Stai visualizzando la documentazione di Apigee e Apigee hybrid.
Visualizza la documentazione di
Apigee Edge.
Il criterio RaiseFault consente agli sviluppatori di API di avviare un flusso di errori, impostare le variabili di errore
in un messaggio del corpo della risposta e impostare i codici di stato di risposta appropriati. Puoi anche utilizzare il criterio RaiseFault per impostare le variabili di flusso relative all'errore, ad esempio fault.name, fault.type e fault.category. Poiché queste variabili sono visibili nei dati di analisi e nei log di accesso al router utilizzati per il debug, è importante identificare con precisione l'errore.
Puoi utilizzare il criterio RaiseFault per trattare condizioni specifiche come errori, anche se non si è verificato un errore reale in un altro criterio o nel server di backend del proxy API. Ad esempio, se vuoi che il proxy invii un messaggio di errore personalizzato all'app client ogni volta che il corpo della risposta del backend contiene la stringa unavailable, puoi invocare il criterio RaiseFault come mostrato nello snippet di codice di seguito:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
Il nome del criterio RaiseFault è visibile come fault.name nel
monitoring dell'API e come x_apigee_fault_policy nei log di accesso di Analytics e del router.
In questo modo è possibile diagnosticare facilmente la causa dell'errore.
Antipattern
Utilizzo del criterio RaiseFault in FaultRules dopo che un altro criterio ha già generato un errore
Prendi in considerazione l'esempio seguente, in cui un criterio OAuthV2 nel flusso del proxy API non è riuscito con un errore InvalidAccessToken. In caso di errore, Apigee imposta fault.name su InvalidAccessToken, entra nel flusso di errore ed esegue eventuali regole FaultRules definite. In FaultRule è presente un criterio RaiseFault denominato
RaiseFault che invia una risposta di errore personalizzata ogni volta che si verifica un errore InvalidAccessToken. Tuttavia, l'utilizzo del criterio RaiseFault in una regola di errore comporta la sovrascrittura della variabile fault.name
e maschera la causa reale dell'errore.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
Utilizzo del criterio RaiseFault in una regola di errore in tutte le condizioni
Nell'esempio riportato di seguito, un criterio RaiseFault denominato RaiseFault viene eseguito se fault.name
non è RaiseFault:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
Come nel primo scenario, le variabili di errore principali fault.name, fault.code e fault.policy vengono sovrascritte con il nome del criterio RaiseFault. Questo comportamento
rende quasi impossibile determinare quale criterio ha effettivamente causato l'errore senza accedere a un file di traccia
che mostri l'errore o riprodurre il problema.
Utilizzo del criterio RaiseFault per restituire una risposta HTTP 2xx al di fuori del flusso di errore.
Nell'esempio seguente, un criterio RaiseFault denominato HandleOptionsRequest viene eseguito quando il verbo della richiesta è OPTIONS:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
Lo scopo è restituire immediatamente la risposta al client API senza elaborare altri criteri. Tuttavia, questo comporterà dati di analisi fuorvianti perché le variabili di errore conterranno il nome del criterio RaiseFault, rendendo più difficile il debug del proxy. Il modo corretto per implementare il comportamento desiderato è utilizzare i flussi con condizioni speciali, come descritto in Aggiunta del supporto CORS.
Impatto
L'utilizzo del criterio RaiseFault come descritto sopra comporta la sovrascrittura delle variabili di errore principali con il nome del criterio RaiseFault anziché con il nome del criterio con errore. Nei log di accesso di Analytics e NGINX,
le variabili x_apigee_fault_code e x_apigee_fault_policy
vengono sovrascritte. In Monitoring API, Fault Code
e Fault Policy vengono sovrascritti. Questo comportamento rende difficile la risoluzione dei problemi e la determinazione del criterio che rappresenta la causa effettiva dell'errore.
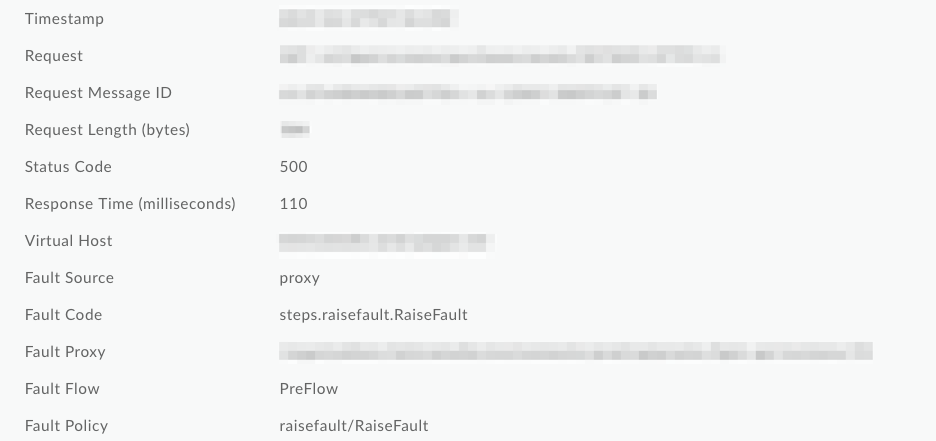
Nello screenshot di seguito di Monitoraggio API,
puoi vedere che il codice di errore e il criterio di errore sono stati sovrascritti con valori generici RaiseFault, rendendo impossibile determinare la causa principale dell'errore dai log:
Best practice
Quando un criterio Apigee genera un errore e vuoi personalizzare il messaggio di risposta di errore, utilizza i criteri AssignMessage o JavaScript anziché il criterio RaiseFault.
Il criterio RaiseFault deve essere utilizzato in un flusso senza errori. In altre parole, utilizza RaiseFault solo per trattare una condizione specifica come un errore, anche se non si è verificato un errore effettivo in un criterio o nel server di backend del proxy API. Ad esempio, puoi utilizzare il criterio RaiseFault per segnalare che i parametri di input obbligatori mancano o hanno una sintassi errata.
Puoi anche utilizzare RaiseFault in una regola di errore se vuoi rilevare un errore durante l'elaborazione di un errore. Ad esempio, il gestore degli errori stesso potrebbe causare un errore che vuoi segnalare utilizzando RaiseFault.
Per approfondire
- Gestione degli errori
- Criterio RaiseFault
- Discussione della community sui pattern di gestione degli errori