En esta página se describe cómo puedes proporcionar varias filas de datos a AutoML Tables a la vez y recibir una predicción para cada fila.
Introducción
Luego de crear (entrenar) un modelo, puedes realizar una solicitud asíncrona para un lote de predicciones mediante el método batchPredict. Proporciona datos de entrada al método batchPredict, en formato de tabla.
En cada fila se encuentran los valores de las características que entrenaste al modelo para usar.
El método batchPredict envía esos datos al modelo y muestra predicciones para cada fila de datos.
Los modelos se deben volver a entrenar cada seis meses para que puedan seguir entregando predicciones.
Solicita una predicción por lotes
Para las predicciones por lotes, especifica una fuente de datos y un destino de resultados en una tabla de BigQuery o en un archivo CSV en Cloud Storage. No necesitas usar la misma tecnología para la fuente y el destino. Por ejemplo, podrías usar BigQuery para la fuente de datos y un archivo CSV en Cloud Storage para el destino de los resultados. Sigue los pasos correspondientes de las dos tareas que se indican a continuación según tus requisitos.
La fuente de datos debe contener datos tabulares que incluyan todas las columnas usadas para entrenar el modelo. Puedes incluir columnas que no estaban en los datos de entrenamiento o que estaban en los datos de entrenamiento, pero que no se usaron para el entrenamiento. Estas columnas adicionales se incluyen en el resultado de la predicción, pero no se usan para generar la predicción.
Usa tablas de BigQuery
Los nombres de las columnas y los tipos de datos de tus datos de entrada deben coincidir con los datos que usaste para el entrenamiento. Las columnas pueden estar en un orden diferente al de los datos de entrenamiento.
Requisitos de la tabla de BigQuery
- Las tablas de fuentes de datos de BigQuery no deben superar los 100 GB.
- Debes usar un conjunto de datos de BigQuery multirregional en las ubicaciones
USoEU. - Si la tabla está en un proyecto diferente, debes proporcionar la función
BigQuery Data Editora la cuenta de servicio de AutoML Tables en ese proyecto. Más información.
Solicita la predicción por lotes
Console
Ve a la página AutoML Tables en la consola de Google Cloud.
Selecciona Modelos y abre el modelo que deseas usar.
Selecciona la pestaña Probar y usar.
Haz clic en Predicción por lotes.
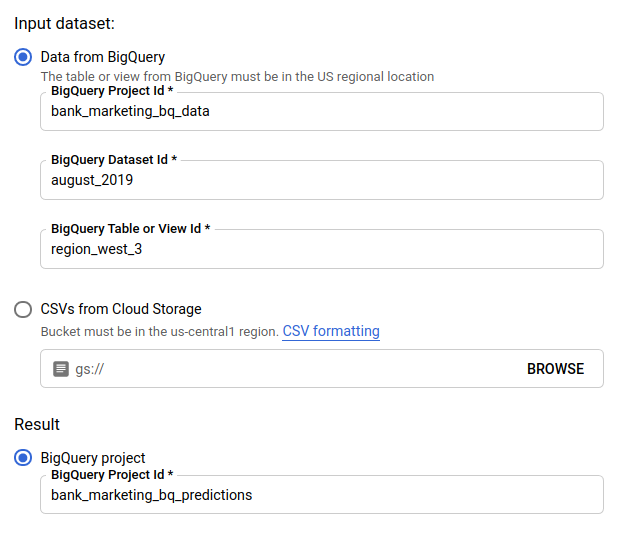
En Conjunto de datos de entrada (Input dataset), selecciona Tabla de BigQuery y proporciona los ID de tabla, proyecto y conjunto de datos para tu fuente de datos.
En Resultado (Result), selecciona Proyecto de BigQuery (BigQuery project) y proporciona el ID del proyecto para el destino de los resultados.
Si deseas ver cómo cada atributo influyó en la predicción, selecciona Generar importancia de características.
La generación de la importancia de los atributos aumenta el tiempo y los recursos de procesamiento necesarios para tu predicción. La importancia de las características locales no está disponible con un destino de resultados de Cloud Storage.
Haz clic en Enviar predicción por lotes para solicitar la predicción por lotes.
REST
Solicita predicciones por lotes con el método models.batchPredict.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - model-id: El ID del modelo. Por ejemplo,
TBL543 - dataset-id: Es el ID del conjunto de datos de BigQuery en el que se encuentran los datos de predicción.
-
table-id: el ID de la tabla de BigQuery en la que se encuentran los datos de predicción
AutoML Tables crea una subcarpeta para los resultados de la predicción llamada
prediction-<model_name>-<timestamp>en project-id.dataset-id.table-id.
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Cuerpo JSON de la solicitud:
{
"inputConfig": {
"bigquerySource": {
"inputUri": "bq://project-id.dataset-id.table-id"
},
},
"outputConfig": {
"bigqueryDestination": {
"outputUri": "bq://project-id"
},
},
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Para obtener la importancia de las características locales, agrega el parámetro feature_importance a los datos de la solicitud. Para obtener más información, consulta Importancia local del atributo.
Java
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Node.js
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Python
La biblioteca cliente de AutoML Tables incluye métodos adicionales de Python que simplifican el uso de la API de AutoML Tables. Estos métodos hacen referencia a conjuntos de datos y modelos por nombre en lugar de ID. El conjunto de datos y los nombres de los modelos deben ser únicos. Para obtener más información, consulta la página de referencia del cliente.
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Usa archivos CSV en Cloud Storage
Los nombres de las columnas y los tipos de datos de tus datos de entrada deben coincidir con los datos que usaste para el entrenamiento. Las columnas pueden estar en un orden diferente al de los datos de entrenamiento.
Requisitos del archivo CSV
- La primera línea de la fuente de datos debe contener el nombre de las columnas.
Cada archivo de fuente de datos no debe superar los 10 GB.
Puedes incluir varios archivos, hasta un máximo de 100 GB.
El bucket de Cloud Storage debe cumplir con los requisitos del bucket .
Si el bucket de Cloud Storage está en un proyecto diferente del que usa AutoML Tables, debes proporcionar la función
Storage Object Creatora la cuenta de servicio de AutoML Tables en ese proyecto. Más información.
Console
Ve a la página AutoML Tables en la consola de Google Cloud.
Selecciona Modelos y abre el modelo que deseas usar.
Selecciona la pestaña Probar y usar.
Haz clic en Predicción por lotes.
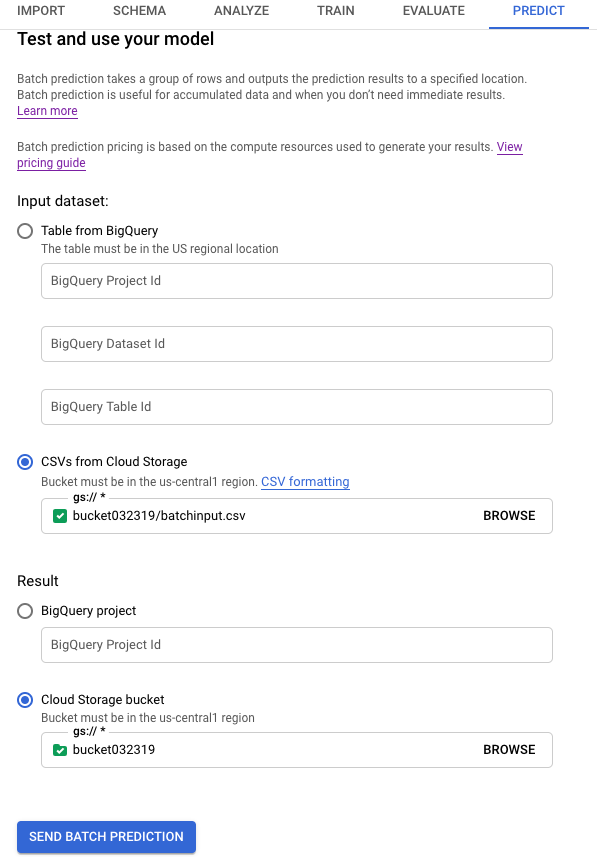
En Conjunto de datos de entrada (Input dataset), selecciona CSV de Cloud Storage (CSVs from Cloud Storage) y proporciona el URI del bucket para tu fuente de datos.
En Resultado (Result), selecciona Bucket de Cloud Storage (Cloud Storage bucket) y proporciona el URI del bucket para tu bucket de destino.
Si deseas ver cómo cada atributo influyó en la predicción, selecciona Generar importancia de características.
La generación de la importancia de los atributos aumenta el tiempo y los recursos de procesamiento necesarios para tu predicción. La importancia de las características locales no está disponible con un destino de resultados de Cloud Storage.
Haz clic en Enviar predicción por lotes para solicitar la predicción por lotes.
REST
Solicita predicciones por lotes con el método models.batchPredict.
Antes de usar cualquiera de los datos de solicitud a continuación, realiza los siguientes reemplazos:
-
endpoint:
automl.googleapis.compara la ubicación global yeu-automl.googleapis.compara la región de la UE. - project-id: Es el ID de tu proyecto de Google Cloud.
- location: la ubicación del recurso:
us-central1para la global oeupara la Unión Europea - model-id: El ID del modelo. Por ejemplo,
TBL543 - input-bucket-name: Es el nombre del bucket de Cloud Storage en el que se encuentran los datos de predicción.
- input-directory-name: Es el nombre del directorio de Cloud Storage en el que se encuentran los datos de predicción.
- object-name: Es el nombre del objeto de Cloud Storage en el que se encuentran los datos de predicción
- output-bucket-name: Es el nombre del bucket de Cloud Storage para los resultados de la predicción.
-
output-directory-name: Es el nombre del directorio de Cloud Storage para los resultados de la predicción.
AutoML Tables crea una subcarpeta para los resultados de la predicción llamada
prediction-<model_name>-<timestamp>engs://output-bucket-name/output-directory-name. Debes tener permisos de escritura para esta ruta de acceso
HTTP method and URL:
POST https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict
Cuerpo JSON de la solicitud:
{
"inputConfig": {
"gcsSource": {
"inputUris": [
"gs://input-bucket-name/input-directory-name/object-name.csv"
]
},
},
"outputConfig": {
"gcsDestination": {
"outputUriPrefix": "gs://output-bucket-name/output-directory-name"
},
},
}
Para enviar tu solicitud, elige una de estas opciones:
curl
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
curl -X POST \
-H "Authorization: Bearer $(gcloud auth print-access-token)" \
-H "x-goog-user-project: project-id" \
-H "Content-Type: application/json; charset=utf-8" \
-d @request.json \
"https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict"
PowerShell
Guarda el cuerpo de la solicitud en un archivo llamado request.json y ejecuta el siguiente comando:
$cred = gcloud auth print-access-token
$headers = @{ "Authorization" = "Bearer $cred"; "x-goog-user-project" = "project-id" }
Invoke-WebRequest `
-Method POST `
-Headers $headers `
-ContentType: "application/json; charset=utf-8" `
-InFile request.json `
-Uri "https://endpoint/v1beta1/projects/project-id/locations/location/models/model-id:batchPredict" | Select-Object -Expand Content
Para obtener la importancia de las características locales, agrega el parámetro feature_importance a los datos de la solicitud. Para obtener más información, consulta Importancia local del atributo.
Java
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Node.js
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Python
La biblioteca cliente de AutoML Tables incluye métodos adicionales de Python que simplifican el uso de la API de AutoML Tables. Estos métodos hacen referencia a conjuntos de datos y modelos por nombre en lugar de ID. El conjunto de datos y los nombres de los modelos deben ser únicos. Para obtener más información, consulta la página de referencia del cliente.
Si tus recursos se encuentran en la región de la UE, debes establecer el extremo de manera explícita. Obtener más información.
Recupera tus resultados
Recupera resultados de predicciones en BigQuery
Si especificaste BigQuery como tu destino de salida, los resultados de tu solicitud de predicción por lotes se mostrarán como un nuevo conjunto de datos en el proyecto de BigQuery que especificaste. El conjunto de datos de BigQuery es el nombre de tu modelo precedido de “prediction_” y con la marca de tiempo de inicio del trabajo de predicción al final. Puedes encontrar el nombre del conjunto de datos de BigQuery en Predicciones recientes, en la página Predicción por lotes de la pestaña Probar y usar de tu modelo.
El conjunto de datos de BigQuery contiene dos tablas: predictions y errors. La tabla errors tiene una fila para cada fila de tu solicitud de predicción en la que AutoML Tables no pudo mostrar una predicción (por ejemplo, si una característica que no admite valores nulos es nula). La tabla predictions contiene una fila para cada predicción que se muestra.
En la tabla predictions, AutoML Tables muestra tus datos de predicción y crea una columna nueva para los resultados de la predicción mediante la anteposición de “predicted_” al nombre de la columna de destino. La columna de resultados de la predicción contiene una estructura de BigQuery anidada que contiene los resultados de la predicción.
Para recuperar los resultados de la predicción, puedes realizar una consulta en la consola de BigQuery. El formato de la consulta depende del tipo de modelo.
Clasificación binaria:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2 FROM <bq-dataset-name>.predictions
“value_1” y “value_2” son marcadores de lugar; puedes reemplazarlos por valores objetivo o un valor equivalente.
Clasificación de clases múltiples:
SELECT predicted_<target-column-name>[OFFSET(0)].tables AS value_1, predicted_<target-column-name>[OFFSET(1)].tables AS value_2, predicted_<target-column-name>[OFFSET(2)].tables AS value_3, ... predicted_<target-column-name>[OFFSET(4)].tables AS value_5 FROM <bq-dataset-name>.predictions
“value_1”, “value_2”, etc., son marcadores de lugar; puedes reemplazarlos por valores objetivo o un valor equivalente.
Regresión:
SELECT predicted_<target-column-name>[OFFSET(0)].tables.value, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.start, predicted_<target-column-name>[OFFSET(0)].tables.prediction_interval.end FROM <bq-dataset-name>.predictions
Recupera resultados en Cloud Storage
Si especificaste Cloud Storage como tu destino de salida, los resultados de su solicitud de predicción por lotes se mostrarán como archivos CSV en una nueva carpeta del bucket que especificaste. El nombre de la carpeta es el nombre de tu modelo, precedido de “prediction_” y con la marca de tiempo de inicio del trabajo de predicción al final. Puedes encontrar el nombre de la carpeta de Cloud Storage en Predicciones recientes, en la parte inferior de la página Predicción por lotes de la pestaña Probar y usar de tu modelo.
La carpeta de Cloud Storage contiene dos tipos de archivos: archivos con errores y archivos de predicción. Si los resultados son grandes, se crean archivos adicionales.
Los archivos con errores se denominan errors_1.csv, errors_2.csv, y así sucesivamente. Contienen una fila de encabezado y una fila para cada fila en tu solicitud de predicción en la que AutoML Tables no pudo mostrar una predicción.
Los archivos de predicción se denominan tables_1.csv, tables_2.csv, y así sucesivamente. Contienen una fila de encabezado con los nombres de las columnas y una fila para cada predicción que se muestra.
En los archivos de predicción, AutoML Tables muestra tus datos de predicción y crea una o más columnas nuevas para los resultados de la predicción, según el tipo de modelo:
Clasificación:
Para cada valor potencial de tu columna de destino, se agrega una columna llamada <target-column-name>_<value>_score a los resultados. Esta columna contiene la puntuación o estimación de confianza de ese valor.
Regresión:
El valor previsto para esa fila se muestra en una columna llamada predicted_<target-column-name>. No se muestra el intervalo de predicción para la salida de CSV.
La importancia de las características locales no está disponible para los resultados en Cloud Storage.
Interpreta los resultados
La forma de interpretar los resultados depende del problema empresarial que resuelvas y de la distribución de los datos.
Interpreta los resultados para los modelos de clasificación
Los resultados de la predicción de los modelos de clasificación (binarios y de varias clases) muestran una puntuación de probabilidad para cada valor potencial de la columna objetivo. Debes determinar cómo quieres usar las puntuaciones. Por ejemplo, para obtener una clasificación binaria a partir de las puntuaciones proporcionadas, debes identificar un valor de umbral. Si hay dos clases, “A” y “B”, debes clasificar el ejemplo como “A” si la puntuación de “A” es mayor que el umbral elegido, y “B” en el caso opuesto. En el caso de los conjuntos de datos desequilibrados, el umbral podría aproximarse al 100% o al 0%.
Puedes usar el gráfico de curva de recuperación y precisión, el gráfico de curva de operador del receptor y otras estadísticas relevantes por etiqueta en la página Evaluar de tu modelo en la consola de Google Cloud para ver cómo cambiar el umbral cambia tus métricas de evaluación. Esto puede ayudarte a elegir la mejor manera de usar los valores de puntuación para interpretar tus resultados de predicción.
Interpreta los resultados de los modelos de regresión
En los modelos de regresión, se muestra un valor esperado, y para muchos problemas, puedes usar ese valor directamente. También puedes usar el intervalo de predicción, si se muestra y si un rango tiene sentido para tu problema empresarial.
Interpreta los resultados de la importancia de las características locales
Para obtener información acerca de cómo interpretar los resultados de la importancia de las características locales, consulta Importancia de las características locales.
¿Qué sigue?
- Obtén más información sobre la importancia de las características locales.
- Obtén más información sobre las operaciones de larga duración.