Pour optimiser les performances d'une application, vous devez tenir compte de l'utilisation qu'elle fait de la bibliothèque NDB. Par exemple, une application peut prendre un certain temps à lire une valeur qui n'est pas mise en cache. Vous pourrez peut-être faire accélérer votre application en exécutant des actions Datastore en parallèle avec d'autres tâches ou entre elles-mêmes.
La bibliothèque cliente NDB propose de nombreuses fonctions asynchrones ("async"),
dont chacune permet à une application d'envoyer une requête à Datastore. La fonction donne un résultat immédiat, en affichant un objet Future. L'application peut effectuer d'autres tâches pendant que Datastore traite la requête,
dont les résultats peuvent être obtenus à partir de l'objet Future.
Présentation
Supposons qu'un des gestionnaires de requêtes de votre application ait besoin d'utiliser NDB pour écrire quelque chose, éventuellement pour enregistrer la requête. Il doit également effectuer d'autres opérations associées à NDB, par exemple pour récupérer des données.
En remplaçant l'appel de put() par un appel de son équivalent asynchrone put_async(), l'application peut effectuer immédiatement une autre tâche au lieu de rester bloquée sur put().
Cela permet l'exécution des autres fonctions NDB et du rendu du modèle pendant que Datastore écrit les données. L'application ne reste pas bloquée sur Datastore tant que ce dernier ne lui a pas fourni de données.
Dans cet exemple, il semble plutôt insencé d'appeler future.get_result : l'application n'utilise jamais le résultat de NDB. Ce code sert juste à s'assurer que le gestionnaire de requêtes ne se ferme pas avant que la requête NDB put ne se termine, car s'il se ferme trop tôt, la requête "put" risque de ne jamais se produire. Pour plus de commodité, vous pouvez décorer le gestionnaire de requêtes avec @ndb.toplevel. Cela indique au gestionnaire de ne pas se fermer avant la fin de ses requêtes asynchrones. De cette façon, vous pouvez envoyer la requête sans vous soucier du résultat.
Vous pouvez spécifier un WSGIApplication entier comme ndb.toplevel. Vous vous assurez ainsi que chacun des gestionnaires de WSGIApplication attend la fin de toutes les requêtes asynchrones avant de répondre
(cela ne définit pas tous les gestionnaires de WSGIApplication comme "toplevel").
L'utilisation d'une application toplevel est plus pratique que toutes les fonctions de ses gestionnaires. Toutefois, si une méthode de gestionnaire a recours à yield, elle doit quand même être encapsulée dans un autre décorateur, @ndb.synctasklet. Autrement, elle cessera de s'exécuter au niveau de l'instruction yield et ne se terminera pas.
Utiliser des API asynchrones et des objets "Future"
Presque toutes les fonctions NDB synchrones ont un équivalent _async. Par exemple, put() a put_async().
Les arguments de la fonction asynchrone sont toujours les mêmes que ceux de la version synchrone.
La valeur affichée par une méthode asynchrone est toujours soit un objet Future, soit (pour les fonctions "multi") une liste d'objets Future.
L'objet Future maintient l'état d'une opération lancée, mais pas encore terminée. Toutes les API asynchrones affichent un ou plusieurs objets Futures.
Vous pouvez appeler la fonction get_result() de l'objet Future pour lui demander le résultat de son opération. Ensuite, en cas de besoin, l'objet Future se bloque jusqu'à ce que le résultat soit disponible, puis vous le renvoie.
La fonction get_result() affiche la valeur qui serait renvoyée par la version synchrone de l'API.
Remarque : Si vous avez utilisé des objets "Future" dans d'autres langages de programmation, vous pensez peut-être pouvoir les utiliser directement en tant que résultat, mais ce n'est pas le cas ici.
Ces langages utilisent des objets Future implicites, tandis que ceux utilisés par NDB sont explicites.
Vous devez appeler get_result() pour obtenir un résultat d'objet Future dans NDB.
Que se passe-t-il si l'opération génère une exception ? Tout dépend du moment où survient l'exception. Si NDB détecte un problème lors de l'exécution d'une requête (par exemple, un type d'argument incorrect), la méthode _async() génère une exception. En revanche, si l'exception est détectée par le serveur Datastore, par exemple, la méthode _async() affiche un objet Future et l'exception est générée lorsque votre application appelle sa fonction get_result(). Ne vous inquiétez pas trop à ce sujet, car tout finit par fonctionner relativement normalement. La plus grande différence réside probablement dans le fait que si une trace est imprimée, certains composants de la machinerie asynchrone de bas niveau seront visibles.
Supposons, par exemple, que vous écriviez une application de livre d'or et que vous souhaitiez présenter une page contenant les publications les plus récentes du livre d'or aux utilisateurs connectés. Cette page doit également montrer à l'utilisateur son pseudo. L'application a besoin de deux types d'informations : les informations de compte de l'utilisateur connecté et le contenu des publications du livre d'or. La version "synchrone" de cette application pourrait ressembler à ceci :
Nous avons ici deux actions d'E/S indépendantes : obtenir l'entité Account et extraire les entités Guestbook récentes. Avec l'API synchrone, ces actions se produisent l'une après l'autre : attendre de recevoir les informations du compte avant de récupérer les entités du livre d'or. Mais l'application n'a pas besoin des informations de compte immédiatement. Nous pouvons donc en profiter pour utiliser des API asynchrones :
Cette version du code crée d'abord deux Futures (acct_future et recent_entries_future), puis les attend. Le serveur travaille sur les deux requêtes en parallèle.
Chaque appel de fonction _async() crée un objet Future et envoie une requête au serveur Datastore, qui peut commencer à travailler sur la requête immédiatement. Les réponses du serveur peuvent revenir dans n'importe quel ordre et les objets "Future" associent les réponses aux requêtes correspondantes.
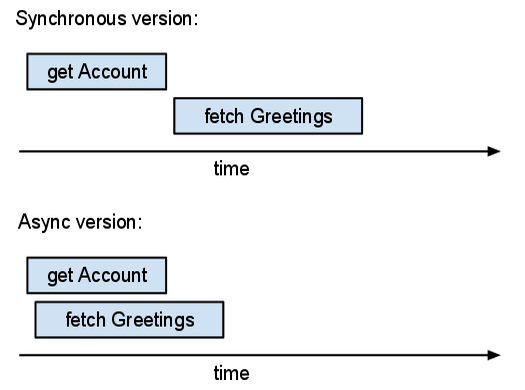
Le temps total (réel) passé dans la version asynchrone est à peu près égal à la durée de l'opération la plus longue, parmi l'ensemble des opérations. Le temps total passé dans la version synchrone est supérieur à la durée cumulée des opérations. Si vous pouvez exécuter davantage d'opérations en parallèle, les opérations asynchrones sont donc plus utiles.
Pour savoir combien de temps prennent les requêtes de votre application ou le nombre d'opérations d'E/S effectuées par requête, utilisez Appstats. Cet outil permet d'afficher des graphiques semblables au schéma ci-dessus, à partir de l'instrumentation d'une application active.
Utiliser des tasklets
Un tasklet NDB est un morceau de code pouvant être exécuté simultanément avec un autre code. Si vous écrivez un tasklet, votre application peut l'utiliser de la même manière qu'elle utilise une fonction NDB asynchrone : elle appelle le tasklet qui affiche un objet Future. Ensuite, en appelant la méthode get_result() de l'objet Future, elle obtient le résultat.
Les tasklets constituent un moyen d'écrire des fonctions simultanées sans threads. Ils sont exécutés par une boucle d'événements et peuvent se suspendre d'eux-mêmes en bloquant des opérations d'E/S ou toute autre opération, à l'aide d'une instruction "yield". La notion d'opération de blocage est résumée dans la classe Future, mais un tasklet peut également appliquer l'instruction yield à un RPC afin d'en attendre la fin.
Lorsque le tasklet obtient un résultat, il génère (raise) une exception ndb.Return, puis NDB associe ce résultat à l'objet Future auquel a été appliquée l'instruction yield auparavant.
Lors de l'écriture d'un tasklet NDB, les instructions yield et raise ne sont pas utilisées de manière habituelle. Par conséquent, si vous recherchez des exemples d'utilisation, vous ne trouverez probablement pas de code semblable à un tasklet NDB.
Pour transformer une fonction en tasklet NDB, procédez comme suit :
- Décorez la fonction avec
@ndb.tasklet. - Remplacez tous les appels faits au datastore synchrone par des instructions
yieldd'appels de datastore asynchrone. - Faites en sorte que la fonction affiche sa valeur avec
raise ndb.Return(retval)(facultatif si la fonction n'affiche rien).
Une application peut utiliser des tasklets pour mieux contrôler les API asynchrones. À titre d'exemple, voyons le schéma suivant :
...
Pour afficher un message, il est judicieux de montrer également le pseudo de l'auteur. La manière "synchrone" de récupérer les données pour afficher une liste de messages pourrait ressembler à ceci :
Malheureusement, cette approche est inefficace. En l'affichant dans Appstats, vous verriez que les requêtes "Get" sont en série, probablement selon le schéma en "escalier" ci-après.
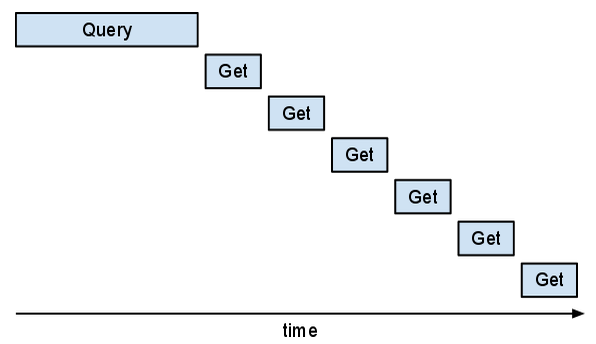
Cette partie du programme serait plus rapide si ces requêtes "Get" pouvaient se chevaucher.
Vous pouvez réécrire le code de sorte à utiliser get_async, mais il sera difficile de savoir quelles requêtes asynchrones appartiennent à quels messages et inversement.
L'application peut définir sa propre fonction "async" en la transformant en tasklet. Cela vous permet d'organiser le code de manière moins confuse.
D'autre part, au lieu de acct = key.get() ou acct = key.get_async().get_result(), la fonction doit utiliser acct = yield key.get_async().
Cette instruction yield indique à NDB qu'il s'agit d'un bon endroit pour suspendre ce tasklet et permettre aux autres de s'exécuter.
Comme la fonction est décorée avec @ndb.tasklet, elle affiche un objet Future au lieu d'un objet de générateur. Dans le tasklet, toute instruction yield d'un objet Future attend et affiche le résultat de l'objet Future.
Exemple :
Notez que bien que get_async() affiche un objet Future, le framework du tasklet oblige l'expression yield à afficher le résultat de l'objet Future dans la variable acct.
map() appelle callback() plusieurs fois.
Mais yield ..._async() dans callback() permet au programmeur de NDB d'envoyer de nombreuses requêtes asynchrones avant d'attendre que l'une d'elles ne se termine.
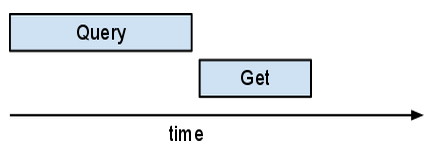
En observant cela dans Appstats, il peut être surprenant de voir que ces requêtes "Get" multiples, en plus de se chevaucher, passent toutes par la même requête. NDB implémente un "autobatcher". Cet autobatcher regroupe plusieurs requêtes dans un seul RPC en lot envoyé au serveur. Il procède de telle sorte que tant qu'il reste des tâches à effectuer (un autre rappel peut être en cours d'exécution), il collecte les clés. Dès qu'un des résultats est requis, l'autobatcher envoie le RPC en lot. Contrairement à la plupart des requêtes, celles-ci ne sont pas "mises en lot".
Lorsqu'un tasklet est exécuté, l'espace de noms par défaut qui lui est attribué correspond à la configuration par défaut au moment de la création du tasklet, ou à toute modification que le tasklet ait pu lui apporter en cours d'exécution. En d'autres termes, l'espace de noms par défaut n'est pas associé au Context et n'y est pas non plus stocké. La modification de l'espace de noms par défaut d'un tasklet n'affecte pas l'espace de noms par défaut des autres tasklets, à l'exception de ceux qu'il génère.
Tasklets, requêtes parallèles, "yield" parallèles
Vous pouvez utiliser des tasklets pour que plusieurs requêtes récupèrent des enregistrements en même temps. Par exemple, supposons que votre application comporte une page qui affiche le contenu d'un panier et une liste d'offres spéciales. Le schéma pourrait ressembler à ceci :
Une fonction "synchrone" qui récupère les articles du panier et les offres spéciales pourrait ressembler à ceci :
Cet exemple utilise des requêtes pour extraire des listes d'articles de panier et d'offres, pour ensuite récupérer les informations sur les articles en stock avec get_multi().
(Cette fonction n'utilise pas directement la valeur de retour de get_multi(). Elle appelle get_multi() pour récupérer tous les détails du stock dans le cache, afin de pouvoir les lire rapidement plus tard). get_multi combine plusieurs requêtes "Get" en une seule, mais les requêtes extraient les informations l'une après l'autre. Pour que ces extractions se produisent en même temps, superposez les deux requêtes :
L'appel get_multi() est toujours séparé : il dépend des résultats de requête. Vous ne pouvez donc pas le combiner avec les requêtes.
Supposons que cette application doive afficher parfois le panier, parfois les offres et parfois les deux. Vous voulez organiser votre code de sorte qu'il y ait une fonction pour obtenir les informations du panier et une fonction pour obtenir les offres. Si votre application appelle ces fonctions en même temps, leurs requêtes pourraient idéalement "se chevaucher". Pour ce faire, vous allez créer des tasklets à partir de ces fonctions :
Cette instruction yield x, y est importante, mais il est facile de l'omettre. S'il s'agissait de deux instructions yield distinctes, elles s'exécuteraient en série. Mais l'application de l'instruction yield à un tuple de tasklets se fait en parallèle : les tasklets peuvent s'exécuter en parallèle et l'instruction yield attend qu'ils se terminent tous, puis affiche les résultats. (Dans certains langages de programmation, cela s'appelle une barrière.)
Après avoir transformé un morceau de code en tasklet, vous risquez fort de vouloir poursuivre en ce sens. Si vous remarquez un code "synchrone" qui pourrait s'exécuter en parallèle avec un tasklet, alors il est probablement judicieux d'en faire également un tasklet.
Vous pouvez ensuite l'exécuter en parallèle avec une instruction yield parallèle.
Si vous écrivez une fonction de requête (une fonction de requête webapp2, une fonction de vue Django, etc.) sous forme de tasklet, elle ne fera pas ce que vous voulez : elle exécute l'instruction "yield", mais s'arrête ensuite. Dans ce cas, il est recommandé de décorer la fonction avec @ndb.synctasklet.
@ndb.synctasklet équivaut à @ndb.tasklet, mais modifié pour appeler get_result() sur le tasklet.
Cela convertit votre tasklet en une fonction qui affiche son résultat de la manière habituelle.
Itérateurs de requêtes dans les tasklets
Pour parcourir les résultats des requêtes dans un tasklet, utilisez le modèle suivant :
Il s'agit d'un code équivalent au code suivant, mais compatible avec les tasklets :
Les trois lignes en gras de la première version représentent l'équivalent compatible avec les tasklets de la ligne en gras unique de la deuxième version.
Les tasklets ne peuvent être suspendus qu'au niveau d'un mot clé yield.
L'absence de yield dans la boucle ne permet pas l'exécution d'autres tasklets.
Vous vous demandez peut-être pourquoi ce code utilise un itérateur de requête au lieu de récupérer toutes les entités à l'aide de qry.fetch_async().
Il se peut que les entités de l'application soient si nombreuses qu'elles ne puissent pas toutes être contenues dans la RAM.
Vous pouvez peut-être vous arrêter une fois que vous avez trouvé l'entité que vous recherchez, mais vous ne pouvez pas exprimer vos critères de recherche avec le seul langage de requête. Vous pouvez utiliser un itérateur pour charger des entités à vérifier, puis sortir de la boucle une fois que vous avez trouvé ce que vous voulez.
Récupération d'URL asynchrone avec NDB
Le Context NDB dispose d'une fonction urlfetch() asynchrone se prêtant idéalement à une exécution en parallèle avec les tasklets NDB, par exemple :
Le service de récupération d'URL possède sa propre API de requêtes asynchrones. Elle est pratique, mais pas toujours facile à utiliser avec les tasklets NDB.
Utiliser des transactions asynchrones
Les transactions peuvent également être effectuées de manière asynchrone. Vous pouvez transmettre une fonction existante à ndb.transaction_async() ou utiliser le décorateur @ndb.transactional_async.
Comme pour les autres fonctions asynchrones, la réponse affichée sera un objet Future NDB :
Les transactions fonctionnent également avec des tasklets. Par exemple, nous pourrions remplacer notre code update_counter par yield en attendant le blocage des RPC :
Utiliser Future.wait_any()
Il se peut que vous souhaitiez effectuer plusieurs requêtes asynchrones et les afficher une fois la première terminée.
Vous pouvez le faire à l'aide de la méthode de la classe ndb.Future.wait_any() :.
Malheureusement, il n'existe aucun moyen pratique d'en faire un tasklet : une instruction yield parallèle attend que tous les objets Future soient terminés, y compris ceux que vous ne souhaitez pas attendre.