Este documento mostra como testar e monitorar o desempenho de exibição on-line dos modelos de machine learning (ML) que são implantados no AI Platform Prediction. O documento usa o Locust (em inglês), uma ferramenta de código aberto para testes de carga.
O documento é destinado a cientistas de dados e engenheiros de MLOps que querem monitorar a carga de trabalho de serviço, a latência e a utilização de recursos dos modelos de ML na produção.
O documento pressupõe que você tenha alguma experiência com Google Cloud, TensorFlow, AI Platform Prediction, Cloud Monitoring e os notebooks do Jupyter.
O documento é acompanhado por um repositório do GitHub que inclui o código e um guia de implantação para implementar o sistema descrito neste documento. As tarefas são incorporadas aos notebooks do Jupyter.
Custos
Os notebooks com que você trabalha neste documento usam os seguintes componentes faturáveis de Google Cloud:
- Notebooks do Vertex AI Workbench gerenciados pelo usuário
- AI Platform Prediction
- Cloud Storage
- Cloud Monitoring
- Google Kubernetes Engine (GKE)
Para gerar uma estimativa de custo baseada na projeção de uso deste tutorial, use a calculadora de preços.
Antes de começar
- Sign in to your Google Cloud account. If you're new to Google Cloud, create an account to evaluate how our products perform in real-world scenarios. New customers also get $300 in free credits to run, test, and deploy workloads.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
-
In the Google Cloud console, on the project selector page, select or create a Google Cloud project.
-
Make sure that billing is enabled for your Google Cloud project.
Visão geral da arquitetura
O diagrama a seguir mostra a arquitetura do sistema para implantar o modelo de ML para previsão on-line, executar o teste de carga e coletar e analisar as métricas do desempenho de exibição do modelo de ML.
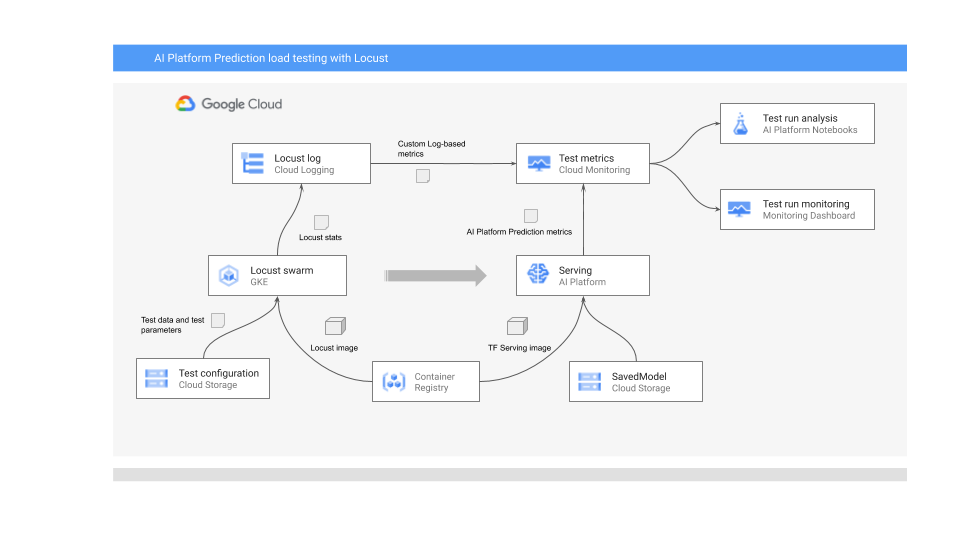
O diagrama mostra o seguinte fluxo:
- O modelo treinado pode estar no Cloud Storage, por exemplo, um SavedModel do TensorFlow ou um scikit-learn joblib. Como alternativa, ele pode ser incorporado a um contêiner de exibição personalizado no Container Registry. Por exemplo, o TorchServe para exibir modelos do PyTorch.
- O modelo é implantado no AI Platform Prediction como uma API REST. O AI Platform Prediction é um serviço totalmente gerenciado para serviço de modelo compatível com diferentes tipos de máquina, compatível com escalonamento automático com base na utilização de recursos e é compatível com vários aceleradores de GPU.
- O Locust é usado para implementar uma tarefa de teste (ou seja, o comportamento do usuário). Isso é feito ao chamar o modelo de ML implantado no AI Platform Prediction e executá-lo em escala no Google Kubernetes Engine (GKE). Isso simula muitas chamadas de usuário simultâneas para testes de carga do serviço de previsão do modelo. É possível monitorar o progresso dos testes usando a interface da Web do Lotus.
- O Locust registra as estatísticas de teste no Cloud Logging. As entradas de registro criadas pelo teste Locust são usadas para definir um conjunto de métricas com base em registros no Cloud Monitoring. Essas métricas complementam as métricas padrão do AI Platform Prediction.
- As métricas do AI Platform e do Locust personalizado estão disponíveis para visualização em um painel do Cloud Monitoring em tempo real. Após a conclusão do teste, as métricas também são coletadas de maneira programática para que você possa analisar e visualizar as métricas nos notebooks gerenciados pelo usuário do Vertex AI Workbench.
Os notebooks do Jupyter para este cenário
Todas as tarefas para preparar e implantar o modelo, executar o teste do Locust e coletar e analisar os resultados do teste são codificadas nos notebooks do Jupyter a seguir. Para executar as tarefas, execute a sequência de células em cada notebook.
01-prepare-and-deploy.ipynb. Você executa esse notebook para preparar um SavedModel do TensorFlow para disponibilização e implantar o modelo no AI Platform Prediction.02-perf-testing.ipynb. Você executa esse notebook para criar métricas com base em registros no Cloud Monitoring para o teste Locust e para implantar o teste Locust no GKE e executá-lo.03-analyze-results.ipynb(em inglês). Você executa este notebook para coletar e analisar os resultados do teste de carga do Locust a partir das métricas padrão do AI Platform que são criadas pelo Cloud Monitoring e do personalizadas do Locust.
Como inicializar seu ambiente
Conforme descrito no arquivo README.md do repositório do GitHub associado, você precisa executar as seguintes etapas para preparar o ambiente para executar os notebooks:
- No projeto do Google Cloud, crie um bucket do Cloud Storage, necessário para armazenar o modelo treinado e a configuração de teste do Locust. Anote o nome usado para o bucket, porque você precisará dele mais tarde.
- Crie um espaço de trabalho do Cloud Monitoring no seu projeto.
- Crie um cluster do Google Kubernetes Engine com as CPUs necessárias. O pool de nós precisa ter acesso às APIs do Cloud.
- Crie uma instância de notebooks gerenciados pelo usuário do Vertex AI Workbench que usa o TensorFlow 2. Neste tutorial, não são necessárias GPUs porque o modelo não é treinado. As GPUs podem ser úteis em outros cenários, especialmente para acelerar o treinamento dos modelos.
Como abrir o JupyterLab
Para executar as tarefas do cenário, é necessário abrir o ambiente do JupyterLab e receber os notebooks.
No Console do Google Cloud, acesse a página "Notebooks".
Na guia Notebooks gerenciados pelo usuário, clique em Abrir o JupyterLab ao lado do ambiente de notebook que você criou.
Isso abrirá o ambiente JupyterLab no navegador.
Para iniciar uma guia de terminal, clique no ícone Terminal na guia Acesso rápido.
No terminal, clone o repositório do GitHub
mlops-on-gcp:git clone https://github.com/GoogleCloudPlatform/mlops-on-gcp.gitQuando o comando for concluído, você verá a pasta
mlops-on-gcpno navegador de arquivos. Nessa pasta, você verá os notebooks com os quais trabalha neste documento.
Como definir as configurações do notebook
Nesta seção, serão definidas as variáveis no notebook com valores específicos para o contexto e você prepara o ambiente para executar o código do cenário.
- Navegue até o diretório
model_serving/caip-load-testing. - Para cada um dos três notebooks, faça o seguinte:
- Abrir o notebook
- Execute as células em Definir as configurações do ambiente do Google Cloud.
Nas seções a seguir, destacamos as principais partes do processo e explicamos os aspectos do projeto e do código.
Como exibir o modelo para previsão on-line
O modelo de ML usado neste documento usa o modelo de classificação de imagem ResNet V2 101 pré-treinado do TensorFlow Hub. No entanto, é possível adaptar os padrões e técnicas de design do sistema desse documento a outros domínios e outros tipos de modelos.
O código para preparar e exibir o modelo ResNet 101 está no notebook
01-prepare-and-deploy.ipynb. Execute as células no notebook para executar as seguintes tarefas:
- Faça o download e execute o modelo ResNet no TensorFlow Hub.
- Crie assinaturas de veiculação para o modelo.
- Exporte o modelo como SavedModel.
- Implantar o SavedModel no AI Platform Prediction
- Validar o modelo implantado.
As próximas seções deste documento fornecem detalhes sobre como preparar o modelo ResNet e sobre como implantá-lo.
Preparar o modelo ResNet para implantação
O modelo ResNet do TensorFlow Hub não tem assinaturas de exibição porque está otimizado para recomposição e ajuste. Portanto, você precisa criar assinaturas de disponibilização para o modelo para que ele possa veiculá-lo para previsões on-line.
Além disso, para exibir o modelo, recomendamos que você incorpore a lógica de engenharia de atributos na interface de exibição. Isso garante a afinidade entre o pré-processamento e a exibição do modelo, em vez de depender do aplicativo cliente para pré-processar os dados no formato necessário. Também é necessário incluir o pós-processamento na interface de exibição, como a conversão de um código de classe em um rótulo de classe.
Para tornar o modelo ResNet utilizável, você precisa implementar assinaturas de serviço que descrevem os métodos de inferência do modelo. Portanto, o código do notebook adiciona duas assinaturas:
- A assinatura padrão. Essa assinatura expõe o método
predictpadrão do modelo ResNet V2 101; o método padrão não tem lógica de pré ou pós-processamento. - Assinatura de pré e pós-processamento. As entradas esperadas para essa interface exigem pré-processamento relativamente complexo, incluindo codificação, escalonamento e normalização da imagem. Portanto, o modelo também expõe uma assinatura alternativa que incorpora a lógica de pré e pós-processamento. Essa assinatura aceita imagens brutas não processadas e retorna a lista de rótulos de classe classificados e as probabilidades de rótulos associadas.
As assinaturas são criadas em uma classe de módulo personalizado. Ela é derivada da
classe base
tf.Module
que encapsula o modelo ResNet. A classe personalizada estende a classe base com um método que implementa a lógica de pré-processamento de imagem e pós-processamento de saída. O método padrão do módulo personalizado é mapeado para o método padrão do modelo ResNet base para manter a interface análoga. O módulo personalizado é exportado como um SavedModel que inclui o modelo original, a lógica de pré-processamento e duas assinaturas de exibição.
A implementação da classe de módulo personalizado é mostrada no seguinte snippet de código:
LABELS_KEY = 'labels'
PROBABILITIES_KEY = 'probabilities'
NUM_LABELS = 5
class ServingModule(tf.Module):
"""
A custom tf.Module that adds image preprocessing and output post processing to
a base TF 2 image classification model from TensorFlow Hub.
"""
def __init__(self, base_model, input_size, output_labels):
super(ServingModule, self).__init__()
self._model = base_model
self._input_size = input_size
self._output_labels = tf.constant(output_labels, dtype=tf.string)
def _decode_and_scale(self, raw_image):
"""
Decodes, crops, and resizes a single raw image.
"""
image = tf.image.decode_image(raw_image, dtype=tf.dtypes.uint8, expand_animations=False)
image_shape = tf.shape(image)
image_height = image_shape[0]
image_width = image_shape[1]
crop_size = tf.minimum(image_height, image_width)
offset_height = ((image_height - crop_size) + 1) // 2
offset_width = ((image_width - crop_size) + 1) // 2
image = tf.image.crop_to_bounding_box(image, offset_height, offset_width, crop_size, crop_size)
image = tf.image.resize(image, [self._input_size, self._input_size])
image = tf.cast(image, tf.uint8)
return image
def _preprocess(self, raw_inputs):
"""
Preprocesses raw inputs as sent by the client.
"""
# A mitigation for https://github.com/tensorflow/tensorflow/issues/28007
with tf.device('/cpu:0'):
images = tf.map_fn(self._decode_and_scale, raw_inputs, dtype=tf.uint8)
images = tf.image.convert_image_dtype(images, tf.float32)
return images
def _postprocess(self, model_outputs):
"""
Postprocess outputs returned by the base model.
"""
probabilities = tf.nn.softmax(model_outputs)
indices = tf.argsort(probabilities, axis=1, direction='DESCENDING')
return {
LABELS_KEY: tf.gather(self._output_labels, indices, axis=-1)[:,:NUM_LABELS],
PROBABILITIES_KEY: tf.sort(probabilities, direction='DESCENDING')[:,:NUM_LABELS]
}
@tf.function(input_signature=[tf.TensorSpec([None, 224, 224, 3], tf.float32)])
def __call__(self, x):
"""
A pass-through to the base model.
"""
return self._model(x)
@tf.function(input_signature=[tf.TensorSpec([None], tf.string)])
def predict_labels(self, raw_images):
"""
Preprocesses inputs, calls the base model
and postprocess outputs from the base model.
"""
# Call the preprocessing handler
images = self._preprocess(raw_images)
# Call the base model
logits = self._model(images)
# Call the postprocessing handler
outputs = self._postprocess(logits)
return outputs
serving_module = ServingModule(model, 224, imagenet_labels)
O snippet de código a seguir mostra como o modelo é exportado como um SavedModel com as assinaturas de veiculação definidas anteriormente:
...
default_signature = serving_module.__call__.get_concrete_function()
preprocess_signature = serving_module.predict_labels.get_concrete_function()
signatures = {
'serving_default': default_signature,
'serving_preprocess': preprocess_signature
}
tf.saved_model.save(serving_module, model_path, signatures=signatures)
Como implantar o modelo no AI Platform
Quando o modelo é exportado como um SavedModel, as tarefas a seguir são executadas:
- O modelo é enviado para o Cloud Storage.
- Um objeto de modelo é criado no AI Platform Prediction.
- Uma versão de modelo é criada para o SavedModel.
O snippet de código a seguir do notebook mostra os comandos que executam essas tarefas.
gcloud storage cp {model_path} {GCS_MODEL_LOCATION} --recursive
gcloud ai-platform models create {MODEL_NAME} \
--project {PROJECT_ID} \
--regions {REGION}
MACHINE_TYPE='n1-standard-8'
ACCELERATOR='count=1,type=nvidia-tesla-p4'
gcloud beta ai-platform versions create {MODEL_VERSION} \
--model={MODEL_NAME} \
--origin={GCS_MODEL_LOCATION} \
--runtime-version=2.1 \
--framework=TENSORFLOW \
--python-version=3.7 \
--machine-type={MACHINE_TYPE} \
--accelerator={ACCELERATOR} \
--project={PROJECT_ID}
O comando cria um tipo de máquina n1-standard-8 para o serviço de previsão de modelo
com um acelerador de GPU nvidia-tesla-p4.
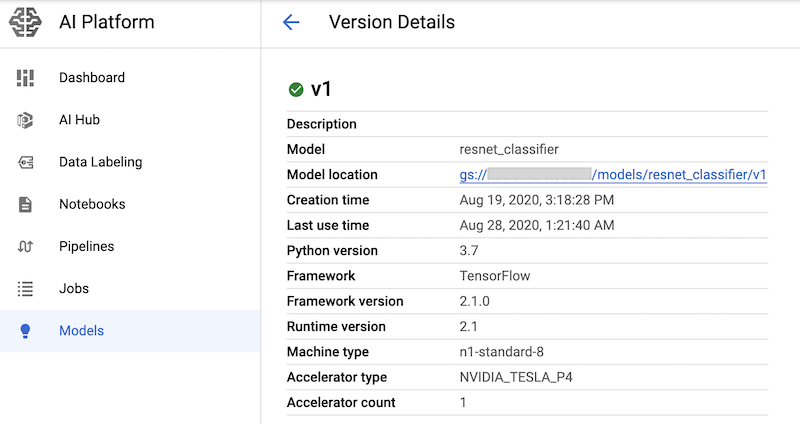
Depois de executar as células do notebook que têm esses comandos, é possível verificar se a versão do modelo foi implantada visualizando-a na página Modelos da AI Platform do console do Google Cloud. O resultado será assim:
Como criar métricas do Cloud Monitoring
Depois que o modelo for configurado para ser exibido, será possível configurar métricas que permitam monitorar o desempenho da exibição. O código para configurar as métricas está no notebook
02-perf-testing.ipynb.
A primeira parte do notebook 02-perf-testing.ipynb cria métricas personalizadas com base em registros no Cloud Monitoring usando o SDK do Cloud Logging para Python.
As métricas são baseadas nas entradas de registro geradas pela tarefa do Locust.
O método
log_stats
grava as entradas de registro em um registro do Cloud Logging chamado locust.
Cada entrada de registro inclui um conjunto de pares de chave-valor no formato JSON, conforme listado na tabela a seguir. As métricas são baseadas no subconjunto de chaves da entrada de registro.
| Chave | Descrição do valor | Uso |
|---|---|---|
test_id
|
O ID de um teste | Filtrar atributos |
model |
O nome do modelo do AI Platform Prediction | |
model_version |
A versão do modelo do AI Platform Prediction | |
latency
|
O tempo de resposta do 95o percentil, que é calculado em uma janela deslizante de 10 segundos | Valores de métricas |
num_requests |
É o número total de solicitações desde o início do teste. | |
num_failures |
É o número total de falhas desde o início do teste. | |
user_count |
É o número de usuários simulados | |
rps |
As solicitações por segundo |
O snippet de código a seguir mostra a função create_locust_metric no notebook, que cria uma métrica com base em registros personalizada.
def create_locust_metric(
metric_name:str,
log_path:str,
value_field:str,
bucket_bounds:List[int]):
metric_path = logging_client.metric_path(PROJECT_ID, metric_name)
log_entry_filter = 'resource.type=global AND logName={}'.format(log_path)
metric_descriptor = {
'metric_kind': 'DELTA',
'value_type': 'DISTRIBUTION',
'labels': [{'key': 'test_id', 'value_type': 'STRING'},
{'key': 'signature', 'value_type': 'STRING'}]}
bucket_options = {
'explicit_buckets': {'bounds': bucket_bounds}}
value_extractor = 'EXTRACT(jsonPayload.{})'.format(value_field)
label_extractors = {
'test_id': 'EXTRACT(jsonPayload.test_id)',
'signature': 'EXTRACT(jsonPayload.signature)'}
metric = logging_v2.types.LogMetric(
name=metric_name,
filter=log_entry_filter,
value_extractor=value_extractor,
bucket_options=bucket_options,
label_extractors=label_extractors,
metric_descriptor=metric_descriptor,
)
try:
logging_client.get_log_metric(metric_path)
print('Metric: {} already exists'.format(metric_path))
except:
logging_client.create_log_metric(parent, metric)
print('Created metric {}'.format(metric_path))
O snippet de código a seguir mostra como o método create_locust_metric é invocado no notebook para criar as quatro métricas personalizadas do Locust mostradas na tabela anterior.
# user count metric
metric_name = 'locust_users'
value_field = 'user_count'
bucket_bounds = [1, 16, 32, 64, 128]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# latency metric
metric_name = 'locust_latency'
value_field = 'latency'
bucket_bounds = [1, 50, 100, 200, 500]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# failure count metric
metric_name = 'num_failures'
value_field = 'num_failures'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
# request count metric
metric_name = 'num_requests'
value_field = 'num_requests'
bucket_bounds = [1, 1000]
create_locust_metric(metric_name, log_path, value_field, bucket_bounds)
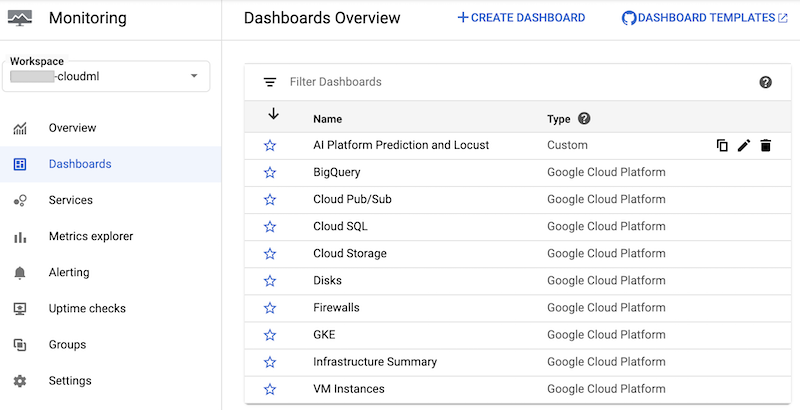
O notebook cria um painel personalizado do Cloud Monitoring chamado AI Platform Prediction e Locust. O painel combina as métricas padrão do AI Platform Prediction e as métricas personalizadas criadas com base nos registros do Locust.
Para mais informações, consulte a documentação da API Cloud Logging.
Esse painel e os respectivos gráficos podem ser criados manualmente.
No entanto, o notebook oferece uma maneira programática de criá-lo usando o modelo JSON
monitoring-template.json. O código usa a classe
DashboardsServiceClient
para carregar o modelo JSON e criar o painel no Cloud Monitoring,
conforme mostrado no snippet de código a seguir:
parent = 'projects/{}'.format(PROJECT_ID)
dashboard_template_file = 'monitoring-template.json'
with open(dashboard_template_file) as f:
dashboard_template = json.load(f)
dashboard_proto = Dashboard()
dashboard_proto = ParseDict(dashboard_template, dashboard_proto)
dashboard = dashboard_service_client.create_dashboard(parent, dashboard_proto)
Depois que o painel for criado, será possível vê-lo na lista de painéis do Cloud Monitoring no console do Google Cloud:
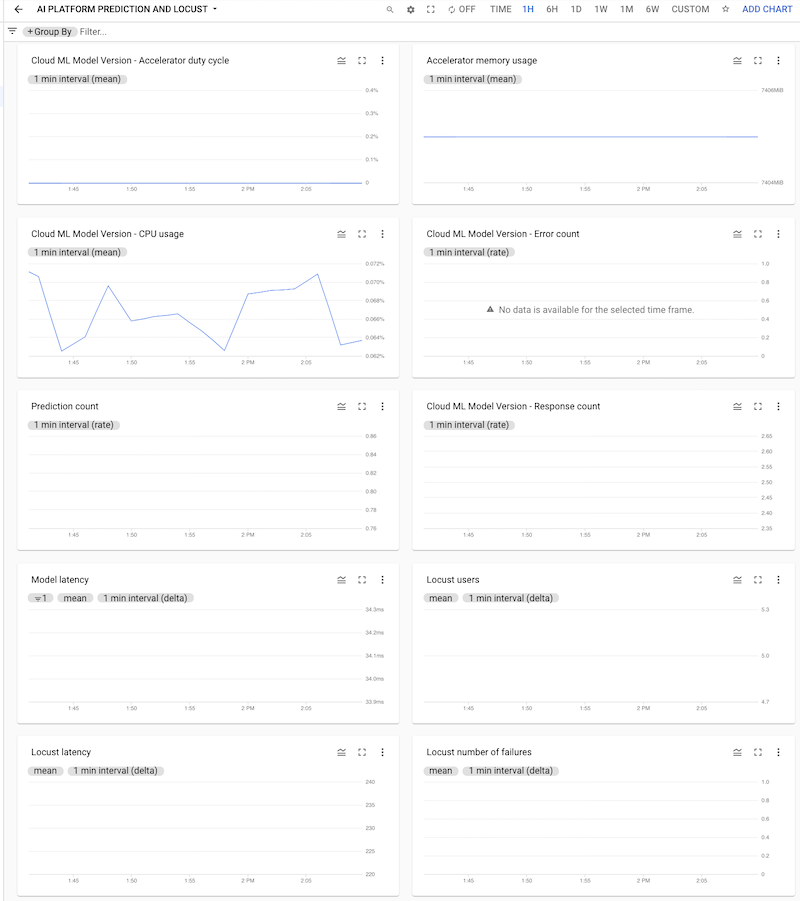
Clique no painel para abri-lo e ver os gráficos. Cada gráfico exibe uma métrica a partir do AI Platform Prediction ou dos registros do Locust, conforme mostrado nas capturas de tela a seguir.
Como implantar o teste do Locust no cluster do GKE
Antes de implantar o sistema Locust no GKE, você precisa
criar a
imagem do contêiner do Docker
que contém a lógica de teste integrada ao arquivo task.py. A imagem é
derivada da
imagem baseline locust.io
e é usada para os pods mestre e de trabalho do Locust.
A lógica para criar e implantar está no notebook em 3. Como implantar o LocusLocust em um cluster do GKE. A imagem é criada usando o seguinte código:
image_uri = 'gcr.io/{}/locust'.format(PROJECT_ID)
!gcloud builds submit --tag {image_uri} locust/locust-image
O processo de implantação descrito no notebook foi definido usando o Kustomize. Os manifestos de implantação do Locust Kustomize definem os seguintes arquivos que definem componentes:
locust-master. Esse arquivo define uma implantação que hospeda uma interface da Web em que o teste é iniciado e mostra estatísticas em tempo real.locust-worker. Esse arquivo define uma implantação que executa uma tarefa para testar a carga do serviço de previsão do modelo de ML. Normalmente, vários workers são criados para simular o efeito de vários usuários simultâneos fazendo chamadas para sua API de serviço de previsão.locust-worker-service. Esse arquivo define um serviço que acessa a interface da Web emlocust-masterpor meio de um balanceador de carga HTTP.
Você precisa atualizar o manifesto padrão antes da implantação do cluster. O
manifesto padrão consiste nos arquivos
kustomization.yaml
e
patch.yaml.
Faça alterações nos dois arquivos.
No arquivo kustomization.yaml, faça o seguinte:
- Defina o nome da imagem personalizada do Locust. Defina o campo
newNamena seçãoimagescomo o nome da imagem personalizada que você criou anteriormente. - Se quiser, defina o número de pods de workers. A configuração padrão implanta 32 pods de worker. Para alterar o número, modifique o campo
countna seçãoreplicas. Verifique se o cluster do GKE tem um número suficiente de CPUs para os workers do Locust. - Defina o bucket do Cloud Storage para a configuração de teste e os arquivos de payload. Na seção
configMapGenerator, verifique se os seguintes itens estão definidos:LOCUST_TEST_BUCKET. Defina como o nome do bucket do Cloud Storage criado anteriormente.LOCUST_TEST_CONFIG. Defina como o nome do arquivo de configuração do teste. No arquivo YAML, isso é definido comotest-config.json, mas você pode alterar isso se quiser usar um nome diferente.LOCUST_TEST_PAYLOAD. Defina como o nome do arquivo de payload de teste. No arquivo YAML, isso é definido comotest-payload.json, mas você pode alterar isso se quiser usar um nome diferente.
No arquivo patch.yaml, faça o seguinte:
- Se quiser, modifique o pool de nós que hospeda o mestre e os workers do Locust. Se você implantar a carga de trabalho do Locust em um pool de nós que não seja
default-pool, localize a seçãomatchExpressionse, emvalues, atualize o nome do pool de nós que a carga de trabalho do Locust.
Depois de fazer essas alterações, crie suas personalizações nos manifestos do Kustomize e aplique a implantação do Locust.locust-master ,locust-worker elocust-master-service ) ao cluster do GKE. O comando a seguir no notebook executa estas tarefas:
!kustomize build locust/manifests | kubectl apply -f -
É possível verificar as cargas de trabalho implantadas no console do Google Cloud. O resultado será assim:
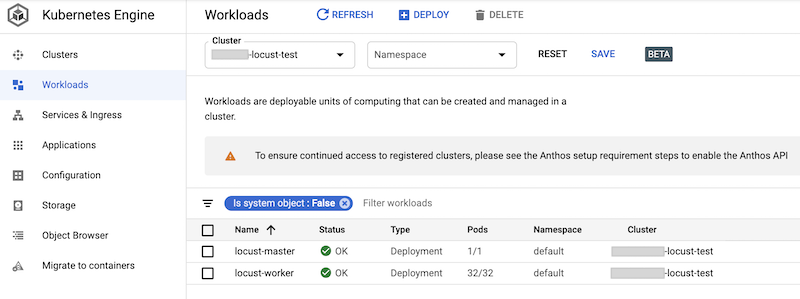
Implementar o teste de carga do Locust
A tarefa de teste do Locust é chamar o modelo implantado no AI Platform Prediction.
Esta tarefa é implementada na classe
AIPPClient
no módulo
task.py
que está na pasta /locust/locust-image/. O snippet de código a seguir mostra a implementação da classe.
class AIPPClient(object):
"""
A convenience wrapper around AI Platform Prediction REST API.
"""
def __init__(self, service_endpoint):
logging.info(
"Setting the AI Platform Prediction service endpoint: {}".format(service_endpoint))
credentials, _ = google.auth.default()
self._authed_session = AuthorizedSession(credentials)
self._service_endpoint = service_endpoint
def predict(self, project_id, model, version, signature, instances):
"""
Invokes the predict method on the specified signature.
"""
url = '{}/v1/projects/{}/models/{}/versions/{}:predict'.format(
self._service_endpoint, project_id, model, version)
request_body = {
'signature_name': signature,
'instances': instances
}
response = self._authed_session.post(url, data=json.dumps(request_body))
return response
A classe
AIPPUser
no arquivo task.py herda da classe
locust.User
para simular o comportamento do usuário de chamar o modelo do AI Platform Prediction. Esse comportamento é implementado no método predict_task. O método on_start da classe AIPPUser faz o download dos seguintes arquivos de um bucket do Cloud Storage especificado na variável LOCUST_TEST_BUCKET no arquivo task.py:
test-config.jsonEste arquivo JSON inclui as seguintes configurações para o teste:test_id,project_id,modeleversion.test-payload.json). Esse arquivo JSON inclui as instâncias de dados no formato esperado pelo AI Platform Prediction, com a assinatura de destino.
O código para preparar os dados e a configuração do teste está incluído no notebook
02-perf-testing.ipynb
em 4. Configure um teste do Locust.
As configurações de teste e as instâncias de dados são usadas como parâmetros para o método predict na classe AIPPClient para testar o modelo de destino usando os dados de teste necessários. O AIPPUser
simula um tempo de espera
de 1 a 2 segundos entre as chamadas de um único usuário.
Como executar o teste do Locust
Depois de executar as células do notebook para implantar a carga de trabalho do Locust no cluster do GKE e depois de criar e fazer upload dos arquivos test-config.json e test-payload.json no Cloud Storage, pode iniciar, interromper e configurar um novo teste de carga do Locust usando a interface da Web.
O código no notebook recupera o URL do balanceador de carga externo que expõe a interface da Web usando o seguinte comando:
%%bash
IP_ADDRESS=$(kubectl get service locust-master | awk -v col=4 'FNR==2{print $col}')
echo http://$IP_ADDRESS:8089
Para executar o teste, faça o seguinte:
- Em um navegador, digite o URL que você recuperou.
Para simular a carga de trabalho de teste usando configurações diferentes, insira valores na interface do Locust, que é semelhante a esta:
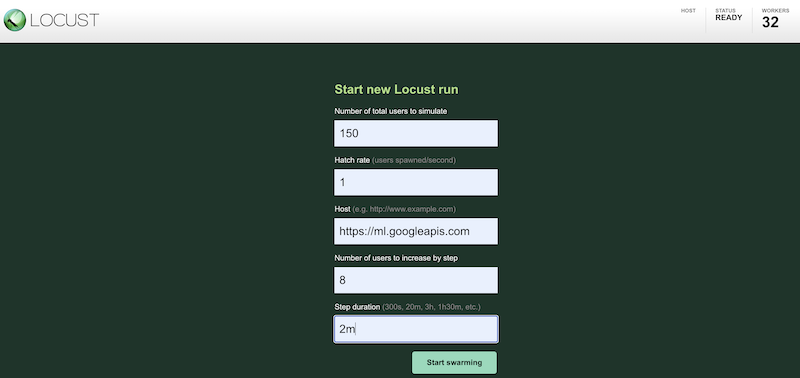
A captura de tela anterior mostra os seguintes valores de configuração:
- Número total de usuários a simular:
150 - Taxa de incubação:
1 - Host:
http://ml.googleapis.com - Número de usuários para aumentar por etapa:
10 - Duração da etapa:
2m
- Número total de usuários a simular:
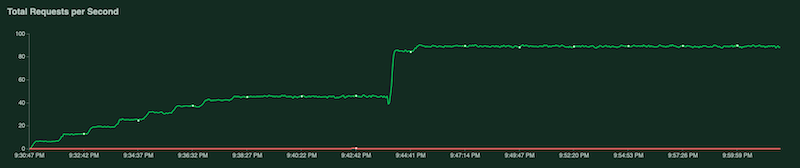
Durante a execução do teste, examine os gráficos do Locust. As capturas de tela a seguir mostram como os valores são exibidos.
Um gráfico mostra o número total de solicitações por segundo:
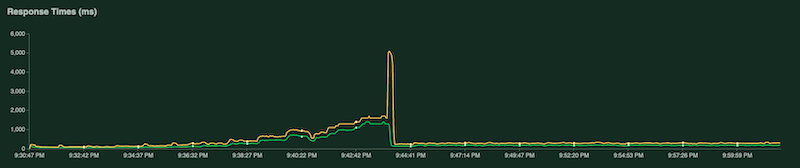
Outro gráfico mostra o tempo de resposta em milissegundos:
Como mencionado anteriormente, essas estatísticas também são registradas no Cloud Logging para que seja possível criar métricas personalizadas com base em registros do Cloud Monitoring.
Como coletar e analisar os resultados do teste
A próxima tarefa é coletar e analisar as métricas do Cloud Monitoring que são calculadas a partir dos registros de resultados como um objeto DataFrame pandas para visualizar e analisar os resultados no notebook. O código para
realizar essa tarefa está no notebook
03-analyze-results.ipynb.
O código usa o SDK do Python para consultas do Cloud Monitoring para filtrar e recuperar os valores de métrica, considerando os valores transmitidos no project_id, test_id, start_time, end_time, model, model_version e log_name.
O snippet de código a seguir mostra os métodos que recuperam as métricas do AI Platform Prediction e as métricas personalizadas com base em registros do Locust.
import pandas as pd
from google.cloud.monitoring_v3.query import Query
def _get_aipp_metric(metric_type: str, labels: List[str]=[], metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified AIPP metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_resources(model_id=model)
query = query.select_resources(version_id=model_version)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.set_index(df.index.round('T'))
return df
def _get_locust_metric(metric_type: str, labels: List[str]=[],
metric_name=None)-> pd.DataFrame:
"""
Retrieves a specified custom logs-based metric.
"""
query = Query(client, project_id, metric_type=metric_type)
query = query.select_interval(end_time, start_time)
query = query.select_metrics(log=log_name)
query = query.select_metrics(test_id=test_id)
if metric_name:
labels = ['metric'] + labels
df = query.as_dataframe(labels=labels)
if not df.empty:
if metric_name:
df.columns.set_levels([metric_name], level=0, inplace=True)
df = df.apply(lambda row: [metric.mean for metric in row])
df = df.set_index(df.index.round('T'))
return df
Os dados das métricas são recuperados como um objeto DataFrame do pandas para cada métrica. Os frames de dados individuais são mesclados em um único objeto DataFrame. O objeto DataFrame final com os resultados mesclados tem a seguinte aparência no notebook:
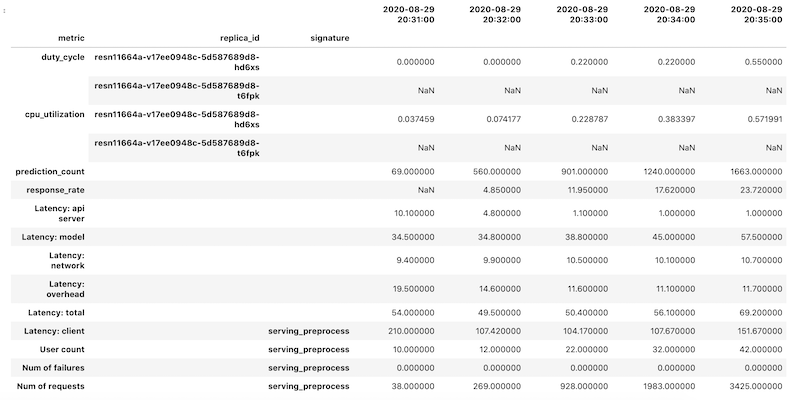
O objeto DataFrame recuperado usa indexação hierárquica para nomes de coluna. O motivo é que algumas métricas contêm várias séries temporais.
Por exemplo, a métrica duty_cycle da GPU inclui uma série temporal de medidas para cada GPU usada na implantação, indicada como replica_id. O nível superior do índice de colunas mostra o nome de uma métrica individual. O segundo nível é um código de réplica. O terceiro nível mostra a assinatura de um modelo. Todas as métricas são alinhadas na mesma linha do tempo.
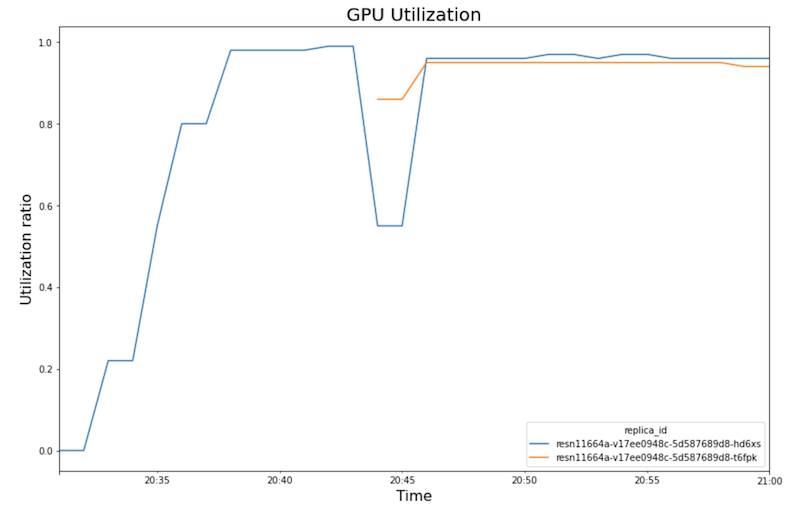
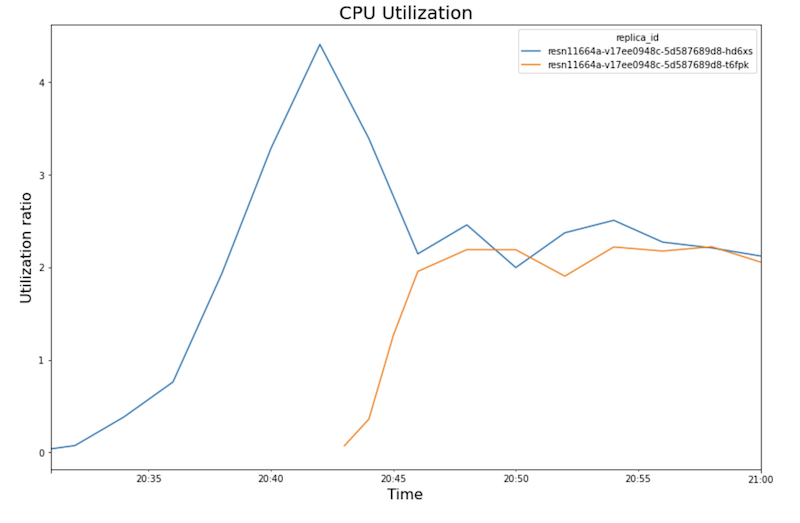
Os gráficos a seguir mostram a utilização da GPU, a utilização da CPU e a latência conforme você os vê no notebook.
Uso da GPU
Utilização da CPU
Latência:
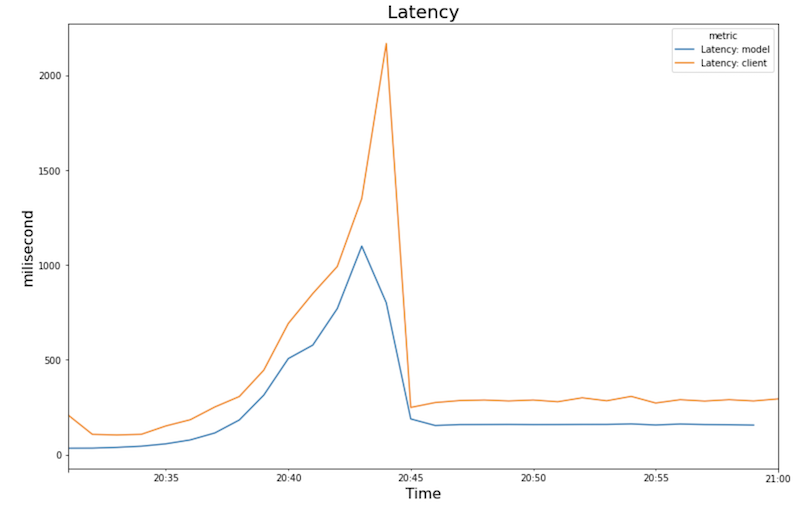
Os gráficos mostram o seguinte comportamento e sequência:
- increases medida que a carga de trabalho (número de usuários) aumenta, a utilização da CPU e da GPU aumenta. Como resultado, a latência aumenta e a diferença entre a latência do modelo e a latência total aumenta até o pico em torno das 20:40.
- Aos 20:40, a utilização da GPU atinge 100%, enquanto o gráfico de CPU mostra que a utilização atinge quatro CPUs. A amostra usa uma máquina
n1-standard-8neste teste, que tem 8 CPUs. Assim, a utilização da CPU atinge 50%. - Neste ponto, o escalonamento automático adiciona capacidade: um novo nó de exibição é adicionado com uma réplica de GPU extra. A primeira utilização de réplica de GPU diminui e a segunda utilização de réplica de GPU aumenta.
- A latência diminui à medida que a nova réplica começa a fornecer previsões, convergindo em torno de 200 milissegundos.
- A utilização da CPU converge em torno de 250% para cada réplica, ou seja, utilizando 2,5 CPUs de 8 CPUs. Esse valor indica que é possível usar uma máquina
n1-standard-4em vez den1-standard-8.
Limpar
Para evitar cobranças na sua Google Cloud pelos recursos usados neste documento, exclua o projeto que contém os recursos ou mantenha o projeto e exclua os recursos individuais.
- In the Google Cloud console, go to the Manage resources page.
- In the project list, select the project that you want to delete, and then click Delete.
- In the dialog, type the project ID, and then click Shut down to delete the project.
Se quiser manter o projeto do Google Cloud, mas excluir os recursos criados, exclua o cluster do Google Kubernetes Engine e o modelo do AI Platform implantado.
A seguir
- Saiba mais sobre MLOps e pipelines de entrega contínua e automação no machine learning.
- Saiba mais sobre arquitetura para MLOps usando o TFX, o Kubeflow Pipelines e o Cloud Build.
- Para mais arquiteturas de referência, diagramas e práticas recomendadas, confira a Central de arquitetura do Cloud.