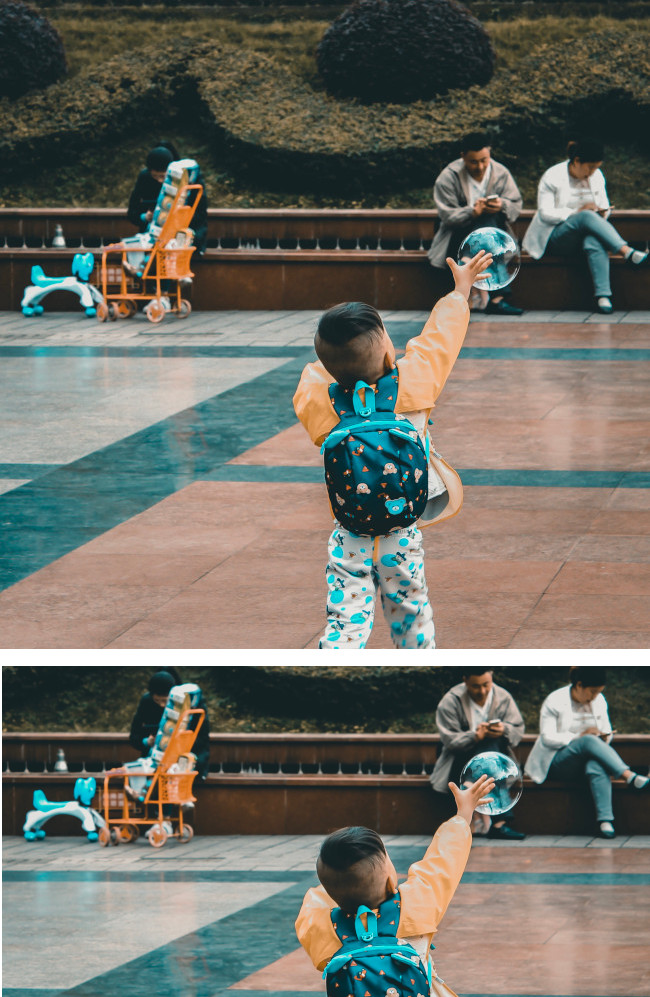Reconocimiento óptico de caracteres (OCR) de una imagen: reconocimiento de texto y conversión a texto codificado automáticamente. Identifica y extrae texto UTF-8 de una imagen.
Imágenes: optimizadas para las zonas dispersas de texto dentro de una imagen más grande.
Respuesta: devuelve una lista de palabras identificadas con texto, cuadros delimitadores y textAnnotations, así como la jerarquía estructural del texto detectado por el OCR (fullTextAnnotation).
Reconocimiento óptico de caracteres (OCR) de un archivo (PDF o TIFF) o de una imagen con mucho texto. Reconocimiento de texto denso y conversión a texto codificado automáticamente.
Archivos: optimizado para archivos de documentos (PDF o TIFF).
Imágenes: optimizada para las zonas densas de texto en una imagen (imágenes que son documentos) e imágenes que contienen escritura a mano.
Respuesta: devuelve la jerarquía estructural del texto detectado por OCR (fullTextAnnotation).
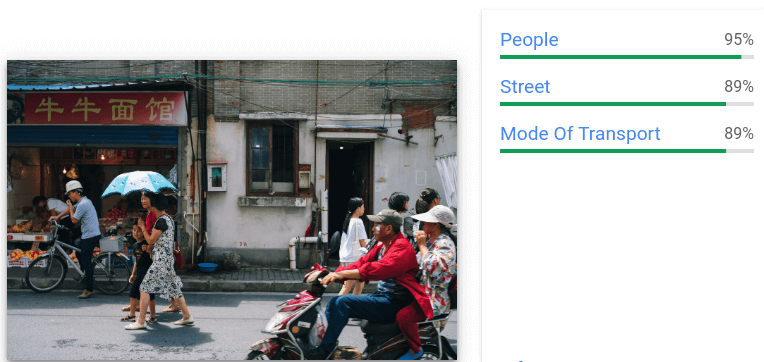
Proporciona etiquetas generales y anotaciones de cuadros delimitadores para varios objetos reconocidos en una sola imagen.
Por cada objeto detectado, se devuelven los siguientes elementos: una descripción textual, una puntuación de confianza y vértices normalizados [0,1] del polígono envolvente del objeto.
Proporciona un polígono delimitador de la imagen recortada, una puntuación de confianza y una fracción de importancia de esta región destacada con respecto a la imagen original en cada solicitud.
Puede proporcionar hasta 16 valores de relación de aspecto de imagen (anchura:altura) para una sola imagen.
Proporciona una serie de contenido web relacionado con una imagen.
Devuelve la siguiente información:
Entidades web: entidades inferidas (etiquetas o descripciones) a partir de imágenes similares en la Web.
Imágenes de coincidencia completa: una lista de URLs de imágenes de coincidencia completa
de cualquier tamaño en Internet.
Imágenes con coincidencias parciales: lista de URLs de imágenes que comparten características de puntos clave, como una versión recortada de la imagen original.
Páginas con imágenes coincidentes: una lista de páginas web (identificadas por la URL de la página, el título de la página y la URL de la imagen coincidente) con una imagen que cumpla las condiciones descritas anteriormente.
Imágenes visualmente similares: una lista de URLs de imágenes que comparten algunas características con la imagen original.
Etiqueta de mejor opción: la mejor opción para el tema de la imagen solicitada, inferida a partir de imágenes similares en Internet.
Localiza caras con polígonos delimitadores e identifica puntos de referencia faciales específicos, como los ojos, las orejas, la nariz o la boca, entre otros, junto con sus valores de confianza correspondientes.
Devuelve las puntuaciones de probabilidad de las emociones
(alegría, tristeza, enfado y sorpresa) y las propiedades generales de la imagen
(subexpuesta, borrosa y con tocado).
Las clasificaciones de probabilidad se expresan
con 6 valores diferentes: UNKNOWN, VERY_UNLIKELY,
UNLIKELY, POSSIBLE, LIKELY o
VERY_LIKELY.
[[["Es fácil de entender","easyToUnderstand","thumb-up"],["Me ofreció una solución al problema","solvedMyProblem","thumb-up"],["Otro","otherUp","thumb-up"]],[["Es difícil de entender","hardToUnderstand","thumb-down"],["La información o el código de muestra no son correctos","incorrectInformationOrSampleCode","thumb-down"],["Me faltan las muestras o la información que necesito","missingTheInformationSamplesINeed","thumb-down"],["Problema de traducción","translationIssue","thumb-down"],["Otro","otherDown","thumb-down"]],["Última actualización: 2025-10-19 (UTC)."],[],[]]