現在、Apigee と Apigee ハイブリッドのドキュメントを表示しています。
Apigee Edge ドキュメントを表示する。
RaiseFault ポリシーを使用すると、エラーフローを開始し、レスポンスの本文メッセージにエラー変数を設定して、適切なレスポンス ステータス コードを設定できます。また、fault.name、fault.type、fault.category などの障害に関連するフロー変数の設定にも、RaiseFault ポリシーを使用できます。これらの変数は分析データと、デバッグに使用されるルーター アクセスログに表示されるので、障害を正確に識別できることが重要です。
RaiseFault ポリシーを使用すると、別のポリシーまたは API プロキシのバックエンド サーバーで実際のエラーが発生していなくても、特定の条件をエラーとして扱うことができます。たとえば、バックエンドのレスポンスの本文に文字列 unavailable が含まれているときは常にプロキシがクライアント アプリケーションにカスタムエラー メッセージを送信するようにするには、以下のコード スニペットのようにして、RaiseFault ポリシーを呼び出すことができます。
<!-- /antipatterns/examples/raise-fault-conditions-1.xml --> <TargetEndpoint name="default"> ... <Response> <Step> <Name>RF-Service-Unavailable</Name> <Condition>(message.content Like "*unavailable*")</Condition> </Step> </Response> ...
RaiseFault ポリシーの名前は、API Monitoring では fault.name として、Analytics と Router のアクセスログには x_apigee_fault_policy として表示されます。これにより、エラーの原因を簡単に診断できます。
アンチパターン
別のポリシーがエラーを送出した後、FaultRules 内で RaiseFault ポリシーを使用する
次の例について考えてみましょう。ここでは API プロキシフローの OAuthV2 ポリシーが InvalidAccessToken エラーで失敗しています。障害が発生すると、Apigee は fault.name を InvalidAccessToken に設定してエラーフローに入り、定義されたすべての FaultRule を実行します。FaultRule には、RaiseFault という名前の RaiseFault ポリシーがあり、InvalidAccessToken エラーが発生するたびにカスタマイズされたエラー レスポンスを送信します。ただし、FaultRule で RaiseFault ポリシーを使用すると、fault.name 変数が上書きされ、障害の真の原因がマスクされます。
<!-- /antipatterns/examples/raise-fault-conditions-2.xml --> <FaultRules> <FaultRule name="generic_raisefault"> <Step> <Name>RaiseFault</Name> <Condition>(fault.name equals "invalid_access_token") or (fault.name equals "InvalidAccessToken")</Condition> </Step> </FaultRule> </FaultRules>
すべての条件下で FaultRule で RaiseFault ポリシーを使用する
次の例では、fault.name が RaiseFault がでない場合、RaiseFault という名前の RaiseFault ポリシーが実行されます。
<!-- /antipatterns/examples/raise-fault-conditions-3.xml --> <FaultRules> <FaultRule name="fault_rule"> .... <Step> <Name>RaiseFault</Name> <Condition>!(fault.name equals "RaiseFault")</Condition> </Step> </FaultRule> </FaultRules>
最初のシナリオと同様に、主要な障害変数 fault.name、fault.code、fault.policy が、RaiseFault ポリシーの名前で上書きされます。この動作が原因で、障害を示すトレース ファイルを確認したり問題を再現したりしない限り、どのポリシーが実際に障害を生じさせたのかを特定することはほとんど不可能です。
RaiseFault ポリシーを使用して、エラーフロー外で HTTP 2xx レスポンスを返す
次の例では、リクエスト動詞が OPTIONS の場合に、HandleOptionsRequest という名前の RaiseFault ポリシーが実行されます。
<!-- /antipatterns/examples/raise-fault-conditions-4.xml --> <PreFlow name="PreFlow"> <Request> … <Step> <Name>HandleOptionsRequest</Name> <Condition>(request.verb Equals "OPTIONS")</Condition> </Step> … </PreFlow>
目的は、他のポリシーを処理せずに、即座に API クライアントにレスポンスを返すことです。ただし、障害変数には RaiseFault ポリシーの名前が含まれ、誤解を招く分析データが得られて、プロキシのデバッグが難しくなります。目的の動作を正しく実装するには、CORS サポートの追加で説明されているように、特別な条件でフローを使用します。
影響
上記のように RaiseFault ポリシーを使用すると、失敗したポリシーの名前ではなく RaiseFault ポリシーの名前で主要な障害変数が上書きされます。Analytics と NGINX Access のログでは x_apigee_fault_code 変数と x_apigee_fault_policy 変数が上書きされます。API Monitoring では、Fault Code と Fault Policy が上書きされます。この動作により、どのポリシーが障害の真の原因なのかをトラブルシューティングして判断することが難しくなります。
以下の API Monitoring のスクリーンショットでは、障害コードと障害ポリシーが一般的な RaiseFault 値に上書きされており、ログから障害の根本原因を特定することが不可能になります。
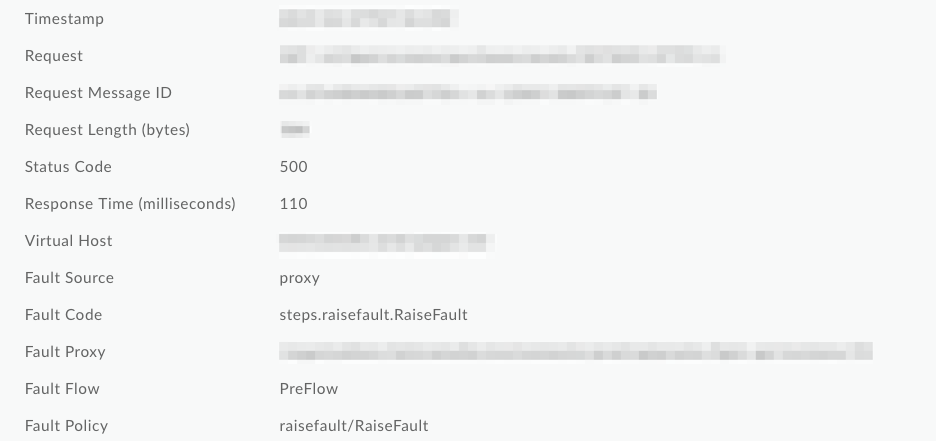
ベスト プラクティス
Apigee ポリシーで障害が発生し、エラー レスポンス メッセージをカスタマイズする場合は、RaiseFault ポリシーの代わりに AssignMessage または JavaScript ポリシーを使用します。
RaiseFault ポリシーは、エラーのないフローで使用する必要があります。つまり、ポリシーや API プロキシのバックエンド サーバーで実際のエラーが発生していなくても特定の条件をエラーとして扱いたい場合に限り、RaiseFault ポリシーを使用します。たとえば、RaiseFault ポリシーを使用して、必須入力パラメータが欠落していることや、構文が正しくないことを通知できます。
また障害ルールで RaiseFault を使用して、障害の処理中にエラーを検出することもできます。たとえば、障害ハンドラ自体がエラーを引き起こす可能性がある場合、そうしたエラーを RaiseFault によって通知できます。