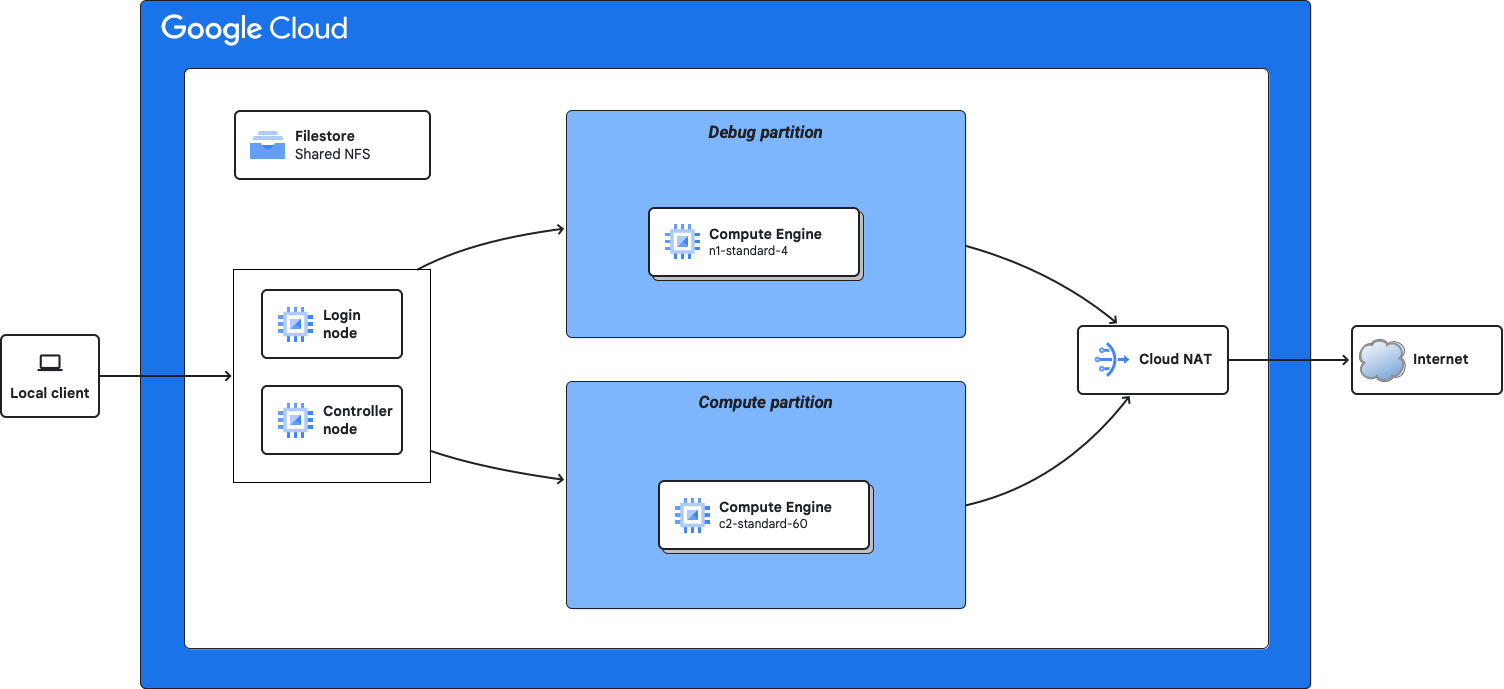
Deploy an HPC cluster with Slurm
To follow step-by-step guidance for this task directly in the Google Cloud console, click Guide me:
Before you begin
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
- Enable the Compute Engine API.
- Enable the Filestore API.
- Enable the Cloud Storage API.
- Enable the Service Usage API.
- Enable the Secret Manager API.
Costs
The cost of running this tutorial varies by section such as setting up the tutorial or running jobs. You can calculate the cost by using the pricing calculator.
Tutorial only costs
To estimate the cost for setting up this tutorial, use the following specifications:
- Filestore Basic HDD (standard) capacity per region: 1024 GB
- Standard persistent disk: 50 GB
pd-standardfor the Slurm login node. - Performance (SSD) persistent disks: 50 GB
pd-ssdfor the Slurm controller. - 1 N2 VM instance:
n2-standard-4 - 1 C2 VM instance:
c2-standard-4
To estimate the cost for running a job on the cluster, use the following specifications:
- 3 N2 VM instances:
n2-standard-2. These are created when thesrun -N 3 hostnamecommand is run and the cluster autoscales. Each of these VMs will have 50 GB ofpd-standarddisk attached. These VMs are deleted automatically after one minute of inactivity.
- 3 N2 VM instances:
Costs for submitting additional jobs
The following resources are not used as a part of this tutorial but because Slurm can autoscale compute nodes, the following resources might be created if you submit additional jobs to the compute or debug partitions:
Jobs submitted to the default debug partition:
- 4 N2 VM instances:
n2-standard-2. Each of these VMs will have 50 GB ofpd-standarddisk attached.
- 4 N2 VM instances:
Jobs submitted to the compute partition:
- 20 C2 VM instances:
c2-standard-60. Each of these VMs will have 50 GB ofpd-standarddisk attached.
- 20 C2 VM instances:
Launch Cloud Shell
In the Google Cloud console, activate Cloud Shell.
At the bottom of the Google Cloud console, a Cloud Shell session starts and displays a command-line prompt. Cloud Shell is a shell environment with the Google Cloud CLI already installed and with values already set for your current project. It can take a few seconds for the session to initialize.
Ensure that the default Compute Engine service account is enabled
Cloud HPC Toolkit requires that the default Compute Engine service account
is enabled in your project and that the roles/editor IAM role is enabled on the
service account. This allows the Slurm controller to perform
actions such as auto-scaling.
From Cloud Shell, run the following commands to ensure these settings are enabled:
Enable the default Compute Engine service account.
gcloud iam service-accounts enable \ --project=PROJECT_ID \ PROJECT_NUMBER-compute@developer.gserviceaccount.comGrant the
roles/editorIAM role to the service account.gcloud projects add-iam-policy-binding PROJECT_ID \ --member=serviceAccount:PROJECT_NUMBER-compute@developer.gserviceaccount.com \ --role=roles/editor
PROJECT_ID: your project IDPROJECT_NUMBER: the automatically generated unique identifier for your projectFor more information, see Identifying projects.
Clone the Cloud HPC Toolkit GitHub repository
Clone the GitHub repository:
git clone https://github.com/GoogleCloudPlatform/hpc-toolkit.git
Go to the main working directory:
cd hpc-toolkit/
Build the Cloud HPC Toolkit binary
To build the Cloud HPC Toolkit binary from source, from Cloud Shell run the following command:
make
To verify the build, from Cloud Shell run the following command:
./ghpc --version
The output shows you the version of the Cloud HPC Toolkit that you are using.
Create the HPC deployment folder
An HPC blueprint is a YAML file that defines the HPC environment. The ghpc command, that is built in previous step, uses the HPC blueprint to create a deployment folder. The deployment folder can then be used to deploy the environment.
This tutorial uses the hpc-slurm.yaml example found in the
Cloud HPC Toolkit GitHub repository.
To create a deployment folder from the HPC blueprint, run the following command from Cloud Shell:
./ghpc create examples/hpc-slurm.yaml \
-l ERROR --vars project_id=PROJECT_ID
Replace PROJECT_ID with your project ID.
This command creates the hpc-slurm/ deployment folder, which
contains the Terraform needed to deploy your cluster.
The -l ERROR validator flag is also specified to prevent the creation
of the deployment folder if any of the
validations
fail.
Deploy the HPC cluster using Terraform
To deploy the HPC cluster, complete the following steps:
Use the
ghpc deploycommand to begin automatic deployment of your cluster:./ghpc deploy hpc-slurm
ghpcreports the changes that Terraform is proposing to make for your cluster. Optionally, you may review them by typingdand pressing enter. To deploy the cluster, accept the proposed changes by typingaand pressing enter.Summary of proposed changes: Plan: 37 to add, 0 to change, 0 to destroy. (D)isplay full proposed changes, (A)pply proposed changes, (S)top and exit, (C)ontinue without applying Please select an option [d,a,s,c]:
After accepting the changes,
ghpcexecutesterraform applyautomatically. This takes approximately 5 minutes while it displays progress. If the run is successful, the output is similar to the following:Apply complete! Resources: 37 added, 0 changed, 0 destroyed.
Run a job on the HPC cluster
After the cluster deploys, complete the following steps to run a job:
Go to the Compute Engine > VM instances page.
Connect to the
hpcslurm-login-*VM using SSH-in-browser.From the Connect column of the VM, click SSH.
After connecting to the VM, if you see the following message on the terminal:
Slurm is currently being configured in the backgroundWait a few minutes, disconnect and then re-connect to the VM.
From the command line of the VM, run the
hostnamecommand using Slurm.srun -N 3 hostname
This command creates three compute nodes for your HPC cluster. This may take a minute while Slurm auto-scales to create the three nodes.
When the job finishes you should see an output similar to:
$ srun -N 3 hostname hpcslurm-debug-ghpc-0 hpcslurm-debug-ghpc-1 hpcslurm-debug-ghpc-2The auto-scaled nodes are automatically destroyed by the Slurm controller if left idle for more than 60 seconds.
Clean up
To avoid incurring charges to your Google Cloud account for the resources used on this page, delete the Google Cloud project with the resources.
Destroy the HPC cluster
Go to the VM instances page and check that the compute nodes are deleted.
Compute nodes use the following naming convention:
hpcslurm-debug-ghpc-*If you see any of these nodes, wait several minutes for them to be automatically deleted. This might take up to four minutes.
After the compute nodes are removed, from the Cloud Shell terminal, run the following command:
./ghpc destroy hpc-slurm --auto-approve
When complete you should see something like:
Destroy complete! Resources: xx destroyed.
Go to the VM instances page and check that the VMs are deleted.
Note: If the destroy command is run before Slurm shuts down the auto-scale nodes then the destroy command might fail. In this case, you can delete the VMs manually and rerun the destroy command.
Delete the project
The easiest way to eliminate billing is to delete the project that you created for the tutorial.
To delete the project:
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.