この記事は、 Google Cloudで AI Platform(AI Platform)を使用して顧客の生涯価値(CLV)を予測する方法を説明した 4 つのパートからなるシリーズのパート 2 です。
このシリーズの記事は次のとおりです。
- パート 1: はじめに。CLV の概要と、CLV 予測の 2 つのモデリング手法について説明します。
- パート 2: モデルのトレーニング(この記事)。データを準備し、モデルをトレーニングする方法について説明します。
- パート 3: 本番環境へのデプロイ。パート 2 で説明したモデルを本番環境システムにデプロイする方法について説明します。
- パート 4: AutoML Tables の使用。AutoML Tables を使用してモデルをビルドおよびデプロイする方法を説明します。
このシステムを実装するためのコードは、GitHub リポジトリにあります。このシリーズでは、コードの内容とその使用方法について説明します。
はじめに
この記事はパート 1 の続きです。このパートでは、顧客の生涯価値(CLV)を予測する次の 2 つのモデルについて学習しました。
- 確率モデル
- ディープ ニューラル ネットワーク(DNN)モデル(機械学習モデルの一種)
パート 1 で説明したように、このシリーズの目標の 1 つは、CLV の予測に関してモデル間の比較を行うことです。このシリーズの本パートでは、まずデータの準備方法について説明します。その後、CLV の予測生成を目的とした両方のモデルタイプの構築とトレーニングについて説明し、それらの比較情報を示します。
コードのインストール
この記事で説明するプロセスに従う場合は、GitHub のサンプルコードをインストールする必要があります。
gcloud CLI をインストール済みの場合は、パソコンのターミナル ウィンドウを開き、コマンドを実行します。gcloud CLI がインストールされていない場合は、Cloud Shell のインスタンスを開きます。
サンプル リポジトリのクローンを作成します。
git clone https://github.com/GoogleCloudPlatform/tensorflow-lifetime-value
README ファイルの Install セクションにあるインストール手順に沿って、環境を設定します。
データの準備
このセクションでは、データの取得方法とクリーニング方法について説明します。
ソース データセットの取得とクリーニング
CLV を計算する前に、ソースデータに少なくとも以下の情報が含まれていることを確認する必要があります。
- 個々の顧客を区別するために使用される顧客 ID。
- 特定の時間における各顧客の購入金額。
- 購入日付。
この記事では、UCI Machine Learning Repository で一般公開されている Online Retail Data Set の過去の売上データを使用してモデルをトレーニングする方法について説明します。[1]
最初のステップは、データセットを CSV ファイルとして Cloud Storage にコピーすることです。BigQuery の読み込みツールのいずれかを使用して、data_source という名前のテーブルを作成します(この名前は任意ですが、GitHub リポジトリのコードではこの名前が使用されています)。データセットは、このシリーズに関連した一般公開バケットで利用可能であり、すでに CSV 形式に変換されています。
- パソコンまたは Cloud Shell で、GitHub リポジトリの README ファイルの Setup セクションに記載されているコマンドを実行します。
サンプル データセットには、次の表に示すフィールドが含まれています。この記事で説明するアプローチでは、使用列が ○ になっているフィールドのみを使用します。一部のフィールドは直接使用されませんが、新しいフィールドの作成に役立ちます。たとえば、UnitPrice と Quantity によって order_value が作成されます。
| 使用済み | フィールド | タイプ | 説明 |
|---|---|---|---|
| いいえ | InvoiceNo |
STRING |
名目値。各トランザクションに一意に割り当てられる 6 桁の整数。このコードが文字 c で始まる場合は、キャンセルという意味です。 |
| いいえ | StockCode |
STRING |
商品(アイテム)コード。名目値。各商品に一意に割り当てられる 5 桁の整数。 |
| いいえ | Description |
STRING |
商品(アイテム)名。名目値。 |
| はい | Quantity |
INTEGER |
トランザクションあたりの各商品(アイテム)の数量。数値。 |
| はい | InvoiceDate |
STRING |
請求の日時(mm/dd/yy hh:mm 形式)。各トランザクションが生成された日時。 |
| はい | UnitPrice |
FLOAT |
単価。数値。英ポンドでの単位当たりの商品価格。 |
| はい | CustomerID |
STRING |
顧客番号。名目値。各顧客に一意に割り当てられた 5 桁の整数。 |
| いいえ | Country |
STRING |
国名。名目値。各顧客の居住国の名前。 |
データのクリーニング
どのモデルを使用する場合でも、すべてのモデルに共通する一連の準備とクリーニングの手順を実行する必要があります。使用できる一連のフィールドとレコードを取得するには、次のオペレーションが必要になります。
- このソリューションの確率モデルで使用される最小時間単位は 1 日であるため、注文を
InvoiceNoではなく日付でグループ化する。 - 確率モデルに有用なフィールドのみを保持する。
- 注文数量や金額(たとえば、購入金額)が正であるレコードのみを保持する。
- 返品など、注文数量が負のレコードのみを保持する。
- 顧客 ID があるレコードのみを保持する。
- 過去 90 日間に何かを購入した顧客のみを保持する。
- 特徴の作成の対象期間中に、少なくとも 2 回購入した顧客のみを保持する。
次の BigQuery クエリを使用して、こうした操作をすべて実行できます(前述のコマンドと同様に、GitHub リポジトリのクローンを作成した場所でこのコードを実行します)。データが古いため、この記事では 2011 年 12 月 12 日を今日の日付とみなします。
このクエリでは 2 つのタスクを実行します。まず、作業データセットが大きい場合はクエリによって縮小されます(このソリューションの作業データセットは非常に小さいですが、このクエリではわずか数秒で非常に大きなデータセットを 2 桁縮小できます)。
次に、クエリで次のような基本データセットが作成されます。
customer_id
|
order_date
|
order_value
|
order_qty_articles
|
|---|---|---|---|
| 16915 | 2011-08-04 | 173.7 | 6 |
| 15349 | 2011-07-04 | 107.7 | 77 |
| 14794 | 2011-03-30 | -33.9 | -2 |
クリーニングされたデータセットには、order_qty_articles フィールドも含まれています。このフィールドは、次のセクションで説明するディープ ニューラル ネットワーク(DNN)で使用することのみを目的として含まれています。
トレーニングとターゲットの間隔の定義
モデルのトレーニングを準備するには、しきい値の日付を選択する必要があります。その日付で、注文を次の 2 つのパーティションに分けます。
- しきい値の日付より前の注文は、モデルのトレーニングに使用されます。
- しきい値の日付以降の注文は、ターゲット値をコンピューティングするために使用されます。

Lifetimes ライブラリには、データを前処理するためのメソッドが含まれています。ただし、CLV に使用するデータセットは非常に大きく、単一のマシンでデータの前処理を実行することは現実的ではありません。この記事で説明するアプローチでは、BigQuery で直接実行されるクエリを使用して、注文を 2 つのセットに分割します。ML モデルと確率モデルでは、両方のモデルが同じデータで動作するように同じクエリを使用します。
ML モデルと確率モデルでは、最適なしきい値の日付が異なる場合があります。この日付値は、SQL ステートメント内で直接更新できます。最適なしきい値の日付をハイパーパラメータと考えてください。データを確認し、いくつかのテスト トレーニングを実行することによって、最も適切な値を見つけます。
次の例に示すように、しきい値の日付は、クリーニングされたデータテーブルからトレーニング データを選択する SQL クエリの WHERE 句で使用されます。
データの集約
データをトレーニングとターゲットの間隔に分割した後、それらを集約して各顧客の実際の機能とターゲットを作成します。確率モデルの場合、集計は使用時期、頻度、金額(RFM)のフィールドに制限されます。DNN モデルの場合、RFM 機能も使用しますが、追加機能を使用して、高度な予測を行うこともできます。
次のクエリは、DNN モデルと確率モデルの両方の特徴を同時に作成する方法を示しています。
次の表に、クエリで作成される特徴を示します。
| 特徴名 | 説明 | 確率 | DNN |
|---|---|---|---|
monetary_dnn
|
機能の期間中の顧客あたりのすべての注文の合計金額。 | x | |
monetary_btyd
|
機能の期間中の顧客あたりのすべての注文の平均金額。確率モデルでは、最初の注文の値が 0 であると想定します。これはクエリによって強制されます。 | x | |
recency
|
機能の期間中の顧客による最初と最後の注文の間の時間。 | x | |
frequency_dnn
|
機能の期間中に顧客が注文した数。 | x | |
frequency_btyd
|
機能の期間中に顧客が注文した数から最初の注文数を差し引いた数。 | x | |
T
|
顧客による最初の注文から機能の期間の終了までの時間。 | x | x |
time_between
|
機能の期間中の顧客の注文間の平均時間。 | x | |
avg_basket_value
|
機能の期間中の顧客のバスケットの平均金額。 | x | |
avg_basket_size
|
機能の期間中に顧客のバスケットに入っている平均アイテム数。 | x | |
cnt_returns
|
機能の期間中に顧客が返品した注文の数。 | x | |
has_returned
|
機能の期間中に顧客が少なくとも 1 つの注文を返品したかどうか。 | x | |
frequency_btyd_clipped
|
frequency_btyd と同じですが、上限の外れ値によってクリップされます。 |
x | |
monetary_btyd_clipped
|
monetary_btyd と同じですが、上限の外れ値によってクリップされます。 |
x | |
target_monetary_clipped
|
target_monetary と同じですが、上限の外れ値によってクリップされます。 |
x | |
target_monetary
|
トレーニング期間とターゲット期間を含めて、顧客が使った総額。 | x |
これらの列の選択はコード内で行われます。確率モデルの場合は、Pandas DataFrame を使用して選択されます。
DNN モデルの場合、TensorFlow の特徴は context.py ファイルで定義されます。これらのモデルでは、以下は特徴として無視されます。
customer_id。これは、特徴として使用できない一意の値です。target_monetary。これは、モデルが予測する必要があるターゲットであり、入力としては使用されません。
DNN のトレーニング セット、評価セット、テストセットの作成
このセクションの説明は、DNN モデルのみに当てはまります。ML モデルをトレーニングするには、重複しない 3 つのデータセットを使用する必要があります。
トレーニング(70~80%)データセットは、損失関数を減らすための重みを学習するために使用されます。損失関数が減少しなくなるまで、トレーニングを続行します。
評価(10~15%)データセットは、モデルがトレーニング データに対して良好に動作するものの、一般化しにくい場合に、過剰適合を防ぐためにトレーニング段階で使用されます。
テスト(10~15%)データセットは、すべてのトレーニングと評価が完了した後、モデルの性能の最終的な測定を行うために 1 回だけ使用すべきです。このデータセットは、モデルでのトレーニング プロセス中に使用されないものであるため、統計的に有効なモデル精度の測定を行えます。
次のクエリでは、データの約 70% が含まれるトレーニング セットを作成します。このクエリでは、次の手法を使用してデータを分離します。
- 顧客 ID のハッシュが計算され、整数が生成されます。
- 剰余演算により、特定のしきい値を下回るハッシュ値が選択されます。
評価セットとテストセットに同じコンセプトが適用され、しきい値を上回っているデータが維持されます。
トレーニング
前のセクションで説明したように、さまざまなモデルを使用して CLV を予測できます。この記事で使用しているコードは、使用するモデルを決定できるように設計されています。モデルを選択するには、model_type パラメータを指定して次のトレーニング シェル スクリプトに渡します。このコードは残りの処理も行います。
トレーニングの第 1 の目標は、両方のモデルで、以下で定義する単純なベンチマークを達成できるようにすることです。両方のモデルタイプがベンチマークを達成する場合(当然その必要がある)、各タイプのパフォーマンスを比較できます。
モデルのベンチマーク
このシリーズの目的のために、以下のパラメータを使用して単純なベンチマークを定義します。
- 平均バスケット値。これは、しきい値の日付より前に行われたすべての注文に対して計算されます。
- 注文数。これは、しきい値の日付より前に行われたすべての注文のトレーニング間隔に対して計算されます。
- カウント乗数。これは、しきい値の日付より前の日数と、しきい値の日付と現在の間の日数の比率に基づいて計算されます。
ベンチマークは、トレーニング期間中の顧客による購入率が、ターゲット期間を通して一定であると単純に想定しています。したがって、顧客が 40 日間に 6 回購入した場合、60 日間では 9 回(60/40 * 6 = 9)購入すると想定します。各顧客のカウント乗数、注文数、平均バスケット値を掛けると、その顧客の簡単に予測されたターゲット値が得られます。
ベンチマーク エラーは二乗平均平方根誤差(RMSE)であり、すべての顧客の予測されたターゲット値と実際のターゲット値の間の絶対差の平均です。RMSE は、BigQuery で次のクエリを使用して計算されます。
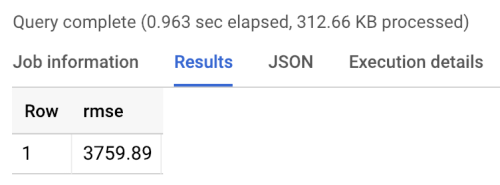
ベンチマークは、次に示すベンチマークの実行結果のように、3760 の RMSE を返します。モデルはこの値を上回るはずです。
確率モデル
このシリーズのパート 1 で説明したように、このシリーズでは Pareto / 負の二項分布(NBD)やベータ幾何学 BG / NBD モデルをはじめ、さまざまなモデルをサポートする Lifetimes という Python ライブラリを使用しています。次のサンプルコードでは、Lifetime ライブラリを使用して確率モデルで生涯価値の予測を行う方法を示します。
ローカル環境で確率モデルを使用して CLV の結果を生成するには、次の mltrain.sh スクリプトを実行します。トレーニングの分割の開始日と終了日、予測期間の終了日のパラメータを指定します。
./mltrain.sh local data --model_type paretonbd_model --threshold_date [YOUR_THRESHOLD_DATE] --predict_end [YOUR_END_DATE]
DNN モデル
サンプルコードには、あらかじめ作成された Estimator DNNRegressor クラスとカスタム Estimator モデルを使用した DNN の TensorFlow の実装が含まれています。DNNRegressor とカスタム Estimator では、各レイヤで同じ数のレイヤとニューロンを使用します。こうした値は、調整が必要なハイパーパラメータです。次の task.py ファイルには、手動でテストされ、良好な結果をもたらした値に設定されたハイパーパラメータの一部が含まれています。
AI Platform を使用している場合は、ハイパーパラメータ調整機能を使用できます。この機能は、yaml ファイルに定義されたさまざまなパラメータをテストします。AI Platform では、ベイジアン最適化を使用して、ハイパーパラメータの領域上で検索を行います。
モデルの比較結果
次の表は、サンプル データセットでトレーニングされた各モデルの RMSE 値を示しています。すべてのモデルは RFM データでトレーニングされます。パラメータの初期化がランダムに実行されるため、RMSE の値は、実行間でわずかに異なります。DNN モデルでは、平均バスケット値や返品数などの追加機能を利用します。
| モデル | RMSE |
|---|---|
| DNN | 947.9 |
| BG/NBD | 1,557 |
| Pareto / NBD | 1558 |
この結果により、このデータセットでは金銭的価値を予測する際に確率モデルより DNN モデルのほうが優れていることが示されています。しかし、比較的小さいサイズの UCI データセットの場合は、これらの結果の統計的妥当性が制限されます。ご使用のデータセットで各手法を試して、どれが最良の結果をもたらすか確かめてください。すべてのモデルは、そのデータから抽出された RFM 値に対して同じ元のデータ(顧客 ID、注文日、注文額を含む)を使用してトレーニングされました。DNN トレーニング データには、平均バスケット サイズや返品数などの追加の特徴が含まれていました。
DNN モデルは、顧客の金銭的価値全体のみを出力します。頻度やチャーンの予測に関心がある場合は、以下の追加タスクを実行する必要があります。
- ターゲットと、場合によってはしきい値の日付を変更するために、データを別々に準備します。
- 関心があるターゲットを予測するリグレッサー モデルを再トレーニングします。
- ハイパーパラメータを調整します。
ここでの目的は、2 つのタイプのモデル間で同じ入力機能を比較することでした。DNN を使用するメリットの 1 つは、この例で使用されているよりも多くの機能を追加して結果を改善できることです。DNN を使用すると、クリック ストリーム イベント、ユーザー プロフィール、商品特徴などのソースのデータを利用できます。
謝辞
Dua, D. and Karra Taniskidou, E. (2017). UCI Machine Learning Repository http://archive.ics.uci.edu/ml.Irvine, CA: University of California, School of Information and Computer Science.
次のステップ
- このシリーズのパート 3: 本番環境へのデプロイを読み、これらのモデルのデプロイ方法を理解する。
- 他の予測ソリューションについて学習する。
- Google Cloud に関するリファレンス アーキテクチャ、図、ベスト プラクティスを確認する。Cloud アーキテクチャ センターをご覧ください。