Cette page décrit les options de haute disponibilité disponibles dans Google Distributed Cloud.
Fonctionnalité de base
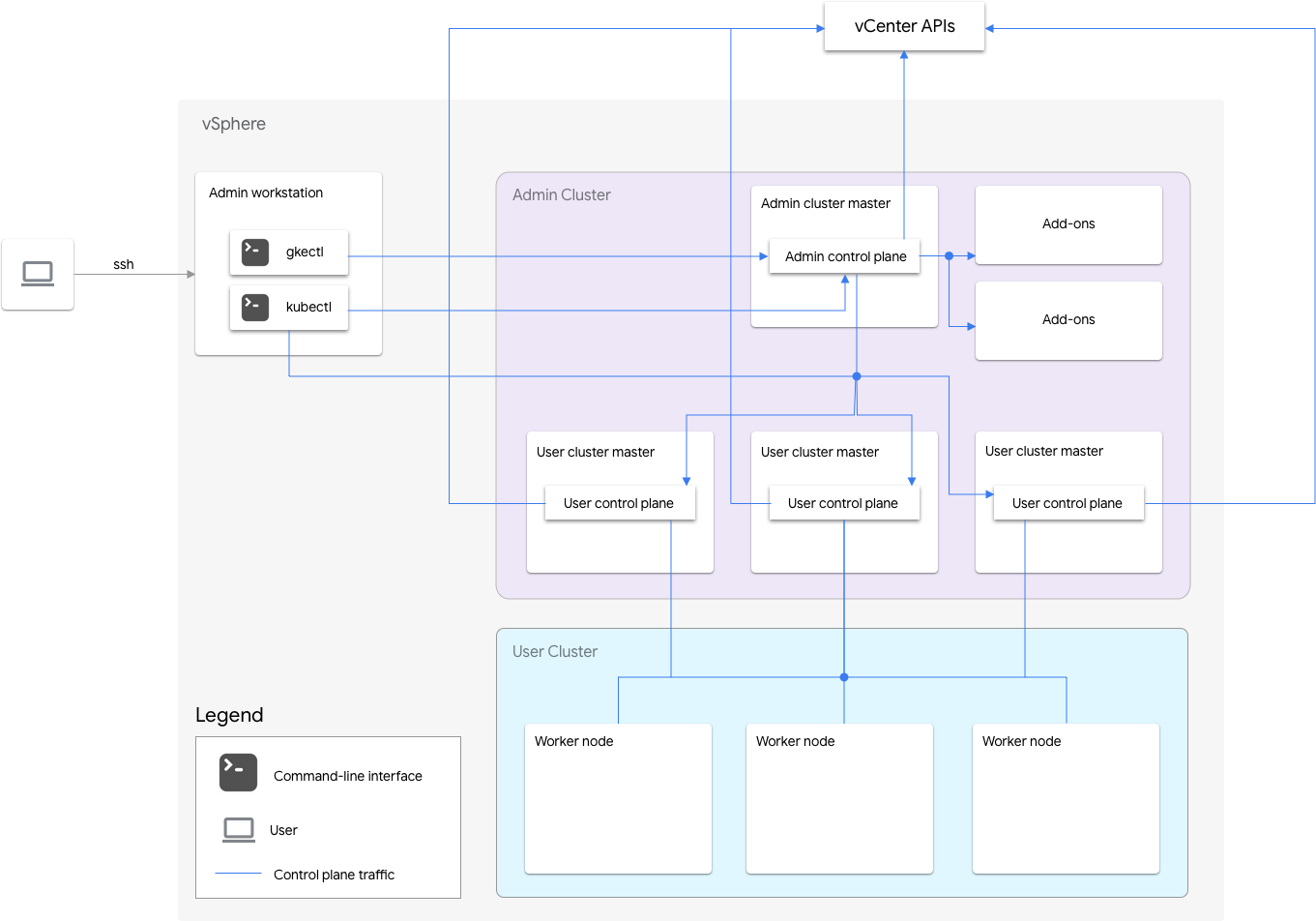
GKE sur VMware inclut un cluster d'administrateur et un ou plusieurs clusters d'utilisateur.
Le cluster d'administrateur gère le cycle de vie des clusters d'utilisateur, y compris leur création, leurs mises à jour, leurs mises à niveau et leur suppression. Dans le cluster d'administrateur, le maître d'administrateur gère les nœuds de calcul d'administrateur, qui incluent les maîtres d'utilisateur (nœuds exécutant le plan de contrôle des clusters d'utilisateur gérés) et les nœuds complémentaires (nœuds exécutant les composants complémentaires compatibles avec les fonctionnalités du cluster d'administrateur).
Pour chaque cluster d'utilisateur, le cluster d'administrateur comporte un nœud standard ou trois nœuds haute disponibilité exécutant le plan de contrôle. Le plan de contrôle inclut le serveur d'API Kubernetes, le programmeur Kubernetes, le gestionnaire de contrôleurs Kubernetes et plusieurs contrôleurs critiques pour le cluster d'utilisateur.
La disponibilité du plan de contrôle du cluster d'utilisateur est essentielle pour les opérations de charges de travail telles que la création, le scaling à la hausse et à la baisse, et l'arrêt d'une charge de travail. En d'autres termes, une panne du plan de contrôle n'interfère pas avec les charges de travail en cours d'exécution, mais les charges de travail existantes perdent les fonctionnalités de gestion du serveur d'API Kubernetes si son plan de contrôle est absent.
Les charges de travail et services conteneurisés sont déployés dans les nœuds de calcul du cluster d'utilisateur. Les nœuds de calcul à un seul nœud ne doivent pas être critiques pour la disponibilité d'une application tant qu'elle est déployée avec des pods redondants programmés sur plusieurs nœuds de calcul.
Activer la haute disponibilité
vSphere et Google Distributed Cloud fournissent un certain nombre de fonctionnalités qui contribuent à la haute disponibilité.
vSphere HA et vMotion
Nous vous recommandons d'activer les deux fonctionnalités suivantes dans le cluster vCenter qui héberge vos clusters Google Distributed Cloud:
Ces fonctionnalités améliorent la disponibilité et la récupération en cas de défaillance d'un hôte ESXi.
vCenter HA utilise plusieurs hôtes ESXi configurés en tant que cluster pour assurer une récupération rapide des pannes et une haute disponibilité économique pour les applications exécutées sur des machines virtuelles. Nous vous recommandons de provisionner votre cluster vCenter avec des hôtes supplémentaires et d'activer la surveillance de l'hôte vSphere haute disponibilité avec Host Failure Response défini sur Restart VMs. Vos VM peuvent alors redémarrer automatiquement sur d'autres hôtes disponibles en cas de défaillance de l'hôte ESXi.
vMotion permet d'effectuer une migration à chaud sans interruption d'un hôte ESXi vers un autre hôte. Pour la maintenance planifiée de l'hôte, vous pouvez utiliser la migration à chaud vMotion pour éviter tout temps d'arrêt d'application et garantir la continuité de l'entreprise.
Cluster d'administrateur
Google Distributed Cloud permet de créer des clusters d'administrateur haute disponibilité. Un cluster d'administrateur haute disponibilité comporte trois nœuds qui exécutent les composants du plan de contrôle. Pour en savoir plus sur les exigences et les limites, consultez la section Cluster d'administrateur haute disponibilité.
Notez que l'indisponibilité du plan de contrôle du cluster d'administrateur n'affecte pas les fonctionnalités de cluster d'utilisateur existantes ni les charges de travail exécutées dans les clusters d'utilisateur.
Un cluster d'administrateur comporte deux nœuds complémentaires. Si l'un est indisponible, l'autre peut toujours traiter les opérations du cluster d'administrateur. À des fins de redondance, Google Distributed Cloud répartit des services complémentaires essentiels, tels que kube-dns, sur les deux nœuds de modules complémentaires.
Si vous définissez antiAffinityGroups.enabled sur true dans le fichier de configuration du cluster d'administrateur, Google Distributed Cloud crée automatiquement des règles d'anti-affinité vSphere DRS pour les nœuds de module complémentaire, qui sont alors répartis sur deux hôtes physiques pour la haute disponibilité.
Cluster d'utilisateur
Vous pouvez activer la haute disponibilité pour un cluster d'utilisateur en définissant masterNode.replicas sur 3 dans le fichier de configuration du cluster d'utilisateur. Si Controlplane V2 est activé sur le cluster d'utilisateur (recommandé), les trois nœuds du plan de contrôle s'exécutent dans le cluster d'utilisateur.
Les anciens clusters d'utilisateur kubeception haute disponibilité exécutent les trois nœuds du plan de contrôle dans le cluster d'administrateur. Chaque nœud du plan de contrôle exécute également une instance répliquée etcd. Le cluster d'utilisateur continuera de fonctionner tant qu'un plan de contrôle est en cours d'exécution et qu'il y a un quorum etcd. Un quorum etcd nécessite que deux des trois instances dupliquées etcd soient en cours d'exécution.
Si vous définissez antiAffinityGroups.enabled sur true dans le fichier de configuration du cluster d'administrateur, Google Distributed Cloud crée automatiquement des règles d'anti-affinité vSphere DRS pour les trois nœuds qui exécutent le plan de contrôle du cluster d'utilisateur.
Cela a pour effet de répartir les VM sur trois hôtes physiques.
Google Distributed Cloud crée également des règles d'anti-affinité vSphere DRS pour les nœuds de calcul de votre cluster d'utilisateur, qui sont alors répartis sur au moins trois hôtes physiques. Plusieurs règles d'anti-affinité DRS sont utilisées par chaque pool de nœuds de cluster d'utilisateur en fonction du nombre de nœuds. Cela garantit que les nœuds de calcul peuvent trouver des hôtes sur lesquels s'exécuter, même si le nombre d'hôtes est inférieur au nombre de VM dans le pool de nœuds du cluster d'utilisateur. Nous vous recommandons d'inclure des hôtes physiques supplémentaires dans le cluster vCenter. Configurez également le DRS pour qu'il soit entièrement automatisé, de sorte qu'en cas d'indisponibilité d'un hôte, il puisse redémarrer automatiquement les VM sur d'autres hôtes disponibles sans enfreindre les règles d'anti-affinité des VM.
Google Distributed Cloud gère une étiquette de nœud spéciale, onprem.gke.io/failure-domain-name, dont la valeur est définie sur le nom d'hôte ESXi sous-jacent. Les applications utilisateur qui souhaitent bénéficier de la haute disponibilité peuvent configurer des règles podAntiAffinity avec ce libellé comme topologyKey, pour garantir que leurs pods d'application sont propagés sur différentes VM et hôtes physiques.
Vous pouvez également configurer plusieurs pools de nœuds pour un cluster d'utilisateur avec différents datastores et des libellés de nœuds spéciaux. De même, vous pouvez configurer des règles podAntiAffinity en utilisant ce libellé de nœud spécial en tant qu'élément topologyKey afin d'améliorer la disponibilité en cas de défaillance du datastore.
Pour bénéficier de la haute disponibilité pour les charges de travail d'utilisateur, assurez-vous que le cluster d'utilisateur dispose d'un nombre suffisant d'instances dupliquées sous nodePools.replicas pour garantir l'exécution du nombre souhaité de nœuds de calcul dans le cluster d'utilisateur.
Pour isoler les défaillances des clusters d'administrateur et des clusters d'utilisateur, vous pouvez utiliser des datastores distincts.
Équilibreur de charge
Vous pouvez utiliser deux types d'équilibreurs de charge pour la haute disponibilité.
Équilibreur de charge MetalLB groupé
Pour l'équilibreur de charge MetalLB groupé, vous obtenez la haute disponibilité en disposant de plusieurs nœuds avec enableLoadBalancer: true.
MetalLB distribue les services sur les nœuds de l'équilibreur de charge, mais pour un seul service, un seul nœud principal gère tout le trafic de ce service.
La mise à niveau du cluster entraîne un temps d'arrêt lors de la mise à niveau des nœuds de l'équilibreur de charge. La durée de l'interruption du basculement de MetalLB augmente à mesure que le nombre de nœuds d'équilibreur de charge augmente. Avec moins de cinq nœuds, la perturbation dure moins de 10 secondes.
Équilibreur de charge groupé Seesaw
Pour l'équilibreur de charge groupé Seesaw, vous pouvez activer la haute disponibilité en définissant loadBalancer.seesaw.enableHA sur true dans le fichier de configuration du cluster.
Vous devez également activer une combinaison d'apprentissage MAC, de transmissions falsifiées et de mode promiscuité sur le groupe de ports de l'équilibreur de charge.
Avec la haute disponibilité, deux équilibreurs de charge sont configurés en mode actif-passif. Si l'équilibreur de charge actif présente un problème, le trafic est acheminé vers l'équilibreur de charge passif.
La mise à niveau d'un équilibreur de charge comporte quelques temps d'arrêt. Si le mode haute disponibilité est activé pour l'équilibreur de charge, le temps d'arrêt maximal est de deux secondes.
Équilibreur de charge F5 BIG-IP intégré
La plate-forme F5 BIG-IP fournit divers services pour vous aider à améliorer la sécurité, la disponibilité et les performances de vos applications. Pour Google Distributed Cloud, BIG-IP fournit un accès externe et des services d'équilibrage de charge L3/4.
Pour plus d'informations, consultez la section Haute disponibilité BIG-IP.
Utiliser plusieurs clusters pour la reprise après sinistre
Le déploiement d'applications dans plusieurs clusters sur plusieurs plates-formes vCenter ou GKE Enterprise peut offrir une disponibilité mondiale plus élevée et limiter le rayon d'action en cas de panne.
Cette configuration utilise le cluster GKE Enterprise existant dans le centre de données secondaire pour la reprise après sinistre au lieu de configurer un nouveau cluster. Voici un résumé détaillé de cette action :
Créez un autre cluster d'administrateur et un autre cluster d'utilisateur dans le centre de données secondaire. Dans cette architecture multicluster, les utilisateurs doivent disposer de deux clusters d'administrateur dans chaque centre de données, et chaque cluster d'administrateur exécute un cluster d'utilisateur.
Le cluster d'utilisateur secondaire dispose d'un nombre minimal de nœuds de calcul (trois) et d'une instance de secours automatique (toujours en cours).
Les déploiements d'applications peuvent être répliqués sur les deux vCenter à l'aide de Config Sync. Il est également préférable d'utiliser une chaîne d'outils DevOps (CI/CD, Spinnaker) pour les applications existantes.
En cas de sinistre, le cluster d'utilisateur peut être redimensionné en fonction du nombre de nœuds.
De plus, un basculement DNS sera nécessaire pour acheminer le trafic entre les clusters vers le centre de données secondaire.