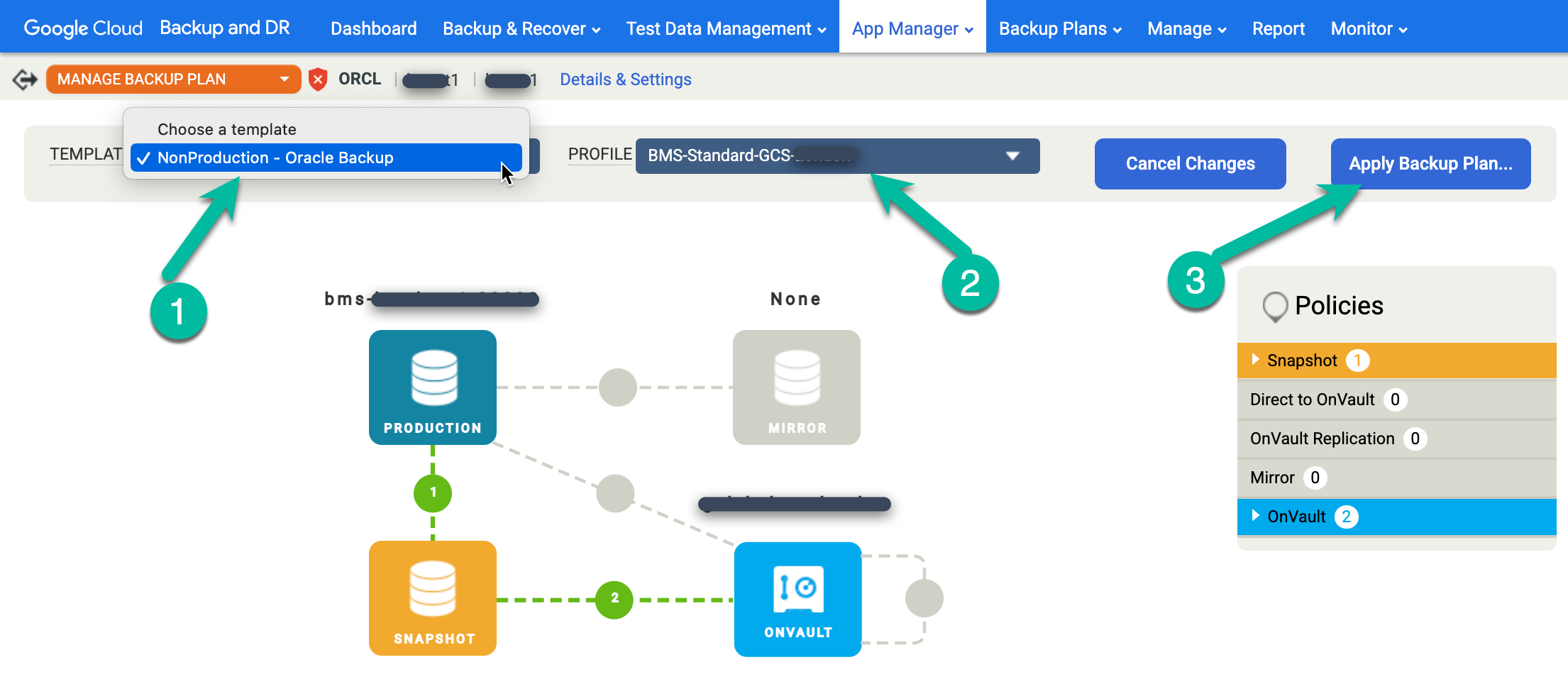
Quando solicitado, defina as Configurações avançadas específicas para Oracle e RMAN que são necessárias para sua configuração. Quando terminar, clique em Aplicar plano de backup.
Número de canais, por exemplo, o padrão é 2. Portanto, se você tiver um número maior de núcleos de CPU, poderá aumentar o número de canais para operações de backup paralelo e defini-lo como um número maior.
Para saber mais sobre configurações avançadas, consulte Definir detalhes e configurações do aplicativo para databases Oracle.
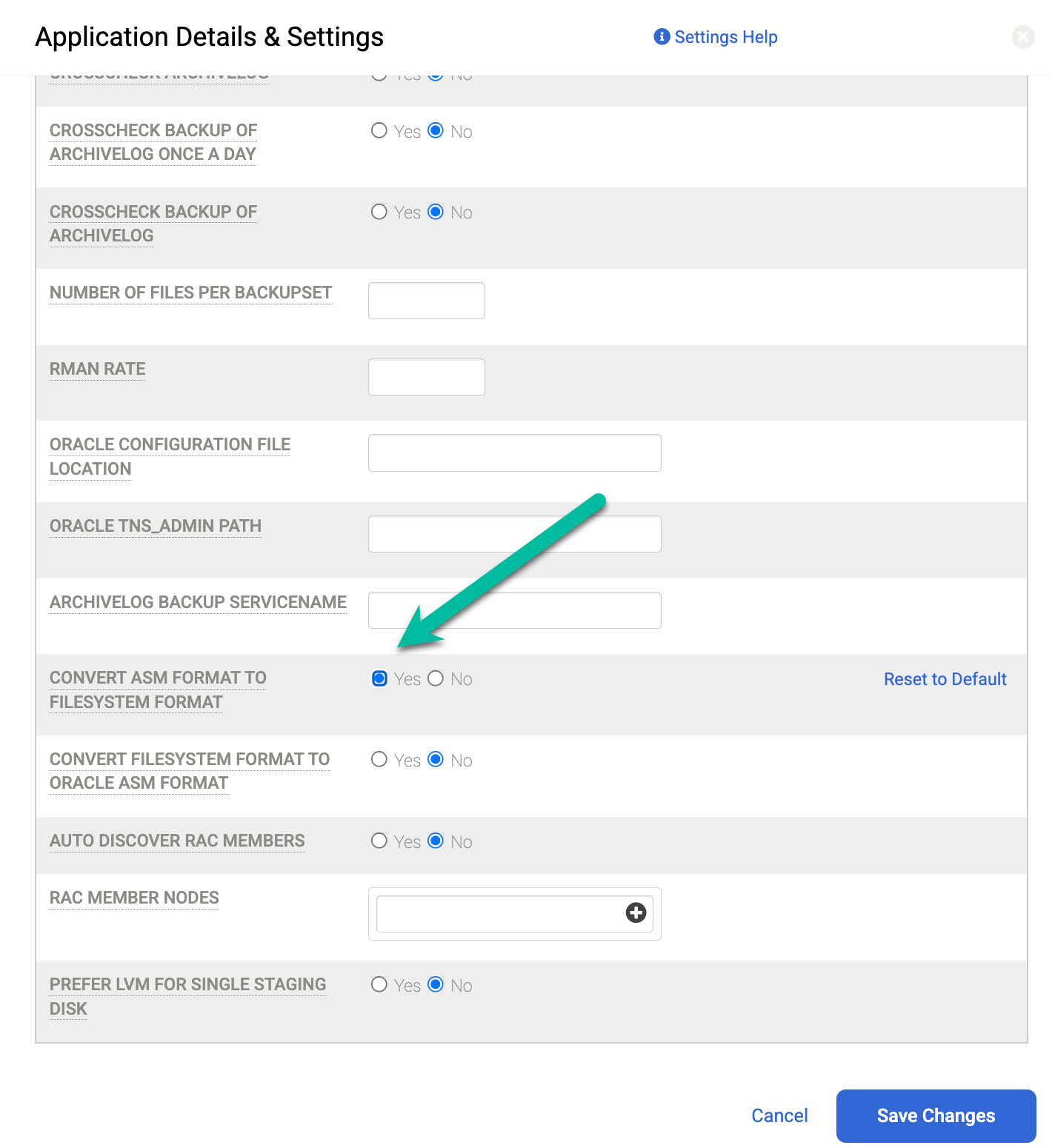
Além dessas configurações, é possível mudar o protocolo que o disco de preparo usa para mapear o disco do Backup Appliance para o host. Acesse a página Gerenciar > Hosts e selecione o host que você quer Editar. Marque a opção Como preparar o formato do disco como convidado. Por padrão, o formato Bloquear é selecionado. Isso mapeia o disco de preparo via iSCSI. Caso contrário, ele pode ser alterado para NFS. Em seguida, o disco de teste usa o disco Protocolo NFS.
As configurações padrão dependem do formato do database. Se você usa o ASM, o sistema usa o
iSCSI para enviar ao backup um grupo de discos do ASM. Se você usar um sistema de arquivos, ele
usará o iSCSI para enviar o backup a um sistema de arquivos. Se você quiser usar NFS ou Direct
NFS (dNFS), altere as configurações de Hosts do disco de preparo para
NFS. Em vez disso, se você usar a configuração padrão, todos os discos de preparo de backup usarão o formato de armazenamento em blocos e o iSCSI.
Iniciar o job de backup
No console de gerenciamento de backup e DR, acesse a página Gerenciador de apps > Aplicativos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Clique com o botão direito do mouse no database Oracle que você quer proteger e escolha Gerenciar plano de backup no menu.
Clique no menu Instantâneo à direita e clique em Executar agora. Isso inicia um job de backup sob demanda.
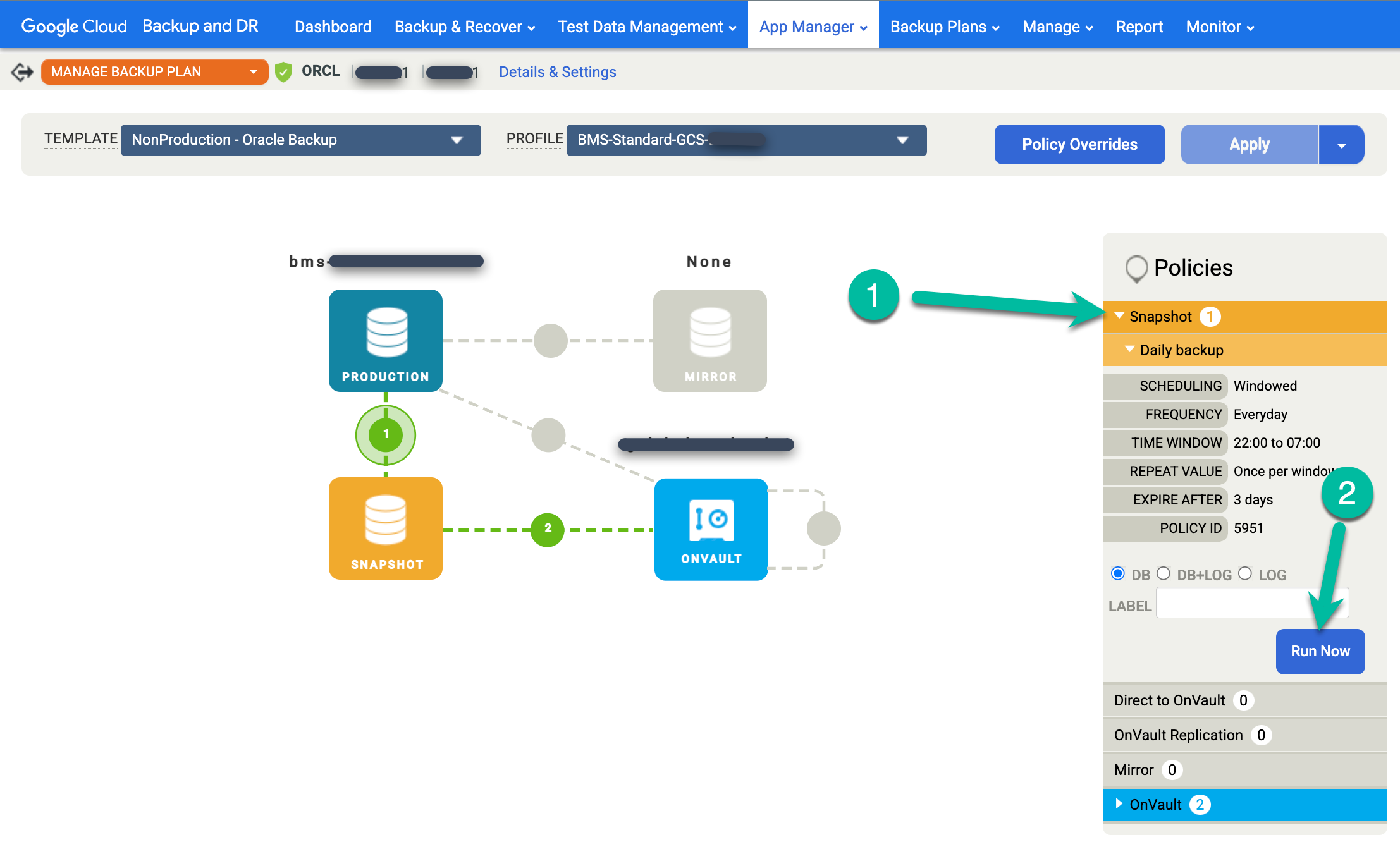
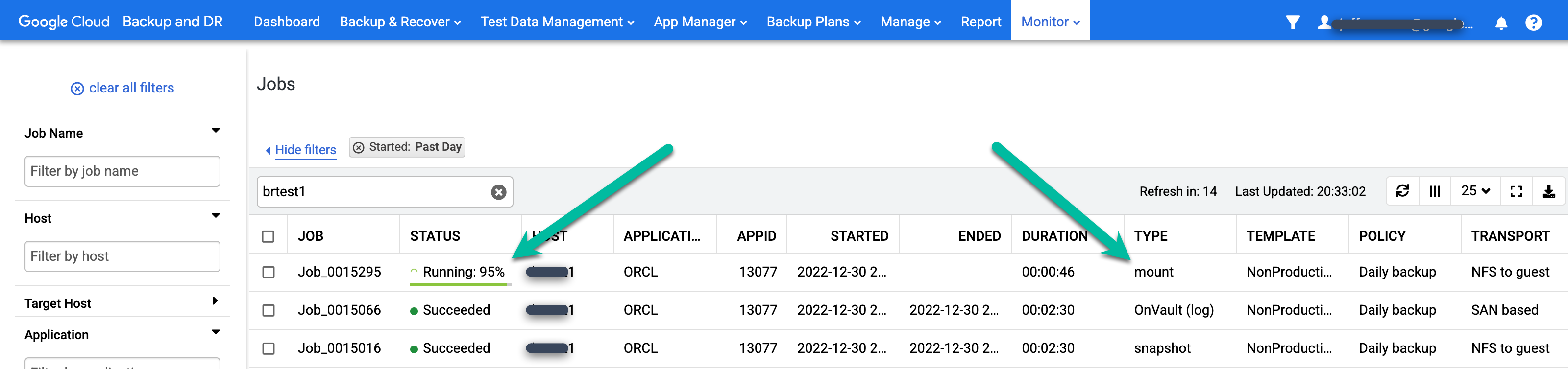
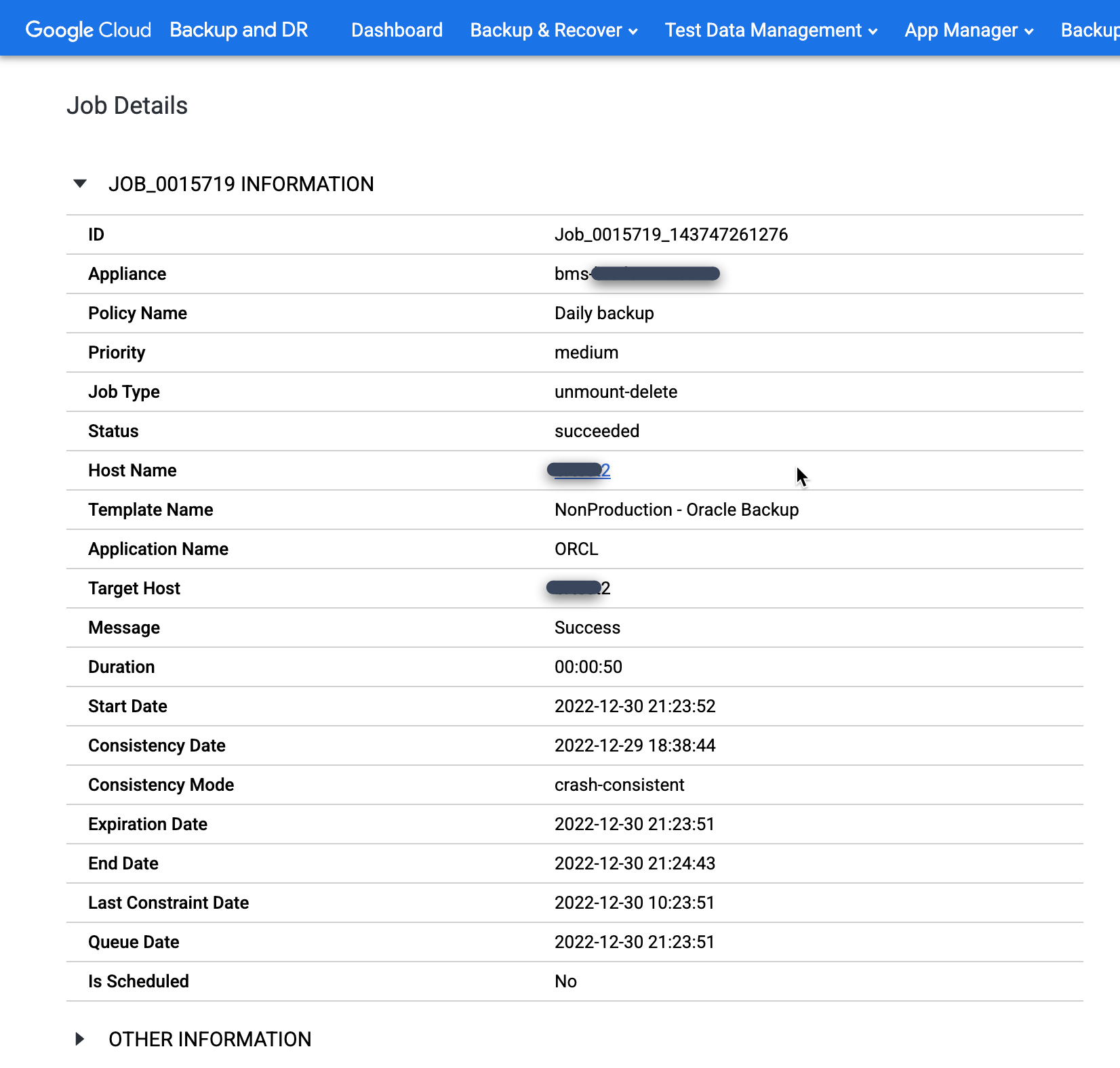
Para monitorar o status do job de backup, acesse o menu Monitorar > Jobs e confira o status do job. Pode levar de 5 a 10 segundos para um job aparecer na lista. Confira a seguir um exemplo de job em execução:

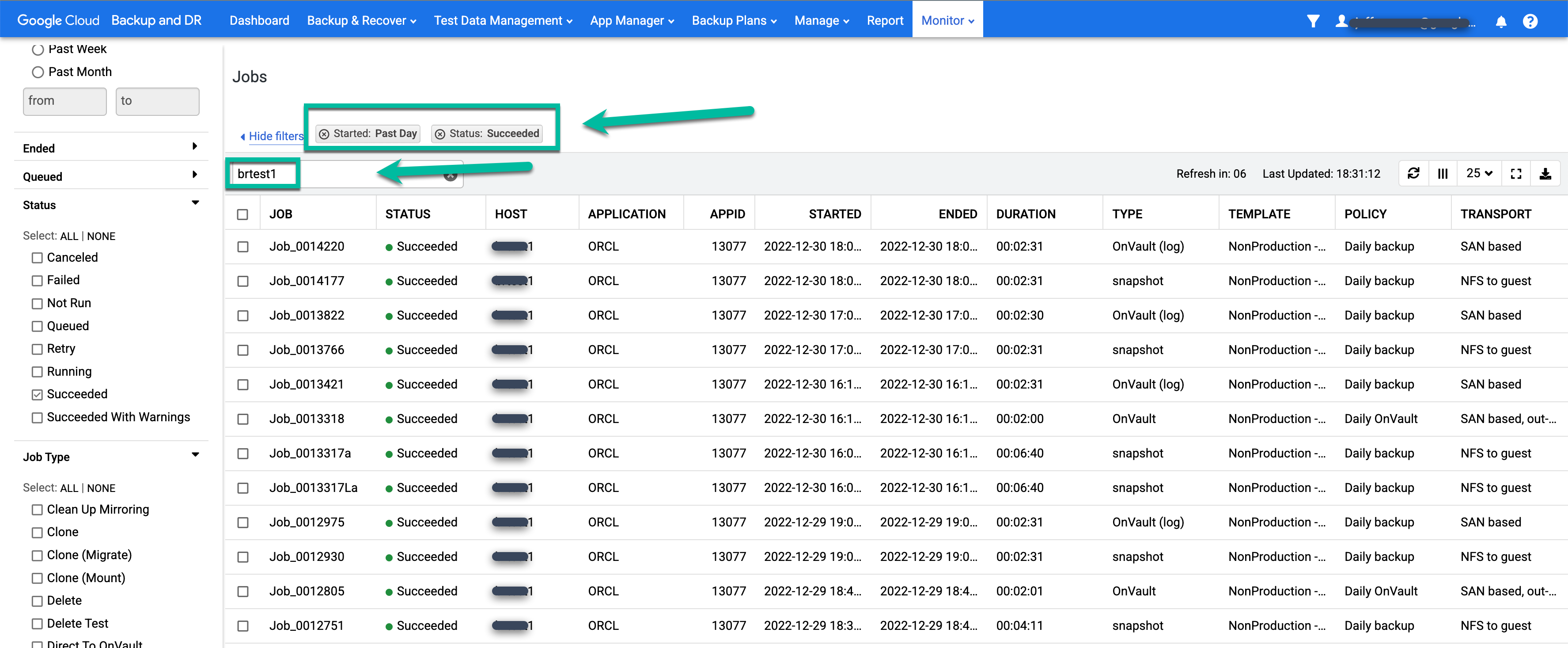
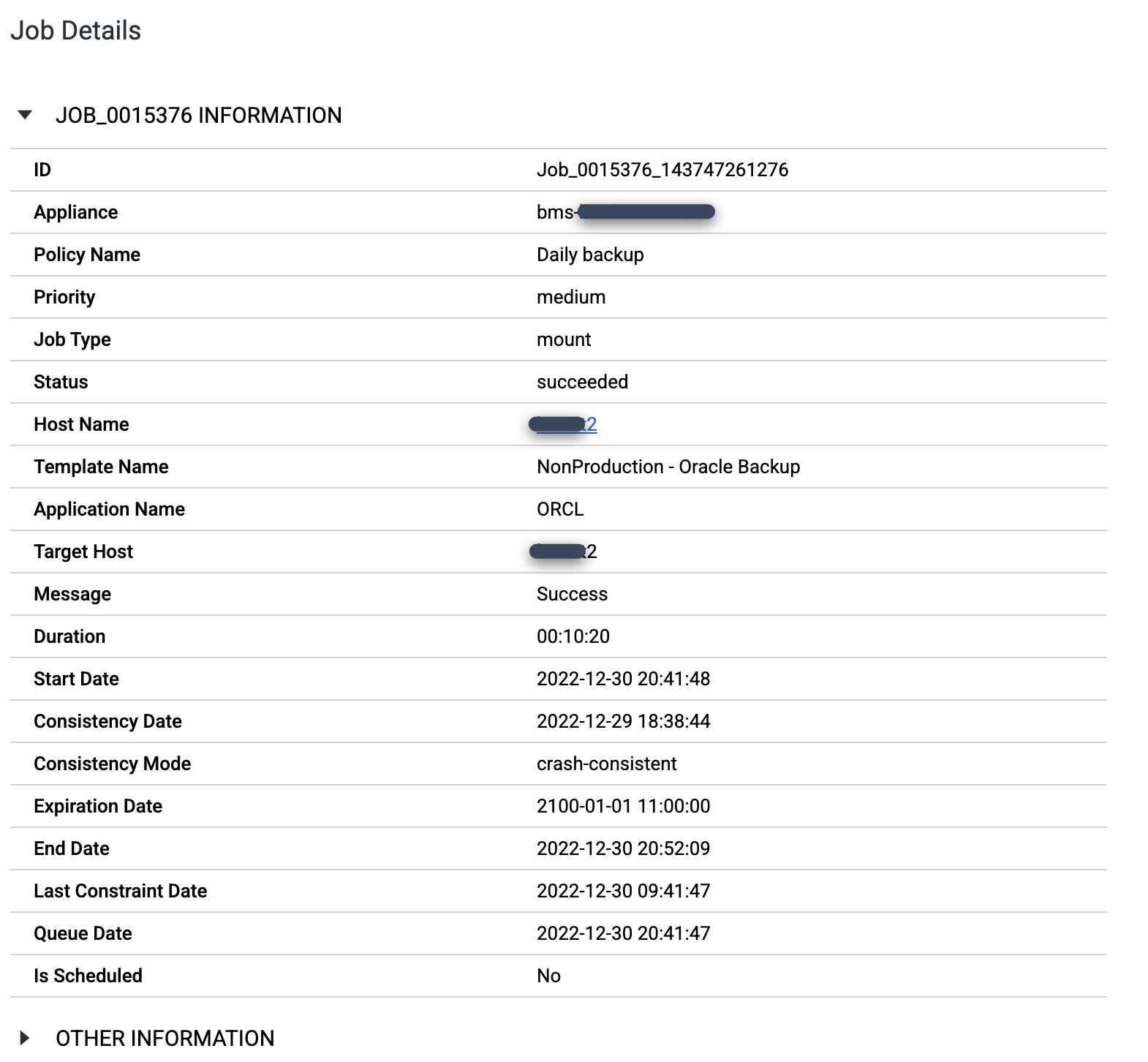
Quando um job é bem-sucedido, você pode usar metadados para visualizar os detalhes de um job específico.
- Aplique filtros e adicione termos de pesquisa para encontrar vagas de seu interesse. O exemplo a seguir usa os filtros Succeeded e Past Day, junto com uma pesquisa para o host test1.
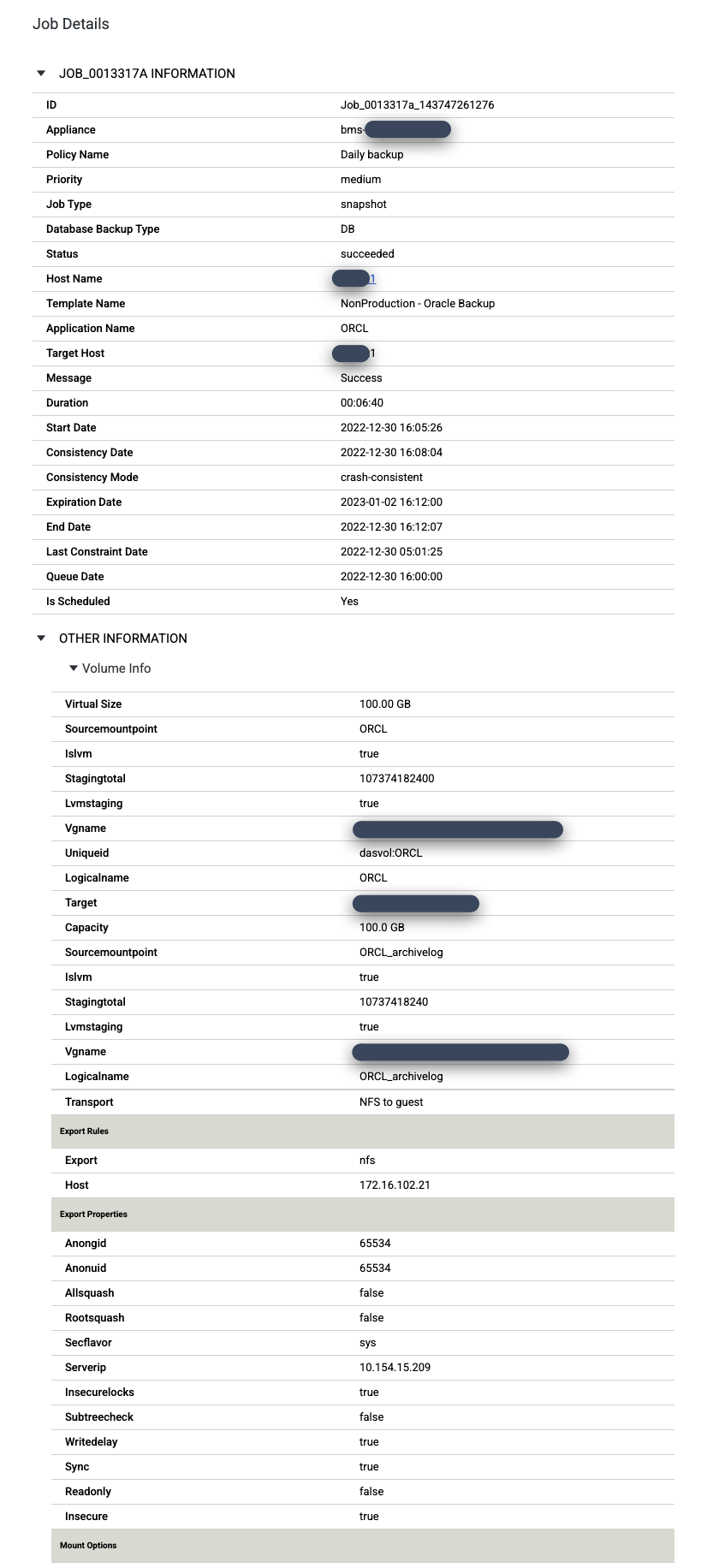
Para ver mais de perto um job específico, clique nele na coluna Job. Uma nova janela será aberta. Como você pode ver no exemplo a seguir, cada job de backup captura uma grande quantidade de informações.
Ativar e restaurar um database Oracle
Google Cloud O Backup e DR tem vários recursos diferentes para acessar uma cópia de um banco de dados Oracle. Os dois métodos principais são os seguintes:
- Ativações compatíveis com apps
- Restaurações (ativação e migração e restauração tradicional)
Cada um desses métodos tem benefícios diferentes. Portanto, você precisa selecionar qual deles quer usar, dependendo do seu caso de uso, dos requisitos de desempenho e de quanto tempo precisa manter a cópia do banco de dados. As seções a seguir contêm algumas recomendações para cada recurso.
Ativações compatíveis com apps
Use ativações para ter acesso rápido a uma cópia virtual de um database Oracle. É possível configurar uma ativação quando o desempenho não é crítico, e a cópia do banco de dados fica ativa por apenas algumas horas ou até alguns dias.
O principal benefício de uma ativação é que ela não consome grandes quantidades de armazenamento extra. Em vez disso, a ativação usa um snapshot do pool de discos de backup, que pode ser um pool de snapshots em um Persistent Disk ou um pool do OnVault no Cloud Storage. O uso do recurso de snapshot de cópia virtual minimiza o tempo de acesso aos dados porque eles não precisam ser copiados primeiro. O disco de backup processa todas as leituras, e um disco no pool de snapshots armazena todas as gravações. Como resultado, a ativação de cópias virtuais é rápida e não substitui a cópia do disco de backup. As ativações são ideais para desenvolvimento, teste e atividades de DBA em que alterações ou atualizações de esquema precisam ser validadas antes de serem implementadas na produção.
Ativar um database Oracle
No console de gerenciamento de backup e DR, acesse a página Backup e recuperação > Recuperar.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
Na lista Aplicativo, encontre o banco de dados que você quer ativar, clique com o botão direito do mouse no nome do banco de dados e clique em Próxima:
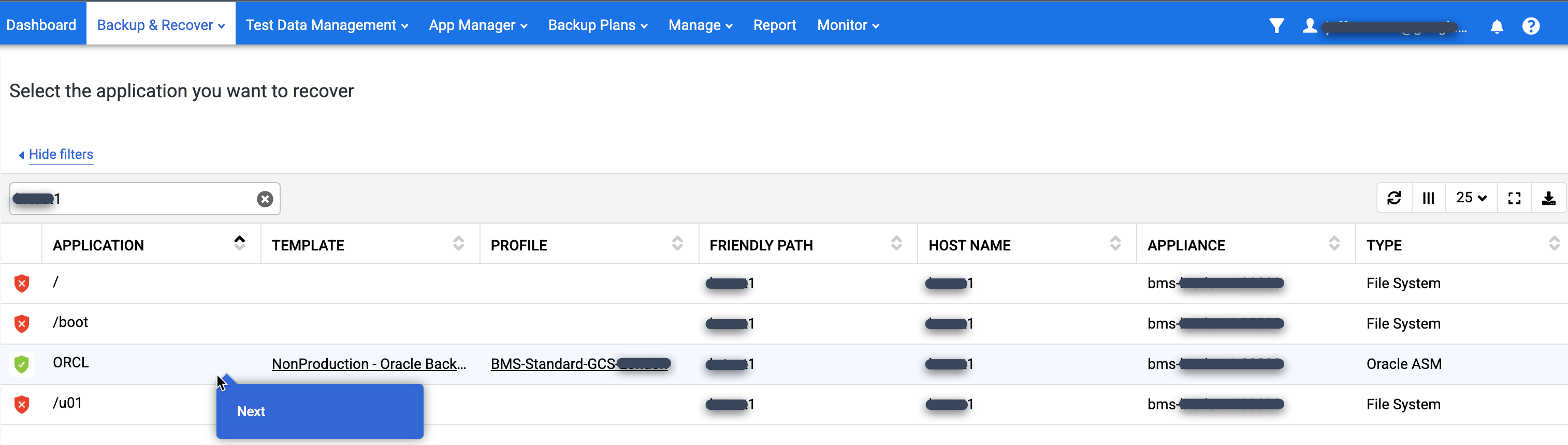
A visualização da rampa do cronograma aparece e mostra todas as imagens pontual disponíveis. Também é possível voltar para ver imagens de retenção de longo prazo se elas não aparecerem na visualização de rampa. Por padrão, o sistema seleciona a imagem mais recente.
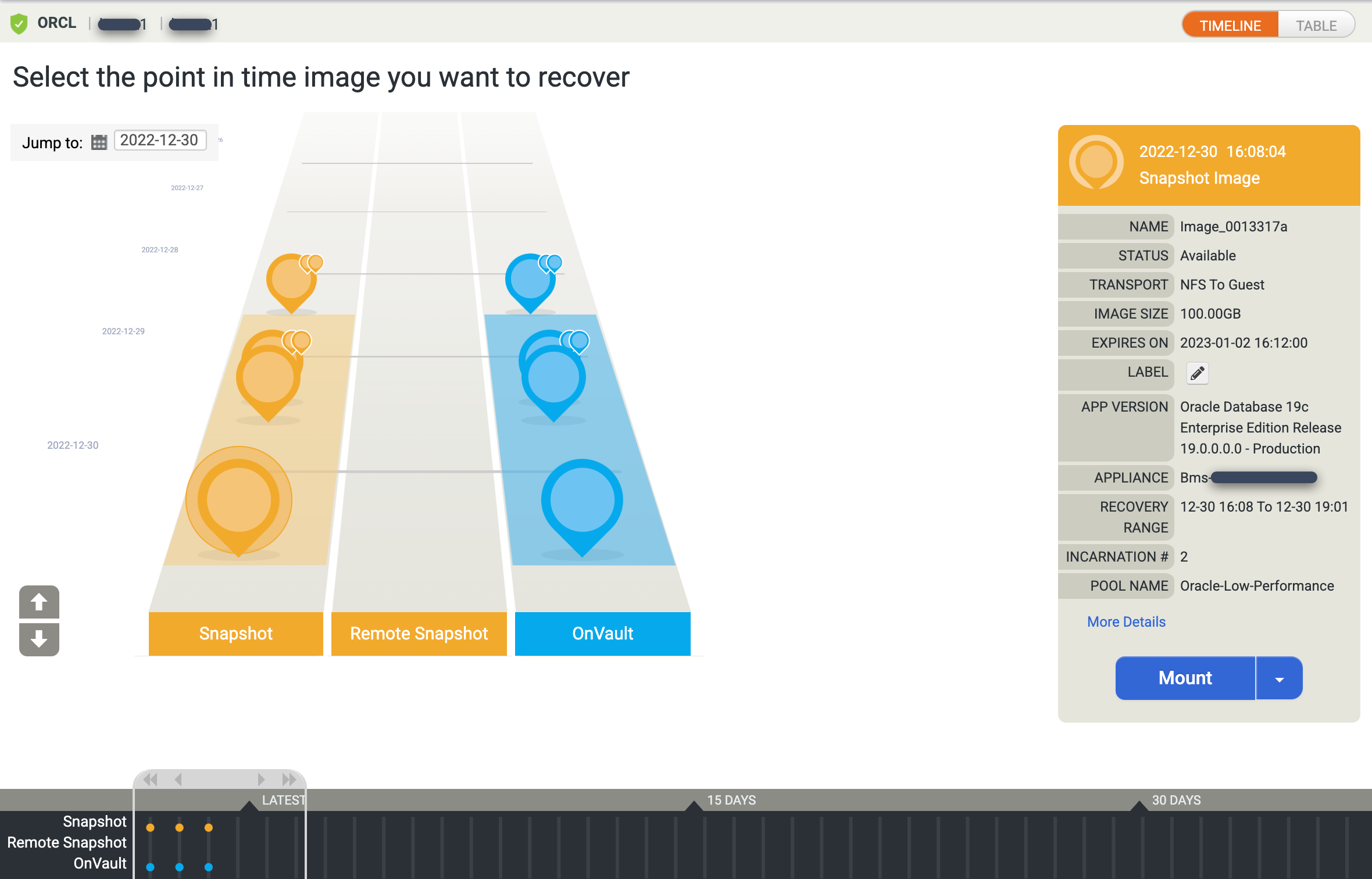
Se preferir uma visualização em tabela para as imagens pontuais, clique na opção Tabela para mudar a visualização:
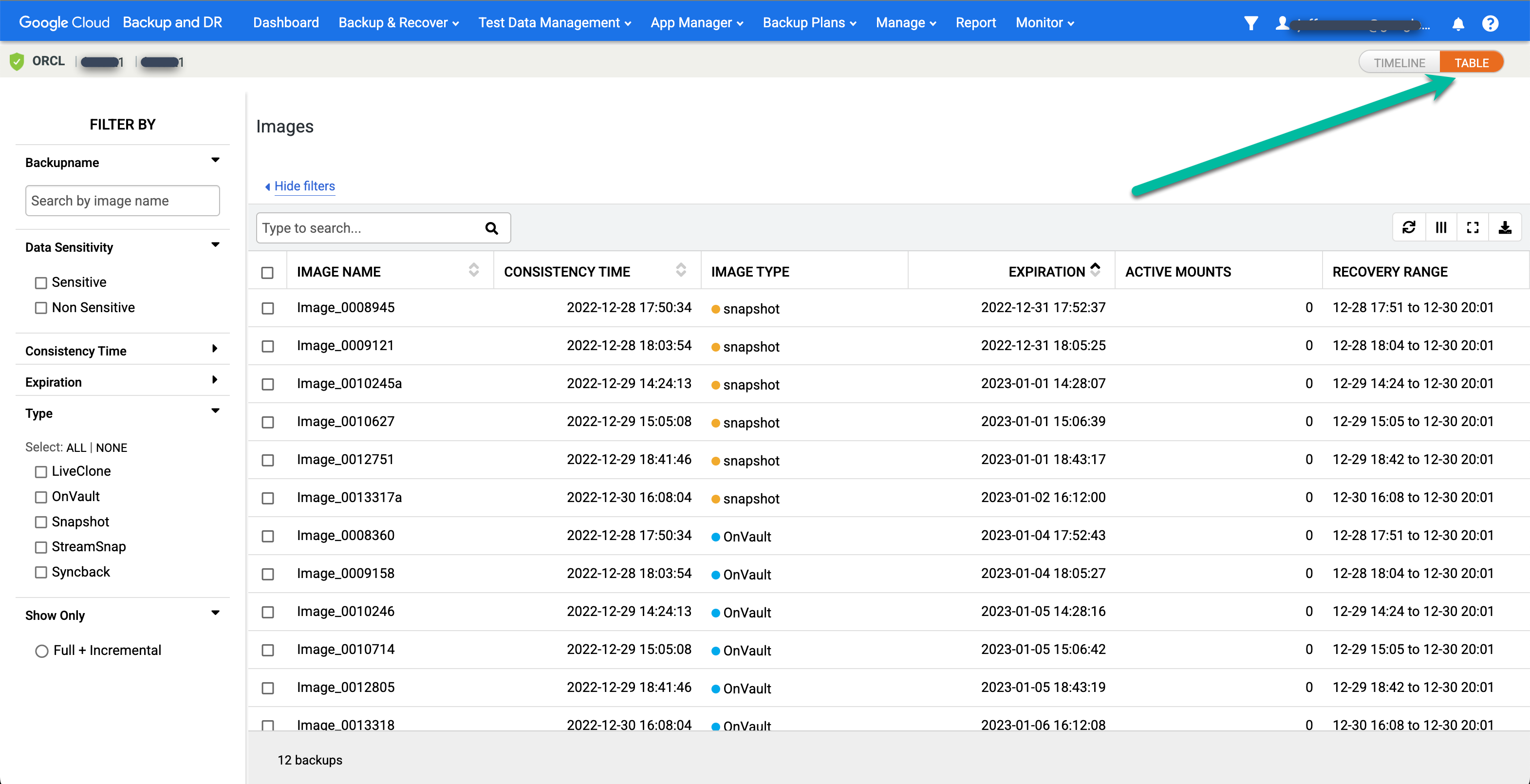
Encontre a imagem desejada e selecione Ativar:
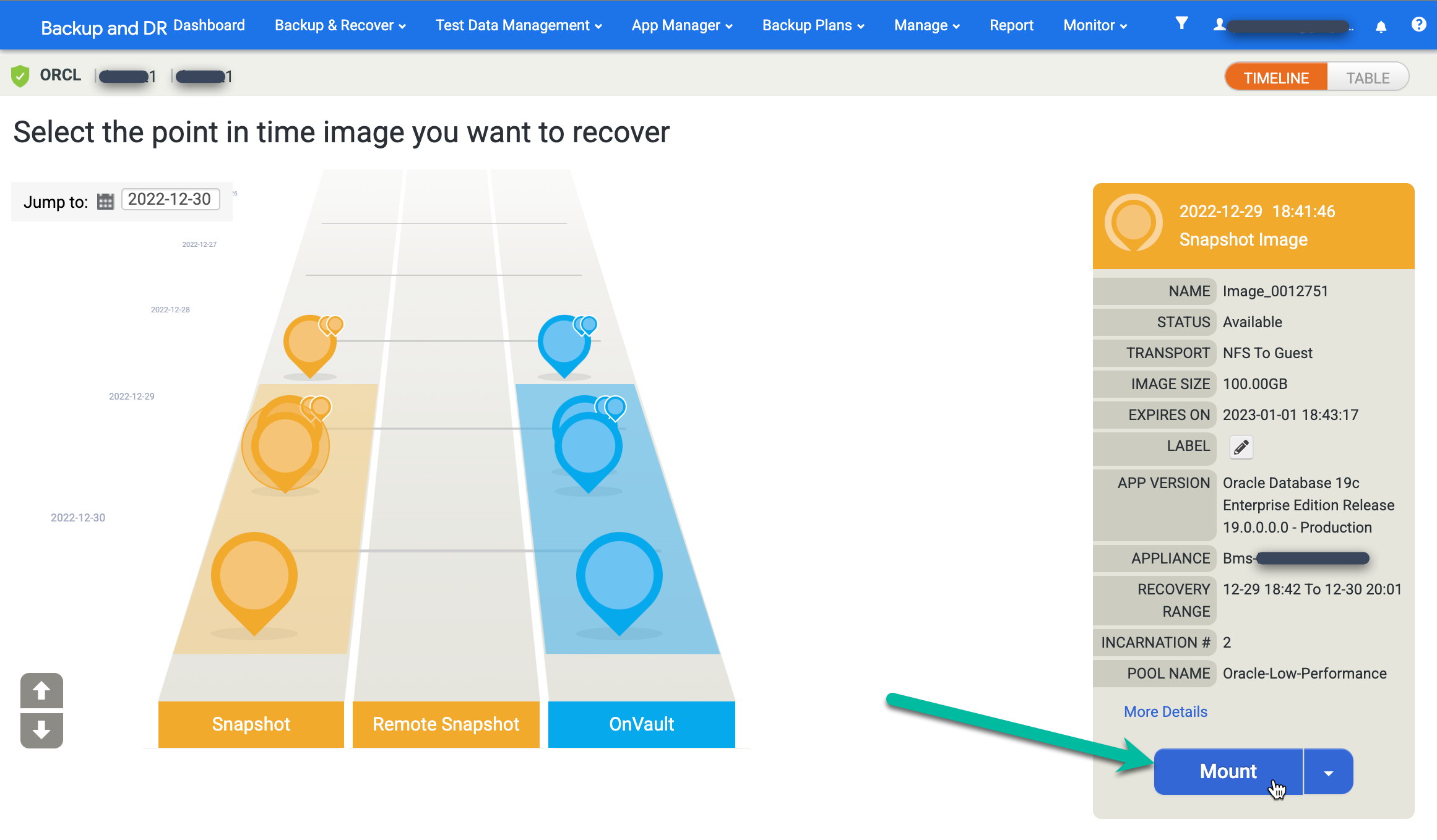
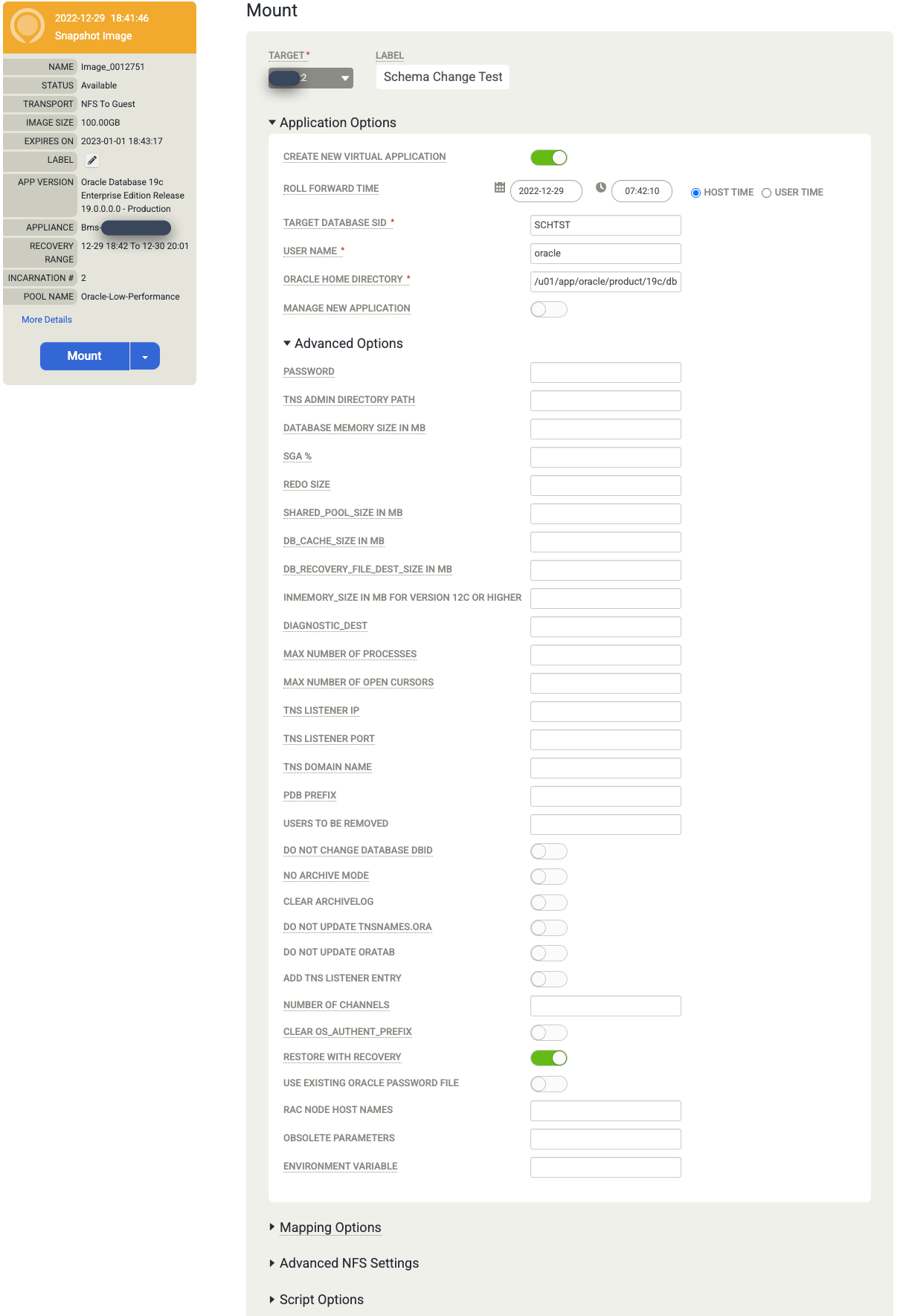
Escolha as Opções de aplicativo do database ativado.
- Selecione Target Host no menu suspenso. Os hosts aparecem nessa lista se você os tiver adicionado anteriormente.
- (Opcional) Digite um rótulo.
- No campo SID do banco de dados de destino, insira o identificador do banco de dados de destino.
- Defina o Nome de usuário como Oracle. Esse nome se torna o nome de usuário do SO para autenticação.
- Digite o Diretório principal da Oracle. Neste exemplo, use
/u01/app/oracle/product/19c/dbhome_1. - Se você configurar os registros do banco de dados para backup, o Tempo de encaminhamento ficará disponível. Clique no seletor de relógio/hora e escolha o ponto de avanço.
- A opção Restaurar com recuperação é ativada por padrão. Essa opção ativa e abre o banco de dados para você.
Quando terminar de inserir as informações, clique em Enviar para iniciar o processo de ativação.
Monitorar o progresso e o sucesso do job
Para monitorar o job em execução, acesse a página Monitorar > Jobs.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
A página mostra o status e o tipo de job.
Quando o job de ativação for concluído, clique em Job Number para ver os detalhes do job:
Para visualizar os processos pmon do SID que você criou, faça login no host de destino e emita o comando
ps -ef |grep pmon. No exemplo de saída a seguir, o banco de dados SCHTEST está operacional e tem um ID de processo de 173953.[root@test2 ~]# ps -ef |grep pmon oracle 1382 1 0 Dec23 ? 00:00:28 asm_pmon_+ASM oracle 56889 1 0 Dec29 ? 00:00:06 ora_pmon_ORCL oracle 173953 1 0 09:51 ? 00:00:00 ora_pmon_SCHTEST root 178934 169484 0 10:07 pts/0 00:00:00 grep --color=auto pmon
Desconectar um database Oracle
Depois de usar o database, é necessário desconectar e excluir o database. Há dois métodos para encontrar um database ativado:
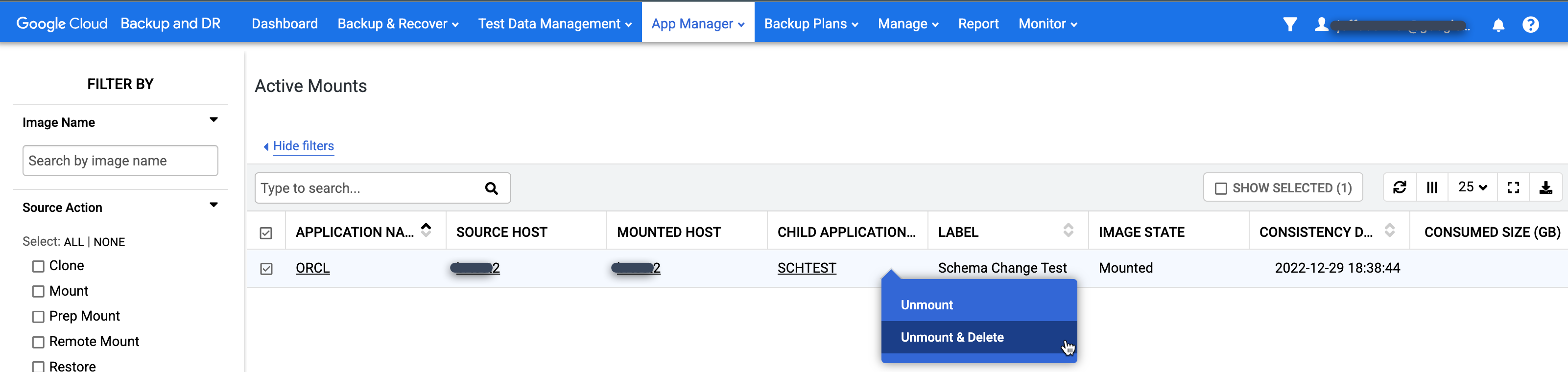
Acesse a página App Manager > Ativações ativas.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#activemounts
Esta página contém uma visualização global de todos os aplicativos ativados (sistemas de arquivos e bancos de dados) atualmente em uso.
Clique com o botão direito do mouse na ativação que você quer limpar e selecione Desativar e Excluir no menu. Essa ação não exclui dados de backup. Ele remove apenas o banco de dados virtual ativado do host de destino e o disco de cache do snapshot que continha as gravações armazenadas para o banco de dados.
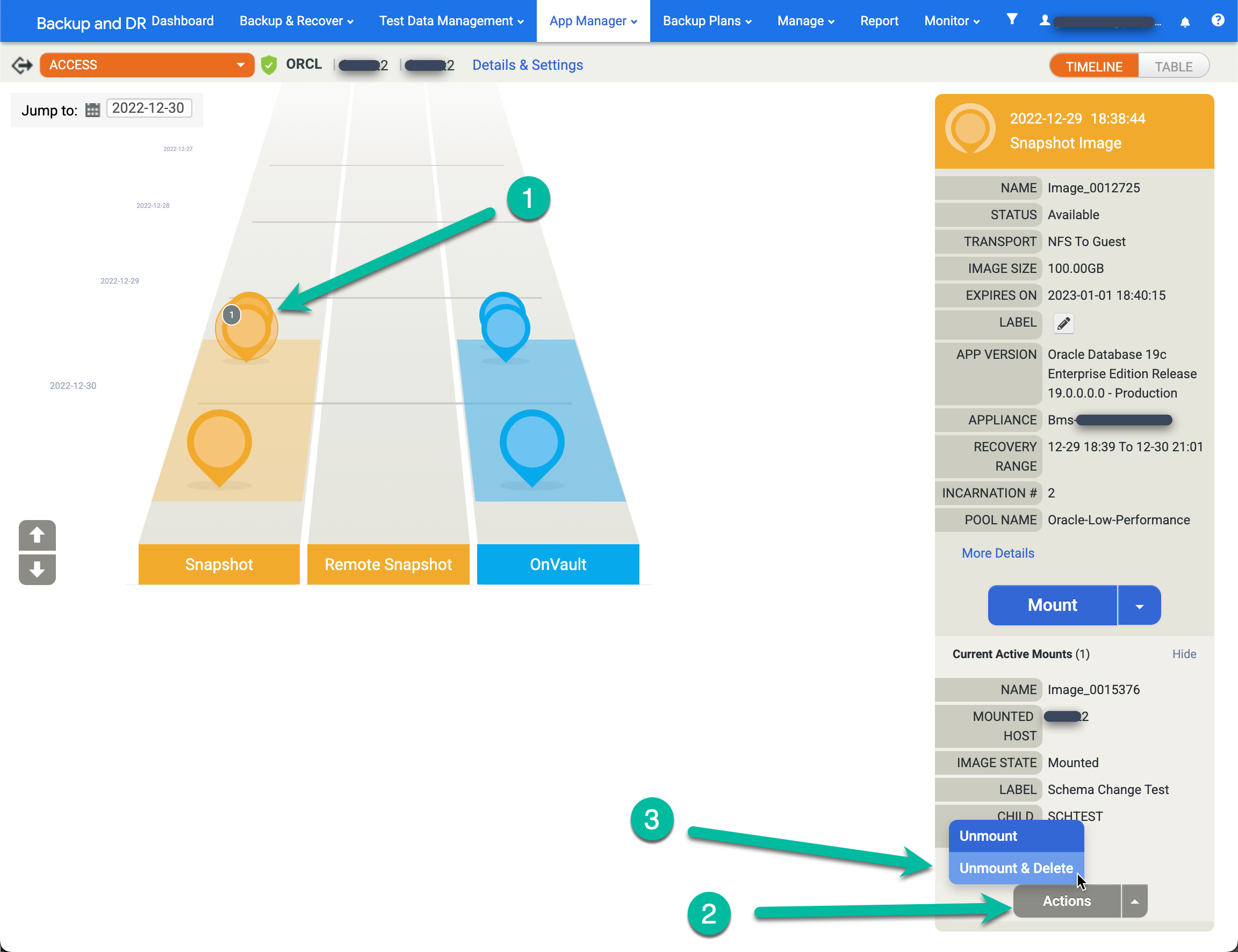
Acesse a página App Manager > Aplicativos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
- Clique com o botão direito do mouse no app de origem (database) e selecione Acessar.
- Na rampa à esquerda, você vê um círculo cinza com um número que indica o número de ativações ativas desse momento. Clique nessa imagem para exibir um novo menu.
- Clique em Ações.
- Clique em Desconectar e excluir.
- Clique em Enviar e confirme essa ação na próxima tela.
Alguns minutos depois, o sistema remove o banco de dados do host de destino, limpa e remove todos os discos. Essa ação libera qualquer espaço em disco no pool de snapshots usado para gravações no disco de refazer em ativações ativas.
É possível monitorar jobs desconectados como qualquer outro job. Acesse o menu Monitorar > Jobs para acompanhar o progresso do job que está sendo desmontado e confirmar se ele foi concluído.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
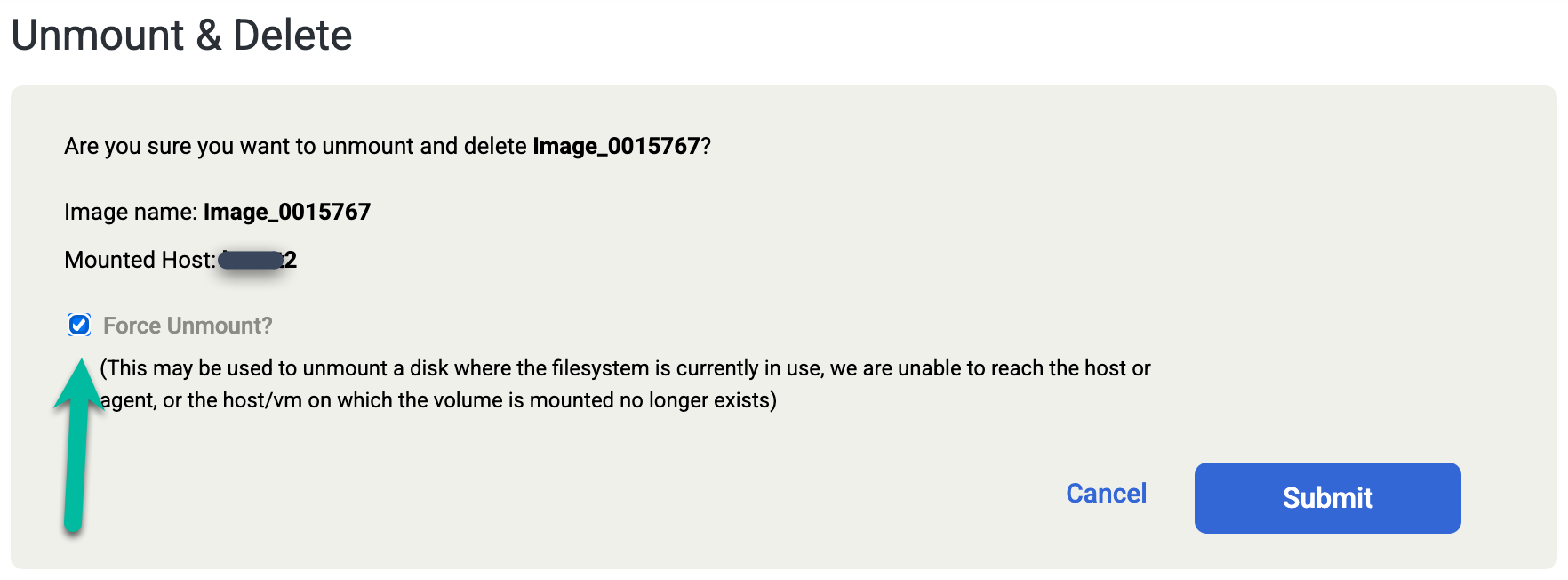
Se você excluir o banco de dados Oracle manualmente ou desligar o banco de dados antes de executar o job Desativar e excluir, execute novamente o job Desativar e excluir e selecione a opção Forçar desativação na tela de confirmação. Esta ação força a remoção do disco de preparo do host de destino e exclui o disco do pool de snapshots.
Restaurações
Use restaurações para recuperar bancos de dados de produção quando ocorre um problema ou corrompimento e é necessário copiar todos os arquivos do banco de dados para um host local de uma cópia de backup. Normalmente, uma restauração é executada após um evento de tipo de desastre ou em cópias de testes de não produção. Nesse caso, os clientes normalmente precisam esperar que você copie os arquivos anteriores de volta para o host de origem antes de reiniciar os bancos de dados. No entanto, o Google Cloud Backup e DR também é compatível com um recurso de restauração (copiar arquivos e iniciar o database) e um recurso de ativação e migração, em que você ativa o database (o tempo de acesso é rápido) e é possível copiar arquivos de dados para a máquina local enquanto o database está ativado e acessível. O recurso de ativação e migração é útil para cenários de baixo objetivo de tempo de recuperação (RTO, na sigla em inglês).
Ativar e migrar
A recuperação com base em migração e ativação tem duas fases:
- Fase 1: a fase de ativação de restauração fornece acesso instantâneo ao database a partir da cópia ativada.
- Fase 2: a fase de migração de restauração migra o banco de dados para o local de armazenamento de produção enquanto ele está on-line.
Ativação de restauração: fase 1
Essa fase fornece acesso instantâneo ao banco de dados a partir de uma imagem selecionada apresentada pelo appliance de backup/recuperação.
- Uma cópia da imagem de backup selecionada é mapeada para o servidor de database de destino e apresentada à camada do sistema de arquivos ASM ou arquivo com base no formato de imagem de backup do database de origem.
- Use a API RMAN para realizar as seguintes tarefas:
- Restaure o arquivo de controle e o arquivo de registro de refazer para o arquivo de controle local especificado e refazer a localização do arquivo (grupo de discos ASM ou sistema de arquivos).
- Alterne o banco de dados para a cópia da imagem apresentada pelo appliance de backup/recuperação.
- Avançar todos os registros de arquivo disponíveis para o ponto de recuperação especificado.
- Abra o database no modo de leitura e gravação.
- O banco de dados é executado a partir da cópia mapeada da imagem de backup apresentada pelo appliance de backup/recuperação.
- O arquivo de controle e o arquivo de registro de refazer do database são colocados no local de armazenamento de produção local selecionado (ASM diskgroup ou sistema de arquivos) no destino.
- Após uma operação de ativação de restauração bem-sucedida, o banco de dados fica disponível para operações de produção. É possível usar a API de movimentação de arquivos de dados on-line da Oracle para mover os dados de volta para o local de armazenamento de produção (grupo de discos ASM ou sistema de arquivos) enquanto o banco de dados e o aplicativo estão em execução.
Ativação de migração: fase 2
Move o arquivo de dados do database on-line para o armazenamento de produção:
- A migração de dados é executada em segundo plano. Use a API de movimentação de arquivos de dados on-line da Oracle para migrar os dados.
- Mova os arquivos de dados da cópia apresentada pelo Backup e DR da imagem de backup para o armazenamento de database de destino selecionado (ASM diskgroup ou sistema de arquivos).
- Quando o job de migração é concluído, o sistema remove e desmapeia a cópia de imagem de backup e de apresentação de backup apresentada pelo DR (grupo de arquivos ASM ou sistema de arquivos) do destino e o database é executado no armazenamento de produção.
Para mais informações sobre a recuperação de ativação e migração, consulte: Ativar e migrar uma imagem de backup da Oracle para recuperação instantânea para qualquer destino.
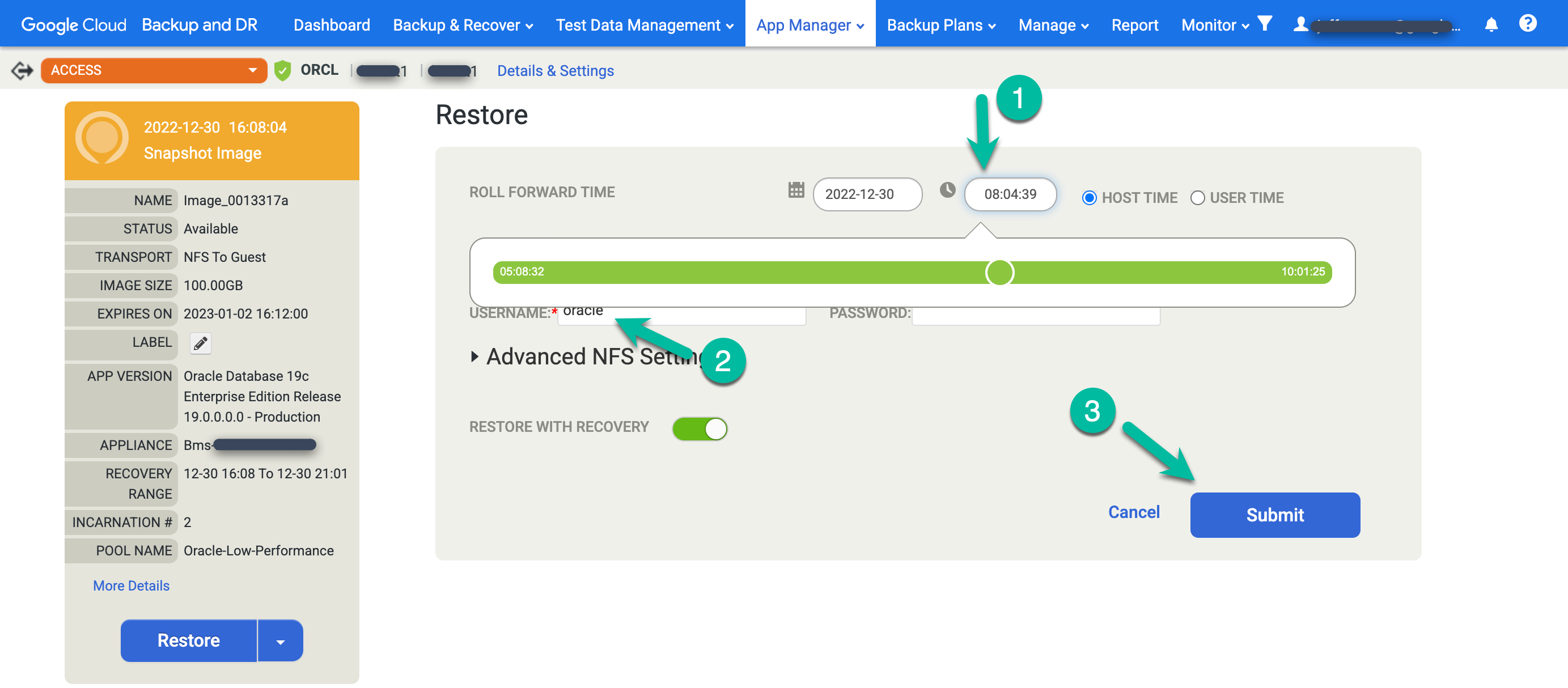
Restaurar um database Oracle
No console de gerenciamento de backup e DR, acesse a página Backup e recuperação > Recuperar.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#recover/selectapp
Na lista Application, clique com o botão direito do mouse no nome do database que você quer restaurar e selecione Next:
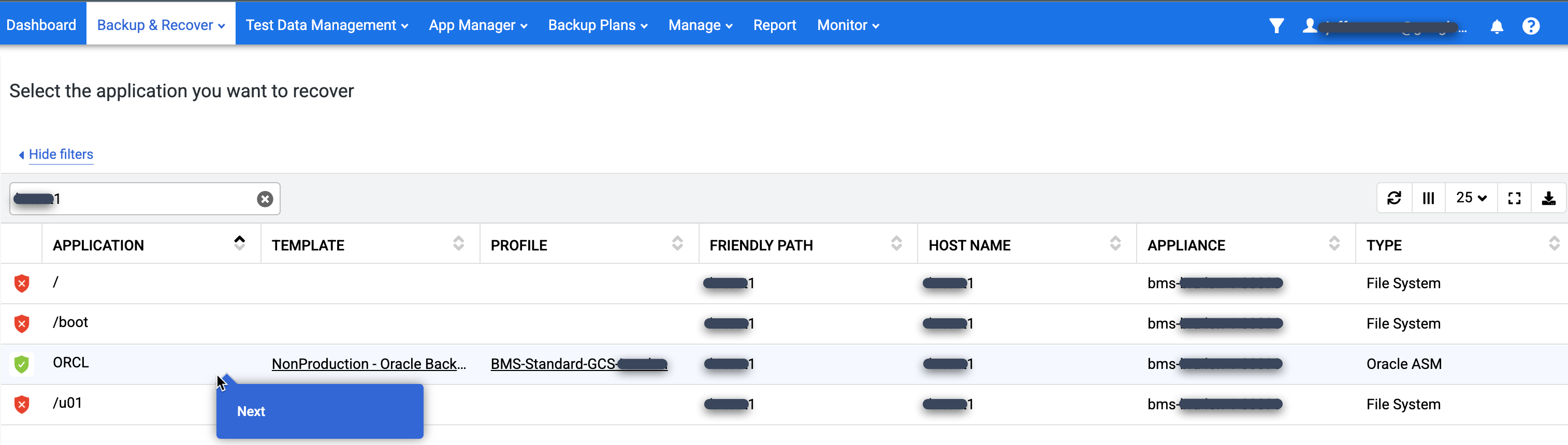
A visualização da rampa do cronograma será exibida, mostrando todas as imagens disponíveis no momento. Também é possível rolar para trás caso seja necessário visualizar as imagens de retenção de longo prazo que não aparecem na rampa. Por padrão, o sistema sempre seleciona a imagem mais recente.
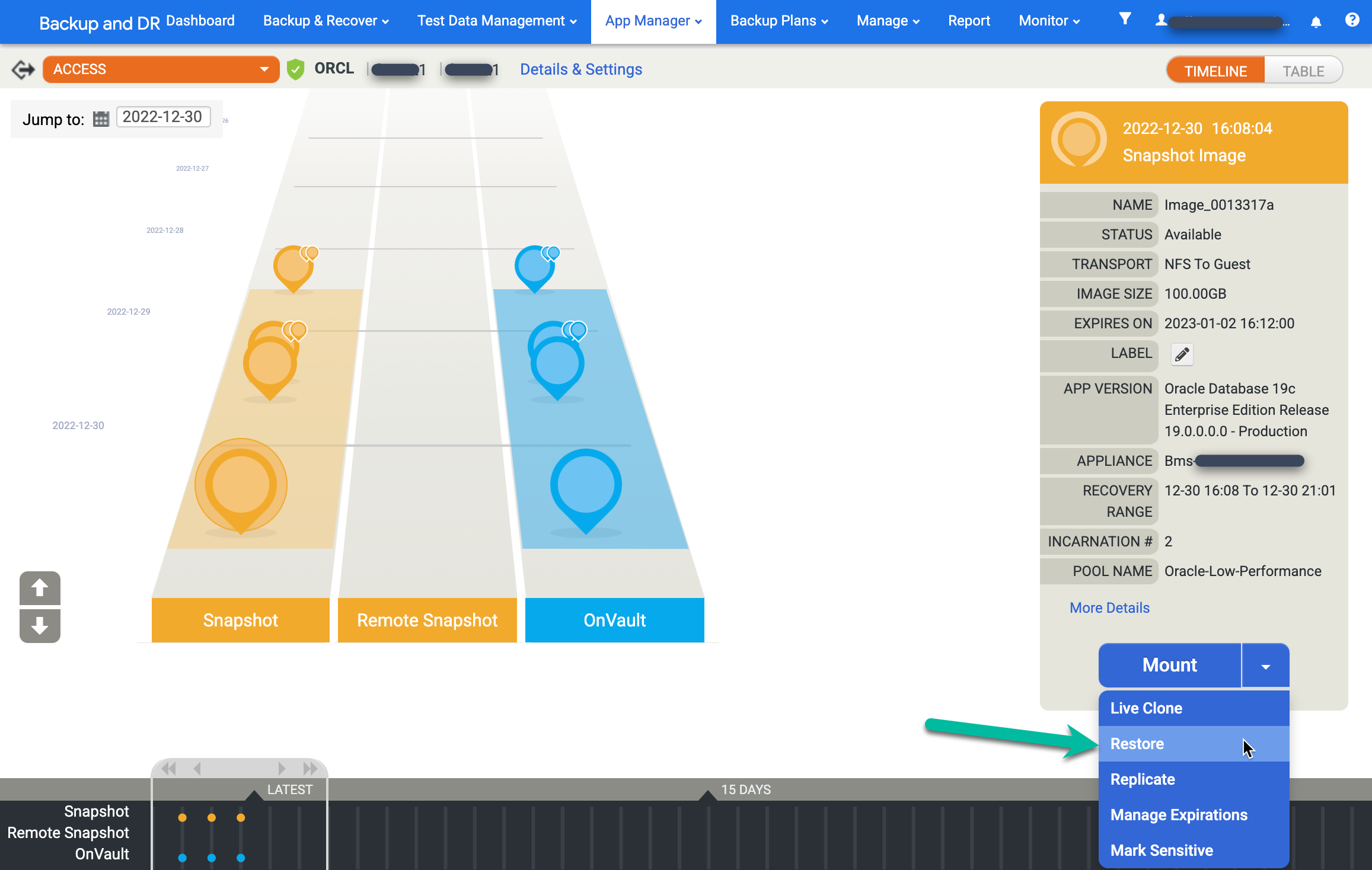
Para restaurar uma imagem, clique no menu Ativar e selecione Restaurar:
Escolha as opções de restauração.
- Selecione o Tempo de avanço. Clique no relógio e escolha o momento desejado.
- Digite o nome de usuário que você planeja usar na Oracle.
- Se o sistema usa autenticação de database, insira uma senha.
Para iniciar o job, clique em Enviar.
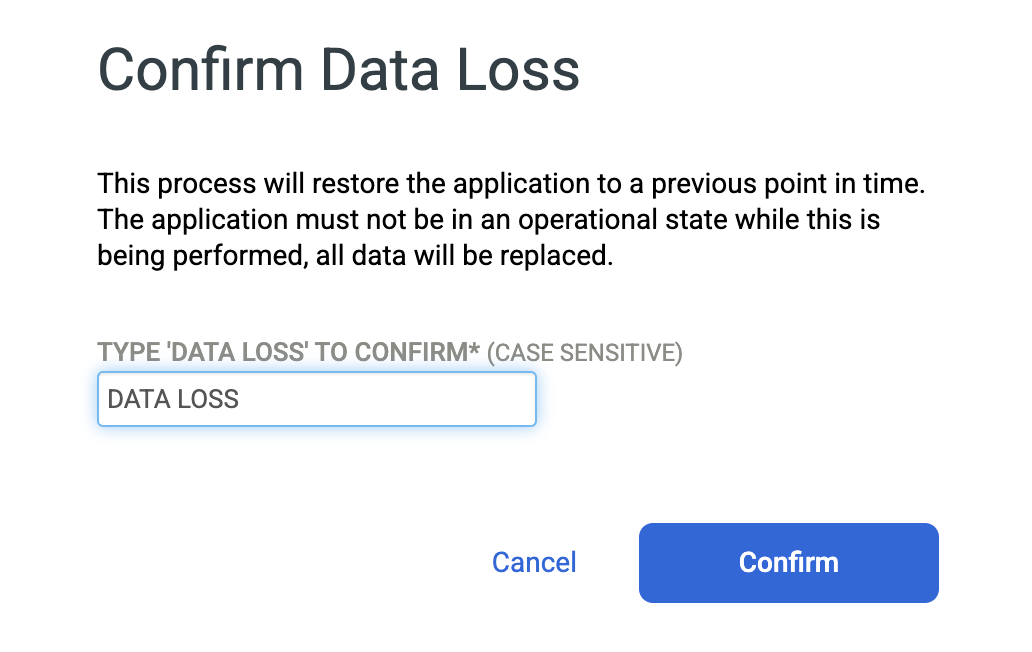
Digite DATA LOSS para confirmar que você quer substituir o banco de dados de origem e clique em Confirmar.
Monitorar o progresso e o sucesso do job
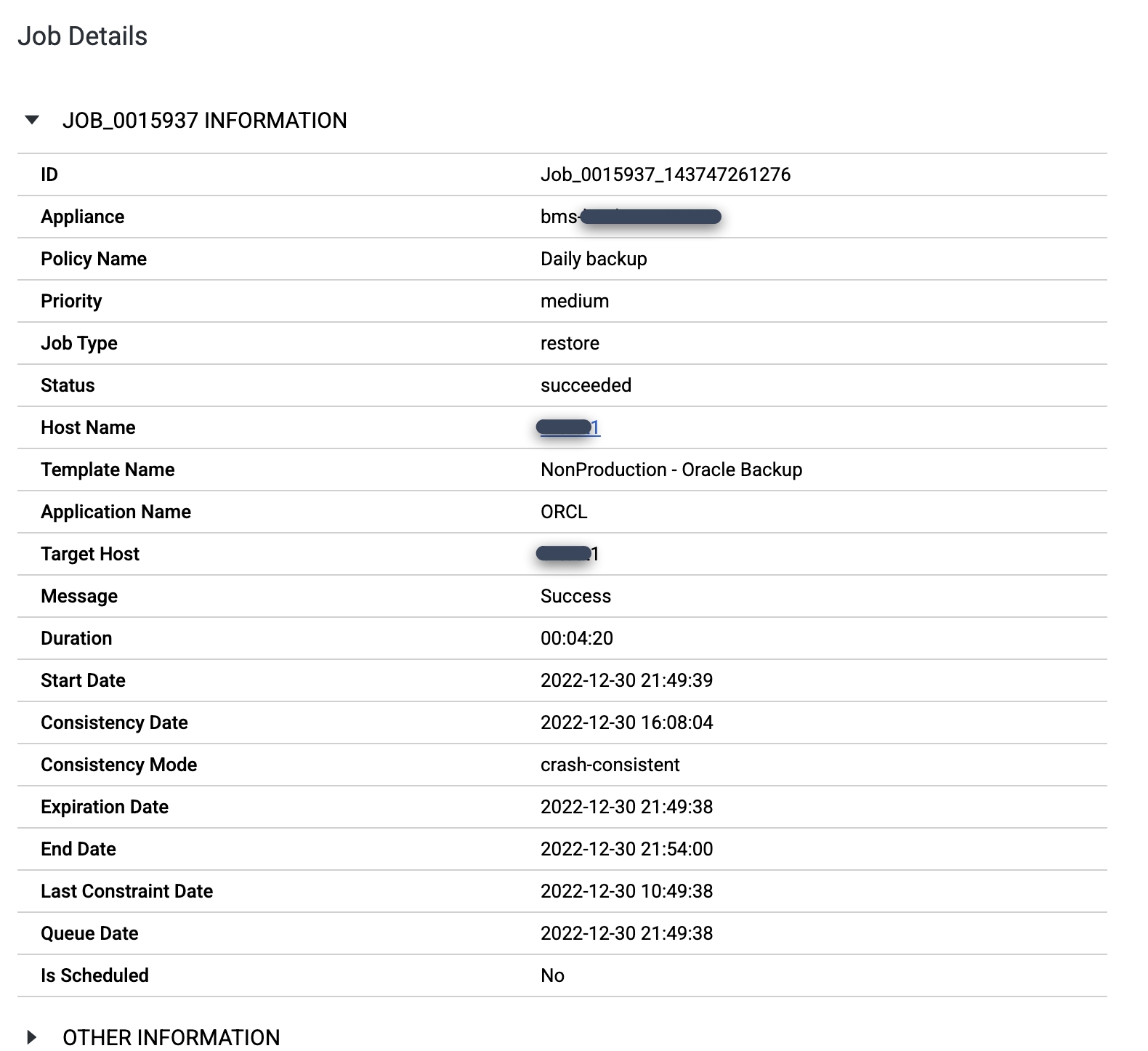
Para monitorar o job, acesse a página Monitorar > Jobs.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#jobs
Quando o job for concluído, clique no Número do job para revisar os detalhes e metadados do job.
Proteger o database restaurado
Quando o job de restauração de banco de dados é concluído, o sistema não faz backup do banco de dados automaticamente após a restauração. Em outras palavras, quando você restaura um banco de dados que tinha um plano de backup, esse plano não é ativado por padrão.
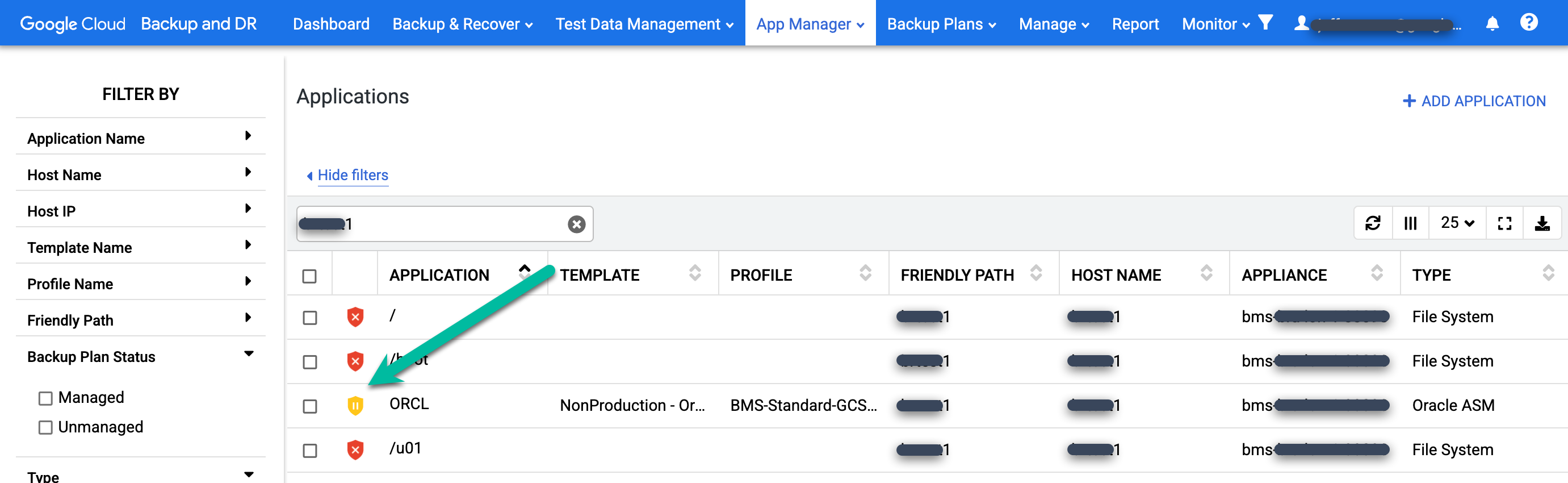
Para verificar se o plano de backup não está em execução, acesse a página App Manager > Aplicativos.
https://bmc-PROJECT_NUMBER-GENERATED_ID-dot-REGION.backupdr.googleusercontent.com/#applications
Encontre o database restaurado na lista. O ícone de proteção muda de verde para amarelo, o que indica que o sistema não está programado para executar jobs de backup para o banco de dados.
Para proteger o database restaurado, procure na coluna Aplicativo o database que você quer proteger. Clique com o botão direito do mouse no nome do banco de dados e selecione Gerenciar plano de backup.
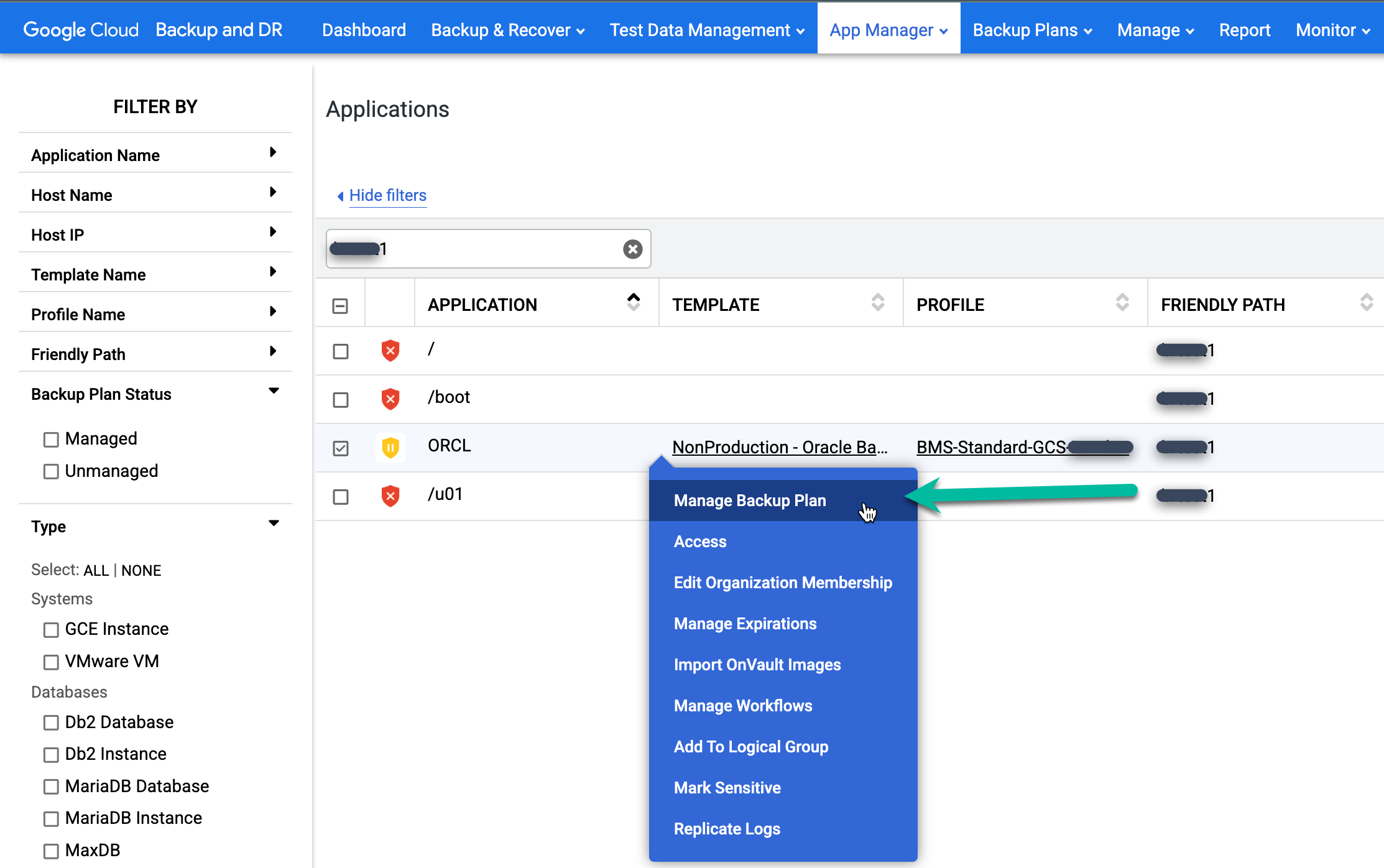
Reativar o job de backup programado para o database restaurado.
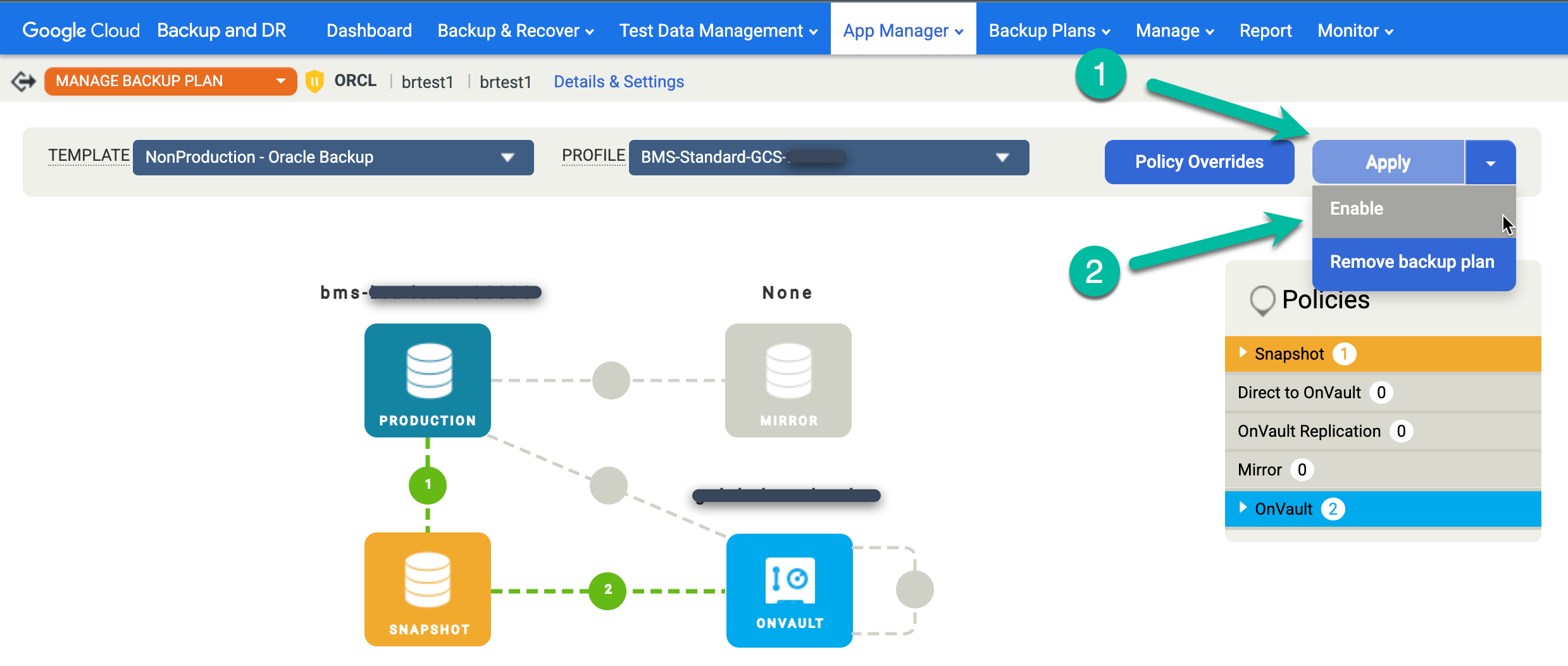
- Clique no menu Aplicar e selecione Ativar.
Confirme as configurações avançadas da Oracle e clique em Ativar plano de backup.
Solução de problemas e otimização
Esta seção fornece algumas dicas úteis para ajudar você a solucionar problemas de backups da Oracle, otimizar o sistema e considerar ajustes para ambientes RAC e Data Guard.
Solução de problemas de backup da Oracle
As configurações do Oracle contêm uma série de dependências para garantir que a tarefa de backup seja bem-sucedida. As etapas a seguir fornecem várias sugestões para configurar instâncias, listeners e databases da Oracle para garantir o sucesso.
Para verificar se o listener do Oracle para o serviço e a instância que você quer proteger está configurado e em execução, emita o comando
lsnrctl status:[oracle@test2 lib]$ lsnrctl status LSNRCTL for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:43:37 Copyright (c) 1991, 2021, Oracle. All rights reserved. Connecting to (ADDRESS=(PROTOCOL=tcp)(HOST=)(PORT=1521)) STATUS of the LISTENER ------------------------ Alias LISTENER Version TNSLSNR for Linux: Version 19.0.0.0.0 - Production Start Date 23-DEC-2022 20:34:17 Uptime 5 days 11 hr. 9 min. 20 sec Trace Level off Security ON: Local OS Authentication SNMP OFF Listener Parameter File /u01/app/19c/grid/network/admin/listener.ora Listener Log File /u01/app/oracle/diag/tnslsnr/test2/listener/alert/log.xml Listening Endpoints Summary... (DESCRIPTION=(ADDRESS=(PROTOCOL=tcp)(HOST=test2.localdomain)(PORT=1521))) (DESCRIPTION=(ADDRESS=(PROTOCOL=ipc)(KEY=EXTPROC1521))) Services Summary... Service "+ASM" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "+ASM_DATADG" has 1 instance(s). Instance "+ASM", status READY, has 1 handler(s) for this service... Service "ORCL" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "ORCLXDB" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "f085620225d644e1e053166610ac1c27" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... Service "orclpdb" has 1 instance(s). Instance "ORCL", status READY, has 1 handler(s) for this service... The command completed successfully
Verifique se você configurou o database Oracle no modo ARCHIVELOG. Se o banco de dados for executado em um modo diferente, você poderá ver jobs com falha com a mensagem Error Code 5556 da seguinte maneira:
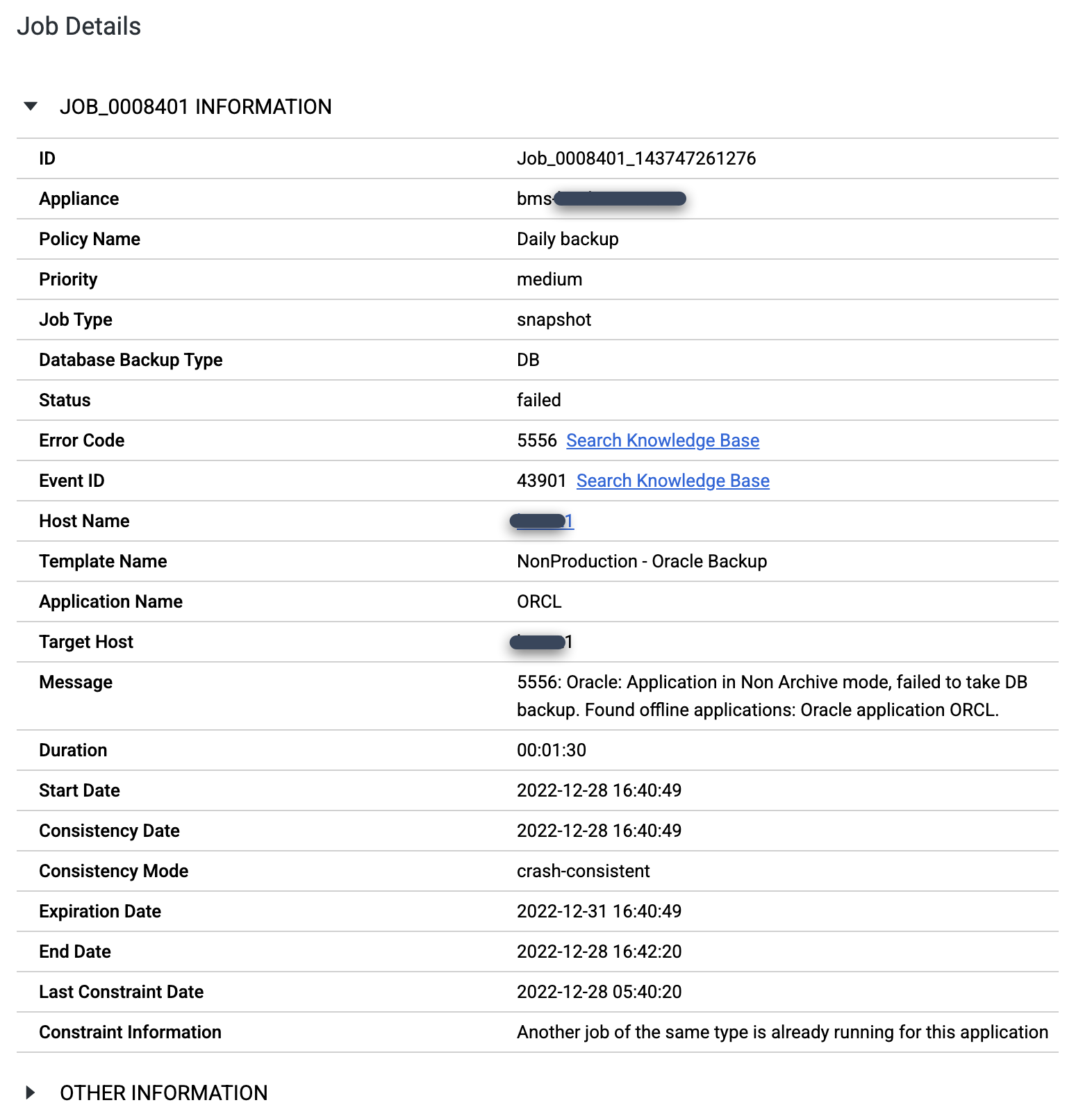
export ORACLE_HOME=ORACLE_HOME_PATH export ORACLE_SID=DATABASE_INSTANCE_NAME export PATH=$ORACLE_HOME/bin:$PATH sqlplus / as sysdba SQL> set tab off SQL> archive log list; Database log mode Archive Mode Automatic archival Enabled Archive destination +FRA Oldest online log sequence 569 Next log sequence to archive 570 Current log sequence 570
Ative o rastreamento de alterações de bloqueio no database Oracle. Embora isso não seja obrigatório para o funcionamento da solução, ativar o rastreamento de alteração de bloco evita a necessidade de executar uma quantidade significativa de trabalho de pós-processamento para calcular blocos alterados e ajuda a reduzir o tempo de backup do job:
SQL> select status,filename from v$block_change_tracking; STATUS FILENAME ---------- ------------------------------------------------------------------ ENABLED +DATADG/ORCL/CHANGETRACKING/ctf.276.1124639617
Verifique se o database usa o
spfile:sqlplus / as sysdba SQL> show parameter spfile NAME TYPE VALUE ------------------ ----------- ------------ spfile string +DATA/ctdb/spfilectdb.ora
Ative Direct NFS (dnfs) para os hosts de database Oracle. Embora não seja obrigatório, se você precisar do método mais rápido de backup e restauração dos databases Oracle, o dnfs é a melhor opção. Para melhorar ainda mais a capacidade, altere o disco de preparo por host e ative o dnfs para a Oracle.
Configure tnsnames para resolução de hosts de database Oracle. Se você não incluir essa configuração, os comandos RMAN geralmente vão falhar. Veja a seguir uma amostra da saída:
[oracle@test2 lib]$ tnsping ORCL TNS Ping Utility for Linux: Version 19.0.0.0.0 - Production on 29-DEC-2022 07:55:18 Copyright (c) 1997, 2021, Oracle. All rights reserved. Used parameter files: Used TNSNAMES adapter to resolve the alias Attempting to contact (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST = test2.localdomain)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = ORCL))) OK (0 msec)
O campo
SERVICE_NAMEé importante para configurações de RAC. O nome do serviço representa o alias usado para anunciar o sistema para recursos externos que se comunicam com o cluster. Nas opções Detalhes e configurações do database protegido, use a Configuração avançada para o nome do serviço Oracle. Digite o nome do serviço específico que você quer usar nos nós que executam o job de backup.O database Oracle usa o nome do serviço apenas para autenticação do database. O database não usa o nome do serviço para autenticação do SO. Por exemplo, o nome do banco de dados pode ser CLU1_S e o nome da instância pode ser CLU1_S.
Se o nome do serviço Oracle não estiver listado, crie uma entrada de nome de serviço nos servidores no arquivo tnsnames.ora localizado em
$ORACLE_HOME/network/adminou em$GRID_HOME/network/admin, adicionando a seguinte entrada:CLU1_S = (DESCRIPTION = (ADDRESS = (PROTOCOL = TCP)(HOST =
)(PORT = 1521)) (CONNECT_DATA = (SERVER = DEDICATED) (SERVICE_NAME = CLU1_S) ) ) Se o arquivo tnsnames.ora estiver em um local não padrão, forneça o caminho absoluto para o arquivo na página Detalhes e configurações do aplicativo descrita em Configurar detalhes do aplicativo e para databases Oracle.
Verifique se você configurou a entrada do nome do serviço para o banco de dados corretamente. Faça login no Oracle Linux e configure o ambiente da Oracle:
TNS_ADMIN=TNSNAMES.ORA_FILE_LOCATION tnsping CLU1_S
Revise a conta de usuário do banco de dados para garantir uma conexão bem-sucedida com o aplicativo de backup e DR:
sqlplus act_rman_user/act_rman_user@act_svc_dbstd as sysdba
Na página Detalhes e configurações do aplicativo descrita em Detalhes e configurações do aplicativo para databases Oracle, insira o nome do serviço que você criou (CLU1_S) no campo Nome do serviço Oracle:
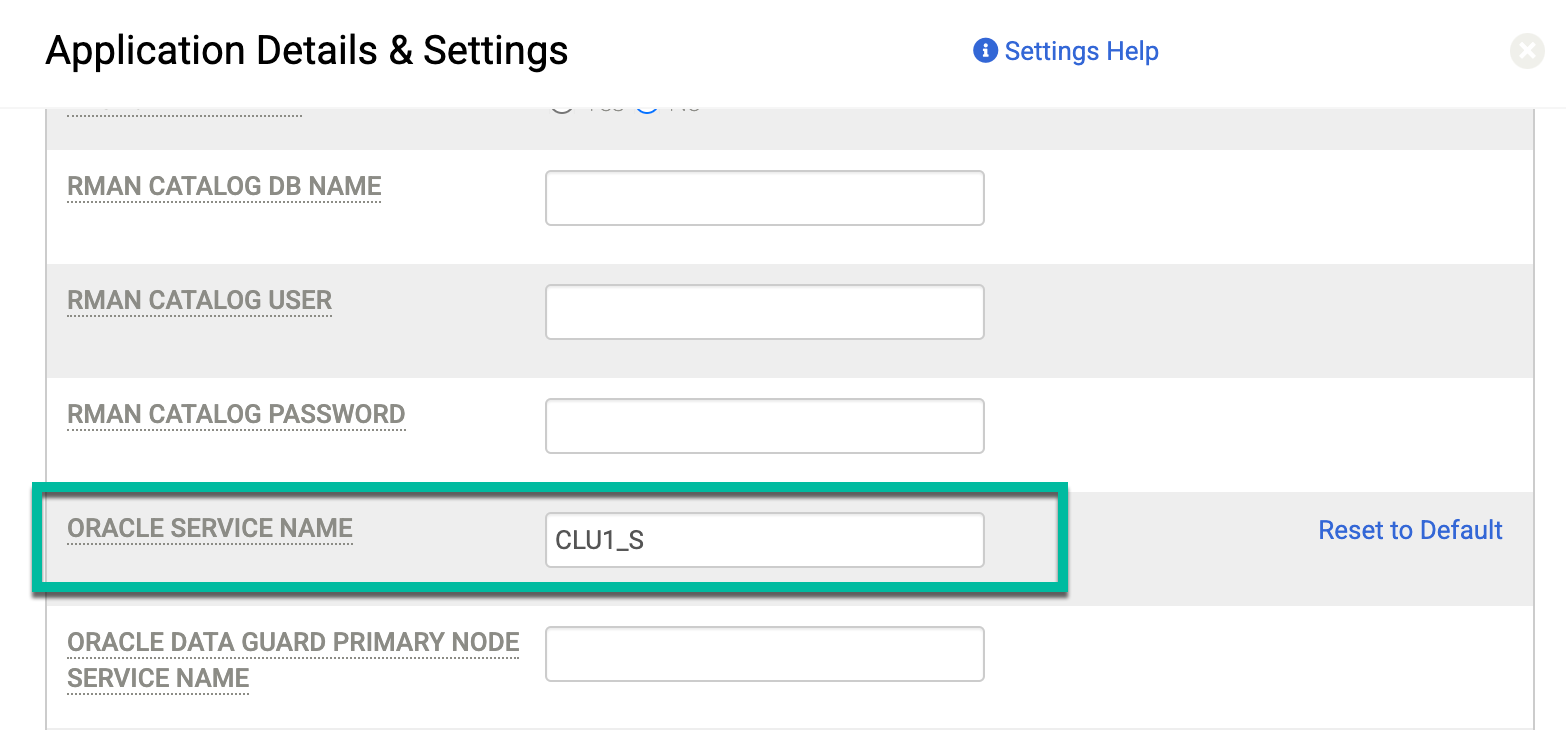
O Código de erro 870 informa que "Não há suporte para backups do ASM com ASM em discos de preparo NFS." Se você receber esse erro, significa que não tem a configuração correta definida em Detalhes e configurações para a instância que quer proteger. Nessa configuração incorreta, o host usa NFS para o disco de preparo, mas o database de origem é executado no ASM.

Para corrigir esse problema, defina o campo Converter formato ASM para formato de sistema de arquivos como Sim. Depois de alterar essa configuração, execute novamente o job de backup.
O Código de erro 15 informa ao sistema de backup e DR "Não foi possível se conectar ao host de backup". Se você receber esse erro, ele indica um dos três problemas:
- O firewall entre o appliance de backup/recuperação e o host em que o agente foi instalado não permite a porta TCP 5106 (a porta de escuta do agente).
- Você não instalou o agente.
- O agente não está em execução.
Para corrigir esse problema, reconfigure as configurações do firewall conforme necessário e verifique se o agente está funcionando. Depois de corrigir a causa subjacente, execute o comando
service udsagent status. O exemplo de saída a seguir mostra que o serviço de agente de backup e DR está sendo executado corretamente:[root@test2 ~]# service udsagent status Redirecting to /bin/systemctl status udsagent.service udsagent.service - Google Cloud Backup and DR service Loaded: loaded (/usr/lib/systemd/system/udsagent.service; enabled; vendor preset: disabled) Active: active (running) since Wed 2022-12-28 05:05:45 UTC; 2 days ago Process: 46753 ExecStop=/act/initscripts/udsagent.init stop (code=exited, status=0/SUCCESS) Process: 46770 ExecStart=/act/initscripts/udsagent.init start (code=exited, status=0/SUCCESS) Main PID: 46789 (udsagent) Tasks: 8 (limit: 48851) Memory: 74.0M CGroup: /system.slice/udsagent.service ├─46789 /opt/act/bin/udsagent start └─60570 /opt/act/bin/udsagent start Dec 30 05:11:30 test2 su[150713]: pam_unix(su:session): session closed for user oracle Dec 30 05:11:30 test2 su[150778]: (to oracle) root on none
As mensagens de registro dos seus backups podem ajudar você a diagnosticar problemas. É possível acessar os registros no host de origem em que os jobs de backup são executados. Para backups de banco de dados Oracle, há dois arquivos de registros principais disponíveis no diretório
/var/act/log:- UDSAgent.log:Google Cloud registro do agente de backup e DR que registra solicitações de API, execução de estatísticas de job e outros detalhes.
- SID_rman.log: registro do RMAN do Oracle que registra todos os comandos do RMAN.
Considerações adicionais sobre a Oracle
Ao implementar o Backup e DR para databases Oracle, esteja ciente das considerações a seguir ao implantar o Data Guard e o RAC.
Considerações sobre o Data Guard
É possível fazer backup dos nós principal e de espera do Data Guard. No entanto, se você optar por proteger os databases apenas nos nós em espera, precisará usar a autenticação de database Oracle em vez da autenticação do SO ao fazer backup do database.
Considerações sobre a RAC
A solução de backup e DR não é compatível com backup simultâneo de vários nós em um database RAC se o disco de preparo estiver configurado para o modo NFS. Se o sistema exigir backup simultâneo de vários nós RAC, use Block (iSCSI) como modo de disco de preparo e defina-o para cada host.
Para um banco de dados Oracle RAC usando ASM, coloque o arquivo de controle de snapshot nos discos compartilhados. Para verificar essa configuração, conecte-se ao RMAN e execute o comando
show all:
rman target / RMAN> show all
CONFIGURE RETENTION POLICY TO REDUNDANCY 1; # default CONFIGURE BACKUP OPTIMIZATION OFF; # default CONFIGURE DEFAULT DEVICE TYPE TO DISK; # default CONFIGURE CONTROLFILE AUTOBACKUP OFF; # default CONFIGURE CONTROLFILE AUTOBACKUP FORMAT FOR DEVICE TYPE DISK TO '%F'; # default CONFIGURE DEVICE TYPE DISK PARALLELISM 1 BACKUP TYPE TO BACKUPSET; # default CONFIGURE SNAPSHOT CONTROLFILE NAME TO '/mnt/ctdb/snapcf_ctdb.f';
Em um ambiente RAC, é preciso mapear o arquivo de controle de snapshots para um grupo de discos ASM compartilhado. Para atribuir o arquivo ao grupo de discos do ASM, use o comando
Configure Snapshot Controlfile Name:
CONFIGURE SNAPSHOT CONTROLFILE NAME TO '+/snap_ .f';
Recomendações
Dependendo dos requisitos, talvez seja necessário tomar decisões em relação a determinados recursos que têm efeito na solução geral. Algumas decisões podem afetar o preço, o que, por sua vez, pode afetar o desempenho. Por exemplo, escolher discos permanentes padrão (pd-standard) ou discos permanentes de desempenho (pd-ssd) para os pools de snapshots do dispositivo de backup/recuperação.
Nesta seção, compartilhamos nossas escolhas recomendadas para ajudar você a garantir o desempenho ideal para a capacidade de backup do database Oracle.
Selecionar o tipo de máquina ideal e o tipo de disco permanente
Ao usar um dispositivo de backup/recuperação com um aplicativo, como um sistema de arquivos ou um banco de dados, é possível medir o desempenho com base na rapidez com que os dados da instância do host são transferidos entre as instâncias do Compute Engine.
- As velocidades de dispositivo do disco permanente do Compute Engine são baseadas em três fatores: o tipo de máquina, a quantidade total de memória anexada à instância e a contagem de vCPU da instância.
- O número de vCPUs em uma instância determina a velocidade de rede alocada para uma instância do Compute Engine. A velocidade varia de 1 Gbps para uma vCPU compartilhada até 16 Gbps para 8 ou mais vCPUs.
- Combinando esses limites,o Google Cloud Backup e DR usa um e2-standard-16 como tipo de máquina de tamanho padrão para um dispositivo de backup/recuperação. A partir desse ponto, você tem três opções para a alocação de disco:
Escolha |
Disco do pool |
Máximo de gravações sustentadas |
Máximo de leituras sustentadas |
Mínimo |
10 GB |
N/A |
N/A |
Padrão |
4.096 GB |
400 MiB/s |
1200 MiB/s |
SSD |
4.096 GB |
1000 MiB/s |
1200 MiB/s |
As instâncias do Compute Engine usam até 60% da rede alocada para E/S nos discos permanentes anexados e reservam 40% para outros usos. Para mais detalhes, consulte Outros fatores que afetam o desempenho.
Recomendação: a seleção de um tipo de máquina e2-standard-16 e um mínimo de 4096 GB de DP-SSD oferece o melhor desempenho para dispositivos de backup/recuperação. Como segunda opção, você pode selecionar um tipo de máquina n2-standard-16 para o dispositivo de backup/recuperação. Essa opção oferece mais benefícios de desempenho no intervalo de 10 a 20%, mas tem outros custos. Se isso corresponder ao seu caso de uso, entre em contato com o Cloud Customer Care para fazer essa mudança.
Otimizar seus snapshots
Para aumentar a produtividade de um único dispositivo de backup/recuperação, é possível executar jobs de instantâneo simultâneos de várias fontes. A velocidade de cada job diminui. No entanto, com jobs suficientes, é possível atingir o limite de gravação sustentada para os volumes Persistent Disk no pool de snapshots.
Quando você usa o iSCSI no disco de preparo, pode fazer backup de uma única instância grande em um dispositivo de backup/recuperação com uma velocidade de gravação sustentada de aproximadamente 300-330 MB/s. Em nossos testes, isso foi válido para tudo, de 2 TB a 80 TB em um snapshot, supondo que você configurou o host de origem e o dispositivo de backup/recuperação em um tamanho ideal, e eles estão na mesma região e zona.
Escolher o disco de preparo correto
Se você precisar de desempenho e capacidade significativos, o NFS direto pode adicionar benefícios significativos em comparação com iSCSI como a opção de disco de preparo a ser usado para backups de database Oracle. O NFS direto consolida o número de conexões TCP, o que melhora a escalonabilidade e o desempenho da rede.
Ao ativar o NFS direto para um banco de dados Oracle, configure uma CPU de origem suficiente (por exemplo, 8 vCPUs e 8 canais do RMAN) e estabeleça um link de 10 GB entre a extensão regional da Solução Bare Metal e Google Cloud. Assim, é possível fazer backup de um único banco de dados Oracle com um aumento na taxa de transferência entre 700 e 900 MB/s. As velocidades de restauração do RMAN também se beneficiam do NFS direto, em que os níveis de capacidade alcançam o intervalo de 850 MB/s ou mais.
Equilibrar o custo e a capacidade
Também é importante entender que todos os dados de backup são armazenados em formato compactado no pool de snapshots do dispositivo de backup/recuperação, o que é feito para reduzir custos. A sobrecarga de desempenho para esse benefício da compactação é marginal. No entanto, para dados criptografados (TDE) ou conjuntos de dados muito compactados, provavelmente haverá algum impacto mensurável, embora marginal, nos resultados da capacidade.
Entender os fatores que afetam o desempenho da rede e dos servidores de backup
Os itens a seguir afetam a E/S de rede entre a Oracle na Solução Bare Metal e os servidores de backup em Google Cloud:
Armazenamento em Flash
Assim como no Google Cloud disco permanente, as matrizes de armazenamento em Flash que oferecem armazenamento para sistemas da Solução Bare Metal aumentam os recursos de E/S com base na quantidade de armazenamento atribuída ao host. Quanto mais armazenamento você alocar, melhor será a E/S. Para resultados consistentes, recomendamos provisionar pelo menos 8 TB de armazenamento em Flash.
Latência de rede
Google Cloud Os jobs de backup e DR são sensíveis à latência de rede entre os hosts da Solução Bare Metal e o appliance de backup/recuperação em Google Cloud. Pequenos aumentos de latência podem criar grandes mudanças nos tempos de backup e restauração. Diferentes zonas do Compute Engine oferecem diferentes latências de rede aos hosts da Solução Bare Metal. É recomendável testar cada zona para ver o posicionamento ideal do dispositivo de backup/recuperação.
Número de processadores usados
Os servidores da Solução Bare Metal têm vários tamanhos. Recomendamos que você dimensione seus canais RMAN para se adequar às CPUs disponíveis, com uma velocidade maior em sistemas maiores.
Cloud Interconnect
A interconexão híbrida entre a Solução Bare Metal e Google Cloud está disponível em vários tamanhos, como 5 Gbps, 10 Gbps e 2x10 Gbps, com desempenho total da opção dupla de 10 GB. Também é possível configurar um link de interconexão dedicado que será usado exclusivamente para operações de backup e restauração. Essa opção é recomendada para clientes que querem isolar o tráfego de backup do tráfego de banco de dados ou de aplicativos que podem passar pelo mesmo link ou garantir largura de banda total quando as operações de backup e restauração são essenciais para atender ao objetivo de ponto de recuperação (RPO) e ao objetivo de tempo de recuperação (RTO).
A seguir
Aqui estão alguns links e informações adicionais sobre o backup e DR do Google Cloud que podem ser úteis.
- Para mais etapas relacionadas à configuração do Google Cloud Backup e DR, consulte a documentação do produto de backup e DR.
- Para ver demonstrações de instalação do recurso e do produto, consulte a playlist de vídeo de DR e backup do Google Cloud.
- Para ver informações de compatibilidade do Google Cloud Backup e DR, consulte Matriz de suporte: backup e DR. É importante verificar se você está executando versões compatíveis de instâncias de database do Linux e da Oracle.
- Para mais etapas sobre a proteção da Oracle Database, consulte Backup e DR para databases da Oracle e Proteger um database Oracle descoberto.
- Sistemas de arquivos como NFS, CIFS, ext3 e ext4 também podem ser protegidos com o Google Cloud Backup e DR. Para ver as opções disponíveis, consulte Aplicar um plano de backup para proteger um sistema de arquivos.
- Para ativar alertas do Google Cloud Backup e DR, consulte Configurar um alerta baseado em registro e assista ao vídeo Configuração de notificações de alerta do Google Cloud Backup e DR.
- Para abrir um caso de suporte, entre em contato com o Cloud Customer Care.