You're viewing Apigee and Apigee hybrid documentation.
View
Apigee Edge documentation.
The RaiseFault policy lets API developers initiate an error flow, set error variables
in a response body message, and set appropriate response status codes. You can also use the RaiseFault
policy to set flow variables pertaining to the fault, such as, fault.name, fault.type,
and fault.category. Because these variables are visible in analytics data and Router access logs
used for debugging, it's important to identify the fault accurately.
You can use the RaiseFault policy to treat specific conditions as errors, even if an actual error has
not occurred in another policy or in the backend server of the API proxy. For example, if you want
the proxy to send a custom error message to the client app whenever the backend response
body contains the string unavailable, then you could invoke the RaiseFault policy as
shown in the code snippet below:
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
The RaiseFault policy's name is visible as the fault.name in
API Monitoring and as x_apigee_fault_policy in the Analytics and Router access logs.
This helps to diagnose the cause of the error easily.
Antipattern
Using the RaiseFault policy within FaultRules after another policy has already thrown an error
Consider the example below, where an OAuthV2 policy in the API Proxy flow has failed with an InvalidAccessToken
error. Upon failure, Apigee will set the fault.name as InvalidAccessToken, enter into
the error flow, and execute any defined FaultRules. In the FaultRule, there is a RaiseFault policy named
RaiseFault that sends a customized error response whenever an InvalidAccessToken
error occurs. However, the use of RaiseFault policy in a FaultRule means that the fault.name
variable is overwritten and masks the true cause of the failure.
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
Using RaiseFault policy in a FaultRule under all conditions
In the example below, a RaiseFault policy named RaiseFault executes if the fault.name
is not RaiseFault:
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
As in the first scenario, the key fault variables fault.name, fault.code,
and fault.policy are overwritten with the RaiseFault policy's name. This behavior makes
it almost impossible to determine which policy actually caused the failure without accessing a trace
file showing the failure or reproducing the issue.
Using RaiseFault policy to return a HTTP 2xx response outside of the error flow.
In the example below, a RaiseFault policy named HandleOptionsRequest executes when
the request verb is OPTIONS:
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
The intent is to return the response to the API client immediately without processing other policies. However, this will lead to misleading analytics data because the fault variables will contain the RaiseFault policy's name, making the proxy more difficult to debug. The correct way to implement the desired behavior is to use Flows with special conditions, as described in Adding CORS support.
Impact
Use of the RaiseFault policy as described above results in overwriting key fault variables with the
RaiseFault policy's name instead of the failing policy's name. In Analytics and NGINX Access logs,
the x_apigee_fault_code and x_apigee_fault_policy variables
are overwritten. In API Monitoring, the Fault Code
and Fault Policy are overwritten. This behavior makes it difficult to troubleshoot and
determine which policy is the true cause of the failure.
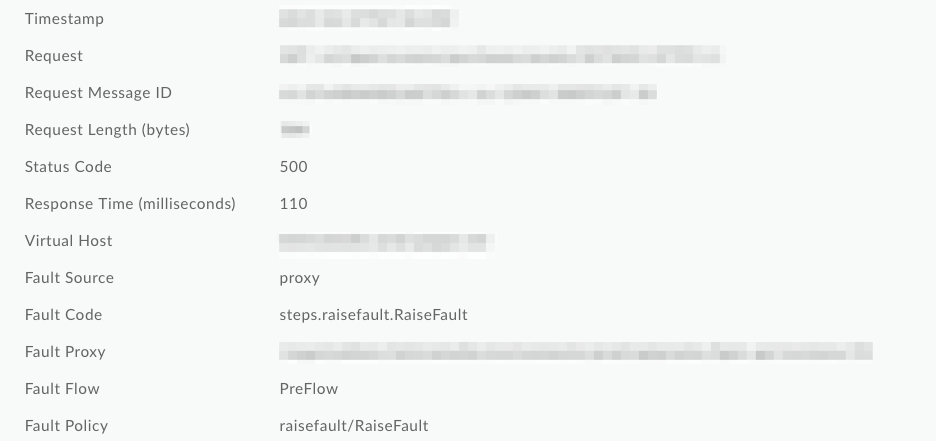
In the screenshot below from API Monitoring,
you can see that the Fault Code and Fault policy were overwritten to generic RaiseFault
values, making it impossible to determine the root cause of the failure from the logs:
Best Practice
When an Apigee policy raises a fault and you want to customize the error response message, use the AssignMessage or JavaScript policies instead of the RaiseFault policy.
The RaiseFault policy should be used in a non-error flow. That is, only use RaiseFault to treat a specific condition as an error, even if an actual error has not occurred in a policy or in the backend server of the API Proxy. For example, you could use the RaiseFault policy to signal that mandatory input parameters are missing or have incorrect syntax.
You can also use RaiseFault in a fault rule if you want to detect an error during the processing of a fault. For example, your fault handler itself could cause an error that you want to signal by using RaiseFault.