En esta página, se describe cómo puedes usar la importancia de las características para obtener visibilidad sobre cómo el modelo realiza sus predicciones.
Si deseas obtener más información sobre las explicaciones de IA, consulta Introducción a las explicaciones de IA para AI Platform.
Introducción
Cuando usas un modelo de aprendizaje automático para tomar decisiones empresariales, es importante comprender cómo contribuyeron tus datos de entrenamiento al modelo final y cómo el modelo realizó las predicciones individuales. Esta comprensión te ayuda a garantizar que tu modelo sea justo y preciso.
AutoML Tables proporciona importancia de las características, a veces llamados atribuciones de las características, lo que te permite ver qué características contribuyeron en mayor grado al entrenamiento del modelo (importancia de las características del modelo) y a las predicciones individuales (importancia de las características locales).
Con AutoML Tables se calcula la importancia de las características mediante el método de Shapley con muestreo. Para obtener más información sobre la explicación del modelo, consulta la página acerca de la introducción a las explicaciones de IA.
Importancia de los atributos del modelo
La importancia de los atributos del modelo te ayuda a asegurarte de que el entrenamiento del modelo informado tenga sentido para tus datos y problemas comerciales. Todos los atributos con un valor de importancia de atributo alto deben representar una señal válida de predicción y poder incluirse de manera coherente en tus solicitudes de predicción.
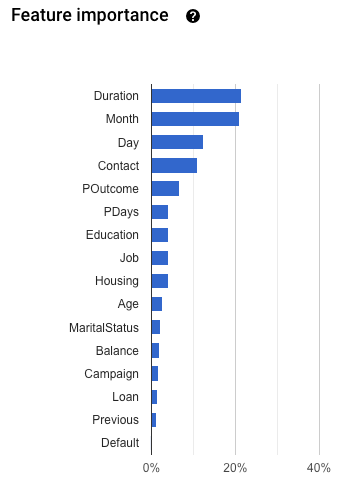
La importancia de las características del modelo se proporciona como un porcentaje para cada característica: cuanto más alto sea el porcentaje, más fuerte será el entrenamiento del modelo.
Obtén la importancia de las características del modelo
Console
Para ver los valores de importancia de los atributos de tu modelo con la consola de Google Cloud, sigue estos pasos:
Ve a la página AutoML Tables en la consola de Google Cloud.
Selecciona la pestaña Modelos en el panel de navegación izquierdo y selecciona el modelo del que deseas obtener las métricas de evaluación.
Abre la pestaña Evaluar (Evaluate).
Desplázate hacia abajo para ver el gráfico Importancia de las características.
REST
Para obtener los valores de importancia de las características de un modelo, usa el método model.get.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea -
model-id: el ID del modelo del que deseas obtener información de la importancia de las características.
Por ejemplo,
TBL543
HTTP method and URL:
GET https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id
Para enviar tu solicitud, elige una de estas opciones:
curl
Ejecuta el siguiente comando:
curl -X GET \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id"
PowerShell
Ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method GET `
-Headers $headers `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id" | Select-Object -Expand Content
{
"name": "projects/292381/locations/us-central1/models/TBL543",
"displayName": "Quickstart_Model",
...
"tablesModelMetadata": {
"targetColumnSpec": {
...
},
"inputFeatureColumnSpecs": [
...
],
"optimizationObjective": "MAXIMIZE_AU_ROC",
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/331",
"columnDisplayName": "Contact",
"featureImportance": 0.093201876
},
{
"columnSpecName": "projects/292381/locations/us-central1/datasets/TBL543/tableSpecs/246/columnSpecs/638",
"columnDisplayName": "Month",
"featureImportance": 0.215029223
},
...
],
"trainBudgetMilliNodeHours": "1000",
"trainCostMilliNodeHours": "1000",
"classificationType": "BINARY",
"predictionSampleRows": [
...
],
"splitPercentageConfig": {
...
}
},
"creationState": "CREATED",
"deployedModelSizeBytes": "1160941568"
}
Java
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Node.js
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Python
La biblioteca cliente de AutoML Tables incluye métodos adicionales de Python que simplifican el uso de la API de AutoML Tables. Estos métodos hacen referencia a conjuntos de datos y modelos por nombre en lugar de ID. El conjunto de datos y los nombres de los modelos deben ser únicos. Para obtener más información, consulta la página de referencia del cliente.
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Importancia local del atributo
La importancia de las características locales te permite ver cómo las funciones individuales de una solicitud de predicción específica afectaron la predicción resultante.
Para llegar a cada valor de importancia de los atributos locales, primero se calcula la puntuación de predicción del modelo de referencia. Los valores del modelo de referencia se calculan a partir de los datos de entrenamiento, y se usa el valor de la mediana para los atributos numéricos y el modo para los atributos categóricos. La predicción que se genera a partir de los valores del modelo de referencia es la puntuación de predicción del modelo de referencia.
Para los modelos de clasificación, la importancia de los atributos locales indica cuánto agregó cada atributo a la probabilidad asignada a la clase con la puntuación más alta o cuánto quitó en comparación con la puntuación de predicción del modelo de referencia. Los valores de puntuación están entre 0.0 y 1.0, por lo que la importancia de los atributos locales para los modelos de clasificación siempre está entre -1.0 y 1.0 (inclusive).
En el caso de los modelos de regresión, la importancia de los atributos locales para una predicción te indica cuánto agregó cada atributo al resultado o cuánto quitó en comparación con la puntuación de predicción del modelo de referencia.
La importancia de las características locales está disponible para las predicciones en línea y por lotes.
Obtén la importancia de las características locales para las predicciones en línea
Console
Si deseas obtener valores de importancia de atributos locales para una predicción en línea con la consola de Google Cloud, sigue los pasos que se indican en Obtén una predicción en línea y asegúrate de marcar la casilla de verificación Generar importancia de los atributos.
REST
Si deseas obtener la importancia de las características locales de una solicitud de predicción en línea, usa el método model.predict y configura el parámetro feature_importance como verdadero.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - model-id: El ID del modelo. Por ejemplo,
TBL543 - valueN: los valores de cada columna, en el orden correcto.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict
Cuerpo JSON de la solicitud:
{
"payload": {
"row": {
"values": [
value1, value2,...
]
}
}
"params": {
"feature_importance": "true"
}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:predict" | Select-Object -Expand Content
"tablesModelColumnInfo": [
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/4704",
"columnDisplayName": "Promo",
"featureImportance": 1626.5464
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/6800",
"columnDisplayName": "Open",
"featureImportance": -7496.5405
},
{
"columnSpecName": "projects/2381/locations/us-central1/datasets/TBL8440/tableSpecs/766336/columnSpecs/9824",
"columnDisplayName": "StateHoliday"
}
],
Cuando una columna tiene un valor de importancia de atributo de 0, no se muestra la importancia de la función para esa columna.
Java
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Node.js
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Python
La biblioteca cliente de AutoML Tables incluye métodos adicionales de Python que simplifican el uso de la API de AutoML Tables. Estos métodos hacen referencia a conjuntos de datos y modelos por nombre en lugar de ID. El conjunto de datos y los nombres de los modelos deben ser únicos. Para obtener más información, consulta la página de referencia del cliente.
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Obtén la importancia de las características locales para las predicciones por lotes
Console
Si quieres obtener valores de importancia de los atributos locales para una predicción por lotes mediante la consola de Google Cloud, sigue los pasos que se indican en Solicita una predicción por lotes y asegúrate de marcar la casilla de verificación Generar importancia de los atributos.
La importancia de las características se muestra mediante el agregado de una columna nueva para cada función, llamada feature_importance.<feature_name>.
REST
Si deseas obtener la importancia de las características locales de una solicitud de predicción por lotes, usa el método model.batchPredict y configura el parámetro feature_importance como verdadero.
En el siguiente ejemplo, se usa BigQuery para los datos de la solicitud y los resultados. Debes usar el mismo parámetro adicional en las solicitudes que usan Cloud Storage.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - model-id: El ID del modelo. Por ejemplo,
TBL543 - dataset-id: Es el ID del conjunto de datos de BigQuery en el que se encuentran los datos de predicción.
-
table-id: el ID de la tabla de BigQuery en la que se encuentran los datos de predicción
AutoML Tables crea una subcarpeta para los resultados de la predicción llamada
prediction-<model_name>-<timestamp>en project-id.dataset-id.table-id.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Cuerpo JSON de la solicitud:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
"params": {"feature_importance": "true"}
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
La importancia de las características se muestra mediante el agregado de una columna nueva para cada función, llamada feature_importance.<feature_name>.
Consideraciones para usar la importancia de los atributos locales:
Los resultados de la importancia de los atributos locales solo están disponibles para los modelos entrenados a partir del 15 de noviembre de 2019.
No se admite la habilitación de la importancia de las características locales en una solicitud de predicción por lotes con más de 1,000,000 filas o 300 columnas.
Cada valor de importancia de los atributos locales muestra solo cuánto afectó el atributo a la predicción de esa fila. Para comprender el comportamiento general del modelo, usa la importancia de las características del modelo.
Los valores de importancia de los atributos locales siempre se relacionan con el valor del modelo de referencia. Asegúrate de referenciar el valor del modelo de referencia cuando evalúes tus resultados de importancia de los atributos locales. El valor del modelo de referencia solo está disponible en la consola de Google Cloud.
Los valores de importancia de los atributos locales dependen en su totalidad del modelo y los datos que se usaron para entrenar el modelo. Solo pueden distinguir los patrones que el modelo encontró en los datos y no pueden detectar ninguna relación fundamental en los datos. Por lo tanto, la presencia de una importancia de los atributos alta para un atributo determinado no demuestra una relación entre ese atributo y el objetivo; solo muestra que el modelo usa el atributo en sus predicciones.
Si una predicción incluye datos que están completamente fuera del rango de los datos de entrenamiento, es posible que la importancia de las características locales no proporcione resultados significativos.
La generación de la importancia de los atributos aumenta el tiempo y los recursos de procesamiento necesarios para tu predicción. Además, tu solicitud usa una cuota diferente a la de las solicitudes de predicción sin la importancia de las características. Obtener más información.
Los valores de importancia de los atributos por sí solos no indican si tu modelo es equitativo, imparcial o de buena calidad. Debes evaluar con cuidado el conjunto de datos de entrenamiento, el procedimiento y las métricas de evaluación, además de la importancia de los atributos.