Microservices refers to an architectural style for developing applications. Microservices allow a large application to be decomposed into independent constituent parts, with each part having its own realm of responsibility. To serve a single user or API request, a microservices-based application can call many internal microservices to compose its response.
A properly implemented microservices-based application can achieve the following goals:
- Define strong contracts between the various microservices.
- Allow for independent deployment cycles, including rollback.
- Facilitate concurrent, A/B release testing on subsystems.
- Minimize test automation and quality-assurance overhead.
- Improve clarity of logging and monitoring.
- Provide fine-grained cost accounting.
- Increase overall application scalability and reliability.
Google App Engine has a number of features that are well-suited for a microservices-based application. This page outlines best practices to use when deploying your application as a microservices-based application on Google App Engine.
App Engine Services as microservices
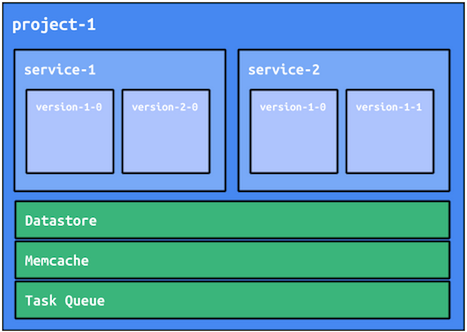
In an App Engine project, you can deploy multiple microservices as separate services, previously known as modules in App Engine. These services have full isolation of code; the only way to execute code in these services is through an HTTP invocation, such as a user request or a RESTful API call. Code in one service can't directly call code in another service. Code can be deployed to services independently, and different services can be written in different languages, such as Python, Java, Go, and PHP. Autoscaling, load balancing, and machine instance types are all managed independently for services.

Versions within services
Furthermore, each service can have multiple versions deployed simultaneously. For each service, one of these versions is the default serving version, though it is possible to directly access any deployed version of a service as each version of each service has its own address. This structure opens up myriad possibilities, including smoke testing a new version, A/B testing between different versions, and simplified roll-forward and rollback operations. The App Engine framework provides mechanisms to assist with most of these items. We'll cover these mechanisms in more detail in upcoming sections.

Service isolation
Though mostly isolated, services share some App Engine resources. For example, Cloud Datastore, Memcache, and Task Queues are all shared resources between services in an App Engine project. While this sharing has some advantages, it's important for a microservices-based application to maintain code- and data-isolation between microservices. There are architecture patterns that help mitigate unwanted sharing. We'll describe these patterns later in this article.
Project isolation
If you don't want to rely on these patterns to achieve isolation and you want a more formal enforcement of separation, you can use multiple App Engine projects. There are pros and cons to using projects instead of services, and you must balance the tradeoffs depending on your situation. Unless you have a specific need for one of the advantages offered by using multiple projects, it's best to start with using multiple services within a single project because performance will be better and the administrative overhead will be minimized. Of course, you can also choose some hybrid of the two approaches.
Comparison of service isolation and project isolation
The following table provides a comparison between using multiple services and multiple projects in a microservices architecture:
| Multiple services | Multiple projects | |
|---|---|---|
| Code isolation | Deployed code is completely independent between services and versions. | Deployed code is completely independent between projects, and between services and versions of each project. |
| Data isolation |
Cloud Datastore and Memcache are shared between services and versions, however
namespaces
can be used as a developer pattern to isolate the data.
For Task Queue isolation, a developer convention of queue names
can be employed, such as user-service-queue-1.
|
Cloud Datastore, Memcache, and Task Queues are completely independent between projects. |
| Log isolation | Each service (and version) has independent logs, though they can be viewed together. | Each project (and service and version of each project) has independent logs, though all the logs for a given project can be viewed together. Logs across multiple projects cannot be viewed together. |
| Performance overhead | Services of the same project are deployed in the same datacenter, so the latency in calling one service from another by using HTTP is very low. | Projects might be deployed in different datacenters, so HTTP latencies could be higher, though still quite low because Google's network is world-class. |
| Cost accounting | Costs for instance-hours (the CPU and memory for running your code) are not separated for services; all the instance-hours for an entire project are lumped together. | Costs for different projects are split, making it very easy to see the cost of different microservices. |
| Operator permissions | An operator has the ability to deploy code, roll forward and roll back versions, and view the logs for all services of a project. There is no way to limit access to specific services. | Operator access can be controlled separately on separate projects. |
| Request tracing | Using Google Cloud Trace, you can view a request and the resulting microservice requests for services in the same project as a single composed trace. This feature can help make performance tuning easier. | Cloud Trace calls can be visualized across GCP projects if they are within the same Organization. |
What's next
- Understand how to create and name dev, test, qa, staging, and production environments with microservices in App Engine.
- Learn the best practices for designing APIs to communicate between microservices.
- Learn the best practices for microservice performance.
- Learn how to Migrate an existing monolithic application to one with microservices.
- Understand if microservices are ideal for your situation. On his personal blog, Google Solution Architect Preston Holmes has published a post about some of the drawbacks he sees in microservices.